A recorded voice is never just a voice: it is a body breathing, a room resonating, a microphone straining, a moment with its own incidental noise. AI-generated speech is often most exposed not in the voice itself but in everything around it.
Across our cases we have come to see a problem in the field of audio authentication: the prevailing practice is to rely on detection software alone. A clip goes in, a verdict comes out – real or fake – and that verdict is treated as the answer. Our own work, which combines critical listening with detection software, is increasingly weighed against the outputs of these tools, as if the software’s verdict and a careful acoustic reading were equivalent forms of evidence. This assumption obscures what authentication requires.
In this month’s newsletter, we share reflections on a few of the cases where we set out to determine whether a recording was genuine or AI-generated, and on the methodology we have been developing for audio authentication of deepfakes: one that pairs critical listening with detection software, attending to the sounds in and around the voice.
Optional paid support: If you’d like to support our work, monthly subscriptions are available at $5.00. Earshot is the foremost independent nonprofit organisation producing sonic investigations with and on behalf of communities affected by corporate, state, and environmental violence. Your support enables us to conduct investigations, develop the field, and establish sonic evidence within accountability frameworks.
The AI models that produce synthetic speech, and the detection tools built to catch them, are trained almost entirely on the voice: its frequencies, rhythm, timbre, the fine patterns that make a person sound like themselves. The models can only reproduce, and the detection tools can only listen for, what they have been trained on. The voice, though, is but one part of what a microphone actually records.
Around the voice sits everything else: breaths and hesitations, the incidental sounds on a recording, the resonance of the space, the strain of the device itself. An AI generation model trained on the voice alone has no room to resonate, no environment to draw incidental sound from, no real air to move across a microphone diaphragm. These surrounding sounds are not noise to be filtered away; they are, we have found, often more reliable evidence of a recording’s authenticity than the voice. It is precisely this relational web of sound, rather than the voice, that current models fail toreproduce and that binary detection tools are not built to hear.
Our methodology is critical listening: close attention to the audio artefacts surrounding the voicethat together form the coherent acoustic web of a genuine recording.
Where it is available, we use detection software as a supplement: a fast, quantified second opinion that examines the voice. But the software is not the work. As the cases below show, some of the most decisive evidence in our investigations is rarely linguistic, and almost never come from the voice itself.
What follows is not a full account of any single investigation. We have isolated each artefact in turn and paired it with the case in which it proved most decisive, to show what each one does and why it matters.
We move outward from the voice: first the breaths that punctuate speech, then the resonance of the room that holds it, and finally the marks left by the microphone at the point of capture.
Breaths are typically heard lasting under a second and are characterised by their broadband frequency content where no single frequency dominates, but rather an airy mixture of all frequencies is heard across the audible spectrum (0–20kHz). Spectrographs allow us to visualise this behaviour. A spectrograph is a visual representation of the frequencies present in an audio recording, with frequency mapped on the y-axis and time on the x-axis. The bright orange colour represents the intensity of each frequency at a particular moment in time. When we examine a spectrograph of a natural breath, the broadband frequency content appears as a diffuse cloud – the product of chaotic air movement around a microphone, causing uncontrolled vibration across all frequencies (Figure 1).
