Control the emotion, delivery and direction with audio tags
Create controllable, expressive speech layered with emotion, audio events, and immersive soundscapes.

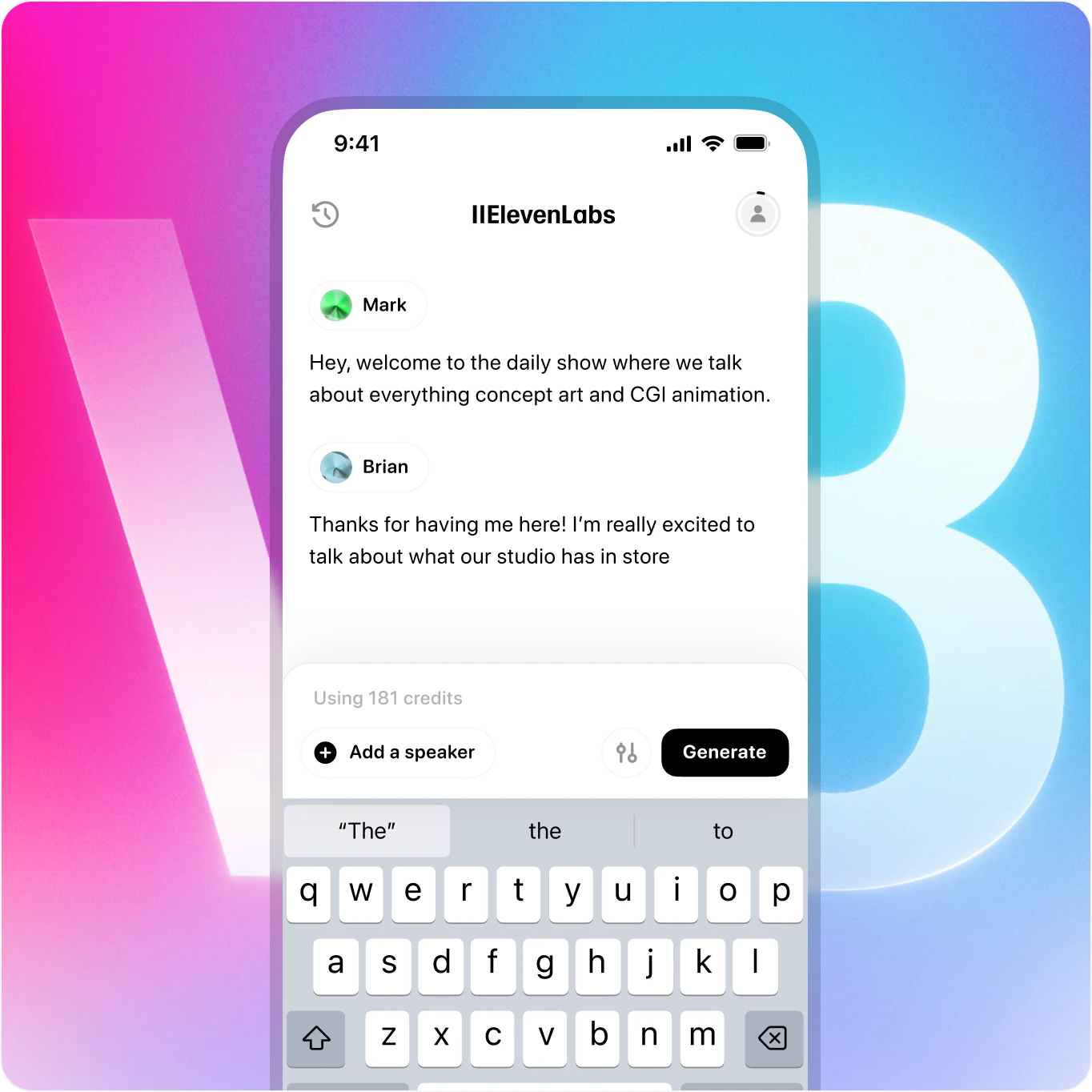
Generate dynamic conversations between multiple speakers
Create audio conversations where speakers share context and emotion, making generated dialogue sound natural and human.

Take v3 anywhere - now available on mobile
Create lifelike speech with rich emotion - all from your phone. Our voice AI delivers studio-quality performance from anywhere.
Human-like speech in 70+ languages
Reach global audiences with expressive and nuanced speech in every major language.

English

Chinese

Spanish

French

Portuguese

German

Japanese

Italian
Experience our most expressive model with emotional depth and rich delivery.
Eleven v3 (alpha) is unlike other ElevenLabs models, offering a broad dynamic range controlled through inline audio tags.
Build with the Eleven v3 API
Generate lifelike speech in 70+ languages with emotion, direction, and multi-speaker control using inline audio tags.
Create with the highest quality AI Audio