Models are getting better at long-horizon tasks. So why don't they help much when you're planning a clinical development program, prioritizing targets, or thinking through a launch? Or, for that matter, when I'm planning what Elicit should work on?
No good software for planning
Software has always been surprisingly weak for planning.
What do I mean by planning? You have a goal, say:
I want my Phase II to read out positive
I want to pick the best fifteen programs from eighty candidates
I want my drug launch to hit a forecast
I want to launch a successful product at Elicit
I have the strong intuition that there should be cross-domain tools for figuring out how to accomplish these goals.
Each domain has its intricacies and data sources, but they also share a lot:
Decompose a goal into sub-goals and actions
Name the uncertainties, and which ones are worth resolving
Map dependencies, constraints, stakeholders
Imagine failures before they happen
Choose metrics for checking progress
Update the plan when the world changes
We have to-do lists, note-taking, outliners, spreadsheets, slides, Notion, Airtable, Jira, but they are all syntactic. They don’t constrain the content much.
Any one domain also has more specialized tools. In Pharma, this may be Planisware for the portfolio, Cytel for trial design, and IQVIA for competitive intelligence. They integrate external data sources, organize data, and run specialized forecasts - but compared to my vision, they help much less with what programs to keep, what trial designs to consider, and when to kill a program. From all I’ve heard, that happens in spreadsheets, slides, and conference rooms. But that was before LLMs.
Language models don't help much yet
You can chat with Claude about plans: "We're scoping a Phase II for our JAK inhibitor in atopic derm, walk me through the design space," and it will sometimes have useful things to say that inform your thinking. But how often does it leave you feeling that you’ve gotten to the bottom of things? Not often, yet.
Why is that? For one thing, it doesn't feel like models truly try to understand what's going on. I'll describe a problem - say, choose between an aggressive adaptive Phase II design and a more conservative parallel-group readout - and they engage with that. But even in the cases where they push back on the frame, it doesn’t feel like there’s someone there who has developed their own internally coherent model of the situation.
In some sense, the models are clearly getting better at planning. Just talk to them - they're obviously getting smarter. And the time horizon of tasks they can do is going up. But (1) they're still weak (this is the no internally coherent model point) and (2) the models being able to plan as part of a long-horizon task, e.g. how to make the tests in your codebase pass, isn't the same as helping you plan.
Another way of saying (2): Becoming more consequentialist - better at planning that systematically achieves goals - is probably a convergent feature for any strong intelligence. As we increase the time horizons models just have to get better at planning, or they won't accomplish the training tasks. And the more diverse the tasks are, the more this will reinforce general planning circuits. But will it help us as much as it helps the models?
Take VendingBench. The models are getting better at running simple business simulations. Does that measure their ability to plan? Or Prediction Arena - does that show that models are getting better at planning? Something within the models is getting better at planning, but that doesn’t mean they help you generate better plans to the same extent.
What even is a plan?
When I think about a plan, I often imagine a policy as in reinforcement learning - a mapping from states to actions. This is of course a radically oversimplified perspective. In the real world, as a planner you're limited by what you can observe, and by the amount of computation you can do. So part of planning is about how to invest computation and whether and how to learn more.
There is a lot of interesting complexity here, which is maybe why it's hard for people and AI to reason about clearly. When you're thinking about whether someone is making a good plan for target validation or portfolio prioritization, what matters is whether they followed a good process, the sort of process you'd expect to lead to good plans, not just that the plan you’re looking at in the end seems promising. And the process needs to take into account a lot - it doesn’t just have to reason about what’s good to do, but also where you don’t know enough and how much it’s even worth thinking about whether to get more info.
Much more can be done
There are two things we can do, at least:
Tools for planning
First, we can work on better LLM-based tools that help people plan, and build in strategies along the lines of what we mentioned at the beginning - decomposition into subgoals, naming uncertainties, imagining different futures.
