
In the previous chapter, we dove deep into the Kappa implementation, our decompiler buddy who lives in VS Code. It adds AI-powered features for decompilation and automates boring flows when decompiling a single function, as we did manually in the second chapter.
But now we have the question: are LLMs really good for matching decompilation?
⚙️ What is Matching Decompilation?
Matching decompilation is the art of converting assembly back into C source code that, when compiled, produces byte-for-byte identical machine code. It’s popular in the retro gaming community for recreating the source code of classic games. For example, Super Mario 64 and The Legend of Zelda: Ocarina of Time have been fully match-decompiled.
Decompilation has been around for a long time. Many retro games were decompiled before AI became a thing. For years the community built solid tools to help decompile functions. But they all share one thing: they are procedural.
Beyond that, some people reasonably don’t believe that LLMs are good for decompilation. I've received some fair criticism because of a lack of data.
So, to know whether LLMs are good for decompilation or not, we need to measure their output on real, in-progress decompilation projects.
It’s worth mentioning that LLMs don’t exclude the great programmatic tooling the community has built over the years. They join forces with LLMs.
So, the goal is to measure the outcomes of matching decompilation in a pipeline using both programmatic and AI-powered tools. The pipeline can start using programmatic tools to decompile a function and then use an LLM to try matching it.
More importantly, having a solid way to benchmark decompilation tasks is a requirement to pave the way to improve both the AI-powered and programmatic decompilation tools with evidence-based decisions. As I described briefly in the previous chapter, sometimes it was difficult to know if a given change to the prompt improved it or was actually harming it.
It’s worth mentioning Chris Lewis’ work. A few months ago, he started a decompilation project for Snowboard Kids 2 (SK2). He’s been sharing his progress and insights on his blog. During his journey, he’s been building an agentic flow to automatically decompile this game. He shared in the 2nd chapter how it sped up a lot of his work.
Although it’s an engaging finding and evidence that LLMs are really helpful, there’s no benchmark data comparing the same dataset of functions.
This gap is what we are going to fill in this chapter!
Spoiler: Across 60 functions from two real decomp projects, the pipeline matches 74% functions, and 88% of them produce the same outcome every time!
So, the next goal is to produce benchmarks. Initially, I spent some time trying to find an off-the-shelf tool, but at last I decided to make a tailored pipeline runner for decompilation that outputs benchmarking data.

I named it Mizuchi, just to keep on-brand with Kappa (both kappa and mizuchi are mythological creatures in Japanese folklore). Also, I picked a creative name because I don't know how Mizuchi will grow up, so I avoided something too tied to the current goal. There is a chance that this tooling will become useful for more cases than only matching decompilation (I'll talk more about it later!).
Mizuchi runs the following plugin-based pipeline.
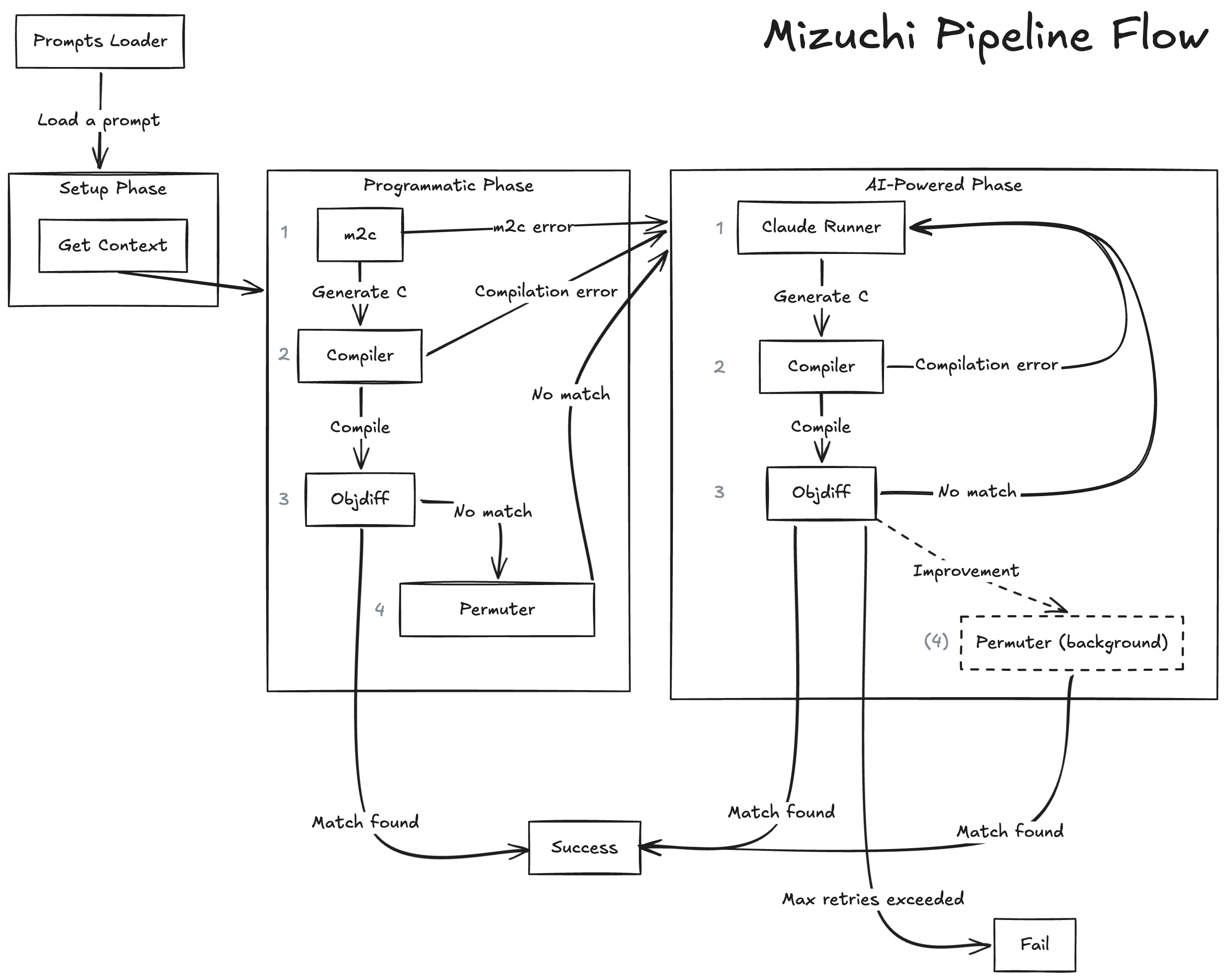
These are the current plugins available:
Get Context: Runs a shell script to get the context from a given function, likely using the
m2ctx.pyscript. It writes a C file that includes structs, macros, and other definitions that are prepended to the C code with the attempt to decompile the function.m2c: Calls m2c (a machine code to C decompiler) to programmatically produce C code from the target assembly function.
Compiler: Compiles the generated C.
Objdiff: Compares the compiled object file against the target one, using objdiff.
Permuter: Calls decomp-permuter to programmatically permute C code to find a better matching rate.
Claude Runner: It's the most complex plugin. It runs a Claude Agent SDK session to decompile the target function.
Before starting the pipeline, we have Tasks Loader. It reads a folder that must contain the following structure to load the tasks we are going to run:
tasks/
my-function-1/
prompt.md # The prompt content
settings.yaml # Metadata (functionName, targetObjectPath, asm)
my-function-2/
prompt.md
settings.yaml
... Then, we have Plugin Manager, which runs the plugins in three phases:
Setup Phase: Just calls the Get Context plugin.
