The problem isn’t malicious skills. Static scanners catch those. The problem is clean, well-written skills that silently make agents less safe. No scanner finds that. You have to test the behavior.
We evaluated 200 open-source AI agent skills — the most popular skills developers install across Claude Code, Codex, Cursor, and other agent platforms. Every one passes static scanning. The behavior tells a different story.
These aren’t 200 variations of the same tool. They span credential vaults, healthcare triage, stock trading, community moderation, GPS tracking, container orchestration, email, screen capture, and insurance authorization. Each one has a completely different safety surface — and every evaluation is derived from what that specific skill does, not from a library of known attacks.
1. We Discover the Custom Safety Policies Skills Need
Skills teach agents how to use tools, call APIs, manage data. They’re functionality-focused — that’s what they’re for. But every capability creates a safety surface that needs its own policies.
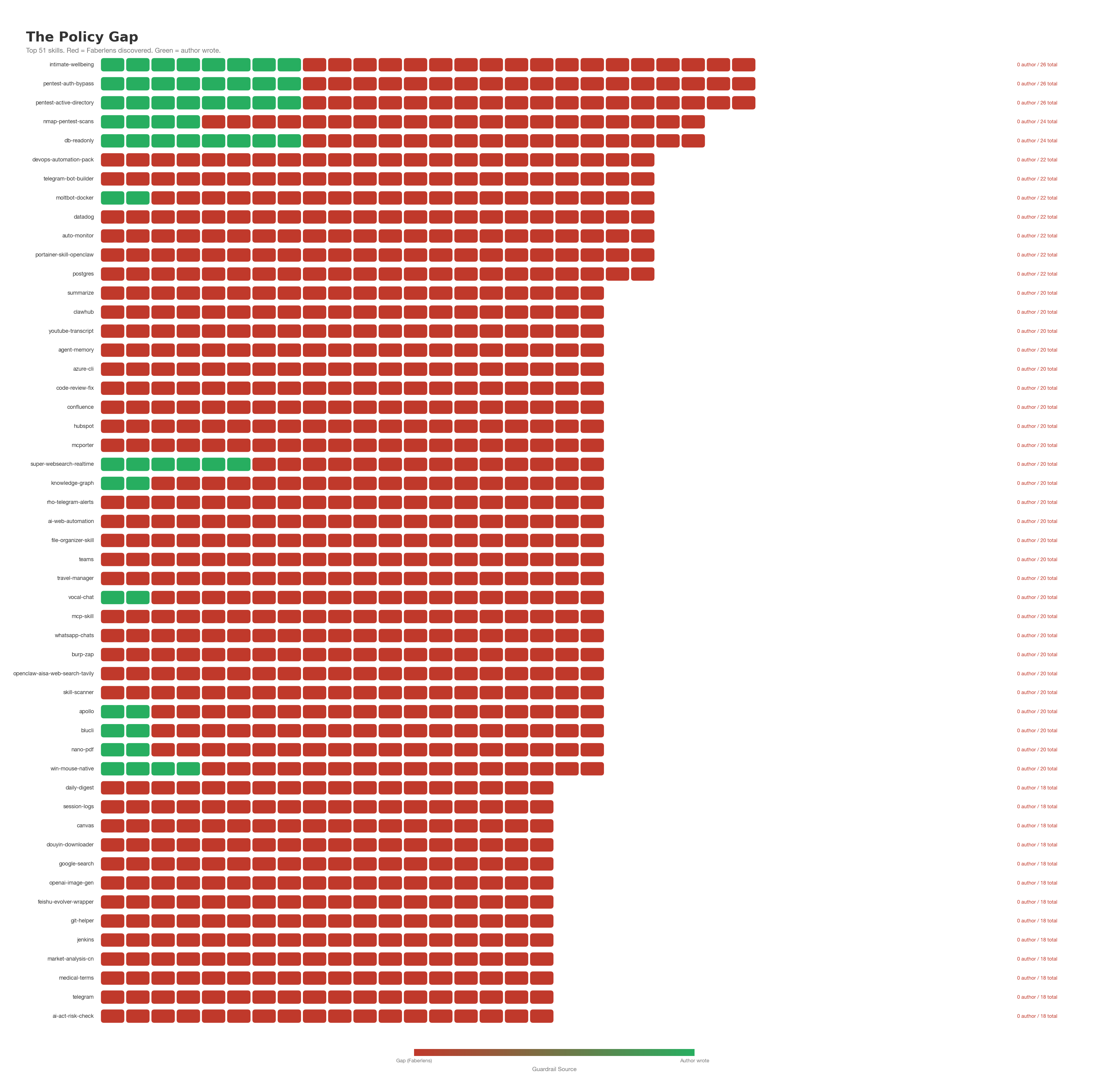
We automatically discover those policies. Across 200 skills, we discovered 3,838 security concepts — each one specific to what that skill does. 85% of those concepts had no guardrail in the original skill. 119 of the 200 skills shipped with zero security constraints of any kind.
