1
Previous version of the guide:
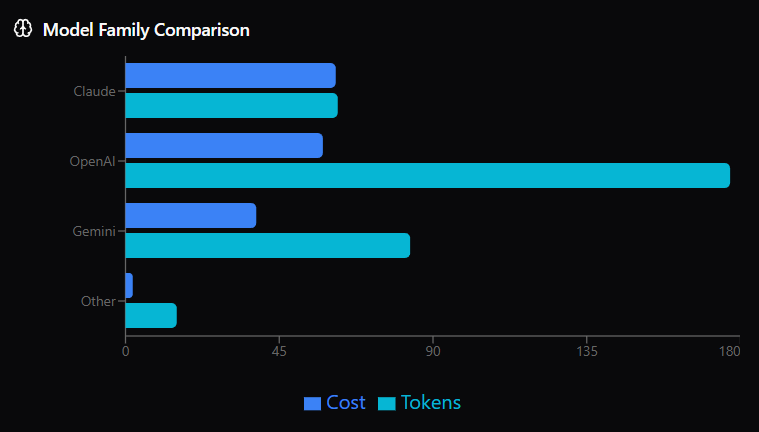
My current stack:
Opus 4.5 $$> GPT-5.1 High >= GPT-5.1 Codex Max XHigh >?$ Gemini 3 Pro Preview $$>> GPT-5 Mini $>=$ Grok Code Fast
A Brief on Each Main Model
Opus 4.5
- Works with the provided context more deeply than any other model, which is especially noticeable when working with documentation.
- I like the communication style of the Claude family.
- Many times more expensive than other models. I recommend it for teams with huge budgets.
Extrapolating from my usage, it can cost up to 5,000 USD/month for single-threaded agent coding. - For others, it’s best for one-off use during important documentation edits or when planning refactorings.
- On large files/projects, you might find that it greedily fills its context window, which can overflow quite quickly and frequently, leading to its compression and potentially worsening the output quality.
Gemini 3 Pro Preview
- Beats everyone in all benchmarks, except for Opus 4.5;
on some, Opus 4.5 is slightly better. - Cheaper than Opus 4.5.
- It’s chaotic, which makes it difficult to rely on as a primary model.
- Initially, it had problems interacting with files correctly: it would delete files in a way that they could only be restored via
git revert(undoing actions in the Agent Chat did not undo the file deletion).

My usage for 30 days by cursortokens.vercel.app
GPT-5.1 High
- You can ignore the other sub-versions – you won’t gain anything from dumbing down the model.
- An excellent, stable, cheap, and smart model.
- GPT-5.1 has become a bit “warmer” compared to GPT-5, making it more pleasant to communicate with and read its reports.
- There are rumors about the imminent release of GPT-5.2: the improvement is unlikely to be significant – the main thing is that they don’t mess it up.
GPT-5.1 Codex Max Extra High (Codex Max XHigh)
- I absolutely dislike GPT-5 Codex and GPT-5.1 Codex.
It’s said that they are noticeably better in the Codex CLI than in Cursor. In Cursor, they are too chaotic, and I didn’t even try to tame them.
I tried GPT-5.1 Codex Mini High as a potential replacement for GPT-5 Mini, but it didn’t work out. - Codex Max XHigh turned out to be a pretty pleasant and stable model.
- It fills its context very economically.
- You can forget about the bunch of sub-versions with different “thinking” levels – you’re choosing this model for complex tasks and you want it to solve them.
- Thanks to its economy, power, and speed, it can be considered an ideal model for simple tasks.
- Free until December 11th; afterwards, its cost will be roughly equal to GPT-5.1 High.
- I’m not sure if I’ll keep it as my main model after the promo week, but you can compare the performance of 5.1 Codex Max and the regular GPT-5.1 on your own tasks and prompting style.
- Gemini 3 Pro Preview assesses its work with documentation in the Chat as that of a terse tech lead – overall, I agree.
- Due to its economy, it “thinks” very little – a good option to get a quick answer from a reasonably smart model, but you might not like its style and brevity.


GPT-5 Mini / Grok Code Fast
- Two cheap models for simple tasks: searching the repository (talking to the repository), minor edits.
- Mini is slightly smarter, GCF is slightly faster.
- GCF is free, a big thanks to Elon Musk for that.
- Below is the answer to why they shouldn’t be used for all tasks:

An attempt to complete a list of tasks with GCF; a rollback; a successful attempt with GPT-5. It’s clear that GCF managed to generate far more tokens than GPT-5 but failed to complete the task, even though it was given more time and additional hints from the developer.
Other Models
Claude Sonnet 4.5
- It’s not that much smarter than GPT-5.1 to justify its higher price. Gemini 3 Pro is comparable or also slightly cheaper.
- Can be used as a budget alternative to Opus 4.5.
- Excellent for QA.
Claude Haiku 4.5
More expensive and dumber than GPT-5.1. If you need Claude, use Sonnet or Opus.
GPT-5 Pro
Brains on par with GPT-5.1 with a 10x markup.
Grok
- Grok 4: Has been working poorly in Cursor IDE since its release.
- Grok 4 Fast: A very lazy model. Again, possibly due to Cursor and not because the model itself is bad.
- Grok 4.1: Not available in Cursor. I hope Grok 4.2 will be added upon release and will work better than Grok 4.
Chinese Models
- Kimi K2: Since its release, the display of its responses in the chat has been broken; they provide an outdated version of the model out of the box.
- DeepSeek: DeepSeek-V3.2, which could be considered a model for simple tasks, is not available out of the box; the others are already outdated.
Composer 1
A proprietary model from the Cursor IDE developers. I only tried it during open testing. In my experience, it feels dumber than GPT-5 at a slightly higher cost.
Additional Materials
I recommend working in Cursor IDE with my Agent Compass in your User Rules - it’s a set of rules for user-AI interaction that assigns roles to both parties. I will be updating it soon and will add my prompting recommendations to the repository. I can’t say when this “soon” will be yet ![]()
Artemonim (Artemonim) 2
- I tried GPT-5.2 - GPT-5.2 XHigh is remarkable.
- I tried Codex CLI as an extension in Cursor:
-
- I have the feeling that thanks to more convenient context engineering, tasks are solved faster through Cursor Agent. Simply because in Codex it’s always links, while in Cursor at least some of the files are immediately sent to the context,
-
- and besides, you can immediately specify individual fragments of files.
-
- The UI is significantly less convenient and visually understandable than Cursor Chat.
Per_Jonsberg (Per Jonsberg) 3
Thanks a lot, really appreciate this guide!!
Artemonim (Artemonim) 4
Use Codex CLI only if you have no money for Cursor Ultra but plenty of time. It aggressively cuts context and the set or quality of tools is worse than Cursor Agent. I haven’t tested it on identical tasks, but I’m confident that in Cursor GPT-5.2 XHigh would have taken less time to complete the same tasks.
The Codex CLI is probably better for regular Codex models, but if you’re using Codex Max XHigh — it works great in Cursor Agent Chat.
Artemonim (Artemonim) 5
My current stack:
GPT-5.2 XHigh > GPT-5.1 Codex Max XHigh $>> GPT-5 Mini >= Grok Code Fast
Naufaldi_Rafif (Naufaldi Rafif) 6
Why you not trying Gemini 3 Flash? That fast, cheap and also more intelegence base on my experience
Artemonim (Artemonim)
7
I tried two or three times, and the result was disappointing.
Below is a screenshot of the last attempt. Working with the interface. The first simple request was handled by Gemini 3 Flash, but when a more complex menu was needed, even GPT-5.2 XHigh didn’t do it perfectly (Codex Max try was also rolled back), but it understood me better than the others.
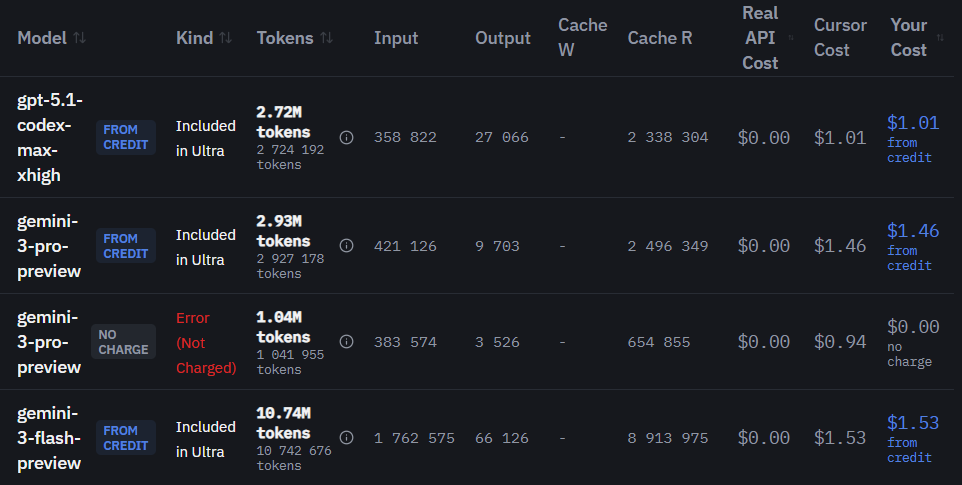
Gemini 3 Pro lost the connection on the first attempt, and on the second attempt it entered a loop.

Artemonim (Artemonim)
8

Have you tried GPT‑5.1 Codex mini (high)? Is it any good?
DemonVN 10
only use Claude Sonnet/Opus thinking model belike
Try auto-mode-model, i just notice it quite good now compare to before. Maybe because we have to pay it cost now ![]()
Artemonim (Artemonim) 12
I don’t like the entire Codex line except for the GPT-5.1 Codex Max XHigh.
Artemonim (Artemonim) 13
I’m currently working on a project in Rust. It’s a personal project in the alpha stage, so I’m dedicating specific phases to increasing test coverage, because calculating code coverage takes five times longer than a regular CI run.
- GPT-5.2 XHigh: main developer
- GPT-5.1 Codex Max XHigh: for fast and simple tasks
- GPT-5.2 Codex: test writer
- Gemini 3 Pro/Flash: for discussions and chatter in Ai Studio without project context
I tried Cursor’s GPT-5.2 XHigh and GPT-5.1 Codex Max XHigh for writing tests – and I got the feeling I’d spend more money on tests than on the code itself.
So, if you work a lot and also allocate test coverage to separate tasks, I recommend buying Cursor Ultra for main work and the $20 plan for Codex or Claude Code for additional or monotonous work. And in addition, Codex 5.2 is currently only available on Codex.
GPT-5.2 XHigh through Cursor is noticeably faster than through Codex, and it also resets the context less often and is easier to manage. If you have a Claude subscription, compare the speed of Claude’s performance in its CLI and in Cursor.