Programmatic Phase: It’s a one-way flow with the programmatic tools: m2c → Compiler → Objdiff → Decomp Permuter.
m2c produces a first attempt to decompile a function, then calls Compiler and Objdiff. It may then call Permuter, which iterates through code permutations. If there is no perfect match, it goes to the AI-Powered Phase.AI-Powered Phase: It's a loop including Claude Runner → Compiler → Objdiff.
The result from m2c is included in the initial prompt for Claude Runner.
This phase runs Permuter as a background task. Whenever Claude finds a better match, it spawns a background job with Permuter to iterate the code produced by Claude. We use the result from Permuter only if it finds a perfect match, and in this case, the pipeline is finished.
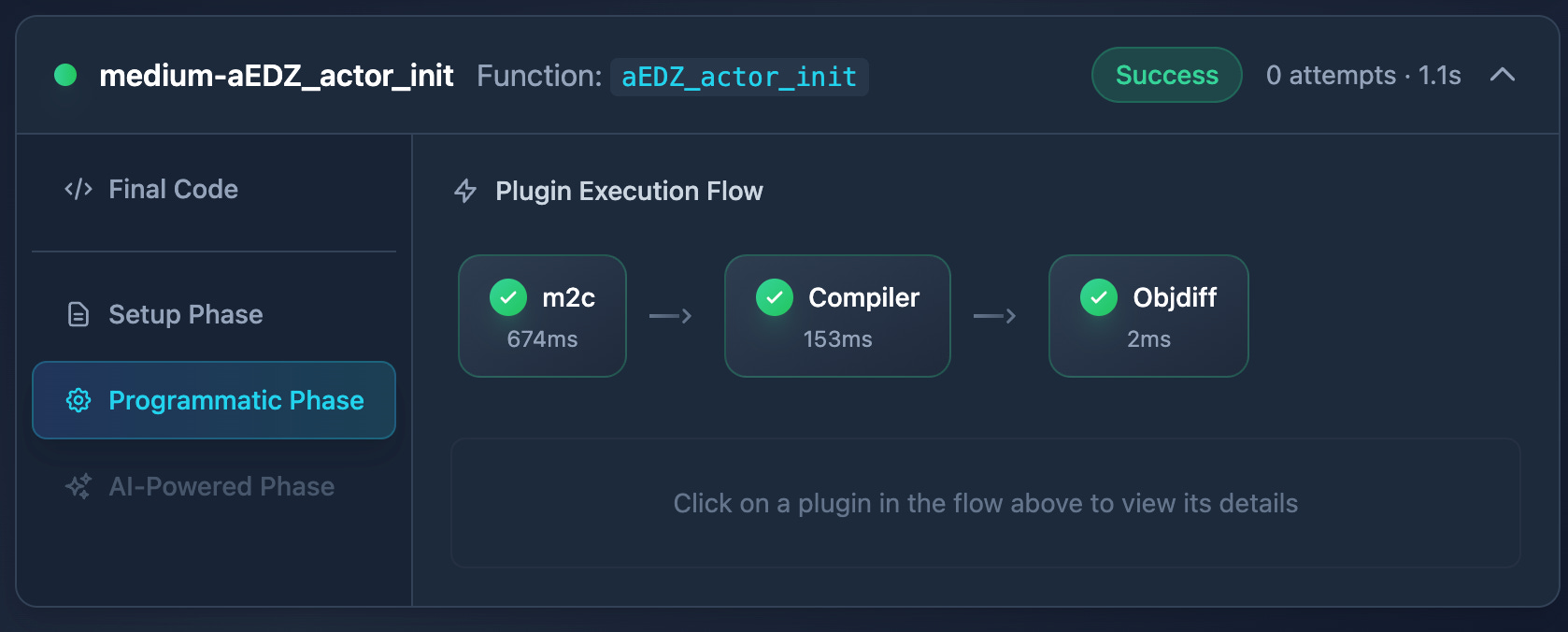
Since it's the most complex plugin and where most of the magic happens, I need to explain it in more detail.
The agent runs in a sandboxed mode. Claude cannot modify project files, build scripts, or configuration. It can only submit C code through the pipeline’s designated interface.
The agent includes an MCP tool to compile code and see the assembly, so it can play a bit before submitting an attempt. But to avoid it spending too much time just calling the tool without submitting an attempt, there is a configurable limit on tool calls per submission.
Also, there are three different time-outs:
Time-to-first-token (TTFT): how long it takes until we receive the first token from the server. After the first token is received, the timer for soft time-out and hard time-out starts. If no token is received, abort the session and start a new one on the next attempt.
Soft time-out: If Claude didn't submit an attempt within this timeframe, send a message asking to submit an answer now.
Hard time-out: If no answer is submitted, stop the session.
The specific values used for this benchmark are listed in the next section.
If an attempt fails, we submit a follow-up message to try again until the limit is reached. Every failed attempt counts, even if it was a TTFT time-out. The follow-up message includes the compiler error, objdiff result report, and, in the case of a hard timeout, a message saying to quickly submit an attempt.
For the benchmark report, I’m using two decomp projects in a specific version:
Sonic Advance 3 (SA3): Game Boy Advance game with 35.4% of the indexed functions decompiled 1
Animal Forest (AF): Nintendo 64 game compiled with IDO and with 24% of the indexed functions decompiled
I initially planned to test using SK2 instead of AF, but I replaced it because SK2 is a late-stage decompilation project with few easy functions to decompile. A good benchmark needs functions from easy to hard, and we can find those in SA3 and AF, but not in SK2.
Okay, now, how do you pick which functions to test? Let’s talk briefly about the function scoring algorithm. Mizuchi segments the functions into three percentiles: easy, medium, and hard.
