Industry analysts predict that roughly 75% of AI compute demand may come from inference by 2030, as models move from training to large-scale deployment. But inference workloads introduce a different bottleneck. Take agentic systems which maintain state while they run: they plan, call tools, reflect and iterate across many turns. Tool outputs accumulate as intermediate results, and multiple agents may exchange those results during execution. Over time, the system’s working state grows quickly. For teams running agent systems in production, this shows up as rising latency and GPU pressure long before model quality becomes the limiting factor.
Figure 1 illustrates how token consumption grows as agent workflows become more complex.
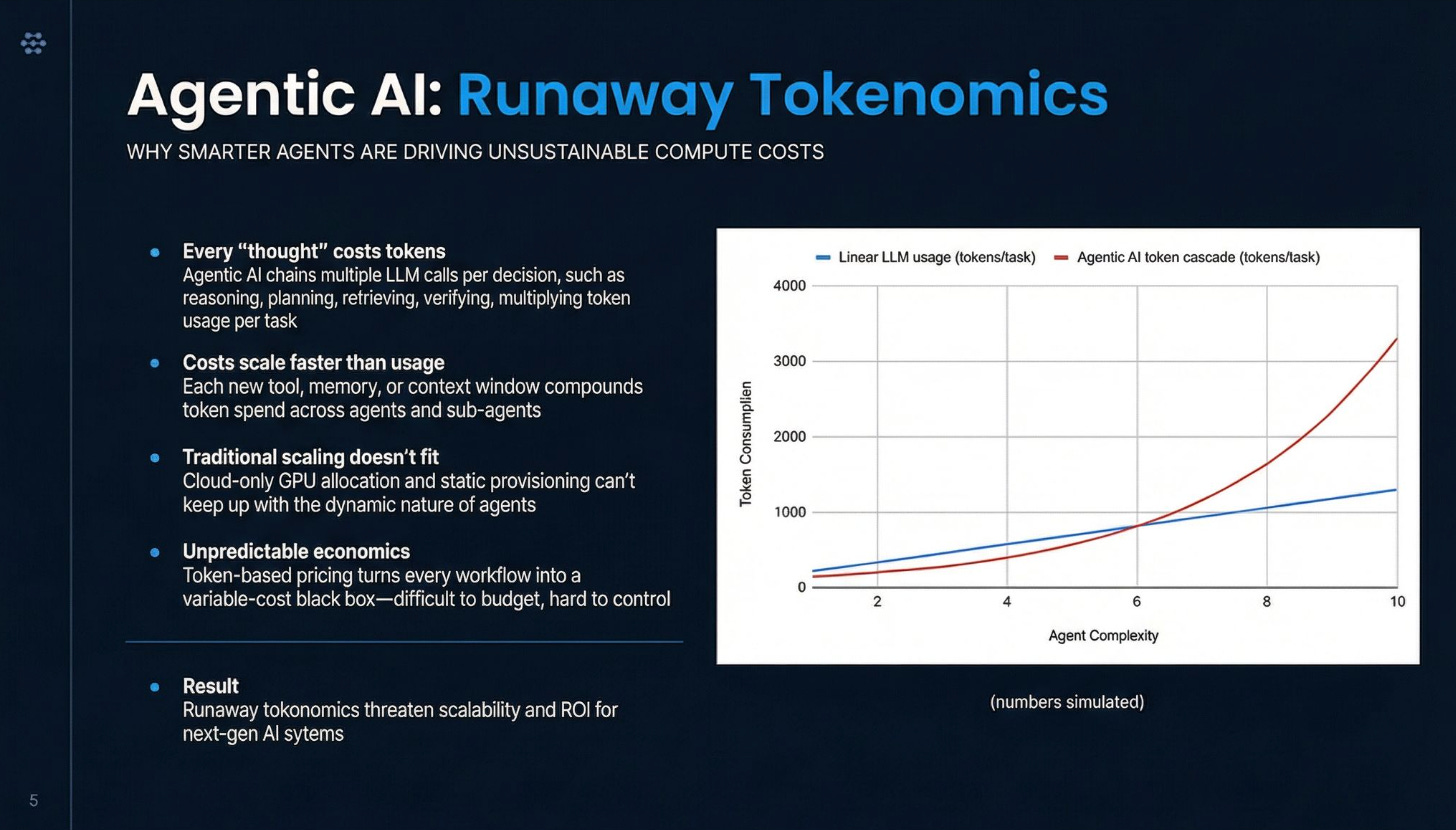
Agent state is built from two sources, and each drives a different kind of cost:
Conversation state is the running context a model holds during generation. In transformer-based models, this state is stored in a Key-Value (KV) cache. The KV cache stores intermediate attention results so the model can generate the next token without recomputing the entire sequence. Unlike model weights, which are fixed once loaded, the KV cache grows with the length of the conversation and the number of active sessions. The longer the conversation and the more concurrent sessions, the more KV cache memory the system requires, and GPU memory is finite.