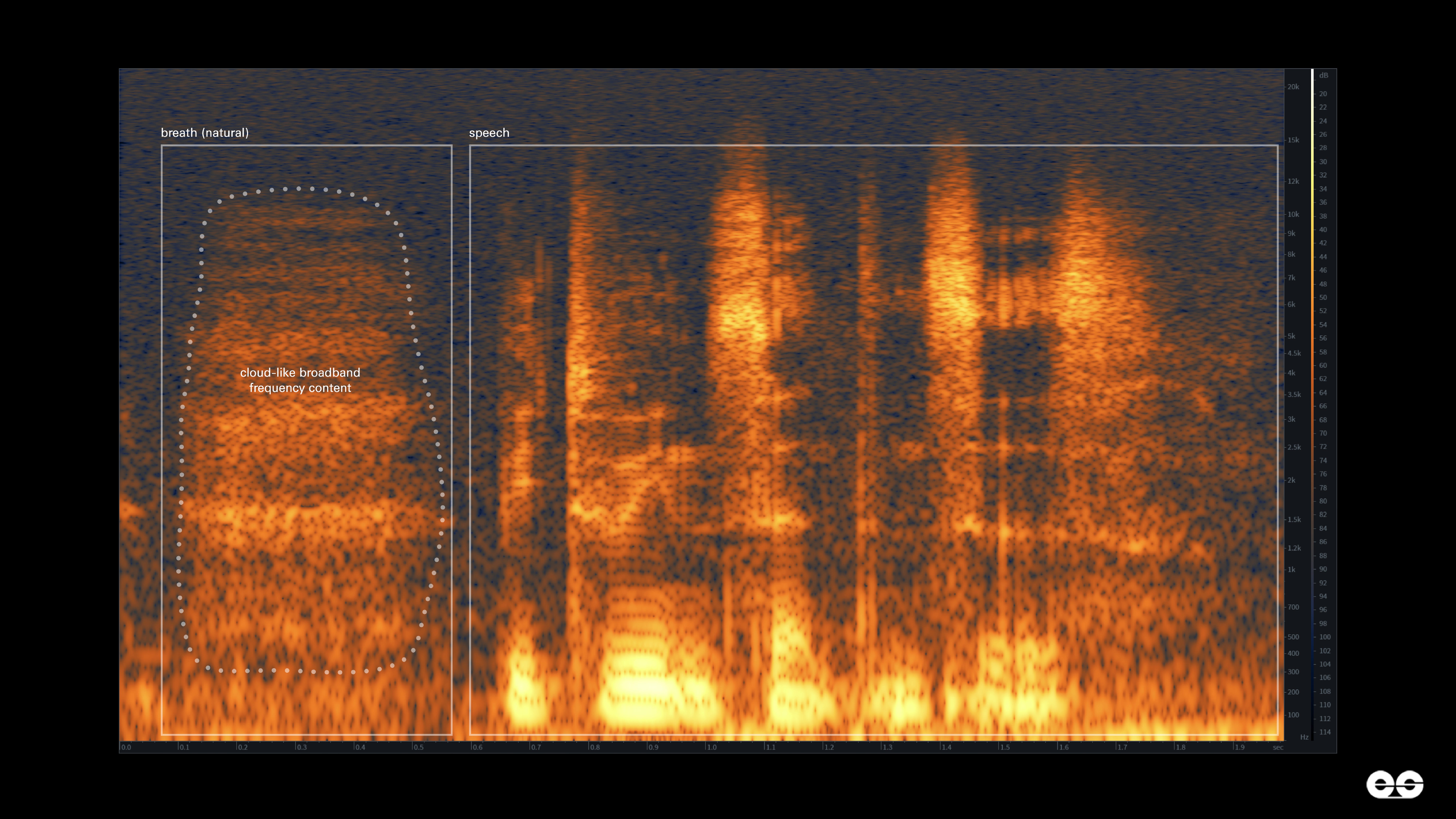
In November 2024, three audio clips were shared by members of the ruling political alliance ‘Mahayuti’ in Maharashtra, India. These clips contained conversations between the leaders and officers from the opposition party ‘Mahavikas Aghadi’ purportedly promising financial favours during an election in the Maharashtra Assembly1. While the voices in these recordings were remarkably close to the people they were targeting, our analysis confirmed they were AI-generated by identifying a strange pattern in the sounds of breaths between sentences.
An AI-generated breath, with the rhythmic, tremolo-like undulation in amplitude that gave the Maharashtra recordings away.
Unlike the natural breaths we were accustomed to hearing and seeing in our spectrographic analysis, the breaths in the Maharashtra investigation were showing a different pattern: a repeating pattern of pronounced frequencies appearing at intervals of a few milliseconds, visible as vertical bands across the entire breath (Figure 2).