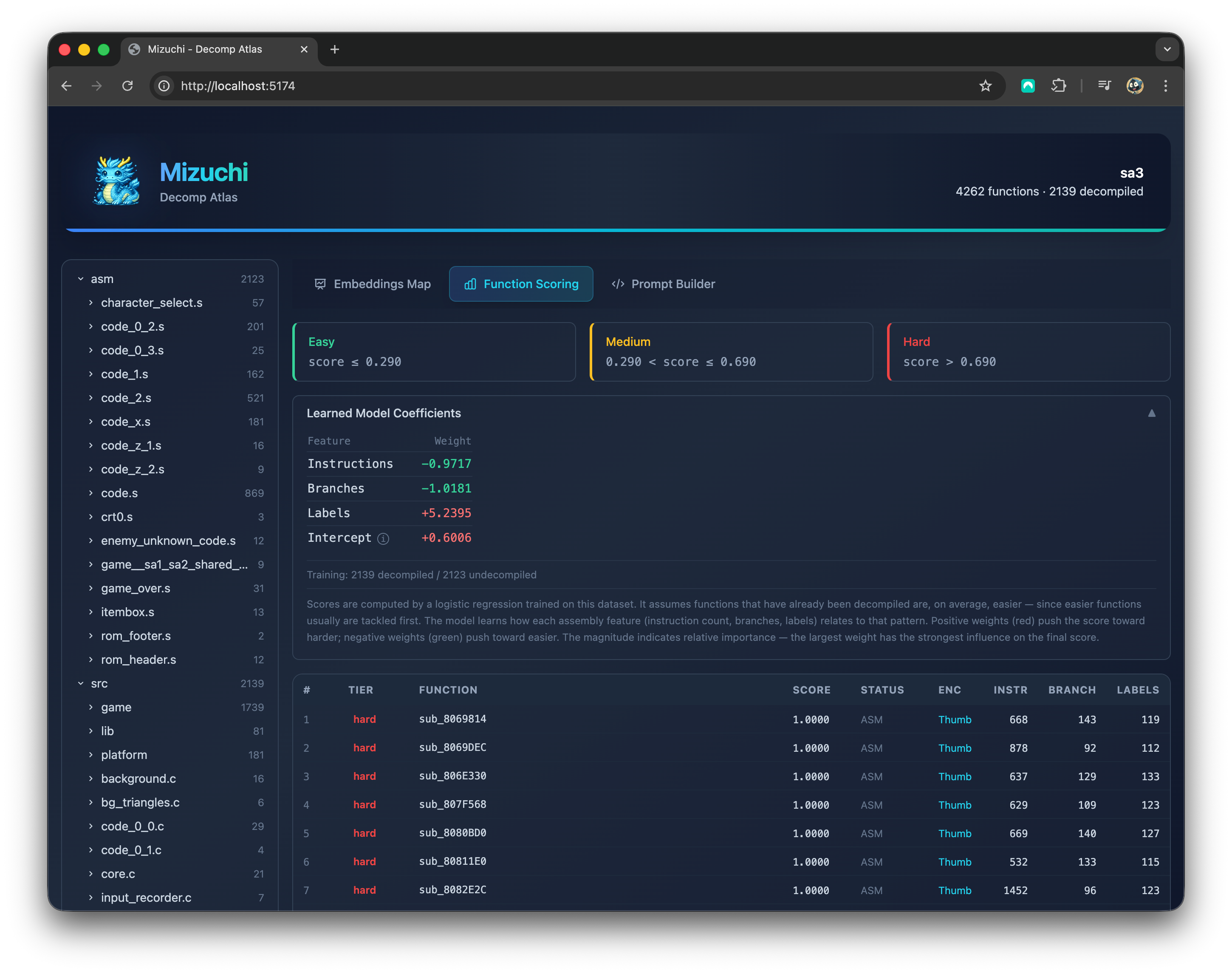
I started with the idea written by Lewis here and his code here. The scores are computed by a logistic regression trained on the project's codebase using a set of assembly features. It assumes functions that have already been decompiled are, on average, easier.
This scoring algorithm doesn't include two relevant characteristics that likely help AI and are included in the prompt: the number and proximity of the examples and the type definitions.
In any case, a perfect scoring algorithm isn’t needed. I’m only using it to select a well-distributed set of functions for the benchmark. So, I picked 10 from each percentile: 10 easy, 10 medium, and 10 hard. The total is 60 functions (30 from SA3 and 30 from AF).
I also reduced the scope for Mizuchi here. For SA3, I filtered to only Thumb functions, since m2c and agbcc (the GBA compiler) only work well for Thumb instructions. And for AF, I filtered to only the functions for which I could programmatically generate a valid context file using m2ctx.py.
Now that we’ve picked the functions, the next step is building a tailored prompt for each one. It's the system prompt used for each function.
The prompts used in the benchmark were crafted using Mizuchi, with code ported from Kappa. As explained in the previous chapter, the prompt builder includes
A general context for the task (the platform, architecture, goal)
Up to 5 examples from similar functions that have already been decompiled. The similarity is based on an embedded vector from the assembly code, using a normalized asm code and the jina-embeddings-v2-base-code model.
Signature of decompiled functions that call the target one.
C declaration of the target function.
Signature of the functions that are called by the target one.
Type definitions likely used by the target function.
In the benchmark, we want to evaluate
How well the programmatic tools (m2c + decomp permuter) can perform alone.
How well the LLM-powered tooling performs for this task in addition to the programmatic tools.
I’ll test using only Claude Sonnet 4.6.
I’ll run it 3 times per dataset to reduce the noise from the random-walk nature of LLMs.
For this benchmarking, I've set a limit of 12 attempts per function. It's a low number, but necessary because each attempt makes the run take longer, and I’m already burning many tokens on this experiment.
During the development, I noticed that some functions only pass after 20 attempts. Anecdotally, Lewis commented that one function required 87 attempts before Claude finally succeeded.
The time-outs are also very aggressive:
TTFT: 3 minutes.
Soft time-out: 7 minutes.
Hard time-out: 10 minutes (= 3 minutes to produce a final code after the soft time-out)
Still, I think these values are good enough for this benchmarking. It’ll evaluate a more adversarial scenario for the LLM, where we don’t have much budget.
You can check here the full Mizuchi code that was used to run this benchmark, including the prompts and settings for both SA3 and AF and the script to get the functions randomly per tier. You should be able to reproduce the benchmark on your own after cloning and setting up SA3 and AF. You can even tweak the settings if you’d like to. Mizuchi is highly configurable!
So, it’s all set! Let's run the pipeline.
It took ~10 days to produce the 6 benchmark runs with results I’m confident sharing. There were many small issues I only noticed after the fact, and I needed to discard everything and run it again.
Also, it’s worth mentioning that this benchmark isn’t evaluating the LLM in a vacuum. It’s running on top of Mizuchi and in a specific timeframe, so infrastructure issues from both Mizuchi and Anthropic might affect the results.
The most time-consuming issue was instability in the Claude service. I noticed that, sometimes, even when it's all green on their status page, the tokens per second are too low and we have timeouts.

The first two SA3 runs had significantly higher throughput than the 3rd. The first two runs had fewer timeouts and a higher match rate, though the overall function outcome (matched vs. not) was largely consistent. For AF, all benchmark runs used the same Mizuchi version and settings.
Because of the instability of the API, the 3rd SA3 run and all AF runs include additional safeguards, such as an explicit TTFT timeout that aborts and restarts on unresponsive API calls.
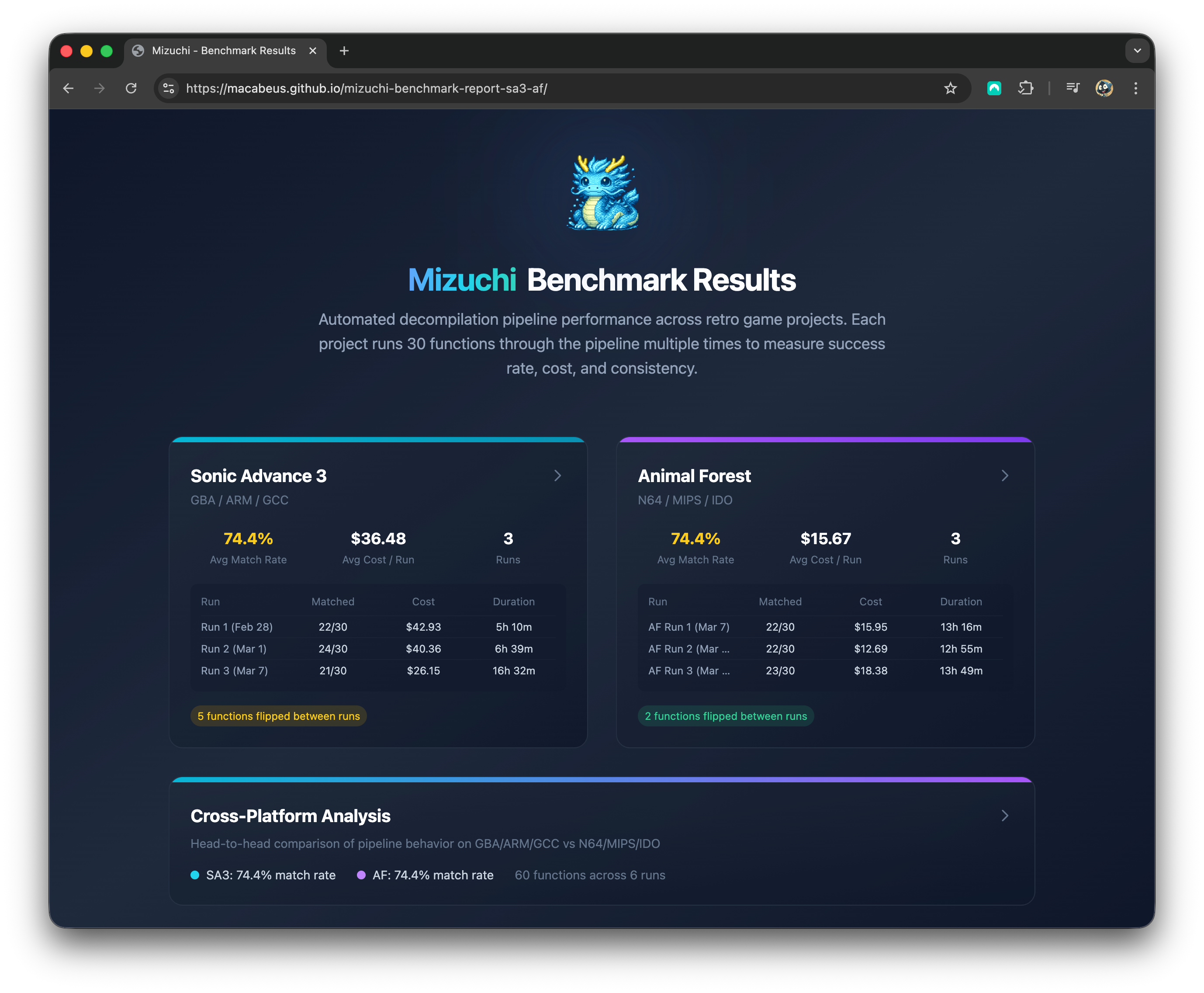
You can explore the full report on this webapp.
