
“Civilization advances by extending the number of important operations which we can perform without thinking of them.”
— Alfred North Whitehead
The café on Fillmore buzzed with noise. I saw a little girl, about six or seven, leaning over the table, lost in a math problem. She tapped her fingers in small groups and moved her lips as she worked. Her mother watched for a bit, then leaned in to help.
“Honey, remember? We memorized it,” the mother said calmly, but she sounded tired. “You don’t have to think about it. You know it.”
In January 2026, DeepSeek released a paper that effectively said the same thing to the most powerful AI on earth.

The paper, Conditional Memory via Scalable Lookup, makes a point that is technical as it is philosophical. The Transformer, the basis of modern AI, cannot distinguish between thinking and remembering. We use it like a universal computer, making it reconstruct information from scratch every time it answers.
For example, if you ask about “Diana, Princess of Wales,” the model doesn’t just pull up the answer. Instead, it rebuilds the idea of Diana through its own neural network, step by step, until it gets to the answer.
DeepSeek calls this “an expensive runtime reconstruction of a static lookup table.”
This approach is analogous to that of the little girl in the café, working out fifty-six by counting on her fingers. It means thinking through something every time, even when the answer should be easy to recall.
The struggle between solving problems and finding information has existed for ages. This back-and-forth goes all the way back to the clay tablets of Uruk.

Babylonian astronomers made Lookup Tables so they wouldn’t have to calculate the positions of the planets every night. Doing the math was hard work and meant scribes had to stay up late, using oil lamps. Instead, they wrote the answers on clay tablets. If you wanted to know where Venus would be, you just checked the library instead of doing the math yourself. In this way, they used more space for clay tablets to save time on calculations.
This trade-off has shaped the entire history of computing.
 - Pingdom")
In the 1940s, memory was hard to come by, so computers stored bits as sound waves in mercury tubes. Because memory was limited, machines had to redo calculations they couldn’t store. By the 1970s, cheaper RAM changed things. Now, computers can save results and avoid repeating work. In the 1990s, processors became so fast that they often had to wait for memory. To fix this, engineers added a small, fast cache to keep important data close to the processor.
Large language models made us depend on raw computing power more than anyone expected. Through the Bitter Lesson, we found out that handcrafted knowledge could not match brute-force methods that simply churn through a lot of compute. Instead of giving models instructions, we let them learn everything from the ground up, mixing facts and reasoning in one system. This method worked, even though for a while, nobody really understood why. But there was a catch: every fact, even simple ones, had to be recreated by the whole network. Now, we use a supercomputer just to check if Paris is in France.

Engineers in China, operating under computational constraints not encountered by their American counterparts, experienced these inefficiencies most directly. Once again, constraints inspire creativity. DeepSeek’s solution, Engram, represents a modern adaptation of the N-gram lookup method, previously considered obsolete, reimagined as a rapid and scalable memory system. This approach enables the model to recognize familiar patterns and retrieve them directly, rather than recomputing, effectively introducing a cache mechanism to transformer architectures.
It allows the model to say: I know this pattern. I don’t need to think about it. I’ll just fetch it.
To look away from the machine and towards the classroom is to see the technical error restated as a crisis of upbringing. We have presided over a bifurcation of the intellect, dividing the mind into two camps in its effort to understand the architecture of the mind.
In the West, especially in elite American education, memory is often viewed with suspicion. Rote memory is seen as a weak substitute for genuine understanding. What matters is critical thinking: expecting children to form opinions grounded in strong logic. The strength of this approach is undeniable. It creates a “self” that is resilient against the unknown, capable of navigating terrain where no map exists. It produces the kind of elasticity that allows a mind to refuse the status quo and invent a new one.

Now, picture the world of the Gaokao, Hagwon, or a Kumon center. A child’s hours after school stretch as long as the school day itself; a single number delineating the shape of the entire life course.
The intensive drill-based educational system in Asia can look analogous to LLM pre-training, in which memory and the illusion of understanding can be solidified through repetition. These systems rely on procedural memory and instinctual recall. In a way, fluency functions as an extensive internalized reference system.
