Kalosm 0.3: Derive Parsers, Streaming Transcription, Improved Performance, and More!
Kalosm 0.3 makes it significantly easier to use structured generation, improves transcription, and makes it possible to track model download progress. It also includes performance improvements for text generation and transcription models along with parser improvements
LLM Performance Improvements
The new version of Kalosm includes significant performance improvements for llama, mistral, and phi models. Performance should be between 2-4x as fast depending on your use case. Here is llama 8b chat running on a M2 Macbook Pro:
Sampler Aware Structured Generation
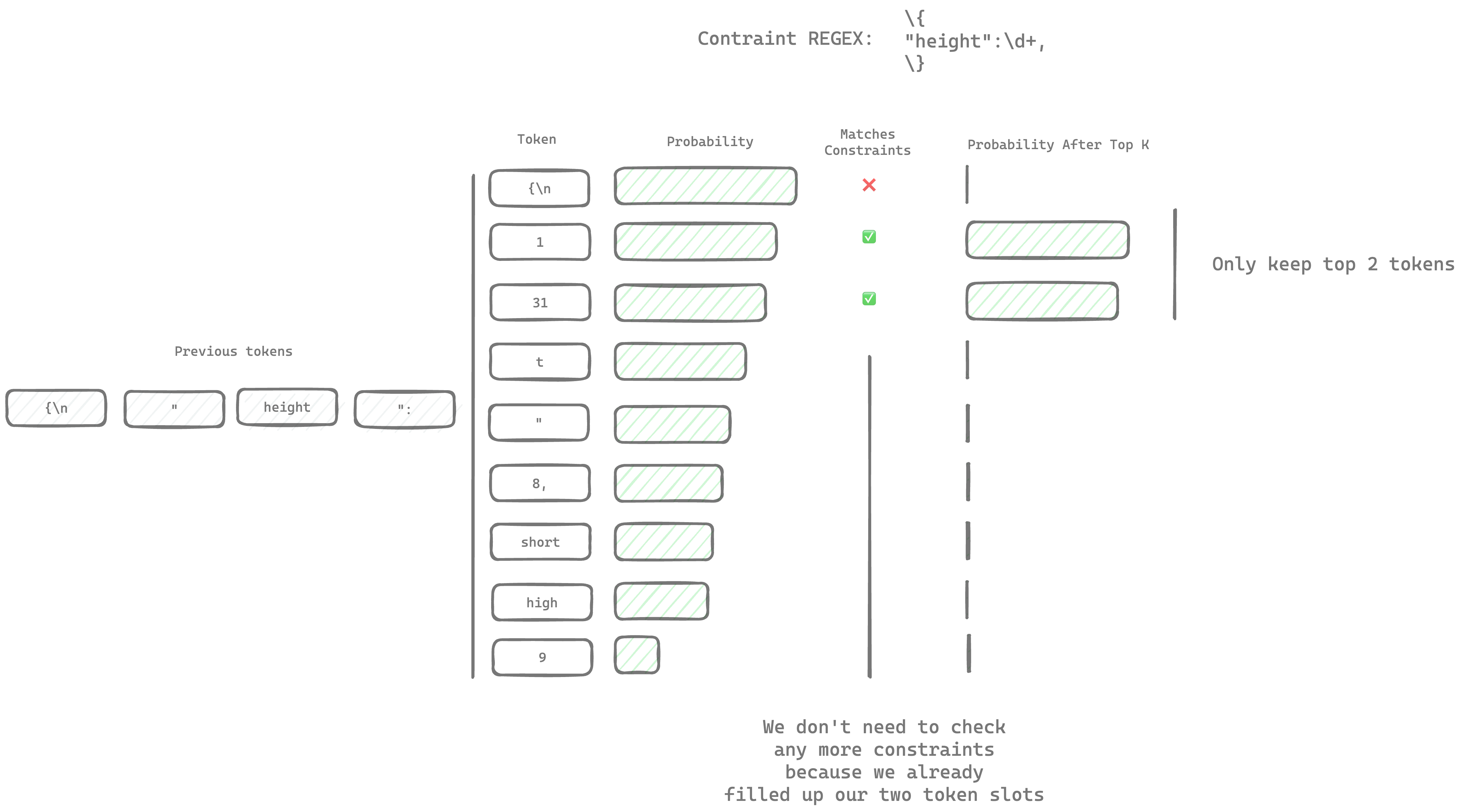
The simplest form of structured generation runs a parser 128,000 times, once for each possible new token. This generally isn't an issue for simple grammars like REGEX because each new token is only a lookup away, but it can be slow for more complex parsers. Kalosm 0.3 introduces a new optimization called sampler aware constrained generation: Instead of parsing every token, we can use the sampler to skip parsing unlikely tokens.