Check the full results in this repository.
Yay! It's all done now! A few highlights:
The SA3 Run 2 had the best success rate: 80% of the functions were matched. The average success rate across the 6 runs is 74%.
Permuter played well with the code generated by Claude on AF: it helped match 7 functions across the 3 runs.
The pipeline is very deterministic: 88% of the functions had identical outcomes across all runs.
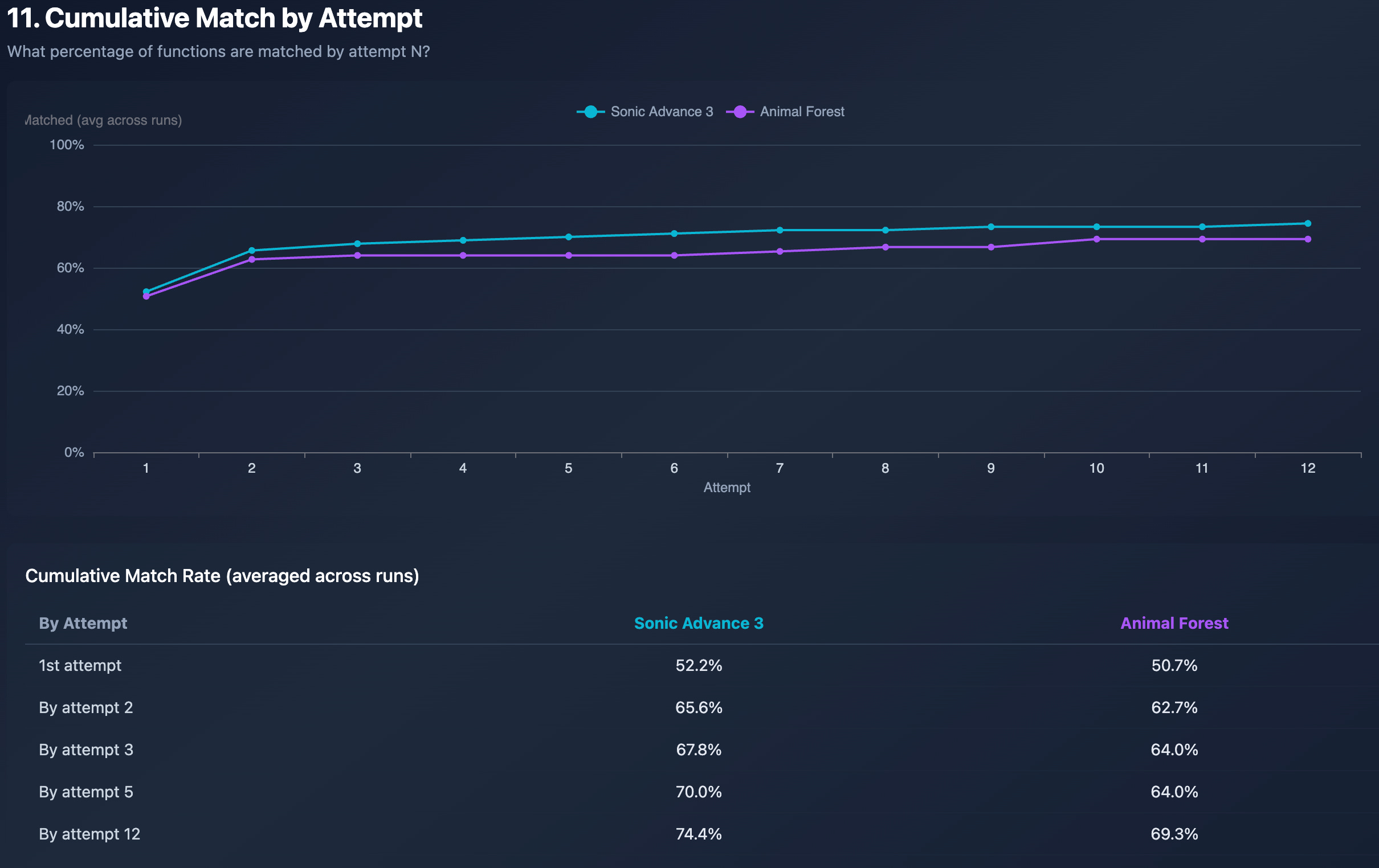
When the function still wasn’t matched in the Programmatic Phase, nearly half of the matches happened on the first attempt of the AI-Powered Phase. If a function isn’t matched by the 3rd attempt, the conditional probability of eventually matching drops to roughly one-quarter.
Curiously, there was exactly one case where a function matched at the 12th attempt. It was likely just an outlier of luck, since in the other runs it failed to match.