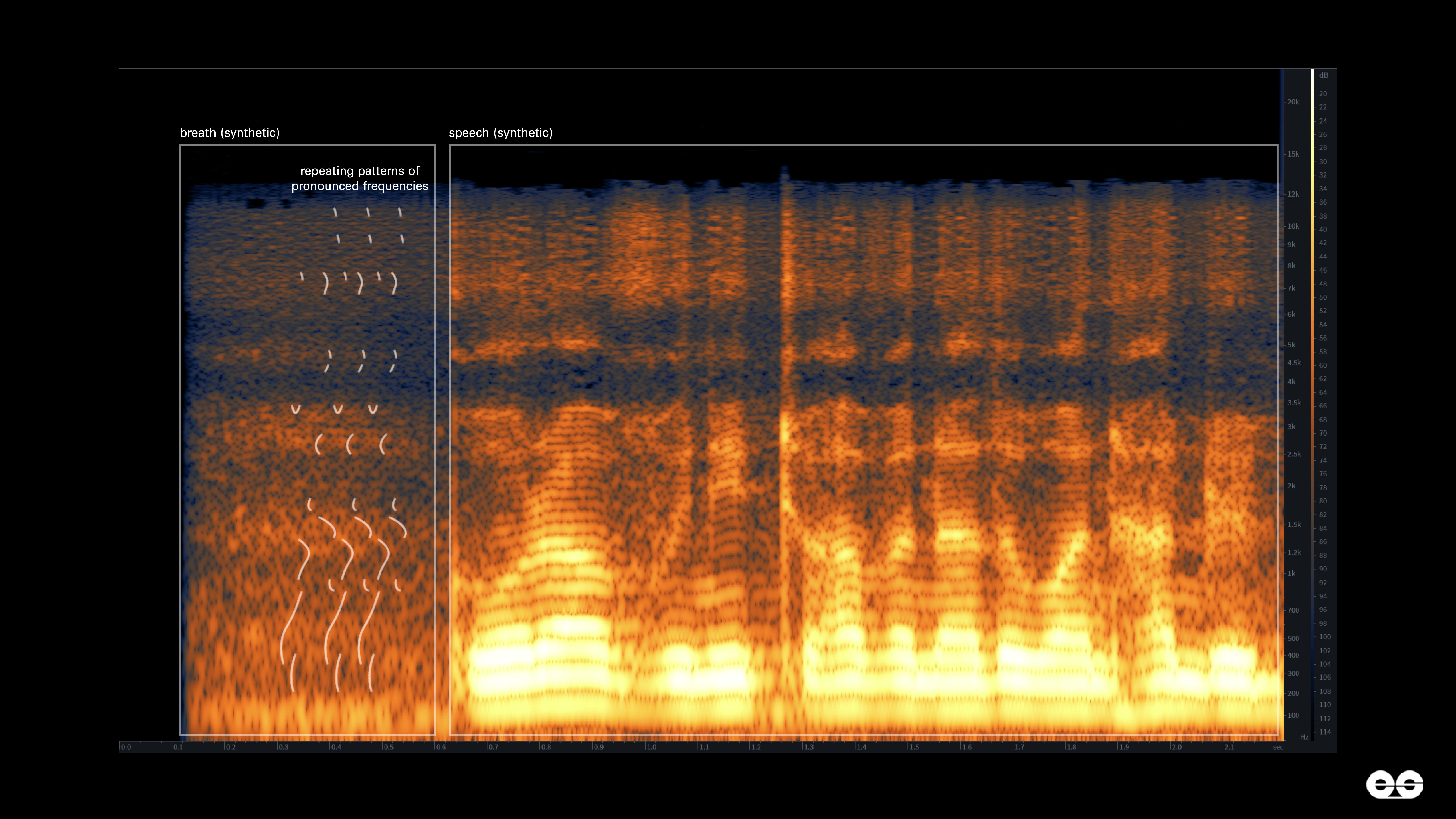
These rapid fluctuations in volume resemble the tremolo effect applied to a guitar – a rhythmic sound undulating in amplitude, not commonly found in natural speech. A seemingly innocent exhalation of air between alleged admissions of financial fraud holds the key to the larger corruption at play: the defamation of the opposition party by those in power. Artificial intelligence, it turns out, is still learning to breathe.