What could that look like? To give one example, we can use LLMs informed by data to sample trajectories of how a Phase II might unfold over time given enrollment rates, dropout, signal strength, and competitor readouts:
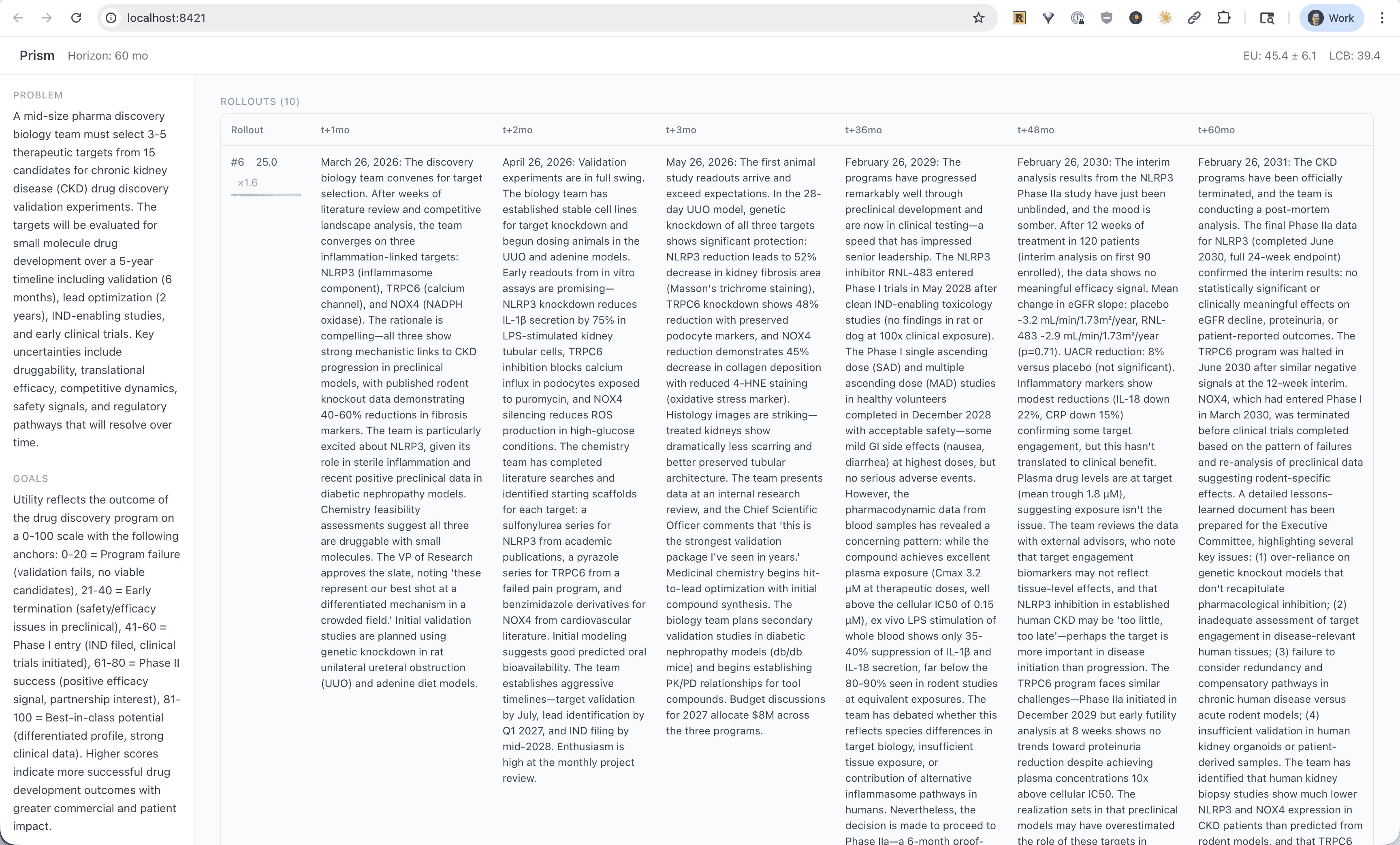
Language models enable us to sample distributions over what might happen if we implement a plan. (Internal Elicit Beta)
We can then use another LLM to plan against this distribution, and find weaknesses in proposed plans - protocols that look fine on paper but fail under realistic enrollment shocks or other interim signals:
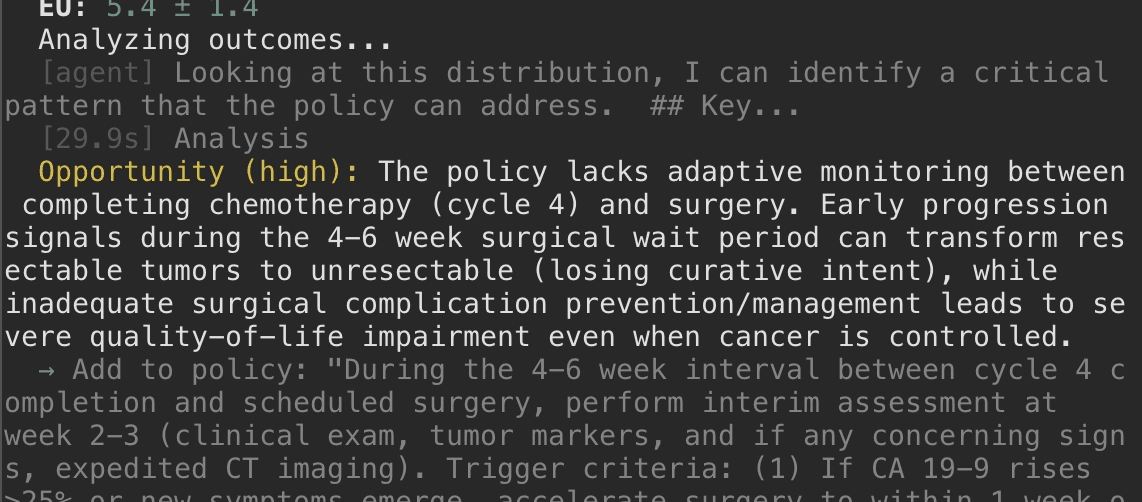
By planning against a distribution of possible futures, we can identify how to systematically improve outcomes. (Internal Elicit Beta)
The design space of tools for thought that don't just use LLMs as chat or coding agents is huge and largely unexplored. This is true in general and especially true for planning.
Tools for checking plans
Second, we can build tools that check plans generated by models. This is especially important if we think that models out of the box will soon generate plans that look quite good to us. Taking the bitter lesson seriously means focusing on methods that scale with more compute, and one of the things that scales is investing in verifiers and loss functions that are robust enough to optimize against.
But again, what matters for checking plans is often not the plan itself but how the model generated the plan - what process did it go through to come up with it? Did it consider all relevant arguments and pieces of evidence?
We can build tools that help us check those processes and make sure they're systematic, that they considered all the evidence in ways that we would expect to lead to good plans ex ante.