There are generally a few steps between the token probabilities after constraints and the token that gets chosen. Each of those steps that modify the probabilities of the tokens is called a sampler. The top-k sampler is one of the most common samplers. It only samples the top k most likely tokens. Here is what that could look like if we only keep the top 2 tokens (where k=2):

Generally, k is larger, but much smaller than the number of tokens in the model. The default in kalosm is 64.
Instead of parsing every token, we can skip parsing tokens once we find the most probable k tokens. Since the LLM knows about the constraints, the valid tokens tend to have a very high probability so we can skip parsing the majority of the 128,000 tokens.
With the new version of Kalosm, loose constraints add almost no overhead to the generation process. Combined with static section acceleration, structured generation is often faster than unconstrained generation. Here is phi-3.5-mini running on a M2 Macbook Pro:
You can read more about how structured generation works in kalosm in our last blog post.
Structured Generation Improvements
Structured generation is also much easier to use in 0.3. Many structured generation tasks can use JSON. If you just need a JSON parser, kalosm 0.3 lets you derive the parser from your data:
Then you can build a task that generates the structure you defined:
Along with the parser, you can also derive a JSON schema that matches the parser which is useful for function calling models.
Streaming Voice Transcription
Kalosm 0.3 adds support for transcribing an audio stream in chunks based on voice activity. You can now read the audio stream directly from the microphone and transcribe it as voices are detected:
Model Progress
Loading models is now async with a callback for loading progress:
Whisper transcriptions and Wuerstchen image generations are also async with progress info thanks to @newfla:
Documentation improvements
The inline documentation has been significantly improved in 0.3. Common items now include inline guides to help you get started like the language page and concept explanations like embeddings
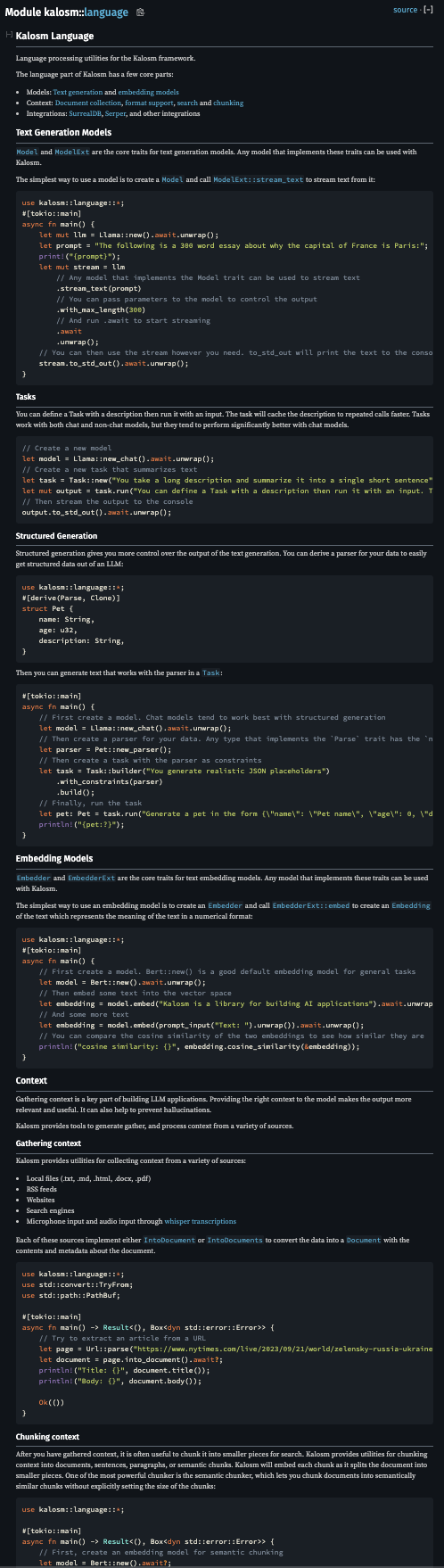
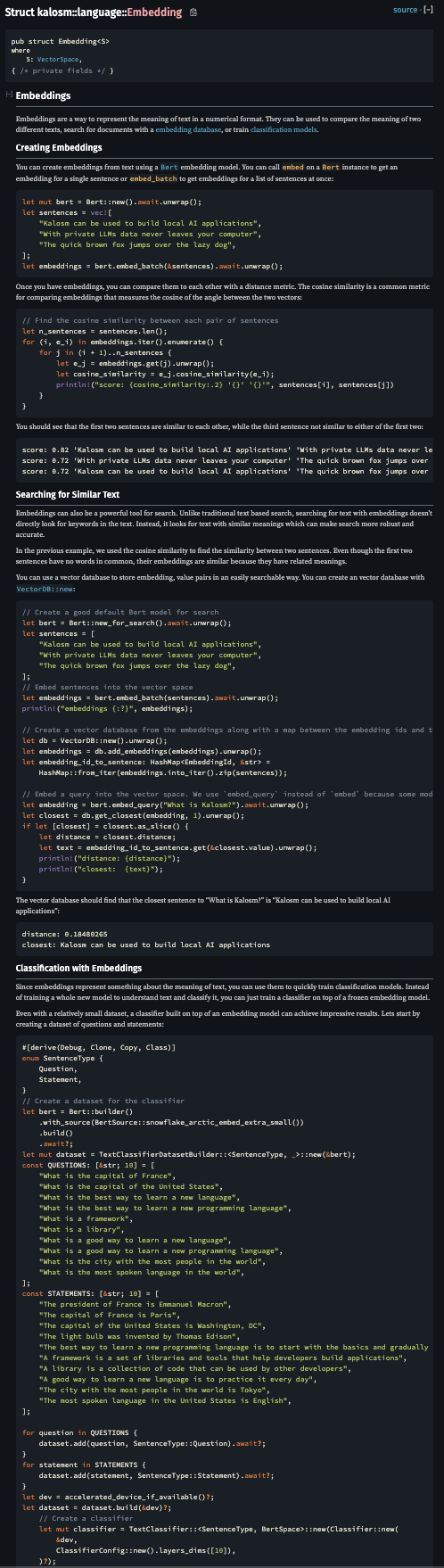
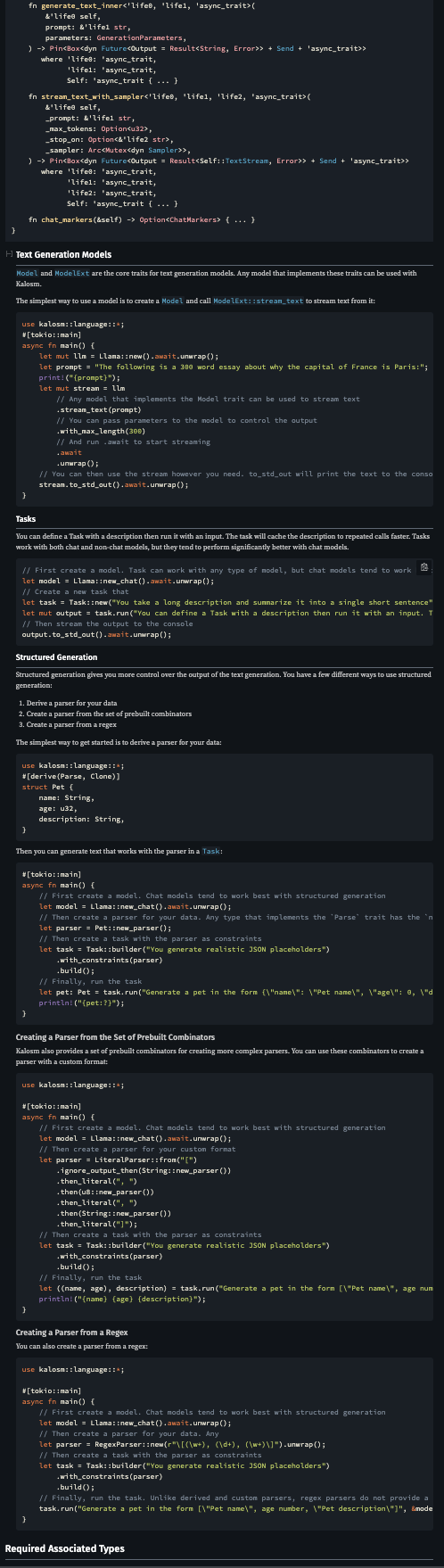
New models!
Along with the new release, kalosm supports a few new models:
- Quantized whisper models are now supported with presets for distilled versions of whisper to run even faster
- The Phi-3 series of models is supported by
kalosm-llama. The Phi series performs above its weight for structured JSON generation tasks
New Contributors
- @KerfuffleV2 made their first contribution in #77
- @haoxins made their first contribution in #86
- @Yevgnen made their first contribution in #93
- @dependabot made their first contribution in #156
- @newfla made their first contribution in #165
- @LafCorentin made their first contribution in #166
- @eltociear made their first contribution in #249