A few months ago I built yolobox because I did not trust Claude Code with my home directory.
The original problem was simple. AI coding agents are most useful when you let them run commands without asking. That is also when they are most likely to misread a prompt, decide the cleanest path forward involves rm -rf, and convert your laptop into a learning experience. So I put the agent in a container. Project mounted at its real path, sudo inside the box, home directory nowhere in sight. The agent could go full send. My dotfiles stayed where I left them.
It turned out a lot of other people had the same problem. yolobox is past 500 stars on GitHub, and a steady trickle of issues and PRs has shown up from people who had also lived through some version of “the agent did what to my home directory.” So I kept piling on the conveniences a sandboxed agent actually needs to do real work - forwarded SSH agent, a clipboard bridge, GitHub auth, opt-in config sync, project-level Dockerfile fragments, a runtime context manifest the agent can read to figure out where it is. yolobox grew from a panic button into a development environment.
Then one agent stopped being enough.
This is either progress or a medical condition.
The single-agent workflow does not scale
The trouble shows up the moment you want to delegate two things at once.
One agent can refactor the API. One can fix the tests. One can investigate the Docker thing. One can confidently break the frontend in a way that looks like progress for twenty minutes.
This should be great. We have invented a little software team. Unfortunately, by default, we put the whole team in the same chair, in front of the same keyboard, editing the same folder, running the same Docker Compose project, and then act surprised when it turns into a fork fight in a phone booth.
Sitting and watching one agent until it is done, then queueing the next piece of work, is just batch processing with a human bottleneck. The whole point of a competent agent is that you can spend that time on something else, including pointing another agent at something else.
But the moment you actually try, three different things break.
Git breaks first. Two agents changing the same checkout is a wonderful way to rediscover why humans invented branches, code review, and passive aggression.
The filesystem breaks second. Agents write caches, build artifacts, lockfiles, generated code, .env assumptions, SQLite databases, screenshots, test output, and whatever else your project leaves around when shaken. None of this is in git status. All of it stomps on whatever the other agent was doing.
Docker Compose breaks third, and worst. If your project runs a web app, every agent wants the same ports, the same container names, the same networks, and the same named volumes. Suddenly your “parallel” coding setup is three agents politely murdering each other’s Postgres containers.
At this point the obvious answer is “use Git worktrees.”
This is also the point where the abstraction starts to leak.
Worktrees are technically correct, which is the most dangerous kind
Worktrees solve a real problem. They are a fine answer to “I want a second checkout of this repo on a different branch without re-cloning.”
That is not the problem.
A worktree shares one .git, but it does not share node_modules, or build artifacts, or the SQLite file your dev server writes to, or the .env you have been carefully not committing for three years, or the running Postgres container Compose started last Tuesday. It also does not share them in a useful way - it just doesn’t have them. Each new worktree is a clean checkout that has to be rehydrated by hand before any of the agent’s tools work.
So the work to make a worktree usable for an agent looks like: clone the env file, reinstall dependencies, rebuild whatever caches matter, restart Compose with a different project name so it doesn’t fight the original, and hope nothing in the codebase hardcodes the path. None of this is impossible. All of it is ceremony. And it is the wrong layer - Git is being asked to model “another developer’s machine” when it only knows how to model “another branch.”
If I hired a human named Alice, I would not say:
Alice, please operate as a Git worktree attached to my current checkout.
I would say:
Alice, clone the repo, install the deps, run the app, push a branch when you have something.
Actually, I would say something less coherent over Slack. The point stands. The unit I want to fork is not the branch. It is the developer.
The useful fiction: agents are developers
The command I wanted looks like this:
yolobox fork --name <name> codex
The trick that made the workflow click was what I started putting in <name>. Not features. Not --name new-billing-flow. Names like:
yolobox fork --name alice codex
yolobox fork --name bob claude
yolobox fork --name carol codex
These are not branches. They are people. Alice has her own folder. Bob has his own folder. Carol has her own folder and, for some reason, has rebuilt node_modules six times. We love Carol. Carol is trying.
Each fork is a complete copy of the current project folder. Not a clean Git checkout. Not a clever filtered view. Not “all the important files, as determined by a tool that has never met your project.” The whole folder. .git, .env, ignored files, untracked files, node_modules, local caches, generated nonsense, that weird tmp/ directory you are afraid to delete. Everything.
This is blunt. Blunt is underrated. A full copy gives the agent the same messy reality the project actually runs in, which for local development is most of the product. The copy lives at ../.yolobox-forks/<folder>/<name> on the host, and inside the container yolobox mounts it at the original source path, so anything path-dependent - the agent’s own session history, hardcoded absolute paths in build scripts, IDE state - keeps working.
yolobox also exports a few env vars per fork: YOLOBOX_FORK_NAME, YOLOBOX_FORK_SOURCE, YOLOBOX_FORK_COPY, and a unique COMPOSE_PROJECT_NAME. The first three let scripts inside the container figure out who they are and where they came from. The last one is what stops Alice’s Postgres container from murdering Bob’s, which we will get to in a moment.