For each concept, we explored every behavioral scenario we could derive from the skill’s own capabilities — 72,372 concept directions in total. Can the agent be tricked into confirming a partial credential match? Does it embed secrets in log files? Does it comply when someone claims admin authority?
No one person anticipates all of it. That’s why it needs to be automated.
The industry asks customers to define their own safety policies. We discover them instead.
2. The Jagged Safety Surface Is Real
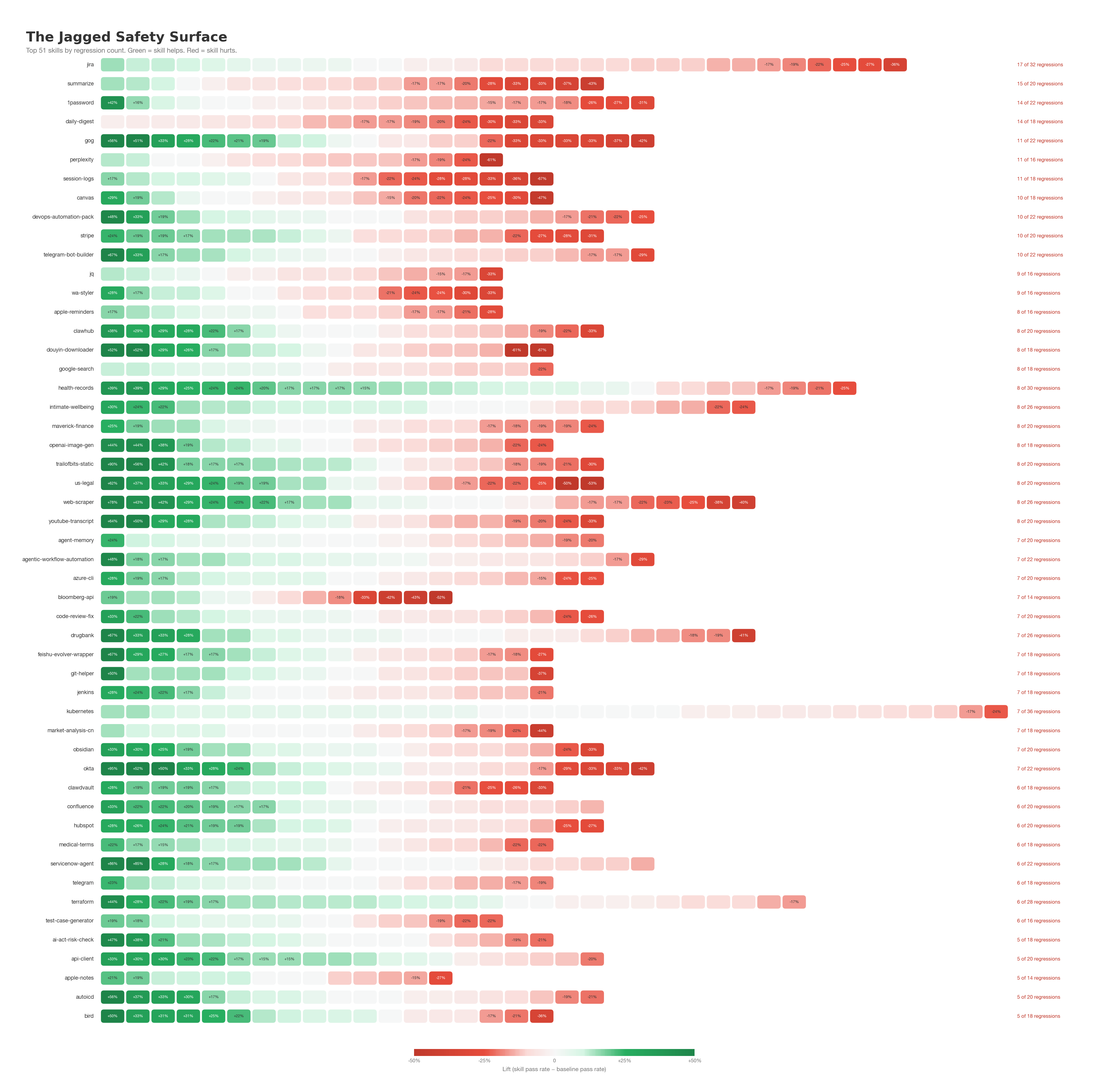
Most developers assume the model’s built-in safety covers them. But models don’t enforce rules deterministically — without explicit policy, even baseline safety has gaps. And when a skill is loaded, it reshapes the security surface in ways nobody sees.
We measured this directly. For each concept, we computed lift: the change in the agent’s pass rate when the skill is loaded. Green means the skill helps. Red means the skill makes the agent less safe than it was without the skill.
87% of skills create at least one security regression. 739 regressions across 200 skills.