A natural breath, for comparison: broadband and chaotic, the sound of real air moving across a microphone.
Acoustic artefacts are also produced by the unique architecture of the space where recordings are made. Every enclosed space has a ‘modal resonance,’ or a set of frequencies at which sound waves reflect and reinforce each other. This is determined by the room’s dimensions, shape, and construction materials. When a sound containing those specific frequencies is introduced into the room (e.g., by a loudspeaker or a crowd cheering), the room is acoustically “excited,” and those frequencies will ring out longer and sound louder than others.
In March 2026, we analysed a recording in which a top aide to Ali Khamenei is heard addressing IRGC commanders, in the period following Khamenei’s death in a US-Israeli strike. The aide recounts a separate strike on the home of Khamenei’s son Mojtaba – aimed at him in anticipation of his succession – and how Mojtaba had survived. With Mojtaba subsequently elected as Iran’s new supreme leader, authenticating this recording took on significant weight. With no public appearance to corroborate his survival, this audio was the regime’s principal channel for asserting it.
Enhanced recording showing the room resonance activated by the aide’s voice and by the response of the audience, probably IRGC commanders, at the end of the recording.
Our analysis found that the recording was likely authentic. We arrived at this conclusion by analysing resonating frequencies in the aide’s voice, heard on amplified speakers in the room, and in noises from an audience, probably IRGC commanders, in the background of the recording. The aide’s amplified voice consistently activated the specific resonant frequencies of the room, most prominently at 200 Hz, 400 Hz, and 700 Hz. Crucially, the audience’s noise present at the end of the recording activated the identical set of resonant frequencies, confirming that both the aide and the audience were in the same acoustic space (Figure 3).