Knowledge state is anything the agent needs to retrieve from an organization’s entire corpus: documents, tickets, code, logs and external sources. Keeping billions of items searchable in RAM becomes prohibitively expensive.
Agent state grows from both sources simultaneously. Conversation history expands inside the model, while external knowledge must be retrieved and injected into the context. Each type of state eventually runs into a different infrastructure constraint.
When either type of state outgrows the memory available to serve it, the system hits a memory wall, where the working state required to run the model no longer fits comfortably in accelerator memory. At that point it can no longer keep enough data in fast storage and begins falling back to slower alternatives such as recomputation, disk reads or eviction.
This problem is not limited to individual workloads. Across the industry, model sizes have grown much faster than accelerator memory capacity, pushing modern AI systems toward what infrastructure providers describe as a “memory wall” (Figure 2).
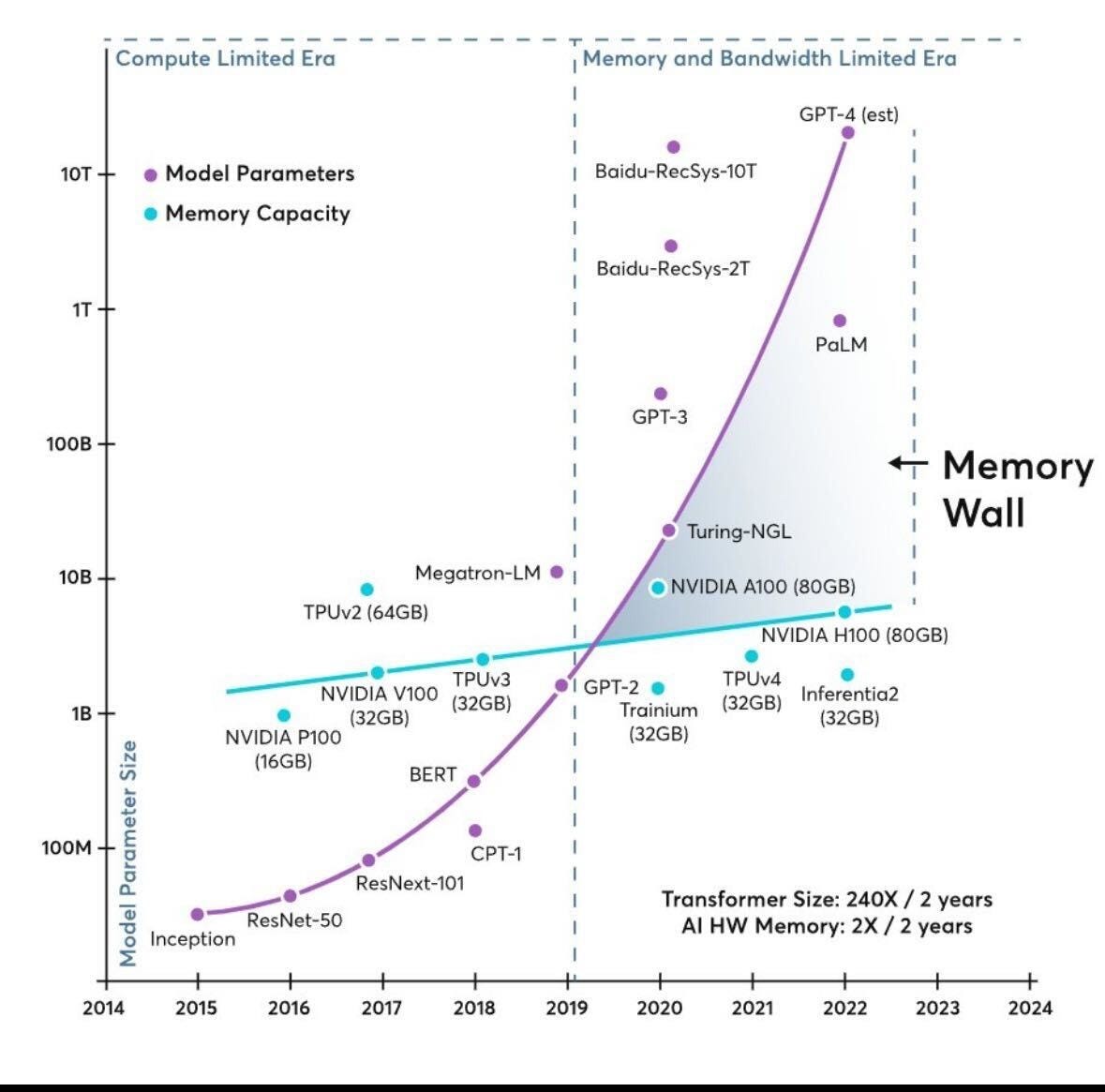
Two distinct memory walls emerge:
The inference memory wall: KV caches for long contexts and many concurrent sessions exceed available GPU VRAM, forcing recomputation and lowering throughput.