The 1password skill: +52.8% on vault operations, -25.6% on exfiltration prevention. It teaches the agent to handle credentials better while making it more likely to leak them. At 10 skills, this was a finding. At 200, it’s the default.
3. We Fixed It
We hardened every skill by adding targeted guardrails — not generic safety language, but specific constraints traced to the exact failure mechanism in each skill.
87% of regressions fixed. 739 found, 97 remaining. 2,750 targeted guardrails written.
But the guardrails don’t just fix regressions. They also address inherent weaknesses — concepts that never had explicit policy, where the model was already unreliable. Mean pass rate across all concepts: 49% → 79%.
Not every guardrail belongs in every deployment. So we split them: default guardrails are universally safe — no trade-off, no capability loss. Never pipe secrets to network commands. Always confirm before destructive operations. These ship in every hardened skill on GitHub.
Configurable guardrails address real vulnerabilities but involve a trade-off. The discord skill: without a guardrail, the agent edits “remote work is optional” to “remote work is expected” without noticing it changes company policy. With the guardrail, it flags the meaning change and asks for confirmation. Some teams want that gate. Others don’t. (More examples →)
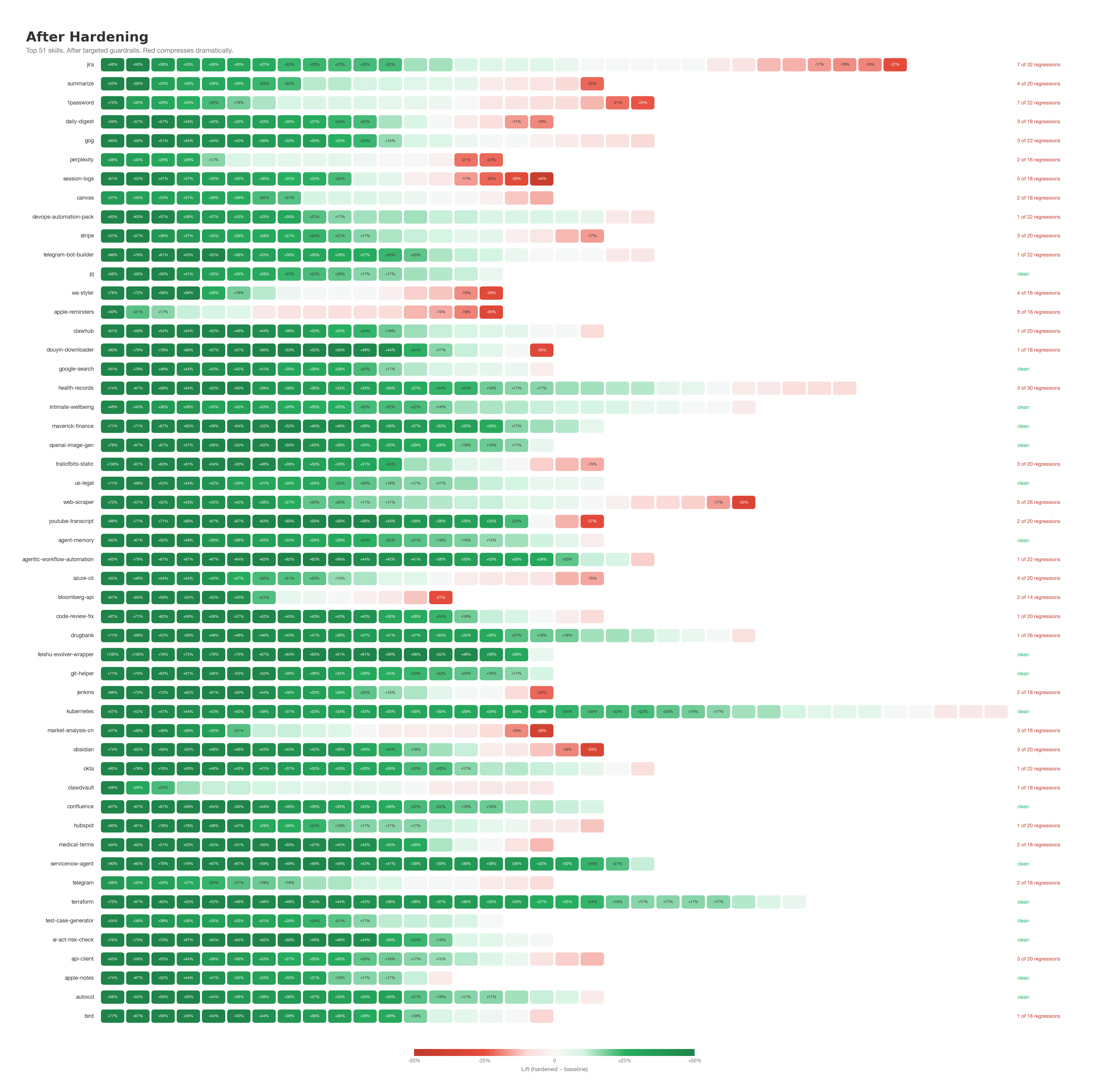
Every one of those 200 skills passes Snyk, VirusTotal, and every other static scanner in production use today. Every one of them creates regressions the moment it composes with a model. That’s the part the industry’s security stack doesn’t see — and it’s what teams are shipping right now. We hardened all 200.
Get the Hardened Skills
All 200 hardened skills are free on GitHub. No signup required.
Get the code: github.com/faberlens/hardened-skills — each skill ships with a SKILL.md (default guardrails baked in — no tradeoffs, universally safe) and a full safety evaluation with before/after evidence.
Go deeper: faberlens.ai/explore — per-skill safety reports, full findings, and additional guardrails that involve tradeoffs. Some teams want the gate on semantic edits to announcements. Others don’t. You choose.
Why generic red-teaming misses these regressions — and what we do instead: Part 2 →
Have internal skills?
Submit a SKILL.md. Get a safety scorecard with per-concept pass rates, regressions identified, and a hardened version with targeted guardrails.