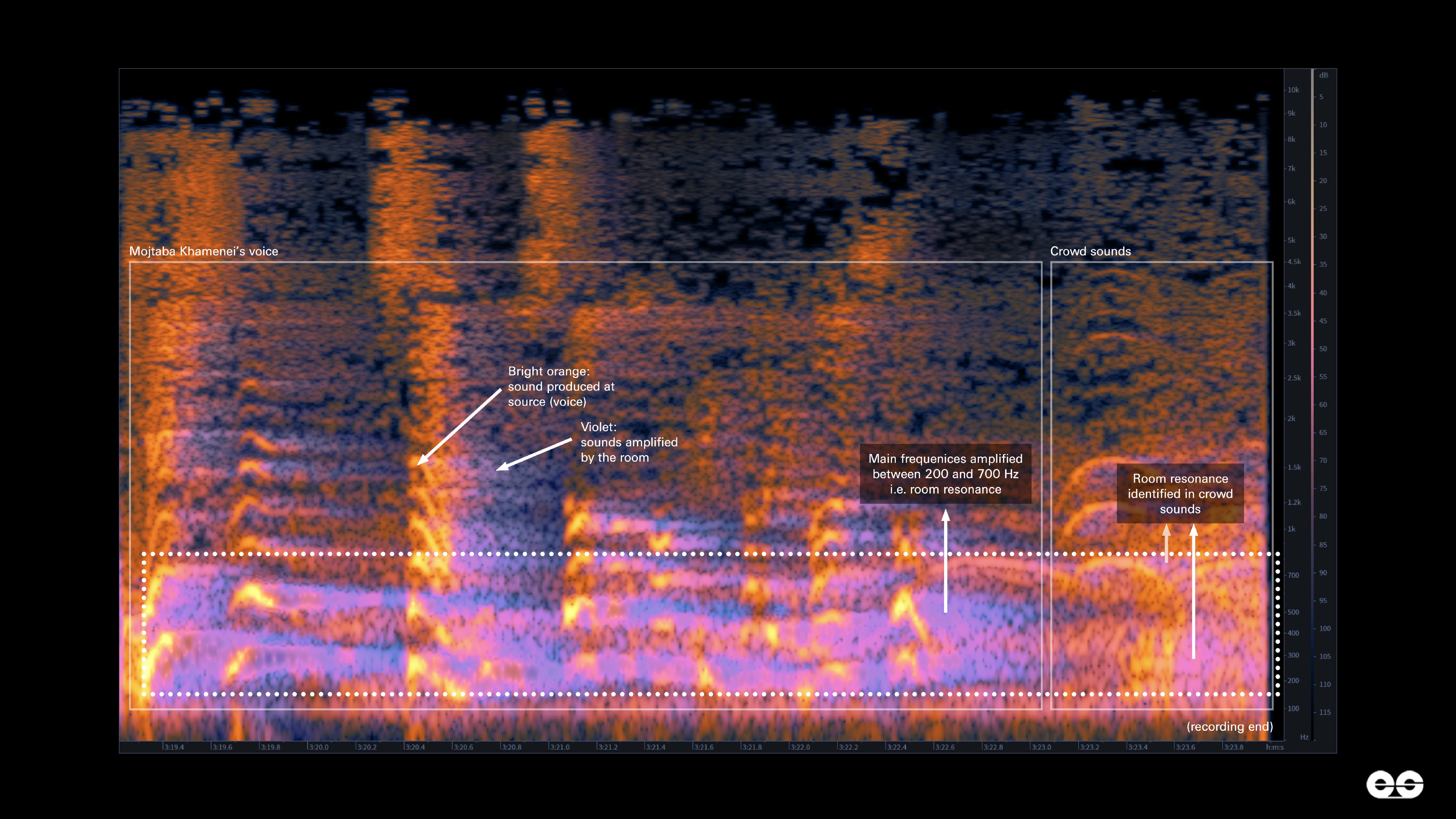
Real-world recordings are rarely without room resonances and AI generation models do not make the distinction between the frequencies of the voice and the resonance caused by the surrounding environment. Synthetically generating both speech and crowd noises with the same resonant frequency would require the model to train on recordings that already contain this same resonance, or skilled manual postproduction. Though not impossible, such a construction is unlikely.
Acoustic artefacts are produced at multiple scales – from the resonance of a large hall to fleeting sounds in and around the small components within a microphone. Microphone distortions are typically caused by physical interactions with the recording device: either through physical contact, or through quick changes in air pressure surrounding the device caused by speech. This latter form of distortion occurs when a speaker exhales strongly and directly onto the microphone, or even when pronouncing with emphasis consonants such as ‘p’ or ‘t’ and the breathier ‘f’, ‘h’ and ‘sh’. These interactions cause the diaphragm to ‘pop’ under the force of the air. While common in real-world recordings, replicating this artefact in AI-generated speech would require either deliberate insertion, or for the algorithm itself to be scripted to include the sound of a ‘pop’ around particular consonants.
In May 2026, we analysed a leaked audio from Brazil that allegedly captures the voice of Flávio Bolsonaro, a right-wing candidate in upcoming general elections. The audio was purportedly sent to Daniel Vorcaro, a banker under investigation for financial fraud. If authentic, the recording would show a previously unconfirmed connection between the banker and the Bolsonaro family.2