Taken to their logical extremes, both systems fail the very students they claim to serve, yielding not mastery but distinct forms of mental stagnation.
A primary limitation of the ‘Eastern’ educational model is overfitting. Students may solve a test problem with mechanical precision, but struggle when confronted with a novel variation. This approach produces learners who become static repositories of information, rich in procedural knowledge but lacking in adaptive reasoning. Such outcomes support critiques that, while these systems excel in efficiency and scale, they often inhibit creativity. This phenomenon appears to be a structural consequence of excessive reliance on memorization rather than a purely cultural issue.
The “Western” model, on the other hand, produces a student of dazzling conceptual agility, who can eloquently explain why multiplication works and deconstruct the colonial history of justice, but who cannot calculate the tip at a dinner party without panic. They are CPUs that have overheated. They have been taught to think so critically that they have forgotten how to know.
This is why the DeepSeek paper can be so edifying. When engineers let the model memorize simple, everyday facts, performance on reasoning tasks improved meaningfully. The leap in reasoning outpaced even the gains in knowledge.
These results highlight a limitation often neglected by prevailing educational philosophies: reasoning capacity is finite, analogous to the context window of a computational model. Cognitive resources are limited, and time spent on basic problem-solving detracts from creative or original intellectual work.
")
When a pianist plays Rachmaninoff, they don’t think about every single note as they play; the piece instead flows through their fingertips like a well-timed storm. The performance is unhindered by technicalities. If the pianist had to think about finger placement for each note, like a student solving a problem from scratch, the music would lose its flow. By memorizing the basics, the mind is free to focus on expression.
What if memorization does not hold us back, but actually helps us think more freely?
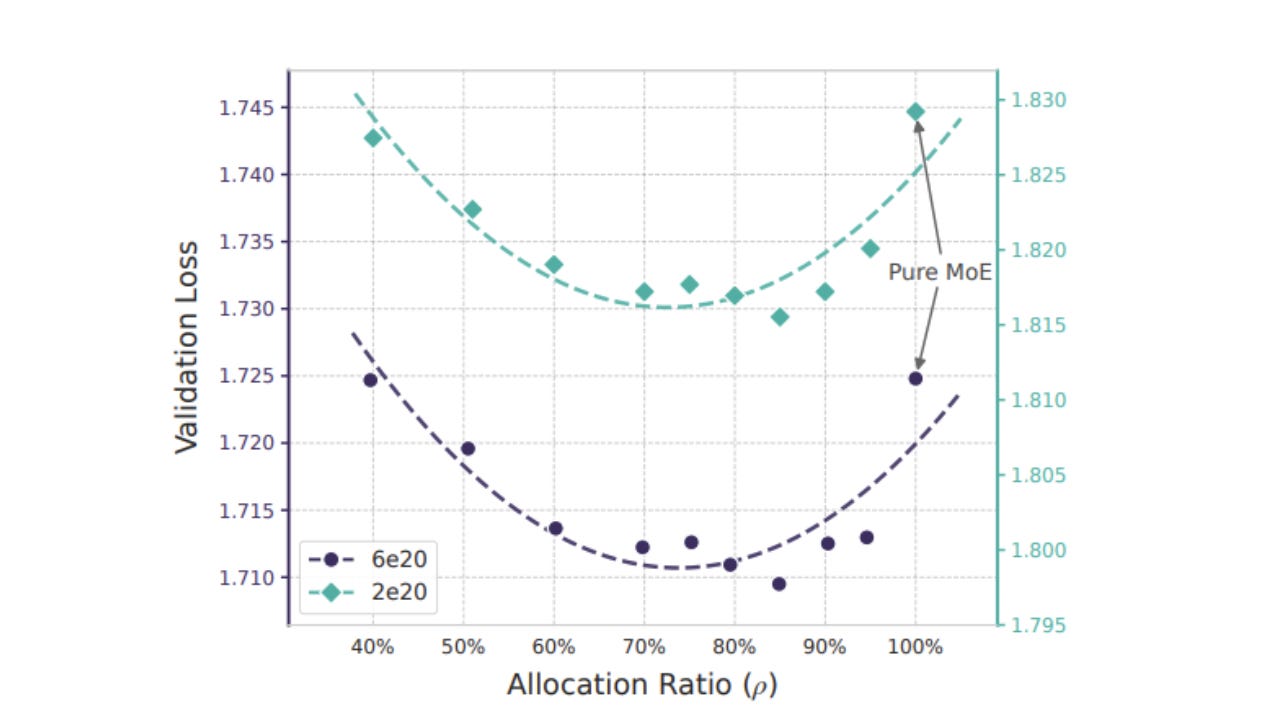
In studying cognitive processes, the researchers at DeepSeek have identified the “U-shaped curve” to determine the optimal allocation of neural resources between the “Engram,” the fixed memory store, and the “Experts,” responsible for active reasoning.