The retrieval memory wall: Large knowledge bases must remain searchable in real time, but RAM-based vector databases become extremely costly at scale.
The industry is responding in two ways: reducing the amount of context that reaches the model, and expanding the infrastructure that can serve it.
Context engineering focuses on reducing how many tokens reach the model in the first place. Techniques such as summarization, progressive disclosure, retrieval filtering and prompt compaction limit how much conversation history and external knowledge are passed into the model. These approaches reduce both latency and memory pressure.
At the same time, model providers have expanded context windows from a few thousand tokens to 100K or more. At first glance this seems like it solves the conversation state problem. In practice, longer contexts increase both latency and memory pressure, and research on context rot by Chroma suggests models begin losing focus beyond roughly 10K to 30K tokens.
The real constraint appears in aggregate: many agents, many sessions and many tokens all competing for the same GPU memory. That aggregate pressure is what triggers the inference memory wall. To understand why, it helps to look at how transformer models store conversation state during inference.
During inference, transformers store a KV cache to hold intermediate attention results so that the model can generate the next token without recomputing the entire sequence. Even with careful pruning, a 50-turn agent interaction carries several thousand tokens of history. Multiply that across hundreds of concurrent users, each with their own KV cache, all sharing the same GPU memory. In smaller deployments, this often shows up as sudden latency spikes when concurrency increases, even if individual conversations are short.
The bottleneck is not any single conversation being too long. It is the total load across all concurrent sessions. A rough estimate: a 100K-token sequence can require around 50 GB of KV cache for a modern large model (source: estimates based on standard transformer KV cache sizing). High-end GPUs like the NVIDIA H100 provide up to 80 GB of VRAM, though many deployments run on 40 GB configurations. A single long-context session can therefore consume a large fraction of a GPU’s memory.
Agent systems amplify the problem because sessions persist for dozens of turns rather than a single prompt-response cycle. In production deployments, GPUs are also shared across many users. Each active session maintains its own KV cache, and memory pressure grows quickly as concurrency increases.
When the KV cache no longer fits, the system begins evicting entries and recomputing them on demand. GPUs spend time rebuilding attention state instead of generating new tokens. Once this happens, throughput drops and latency rises; you have hit the inference memory wall. More GPUs add compute capacity, but memory pressure still limits how many sessions the system can sustain. Algorithmic approaches like KV-cache compression, sparse attention and state-space models can reduce per-session memory pressure. But compressed state still needs to be stored and moved efficiently, and models still need fast access to external knowledge. Infrastructure layers stay important: they determine what to keep close to the model and what to page out. There are three broad ways teams respond to this:
Reduce memory per session (KV compression, sparse attention)
Extend effective memory (paging KV cache to slower storage)
Change model architectures to reduce or eliminate KV state
In practice, most production systems rely on some combination of the first two.
Modern inference workloads constantly move data between storage and GPUs. Models must load weights, maintain KV caches for active sessions, and manage state as requests begin and finish. When this working set no longer fits in GPU memory, systems begin evicting cache entries and recomputing them. The result is unstable performance. KV caches are evicted and rebuilt, increasing latency as context length or concurrency grows.
One approach is to extend effective memory by paging state beyond GPU High Bandwidth Memory (HBM). One example of that is Weka’s NeuralMesh tool which provides a parallel filesystem built on distributed Nonvolatile Memory express (NVMe) drives and high-speed networking. Using technologies such as RDMA and GPUDirect Storage, data can move directly between GPUs and storage without passing through the CPU.
Instead of forcing all model state and KV caches to remain in GPU memory, inference platforms can page data between GPU HBM and NVMe storage as needed.
Frequently accessed state remains in GPU memory, while colder KV entries and model data sit on NVMe. This effectively creates a memory hierarchy for inference workloads: hot state stays in GPU HBM, while colder state is paged to NVMe storage. The result is a larger effective working memory for the system. In that sense, inference systems are beginning to resemble familiar computer architectures where a small, fast cache sits above larger and slower memory layers. Larger models, longer contexts and more concurrent sessions can be supported without being constrained strictly by GPU VRAM.
The trade-off is bandwidth. H100 GPUs provide roughly 3 TB/s of HBM bandwidth, while modern NVMe drives deliver 10–15 GB/s. NVMe is not a replacement for GPU memory. The goal is to keep colder state close enough to the GPU that paging is viable while the hot working set remains resident in HBM.