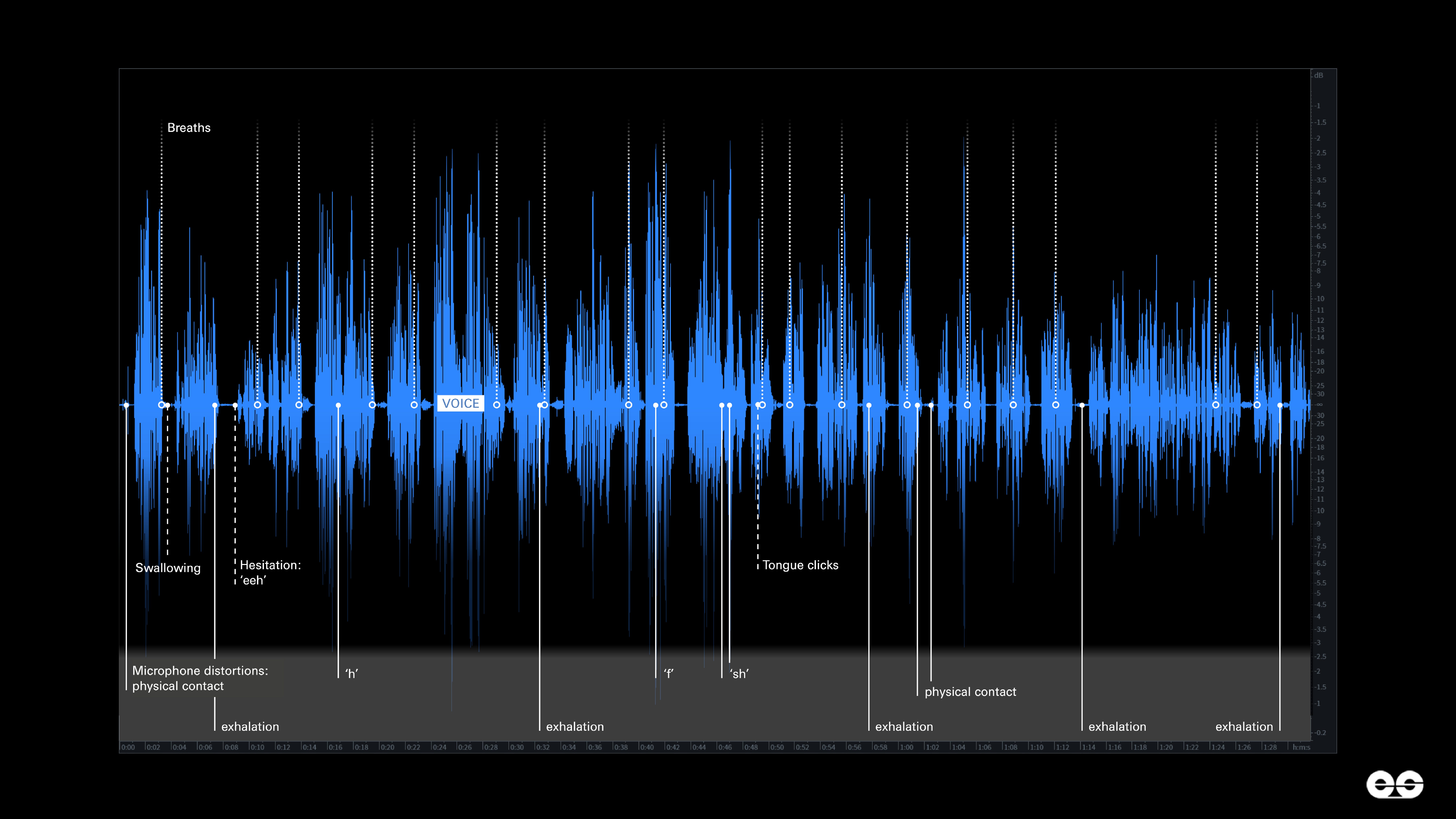
Our analysis identified multiple distortions caused by the speaker exhaling directly onto the microphone, but the distortions did not stand alone. The recording also contained a further patternwe look for routinely in our work: incidental sounds, such as vocal hesitations (‘mm’ and ‘eeh’), tongue clicks, swallowing, throat clearing.
A vocal hesitation (’eeh’) followed by a microphone distortion caused by an exhalation onto the microphone. From the recording allegedly featuring Flávio Bolsonaro.
While AI models may be able to generate these sounds, they currently require such sounds to be inserted manually into a text prompt:
‘I am sitting in a room [sigh], different from [hmm] the one you are sitting in now [clears throat].’ 34
In either case, the staging is conscious where natural speech is instinctive, and the density required to match a real recording – hundreds of small sounds at unpredictable intervals – quickly becomes impractical to sustain.
The Bolsonaro recording was thick with these incidental sounds. Together with the microphone distortions, these patterns formed a rich acoustic backdrop consistent with authentic speech (Figure 4).
These same methods were recently applied in our investigation into the Hondurasgate scandal, in which leaked audio revealed US interventions aimed at sidelining leftist governments in Central and south America.5
As the methodology section established, detection software supplements our critical listening when it helps. Here we look at one such tool in detail – Resemblyzer from Resemble AI – to show how these systems work and where they fall short.