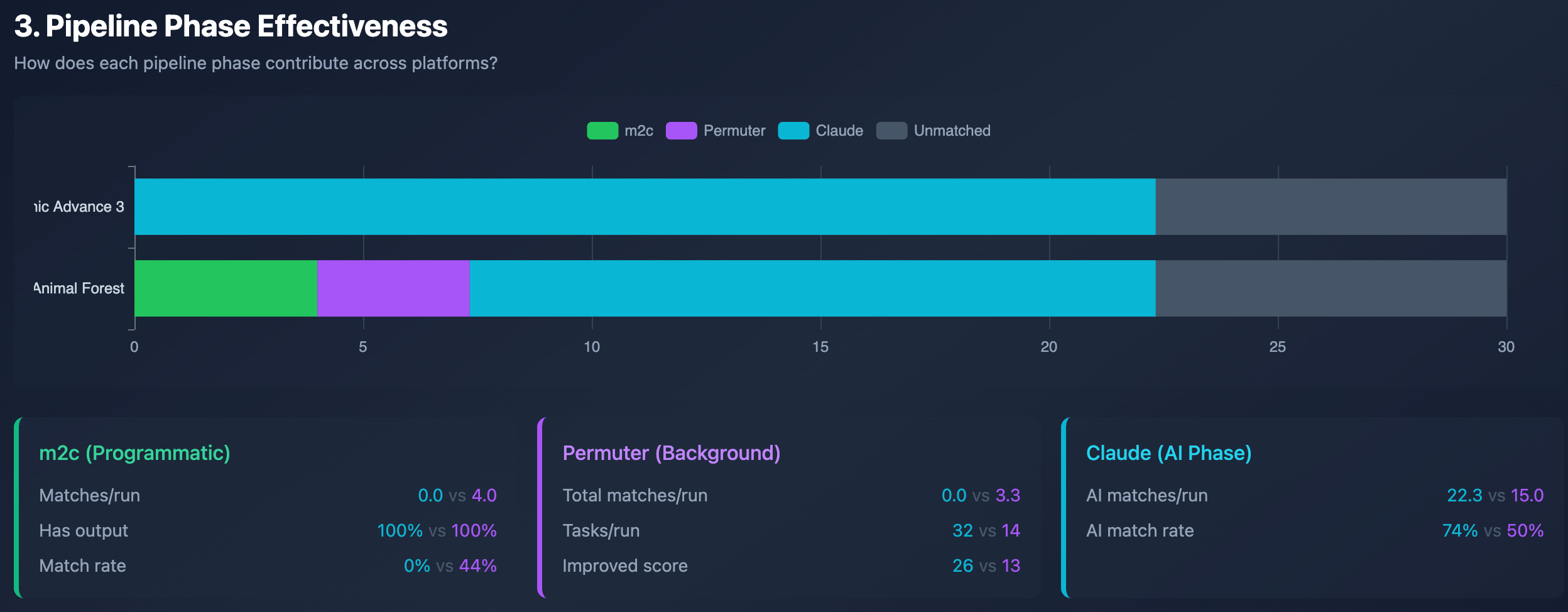
For SA3, no function was matched using only programmatic tools. AF was different. Permuter and m2c were great allies on AF! m2c produced matching code for 4 functions per run, and Permuter matched 3–4 functions per run.
Permuter likely worked better on AF because it was initially designed for IDO (the compiler used for AF). Although there are efforts to make it work with other compilers, IDO is still the one it works best with. It's likely the same reason for m2c: the support for ARM was released 6 months ago, so it isn't as mature as the support for IDO.
Permuter mostly found matches using the code generated by Claude. The only exception is func_808D6BAC_jp, where it found the match still in the Programmatic Phase, using the m2c code as the base. Curiously, in Run 1 and Run 3, Permuter helped to match the function func_808D6BAC_jp while in Run 2, no match was achieved for this function.
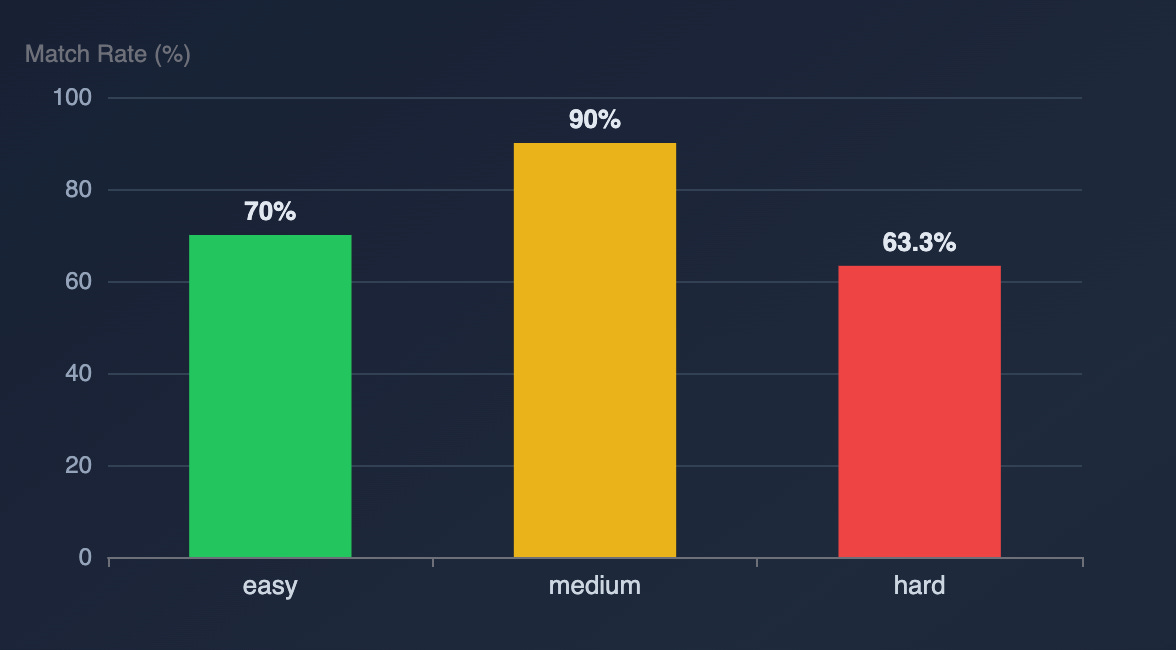
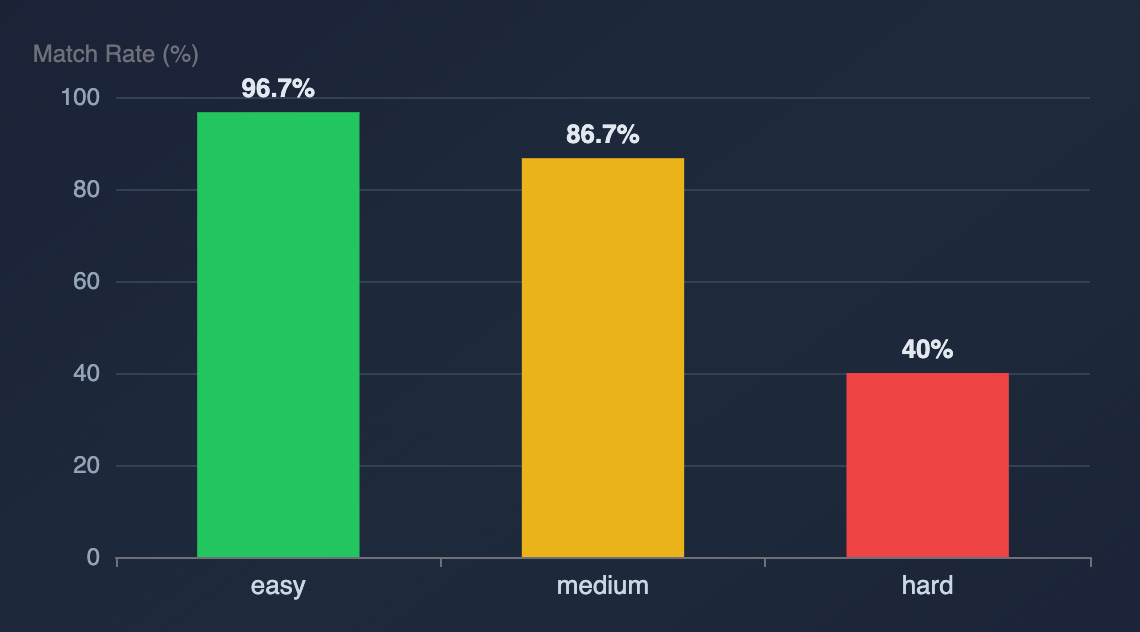
I also tried to check whether the scoring mechanism that splits functions into three tiers (easy/medium/hard) really offered predictability.
