Story time. A fictional IT team (we’ll call them Initech) wants to automate how help desk tickets get routed, escalated and resolved. They’re drinking the SaaSpocalypse kool-aid, decide they don’t need 90% of big enterprise software functionality and point an LLM at the problem to let it generate highly personalized code. It writes cron jobs, calls APIs, queries databases, sends Slack messages and modifies user permissions.
A few weeks in, the generated code gives support agents permissions they shouldn’t have because it mixed up who’s allowed to do what. Login sessions expire at random because the code didn’t handle token refresh correctly, and agents get kicked out mid-conversation. And the worst one: when a ticket gets escalated and reassigned at the same time, the system creates a duplicate that inherits the customer’s access instead of the agent’s. A customer can now see internal notes. The business is now listed on Krebs on Security as a poster-child for engineering hubris.
An LLM can produce correct code, incorrect code, and dangerous code. All three are syntactically valid – and that’s the problem. Every standard library import, every API call, every system interaction is surface area where things could go wrong. The language gives the LLM access to everything, and the LLM has no reason not to use all of it.
Now shrink the language. Instead of generating arbitrary code, the LLM writes in a workflow Domain Specific Language (DSL):

Session handling, Rule Based Access Control (RBAC) scoping and access control are baked into the runtime; the LLM never touches them directly but it composes pre-validated building blocks. If it references a function that doesn’t exist, the parser rejects it. If it tries to manage permissions outside the DSL’s type system, the grammar won’t allow it.
That’s the Drafter Pattern. It trades expressiveness for reliability. As the language gets smaller, the error surface gets smaller with it.
Shrinking the language to shrink the error surface is one of the oldest ideas in software.
Before SQL, querying a database meant writing procedural code that manually traversed pointer networks. Don Chamberlin, SQL’s co-creator, described seeing Codd’s relational model for the first time: “a query that would require a complex program in the [Data Base Task Group (DBTG)] language could be reduced to a few simple lines.” SQL didn’t give programmers more power — it took away their ability to write pointer traversal bugs by removing pointers from the vocabulary entirely.
Fifty years later, the same pattern played out with TypeScript. JavaScript imposes virtually no constraints — assign a string to a number, call a function with the wrong arguments, misspell a property and get undefined instead of an error. TypeScript removed those freedoms. Airbnb’s postmortem analysis found that 38% of their production bugs would have been prevented by TypeScript. The language is strictly less expressive, and that’s the point.
Terraform did the same thing for infrastructure. Cloud consoles let engineers get away with murder – create a security group, attach it to the wrong VPC, open port 22 to the world and forget they did it. HashiCorp Configuration Language (HCL) removed the ability to express sequencing. An engineer declares what should exist; the runtime resolves ordering, dependencies, and rollback. You can’t write an ordering bug because the language has no concept of order. A DSL was once again used to control entropy.
Now before you close this tab — no, you don’t need to invent SQL. These are just recognizable examples. A DSL can be as simple as a JSON schema with a dozen allowed operations, or a config format with typed fields. The point isn’t the sophistication of the language, but the decision to constrain what can be expressed.
You’ve probably used the Drafter Pattern this week without naming it. Every time AI writes a spreadsheet formula, a Mermaid diagram, or a markdown slide deck, it’s generating constrained code where the grammar is the guardrail. These formats work because they’re limited (i.e. the AI can’t express anything dangerous, and the output is machine-verifiable).
Some companies have built entire products around this principle in higher-stakes domains. For example:
Sublime Security’s* Message Query Language (MQL) is a structured language for email threat detection. Analysts describe threats in natural language; the system produces detection rules that can be reviewed, version-controlled and executed deterministically. The AI can’t express anything outside MQL’s grammar — no arbitrary code, only pattern-matching over email events.
Serval.ai built DSL-first IT workflow automation from day one. The AI drafts workflows in a constrained language where the building blocks — routing, escalation, approval chains — are pre-validated. The DSL was co-designed with AI generation in mind, not bolted on after.
The pattern is the same everywhere it shows up: the AI authors, but the language decides what’s possible.
This isn’t a new idea. It’s an old idea that many AI teams are ignoring.
The default response to “LLMs produce unreliable code” is to add more checks after generation — guardrails, evals, human review, prompt engineering. The Drafter Pattern goes the other direction: change what can be generated in the first place. Don’t filter bad output. Make bad output inexpressible.
The difference is between a code review that catches rm -rf / and a language that doesn’t have rm. Between a guardrail that blocks unauthorized API calls and a grammar where unauthorized API calls aren’t part of the vocabulary, the Drafter Pattern chooses the latter.
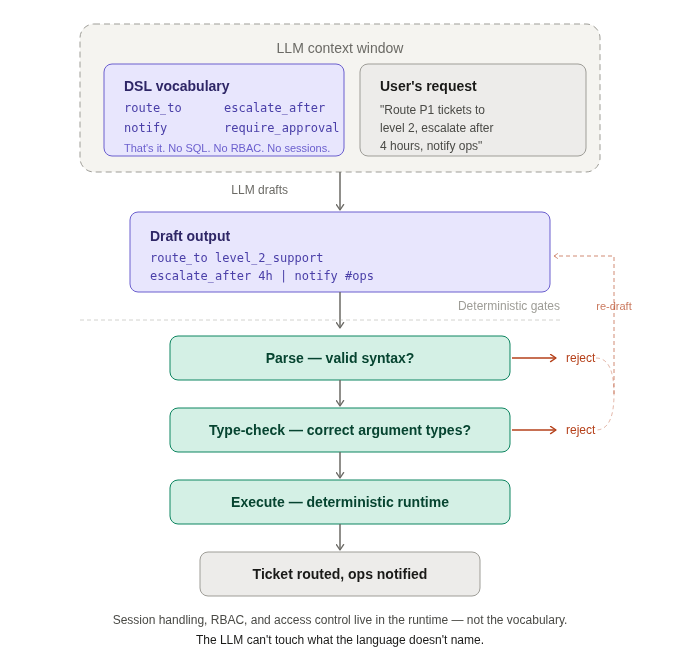
Back to the hypothetical Initech. Instead of generating an incorrect SQL query against a user table (and causing a horrible security breach), code-generating with a constrained DSL results in a battle-tested component/block like route_to level_2_support being used because the DSL doesn't have a concept of “user table.” Session handling, RBAC, and access control live in the runtime. The LLM composes pre-validated building blocks. It can't reach past them.