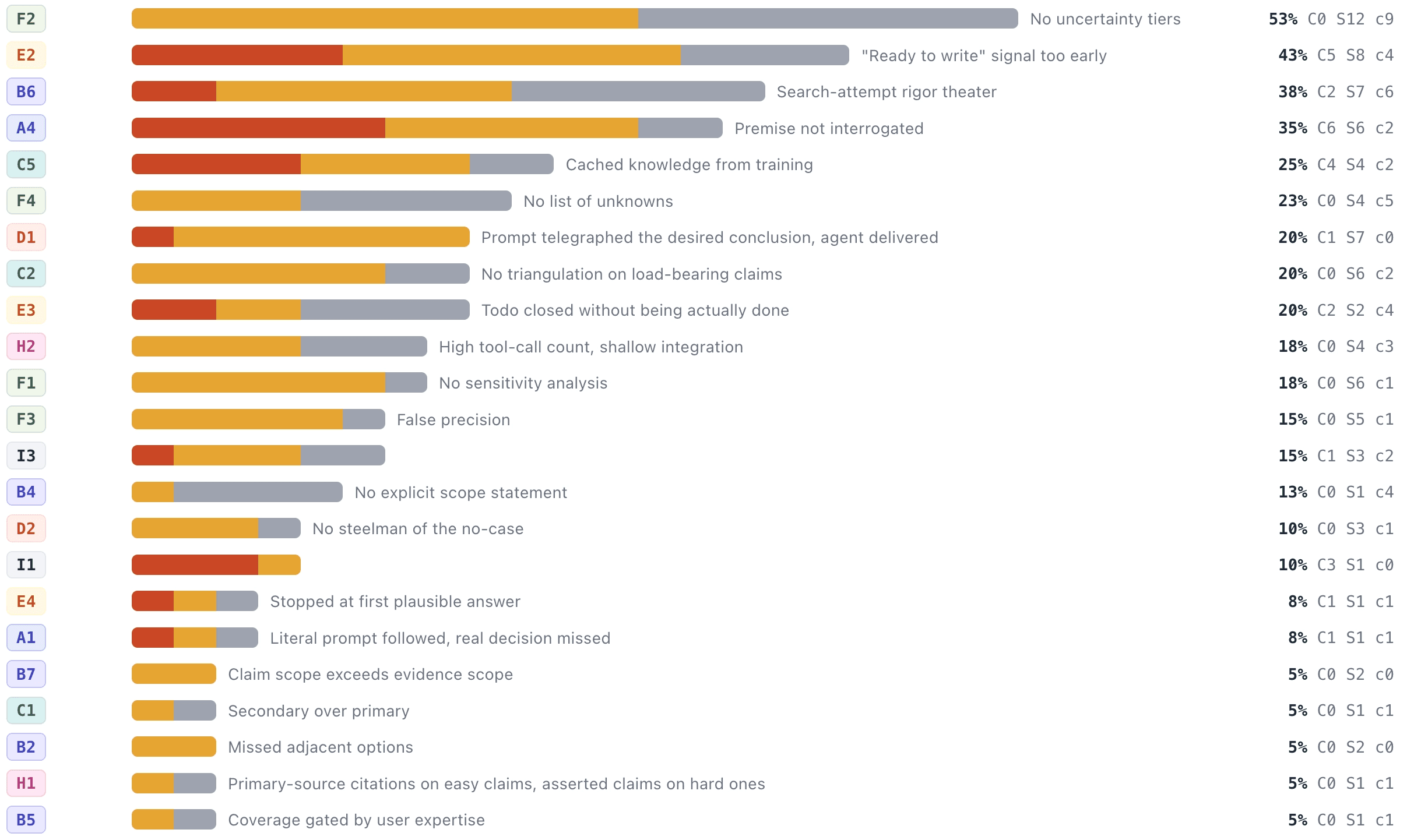
Error analysis of plans at scale. Each row is an error type, bars indicate how often the error was critical / serious / cosmetic. (Internal Elicit Beta)
Verification of of processes for adherence to high-quality reasoning is largely unexplored, in part because models only recently got good enough to be able to coherently think about failure modes.
Upshot
Planning is harder to evaluate than most of what models are trained on. Improving loss functions, running experiments with rapid software feedback, or even real-world feedback, has a tight learning loop. Planning in most domains doesn't.
We probably shouldn't expect helping-humans-plan to fully fall out of bigger models, or least shouldn't rely on it. It likely needs deliberate work, especially if we care about it arriving soon: tools that make planning processes legible and systematic, and verifiers that check whether these processes implement high-quality reasoning, with domain experts judging how much we're actually helping.
If you want to build tools for planning, come work at Elicit. If you're at a top-20 pharma working on planning problems like these, get in touch about our early access program.