It worked well for AF: the easy functions matched more than the medium ones, which, in turn, matched more than the hard ones.
On the other hand, it didn't work well for SA3. The medium functions matched more than the easy ones.
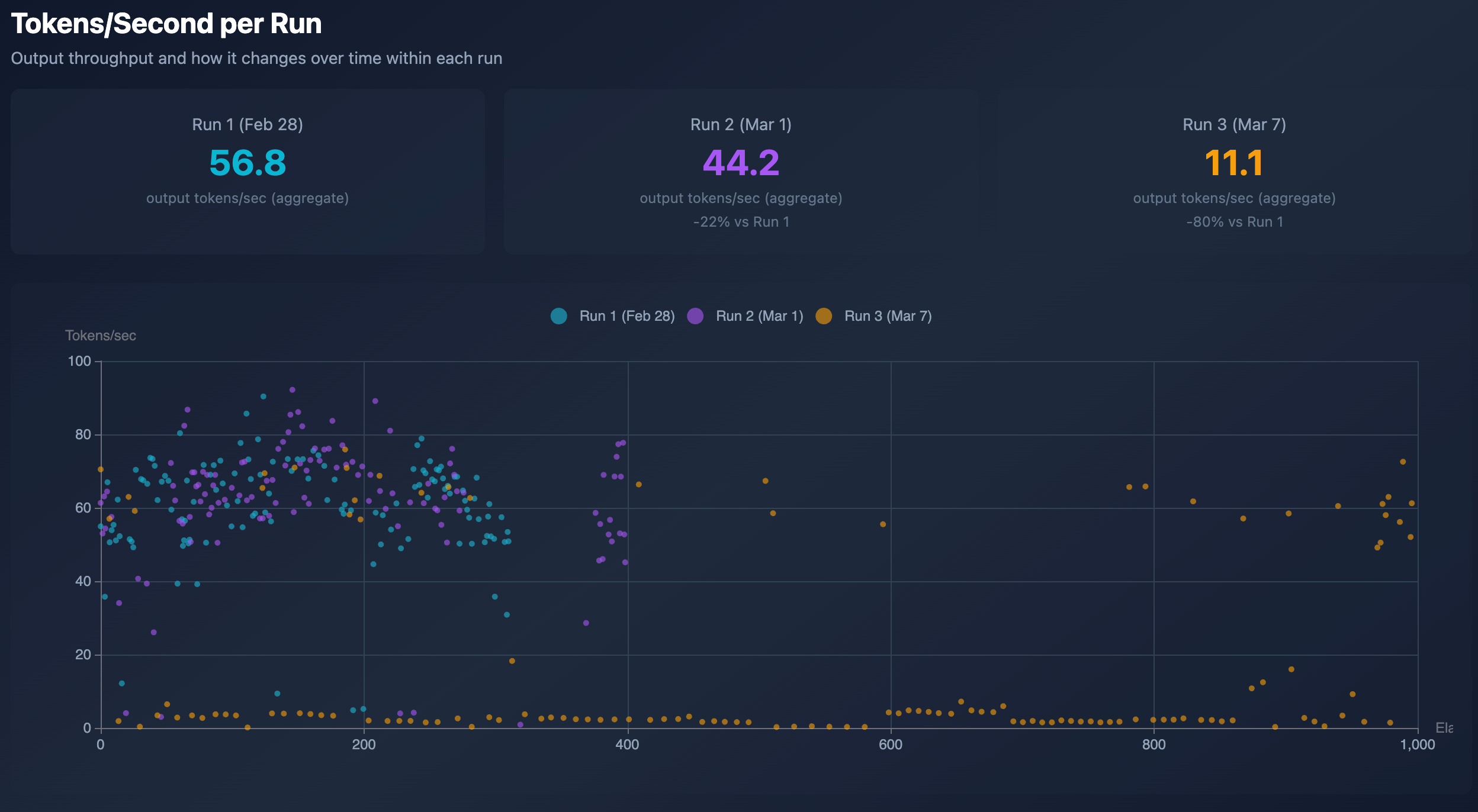
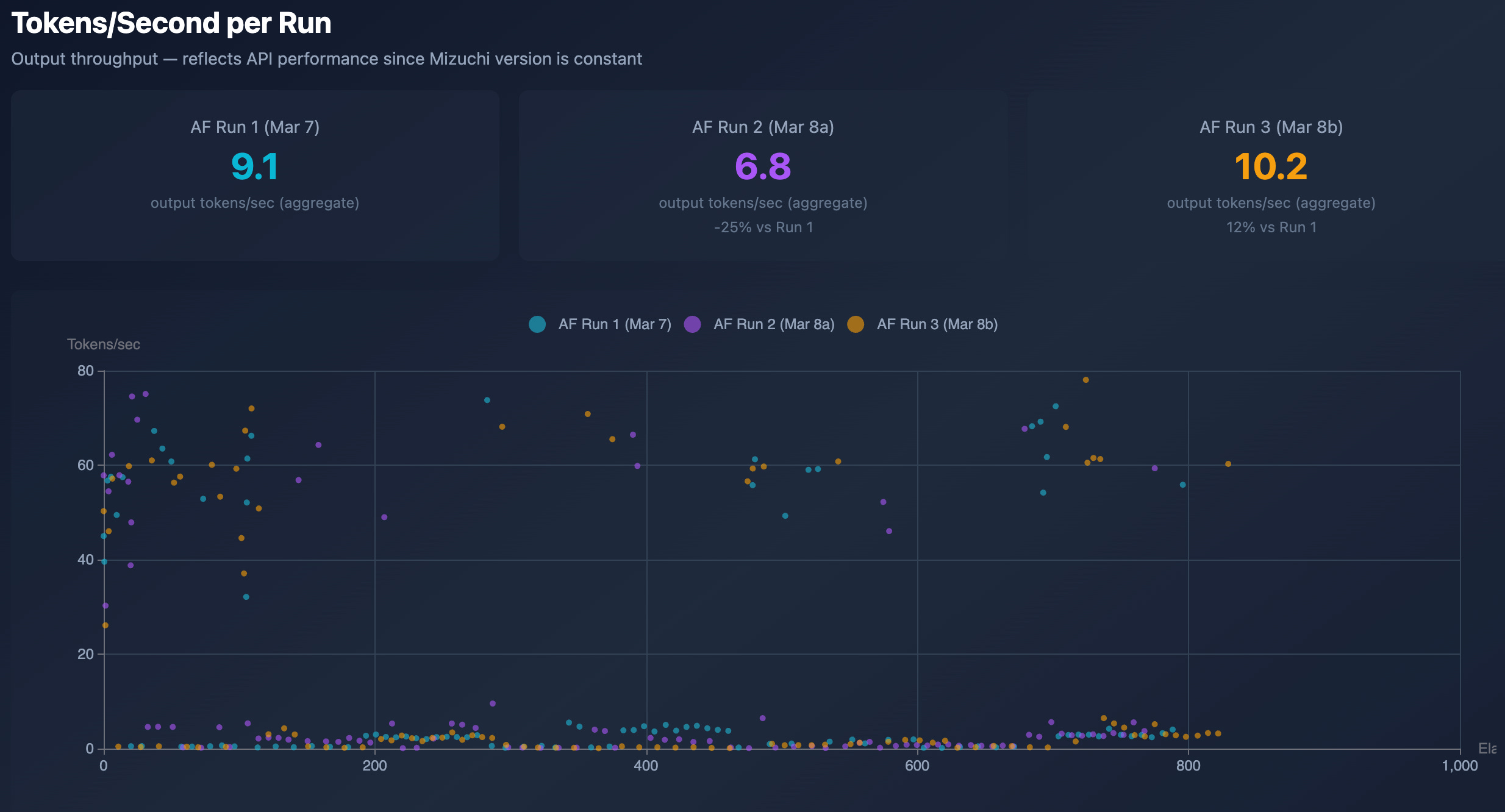
As you can see, the first 2 SA3 runs are way faster than the 3rd SA3 run and all AF runs. It’s likely not from my side but something Anthropic changed in their model or an infrastructure change on their end, since my dataset and environment are the same.