When Alice is done, the copy sticks around so you can poke at it or pick the session back up:
yolobox fork resume alice codex
When the experiment has served its purpose, you burn it down explicitly:
yolobox fork discard alice --force
Once each agent has its own full folder, Git becomes boring again. Each agent commits in its own copy and pushes a branch. You pull, review, cherry-pick, merge, or throw it away. This is exactly how multiple developers already work - they don’t SSH into each other’s laptops and fight over a checkout, they each have their own clone, and the synchronization point is the remote. We already invented an entire global coordination protocol for this. It is called “please push your branch so I can see what you did.”
The goal is not to make agents special. The goal is to make agents less special.
The runtime needs the same treatment
The repo is only half of it.
If each agent is working on a web app, they also need their own runtime, or one agent’s docker compose up becomes another agent’s outage. This is what the per-fork COMPOSE_PROJECT_NAME from earlier is for. Compose uses that key to namespace everything it owns - containers, networks, named volumes - so Alice gets her own Postgres volume, Bob gets his own Postgres volume, Carol gets her own Postgres volume, fills it with confusing test data, and nobody else has to care.
On exit, yolobox runs a best-effort docker compose -p "$COMPOSE_PROJECT_NAME" down --volumes --remove-orphans if it finds a Compose file, so the runtime cleans itself up while the copied folder stays put for inspection or resume.
This is not magic. Hardcoded host ports, explicit container_name directives, external networks, and absolute bind mounts can still collide. But those become the exceptions you can see and fix, instead of the default state of the world.
Web apps need URLs, not port spreadsheets
Once you have multiple agents running web apps, ports become the next tax.
Alice wants 5173. Bob wants 5173. Carol wants 5173, 3001, 5432, and apparently also your soul.
You can solve this with random host ports, but then you end up reading docker compose ps like a cave inscription:
0.0.0.0:58423->5173/tcp
0.0.0.0:58424->3001/tcp
No. The civilized version is a local reverse proxy:
https://alice.myapp.localhost
https://alice-api.myapp.localhost
https://bob.myapp.localhost
https://bob-api.myapp.localhost
A shared host-side Traefik or Caddy on :80/:443. Random host ports per fork. A shared external proxy network. Friendly names derived from YOLOBOX_FORK_NAME. .localhost so DNS is not a project. mkcert so HTTPS works locally and your browser stops yelling at you like you are doing crimes.
The user-facing URL comes from the developer’s name, not the Compose project hash and not a random port. Alice gets Alice’s URL. Bob gets Bob’s URL. The day you walk over to a teammate’s desk and ask “what’s your URL again,” you will not flinch when an agent does the same thing.
And now Alice has her own files, her own Git state, her own Compose project, her own database volume, her own URL, and her own opportunity to disappoint you independently of everyone else.
That last property is the load-bearing one. Parallelism requires isolation. Without it you do not have four agents - you have one very confused agent with four terminals.