Both extremes can be unforgiving. If too little memory is used, the system can’t develop and stays stuck, unable to remember things, like a child who can’t learn. But if too much memory is used, the system becomes rigid and stops reasoning, relying solely on what existed before.
The optimal configuration identified was an asymmetrical distribution: 25% allocated to memory and 75% to active reasoning.
When memory allocation exceeds this threshold (typically called a Hash Collision), overfitting occurs. Encountering the word “Bank” may prompt the immediate recall of a riverbank, even when the context pertains to a financial institution. This misretrieval exemplifies the challenges experts face, who often rely on experience rather than context-specific reasoning.
Everyone knows the senior partner at a law firm who has seen everything. He sits behind glass, radiating experience, cutting you off before you finish. Usually, he already knows your question. He operates like a living lookup table. Nothing seems to make him flinch. He spots the pattern, recalls what worked in 1998, and applies it with confidence.
He moves with speed and authority; however, his reliance on outdated knowledge can result in errors. The accumulation of past experiences may hinder his ability to accurately assess current situations, as excessive recall diminishes critical inquiry.
It’s a huge efficiency gain that so much human knowledge can be accessed simply by recalling it, rather than working it out each time. But if we relied on memory without any checks, we could easily hallucinate. That’s why we need something like a Gate between stored memories and active reasoning. This gate does more than just open or close. It looks at what we remember, catches easy answers or familiar solutions, and tests them before information passes through.
The Gate helps us distinguish between situations. It stops us from running on autopilot. It reminds us: even if this crisis looks like the Dot Com bubble and the chart looks like 1999, the details are different. Don’t rely on memory. Don’t just rely on pattern recognition. Think it through.
The DeepSeek paper asks a question that seems to be about computer chips, but it’s really about us. It’s a question of how we use our limited attention.
With only so much attention to give at any moment, how should we use it? How much should go to the parts of us that solve problems as they come up, and how much to the parts that simply remember what we already know?
Most of us are living far out on the edges of the U-shaped curve, suffering the high validation loss of a misallocated life.
I have friends who are under-cached. Every email is a fresh existential crisis, every menu a small referendum on who they are. They would tell you they guide themselves with first principles, authentic, a pure MoE machine, running hot, believing friction to be virtue. And they are exhausted. By refusing to automate the syntax of their lives, they have nothing left for spontaneity or poetry, Nietzsche’s Dionysian, the animal spirits.
The over-cached are worse, potentially, delegating way too generously to buzzwords, borrowed heuristics, an anecdote for everything and an insight for nothing. Memory scaled to the billions while the reasoning starves. Their Gate quit years ago. They aren’t living so much as re-running days they already survived, and the rerun gets cheaper every season.
Twenty-five percent less thinking is, paradoxically, a heuristic one can borrow. It’s not up to any mortal to allocate our tokens with the precision of a model architecture, but we can be deliberate about what we let harden in our cache.
So it’s time to compile. The multiplication tables, the polite greetings, the commute, the filing of tasks into their cabinets, all of it pushed down into the Engram where it runs without me. What’s left over, I spend at the edges: the heartbreak, a blank page, a glance from a stranger.
When the little girl in the café one day blurts out “fifty-six” without her fingers and looks up, she starts noticing the world around her. Then we’re reminded once again that memorization is not an escape from thought. We remember just enough so that, at last, real thinking can start.