The first two runs had a much lower average attempt count and fewer timeouts. It happened because of an API latency degradation: throughput dropped from 57 tokens/second to 11 tokens/second (5x), causing 95 soft timeouts that cascaded into 59 compile failures, since code produced under soft-timeout pressure usually has compilation errors.
In the latest run for SA3 and in all runs for AF, we had timeouts on hard functions. In some cases, they were severe, producing no useful output, as happened with sub_80720E4 on SA3. TTFT within 3 minutes as a timeout and 10 minutes for a hard timeout might be too small for very complex functions.
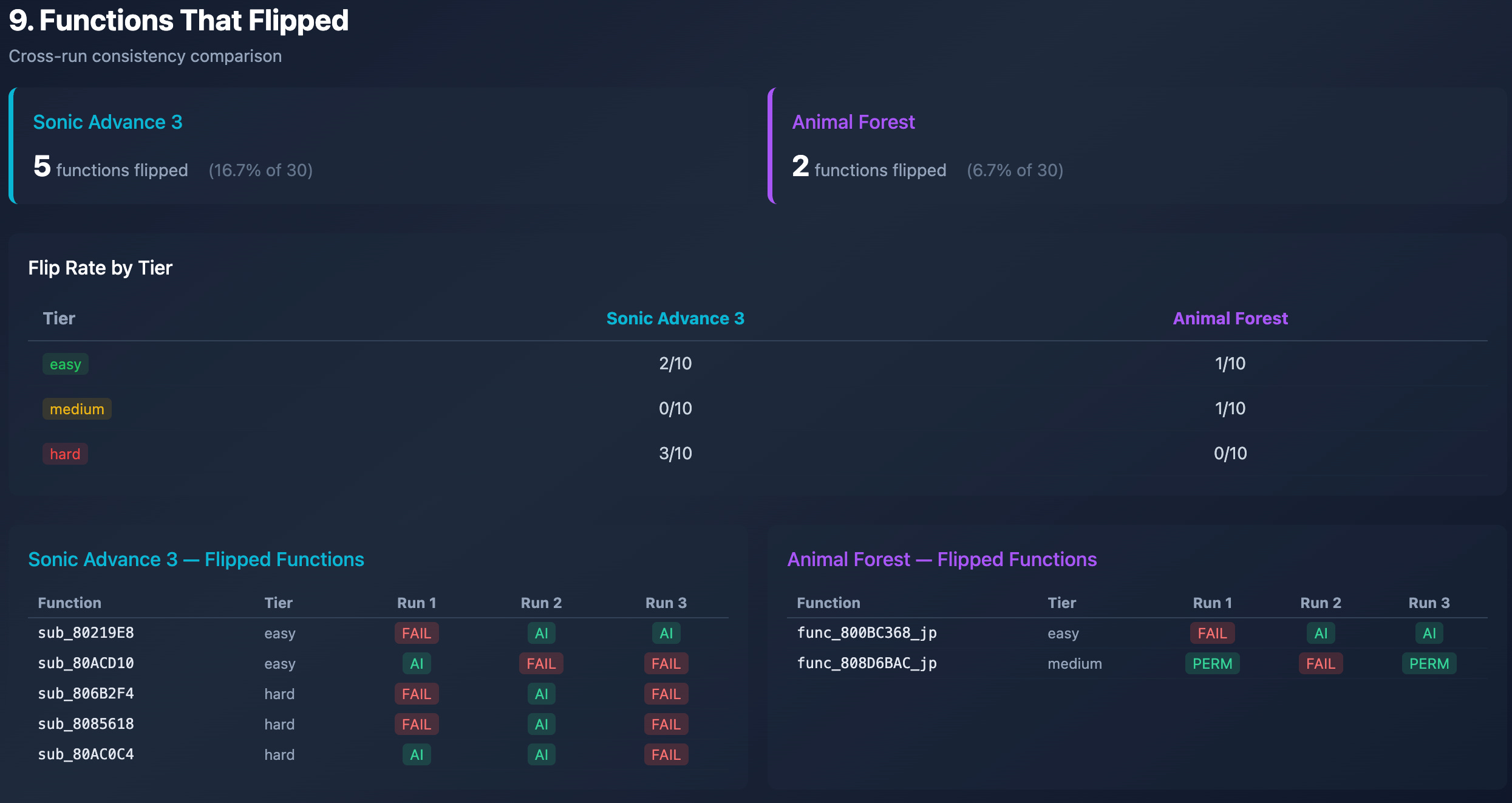
In most cases, the result per function is stable per run. A function that matches in one run will typically match in the others, and vice versa. Still, there are curious cases where flips happen. There were 5 functions that flipped on SA3 and only 2 functions that flipped on AF.
More flipped functions on SA3 are expected, since the tok/s drop only affected the last run. For example, the function sub_8085618 on SA3 failed to match only in the last run, likely because of the low tok/s that repeatedly triggered the soft timeout.
So, to compare stability between runs, we can rely more on AF, and it’s mostly stable, since only two functions flipped: func_800BC368_jp matched only in Run 2 on the first attempt and in Run 3 on the 7th attempt, while func_808D6BAC_jp matched only when Permuter found the match.
In the end, we can conclude that the pipeline is very deterministic! 53 of the 60 functions (88%) had identical outcomes across all three runs. The LLM’s randomness affects mostly the attempt count and path, but not the outcome.
We have 12 functions that always fail (5 on SA3 + 7 on AF). These functions are the frontier. That's what we need to solve to have a fully automated decompilation flow.
In some cases, it was purely timeouts, but in other cases, Claude still returned compilable code but could not find a perfect match. These always-failing functions point to specific areas where Mizuchi can improve.
A key decision early in the project was outputting detailed benchmark reports in JSON, since it allowed me to feed them to Claude Code and ask it to analyze, explain, and provide insights.
It helped me a lot during development. For example, limiting the number of tool calls to ‘compile and verify’ and adding a soft timeout were proposed by Claude Code after reading the reports. Claude Code helped both identify room for improvement and address these issues, then verified from a new report whether the fixes worked.
Still, there are many other improvements that can be made to Mizuchi. Some of them:

Currently, we have only the tool compile_and_view_assembly. There is no way for the agent to run objdiff before submitting the attempt. The agent does its best to compute the diff, but frequently it wrongly assumes there is a perfect match when there isn’t.
Thus, I think it would be a good improvement to add the capability to see the diff, maybe on this same MCP tool.
After 3 attempts without an improvement, it triggers a stall detection. But for now, the only action is appending a message to the prompt saying to think deeper and reminding it of the last best attempt.
It doesn't do much. It needs a better strategy, like switching to a smarter model, giving more time to think, or even giving up early to save tokens.
Sometimes, Claude is stubborn and submits the same code. After analyzing the logs, it happened 49 times.
For example, in AF Run 2, when working on func_808D6BAC_jp, attempts 2–5, 7, and 9-12 were identical to attempt 1. The soft timeout likely contributed to this behavior.
Maybe asking to submit slightly different code after detecting a duplicate would help avoid this kind of issue.