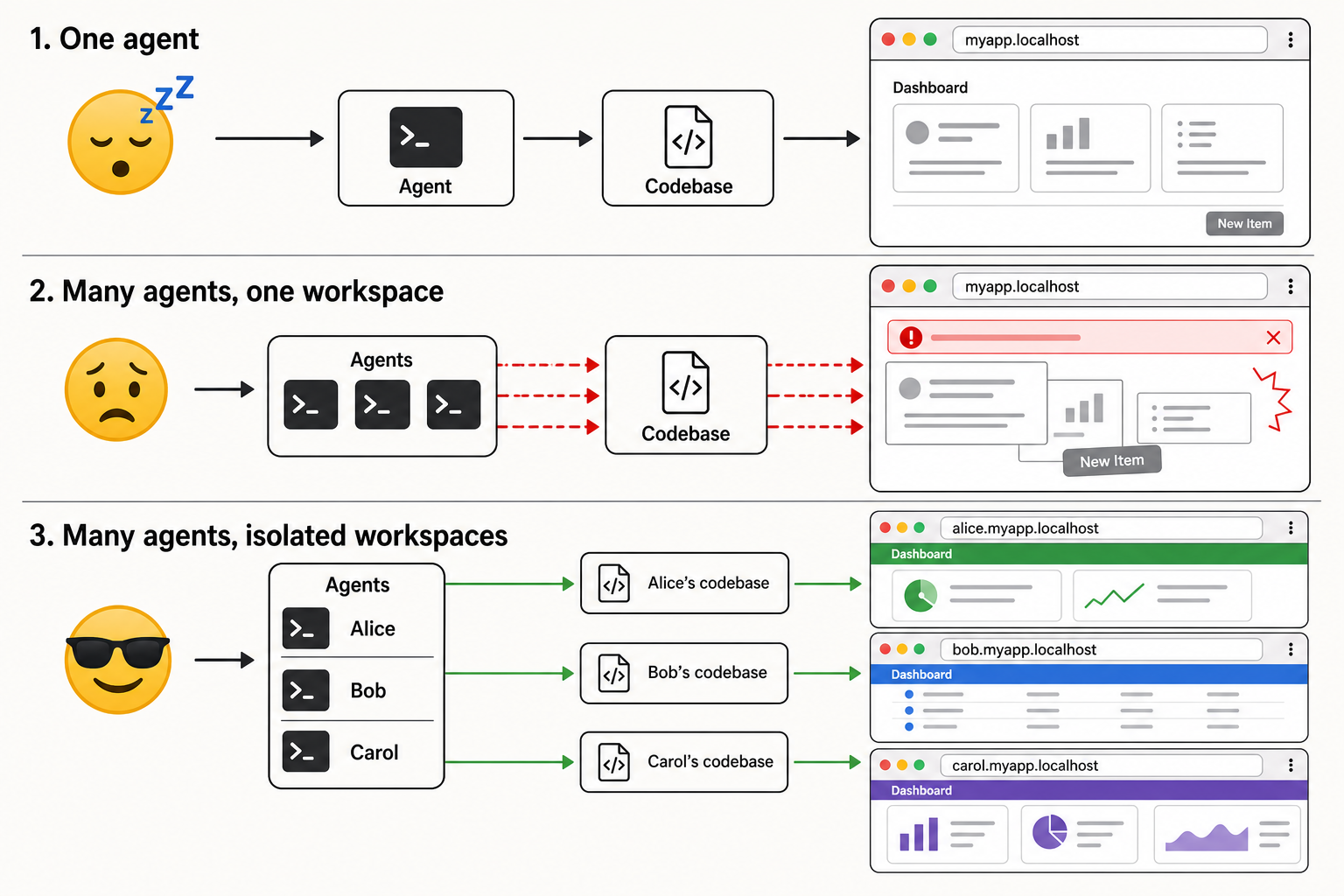
Why a full copy beats every clever alternative
There are more elegant designs than “copy the whole folder.”
You could use worktrees. You could use sparse checkouts. You could rsync while excluding dependencies. You could build an overlay filesystem that lets you feel briefly like a kernel engineer before ruining your afternoon.
Some of these are probably better for some teams. But the boring full-copy approach has three properties that have, so far, beaten every clever alternative I have tried:
- It preserves the exact local state the project needs to run, including the parts that are not in version control and that you have stopped thinking about.
- It mounts the copy at the original path inside the container, so anything path-dependent - agent session history, build scripts, IDE state - keeps working without translation.
- It makes the mental model obvious. There is no new abstraction to hold in your head. Each fork is another developer’s machine. That is the whole API.
The disk usage is not free. Copying a large repo with dependencies takes time. If your project carries 40GB of local junk, you will learn that fact quickly and personally. But storage is cheap, and my patience for local development ceremony is not.
What this actually looks like in a day
In practice the workflow has converged on something like: a few named forks open at once, each in its own terminal tab, each with a friendly URL pinned in the browser. One investigates a bug from a stack trace, one prototypes a feature behind a flag, one is grinding through a refactor I would not voluntarily do myself, one is running the test suite I keep meaning to fix. They commit and push to branches I review the same way I review pull requests from humans. The merge conflicts are normal merge conflicts. The CI feedback is normal CI feedback. The review is normal review.
.localhost subdomain via Traefik.The thing that surprised me is how much of the friction was coordination friction, not capability friction. The agents were already good enough to do the work. What was missing was the boring infrastructure that lets more than one of them do it at the same time without standing on each other’s feet.
This is the tutorial level
One human supervising one terminal agent in one checkout is not the final form. It is the tutorial level.
The next step is small teams. One agent investigates. One implements. One writes tests. One reviews. One tries the migration that makes you nervous, in an environment you can delete without having a small emotional event.
For that to work, the agents need the same things humans need: their own workspace, their own runtime, a way to publish work, a way to inspect what they are running, a way to delete the whole thing when it gets weird. None of those are interesting research problems. They are operational problems we already solved for human developers - branches, remotes, isolated dev environments, preview URLs, code review.
Making agents more useful turns out to require treating them less like magical autocomplete and more like junior developers with laptops.
Give them a desk.
Give them a clone.
Give them their own Compose namespace.
Then make them push a branch like everyone else.