When the LLM does get something wrong — and it will — the failure modes are constrained too:
It hallucinates a function that doesn’t exist → the parser rejects it before anything runs.
It passes the wrong type to a valid function → the type system catches it at validation, not in production.
It produces valid code that does the wrong thing → that’s a semantic error, and you still need human review, evals, and testing for those. The pattern doesn’t solve everything. More on that below.
What the pattern does enforce: the AI can’t express anything the language doesn’t allow. The surface area of possible errors shrinks to the surface area of the DSL.
The Drafter Pattern eliminates categories of errors. It doesn’t eliminate errors.
An LLM generating Initech’s workflow DSL can still write route_to level_1_support when the ticket should go to level_2_support. That’s valid code that does the wrong thing. The parser won’t catch it. The type system won’t catch it. It’s a semantic error; the AI understood the grammar but misunderstood the intent. You still need human review, evals, and testing against historical data for these. The pattern shrinks the error surface. It doesn’t shrink it to zero.
Building and maintaining a DSL has real costs too. You’re designing a language — even a small one. That means schema decisions, migration paths when the domain evolves, and the discipline to keep the DSL tight as pressure mounts to “just add one more feature.” If your domain changes faster than your DSL can keep up, you’re accumulating debt. This tradeoff is worth it when the DSL is central to the product. It’s not worth it when it’s bolted on as an afterthought.
And not every domain needs this much constraint. If the cost of wrong output is low — a chatbot, a brainstorming tool, a content draft — the expressiveness of a general-purpose language is a feature, not a risk. The pattern earns its complexity when AI-generated code touches systems where mistakes have real consequences: permissions, money, health, compliance. If nobody gets hurt when the AI gets it wrong, let it write Python.
I think that most AI teams are neglecting language as a guardrail. They’re tuning prompts, stacking guardrails, running evals, and building review pipelines all to compensate for giving the LLM a language that is likely too expressive for the job. They’re filtering output when they should be constraining input.
The language your AI writes in is a design decision. Teams can default to Python or JavaScript because that’s what the LLM already knows. But the LLM also knows SQL. It knows YAML. It knows constrained formats it’s never been explicitly trained on. The choice to give it a smaller, safer language is available today.
The result isn’t a chatbot with guardrails. It’s a platform where customers can get the flexibility of AI generation and the reliability of constrained execution because the grammar rules out failure modes before anything runs.
There are many domains that could exploit the properties of AI code generation (e.g. legal, clinical, financial, security, infrastructure) by designing their own DSL. Not a new programming language. A constrained vocabulary of validated building blocks, a type system that catches errors before runtime and a grammar that makes the failure modes inexpressible. In my opinion, the companies that figure this out will be able to harness more reliable and robust forms of AI. They’ll have platforms where customers can safely personalize software to their exact needs because the language guarantees that personalization can’t break anything it shouldn’t.
SQL gave non-programmers safe access to databases. TypeScript gave large teams safe access to dynamic codebases. The next generation of DSLs will ideally give AI safe access to production systems.
We’re not short on model capability. We’re short on languages designed for the models to write in.
Here is a list of readings I find interesting on the topic.
Early History of SQL — Don Chamberlin, IEEE Annals of the History of Computing, 2012
Adopting TypeScript at Scale — Brie Bunge, JSConf Hawaii 2019 (Airbnb’s 38% bug reduction finding)
To Type or Not to Type: Quantifying Detectable Bugs in JavaScript — Gao, Bird, Barr, ICSE 2017 (15% of committed bugs preventable by type systems)
Declarative Application Management in Kubernetes — Brian Grant, 2017 (design rationale behind declarative infrastructure)
How Code Execution Drives Key Risks in Agentic AI Systems — NVIDIA AI Red Team, 2025 (code sanitization is “inherently limited”)
PreGenie: An Agentic Framework for High-quality Visual Presentation Generation — on markdown-based frameworks reducing LLM code generation difficulty
Companies Referenced
Nahim Nasser is Head of AI Engineering at Georgian, where he leads the applied AI engineering team building production AI systems for growth-stage companies.
Grateful to Frederik Dudzik, Asna Shafiq and Madalin Mihailescu for their thoughtful feedback on this piece.
* a Georgian portfolio company
This blog is provided for informational purposes only and should not be relied upon as legal, business, investment, or tax advice. Nothing in this blog constitutes investment advice, nor is it intended for use by any investors or prospective investors in any Georgian funds.This blog may include links to external websites or information obtained from third-party sources. Georgian has not independently verified and makes no representations regarding the accuracy or completeness of such information, whether current or ongoing.If this content includes third-party advertisements, Georgian has not reviewed such materials and does not endorse any advertising content or the companies referenced.
Any investments or portfolio companies mentioned are for illustrative purposes only and may not be representative of all investments made by funds managed by Georgian. Please contact Georgian for more information.