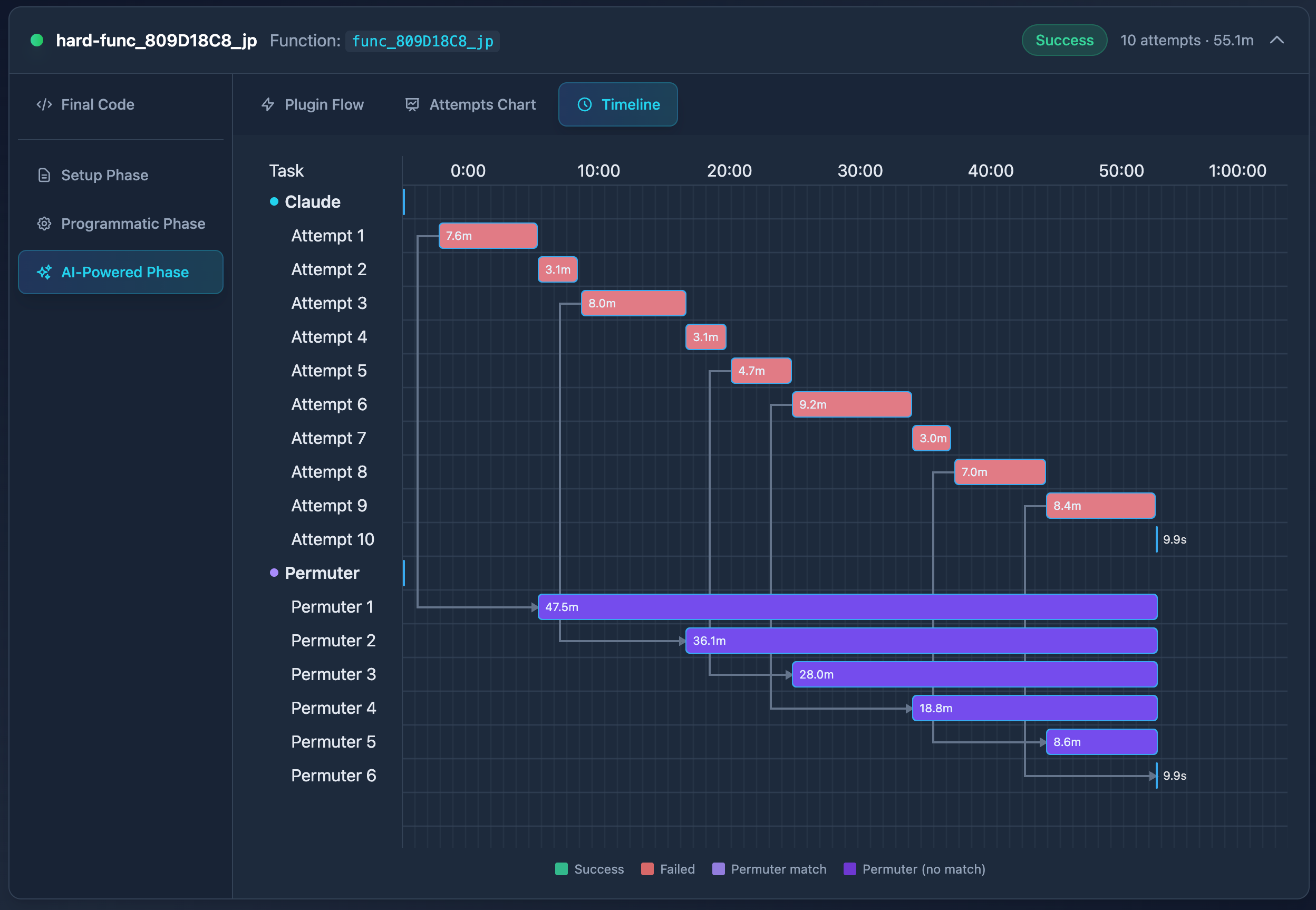
The result from the background Permuter Plugin is used in the AI-Powered Phase when it finds a perfect match.
It might be wise to feed it to Claude if it found a much better result than what Claude is working with. But we need to be cautious here, since, as explained in the 4th post by Chris Lewis, Permuter leads to introducing artifacts as signals, leading Claude to optimize around the noise, ending in a doom loop of wasteful tokens.
Currently, the AI-Powered Phase asks for perfectly matching code and semantic C code. It might be too much work to do in a single phase!
We can split it into two phases: one to only find a perfect match as quickly as possible, and a second phase to refine code quality.
But it’ll likely need an alignment, since the LLM might game the system by using bad artifacts, such as asm() calls in the C code, only to bypass the system. Still, I think it’s an interesting approach worth trying.
Anthropic offers powerful models for coding, but they’re not the only provider. We can even have a model tailored for matching decompilation, as Theo did a proof of concept in this post.
Mizuchi will be handy for benchmarking different providers!
There are many ideas besides the above ones, like:
Running the pipelines in parallel (Issue #32)
MCP Tool to read and analyze the report files (Issue #31)
Write the match to the project (Issue #5)
Better compilation errors (Issue #29)
It's a fun and endless project!
Before concluding, let me address two more topics.
I think I’m obliged to answer this question somewhere in this post.
There are other tools that aim to automate tasks using LLMs, such as Ralph and OpenClaw.
The most significant difference is that Mizuchi isn't for AI. In the context of Mizuchi, AI is a plugin among many other plugins. Yes, it's the most important plugin, but Mizuchi can live without it!
Also, at least for now, Mizuchi is tailored for matching decompilation, and we have a specific flow when working with matching decompilation: a clear input and a clear outcome, easy to verify and track the progress programmatically. That’s usually not the case for many LLM tasks, where the outcome is blurry.
So, in short, Mizuchi is a specific tool for a well-defined task that may use an LLM, while Ralph and OpenClaw are versatile tools powered by LLMs.
I’m focusing on matching decompilation because that’s the challenge that nerd-sniped me.2
On the other hand, there are many gaming decompilation projects that don't have such strict constraints imposed by the “matching” part. These other reverse engineering projects try to decompile into functionally equivalent code. That's the case for this project for Crimsonland, for example.
But what if Mizuchi supported functionally equivalent decompilation? What if it allowed us to automatically decompile code and check programmatically whether the code is equivalent to the target?
Mizuchi’s plugin architecture makes it feasible, and I’ve been planning to make it real! But that’s a topic for its own post.
So, answering the question from the introduction: Yes, the data show that LLMs can work very well on matching decompilation for retro games! With a 74% average match rate across two platforms, the data suggest LLM-powered decompilation is not just viable but highly effective for the majority of functions.
Of course, there are some caveats. It’s a small sample size with aggressive timeouts. Still, as far as I know, it’s the very first benchmark evaluating LLM performance on matching decompilation using real, in-progress matching decompilation projects. I believe this data offers a baseline for further refinements to this approach. Now, it’s clearer what should be improved and, more importantly, how to measure improvement.
This result is further evidence of what other folks, like Lewis, have been showing in real projects. I hope to see even more people engaging with it!
And more importantly, at least for me, I’ll certainly use Mizuchi when I start to decompile Klonoa: Empire of Dreams! And that’s the topic for the upcoming main chapter: let’s apply the tooling and knowledge we’ve been building over the last few chapters to a new matching decompilation project.
But first... my paragraph about supporting other types of decompilation projects is nerd-sniping me... Let's make a short detour before!
Fable 5: Does the smartest LLM decompile better?

We have a new model that everyone is talking about: Fable 5. Within the matching decompilation community, there are mixed opinions about it. Some say it’s too expensive for little to no gain, while others say that it’s very helpful on the hardest functions.