We focus on Resemblyzer as it is open-source and narrower in scope, but there are other tools available out there, such as Phonexia (used widely in forensic voice biometrics) and Azure Speech, Microsoft’s speech analytics platform. These differ in scale and approach, but the underlying logic is the same: feed the software a sample, get back a number or a category.
Resemblyzer takes a recording and reduces all the patterns of a voice that distinguish one speaker from another into a single numerical value, a kind of vocal fingerprint. That fingerprint can then be compared against another recording of the same supposed speaker, and the comparison returns a score between 0 and 1: the closer to 1, the more likely the two voices belong to the same person; the closer to 0, the more likely they do not, and the more reason to suspect synthetic generation.
What Resemblyzer attempts is essentially the automation of phonetic analysis: pattern-matching the features of speech that distinguish one speaker from another. Used carefully, the score is useful as a cross-check: something to read against what we are hearing. But two limitations sit inside the number, and both become visible only once you understand how the score is produced.
The first is that the scale has no fixed threshold. There is no point on the 0-to-1 range at which a recording becomes definitively fake; a score of 0.6 is not a verdict, only a prompt for closer attention. Where the line falls depends on the voice, the recording conditions, and the quality of the reference material. This shifts as generative models improve, and synthetic voices score higher. The number narrows the question; it does not answer it.
The second limitation lies not just with Resemblyzer but with the field as a whole. Tools like Resemblyzer are trained predominantly on a handful of well-resourced languages, English above all. Most of the recordings that reach us are in Spanish, Portuguese, Farsi, Hindi, and Arabic amongst others, often in regional accents the model has barely encountered. So, the tool is least reliable in the languages our cases most often come in.
These two limitations point to a distinction at the heart of our work. Resemblyzer, like the broader practice of phonetic analysis, asks whether speech is consistent with a given speaker. This is the work of linguists and phoneticians, and they would not rely on a single similarity score to answer it. Their professional protocols call for multiple methods, careful comparison against reference materials, and judgement that cannot be reduced to a number. Yet in media and elsewhere, organisations increasingly do rely on automated tools alone, treating the score as the verdict it cannot honestly be.
Even at its best, this is speech analysis. It asks whether a voice is a specific person’s. Audio authentication asks a different question: whether a recording is what it claims to be. To answer it, you have to attend to everything the microphone captured beyond the voice, the world the voice inhabits. As the cases above show, it is that world – sometimes alone, sometimes in combination with the voice itself – that reveals whether a recording is authentic.
Across these cases, a single pattern holds. The evidence that settled each one rarely came from the voice alone. It came from around it: the breath too regular to be real, the room that resonated exactly as an actual room does, the microphone clipping under the force of an exhalation. AI-generated speech, for now, does not usually fail because the voice is wrong. It fails because the voice does not belong to the world it claims to inhabit.
This is the part of authentication that is hardest to automate, and the part most often missing from the conversation about it. The prevailing tools treat the problem as closed and binary, and they are built for a handful of well-resourced languages. As speech-generation tools flatten regional difference in the name of fluency, the gap widens precisely where the stakes tend to be highest. A better score will not close it. What will is a wider practice: methods that can be examined and contested, documentation of how conclusions are reached, careful attention to the acoustic conditions of a recording beyond the voice, and collaboration with linguists who know the languages and places these recordings come from.
Synthetic recordings will keep coming, and they will keep getting better, but none of that will replace the need for the practice of critical listening. Placing two modes of digital analysis in contention with one another is not the answer – both can only describe the slice of a recording that machines can model. What reveals whether a recording is authentic sits in the excess: the room, the breath, the microphone, everything the voice happens to inhabit.
Authentication, in the end, is the work of listening for coherence: whether a recorded voice belongs to its room, its moment, its claimed world.
Optional paid support: If you'd like to support our work, monthly subscriptions are available at $5.00. Earshot is the foremost independent nonprofit organization producing sonic investigations with and on behalf of communities affected by corporate, state, and environmental violence. Your support enables us to conduct investigations, develop the field, and establish sonic evidence within accountability frameworks.