The alternative is KV cache eviction and recomputation. In practice, this shifts the problem from memory limits to bandwidth limits. When entries are evicted, the model must rebuild attention state by recomputing earlier tokens. For long contexts this can add hundreds of milliseconds or more of latency, making selective paging often preferable to repeated recomputation.
Even if GPU memory were unlimited, agents would still face another constraint: retrieving the right information to inject into the agent’s context.
Agents rarely rely only on the prompt. They need access to an organization’s knowledge: documents, tickets, code repositories, logs, CRM records and external data sources. In large environments this corpus can grow to hundreds of millions or billions of documents.
Keeping that data searchable in real time can become expensive. For most teams, keeping the full index in RAM stops being viable well before datasets reach billions of documents. Many early vector search systems assumed the index would live primarily in RAM. This works for small datasets but breaks down as collections grow. Memory requirements increase, tail latencies rise, and infrastructure costs climb quickly. Large deployments can reach six- or seven-figure annual costs simply to keep the index resident in memory.
This is the retrieval memory wall: the cost of keeping large knowledge bases searchable with low latency. Retrieval systems generally fall into three categories:
Fully in-memory indexes (fast, but can be expensive at scale)
Disk-backed indexes (cheaper, but can have higher latency)
Tiered architectures combining RAM, SSD and object storage
Most large-scale systems are moving toward tiered designs to balance cost and latency.
turbopuffer is an example of the third approach. Instead of keeping indexes entirely in RAM, it treats object storage as the primary storage layer.
Its architecture uses three tiers:
Object storage (S3 or GCS) holds the majority of the index and document corpus
NVMe SSDs cache frequently accessed index segments
RAM stores the hottest index structures and working set
Most of the corpus therefore lives in inexpensive object storage, while frequently accessed data remains close to compute. This tiered design allows the index to scale to very large datasets while keeping only a small working set in memory.
The economics change significantly. A 10-TB vector dataset stored entirely in RAM-based infrastructure can cost $50K–$100K per month once replication and production redundancy are included. With a tiered architecture, most of the corpus sits in object storage while only the active working set remains in RAM. The same dataset can often be served for under $1K per month in storage costs, with NVMe and RAM reserved only for hot data. The trade-off is latency. Queries served from cache can return in tens of milliseconds, while cold queries that reach object storage may take several hundred milliseconds.
For workloads with power-law access patterns, where a small fraction of documents accounts for most queries, this architecture maintains fast responses for common requests while dramatically reducing infrastructure cost. This works well when access follows a power-law distribution, where a small portion of data serves most queries. If access is uniform, more queries hit cold storage and latency increases.
In practice, turbopuffer acts as the retrieval layer for agent systems. It keeps large knowledge bases searchable while allowing the majority of data to remain in low-cost storage.
A typical request in a production system looks like this:
1. The agent searches a large knowledge base for relevant documents
2. Those documents are loaded into the model’s prompt
3. The model reasons over that prompt while maintaining conversational state in KV cache
Systems like turbopuffer address the retrieval memory wall by making large knowledge bases searchable without keeping everything in RAM. Systems like Weka’s NeuralMesh address the inference memory wall by expanding the effective memory available to GPUs.
Combined with context engineering techniques that limit unnecessary tokens, these layers form the foundation of scalable agent systems.
This shift reflects a broader pattern in AI infrastructure. Early work on large language models focused primarily on compute: how to train larger models with more FLOPs. Agentic systems change the constraint. Long-running interactions create persistent state that must be stored, retrieved and moved efficiently. As a result, inference infrastructure increasingly resembles traditional systems like databases and operating systems, with hot working sets, paging, caching layers and tiered storage.
Scaling agent systems ultimately becomes a memory problem. Conversation state pressures GPU memory through KV caches, while knowledge state pressures retrieval infrastructure through massive searchable corpora. Both must scale together for agent systems to operate at scale.
Frederik Dudzik is a DevSecOps Tech Lead on Georgian’s AI Lab, where he works on scaling and securing agentic AI systems, building on his production engineering experience at Shopify and as a founding engineer shipping a top-ranked consumer app.
Grateful to Paul Inder, Kshitij Jain, Asna Shafiq & Pashootan Vaezipoor for their thoughtful feedback on this piece.
This blog is provided for informational purposes only and should not be relied upon as legal, business, investment, or tax advice. Nothing in this blog constitutes investment advice, nor is it intended for use by any investors or prospective investors in any Georgian funds.This blog may include links to external websites or information obtained from third-party sources. Georgian has not independently verified and makes no representations regarding the accuracy or completeness of such information, whether current or ongoing.If this content includes third-party advertisements, Georgian has not reviewed such materials and does not endorse any advertising content or the companies referenced.
Any investments or portfolio companies mentioned are for illustrative purposes only and may not be representative of all investments made by funds managed by Georgian. Please contact Georgian for more information.