I thought I was seeing fewer arXiv papers on the front page of Hacker News (HN) these days, and I wanted to check if that was real.
So I asked Claude to run a quick analysis: track the share of arXiv stories on HN over time. It queried the BigQuery HN dataset, bucketed the stories by month, and plotted the series:
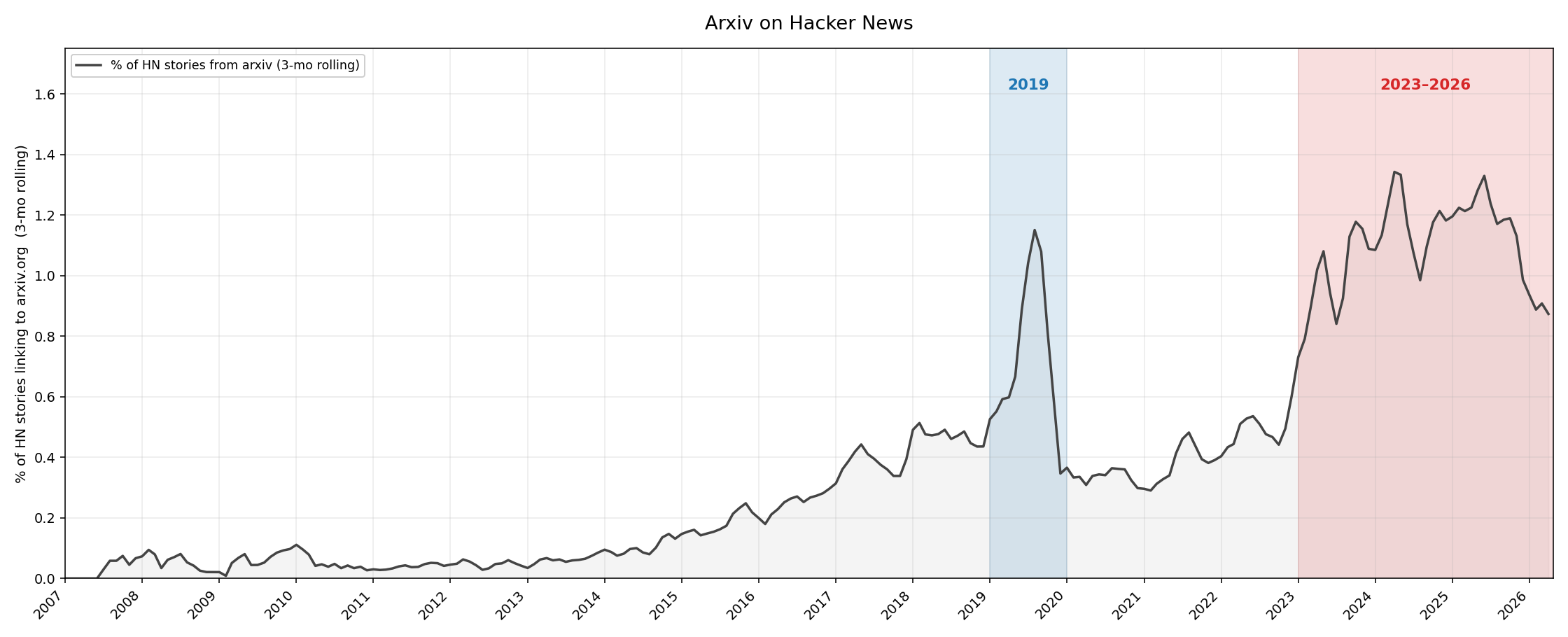
That confirmed my hunch. arXiv posts have been decreasing rapidly in the last few months. Interestingly, it also showed another peak around 2019, and I wanted to know what drove it.
I asked Claude to pull the top 100 papers by upvotes from 2019 and group them by topic. It was the deep learning peak. 41% of the top 100 were about deep learning.
Then I ran the same query for 2023-2026, to see how dominant LLMs were. 59% of the top 100 upvoted papers were about LLMs or AI.
So I asked him to make a nice chart with all of this:
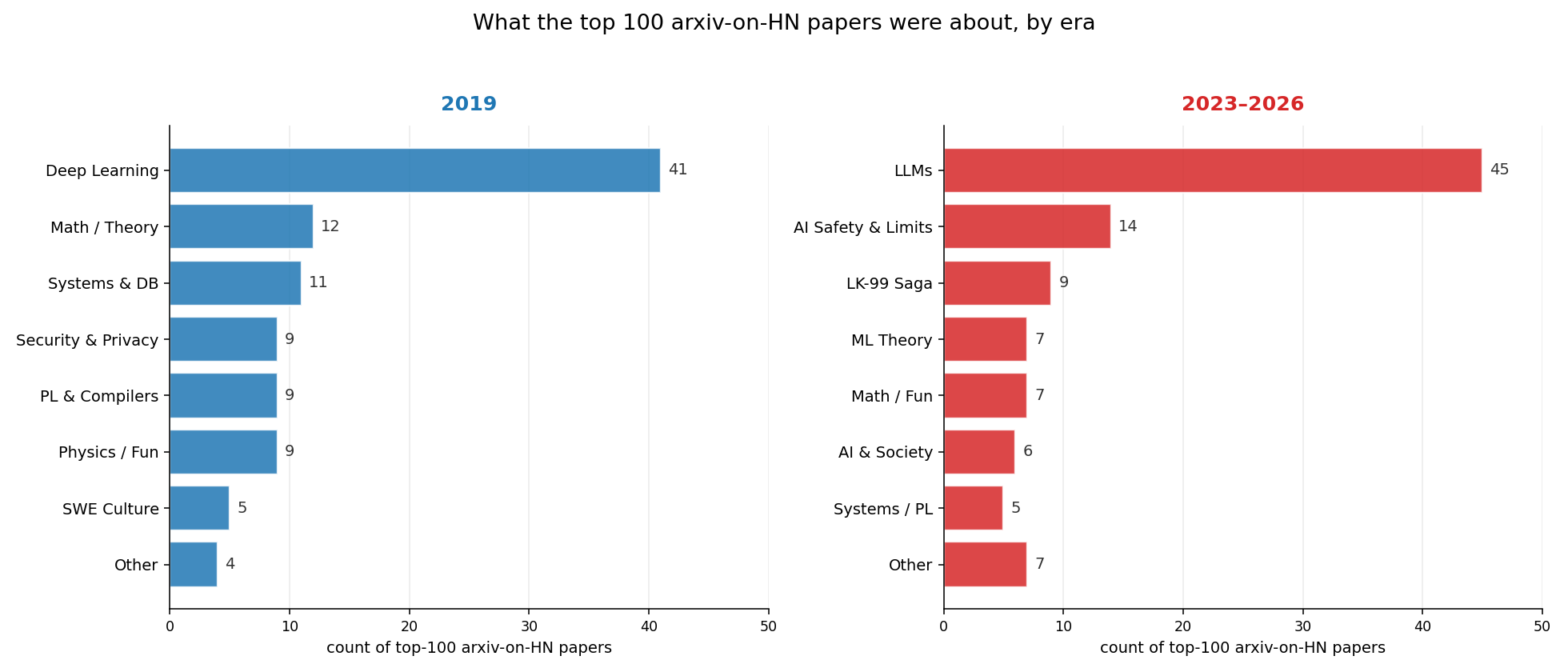
Then I wanted to see which 2019 papers aged well, so I asked Claude to pull the ones that held up from the top 100. Here’s what he got:
- MuZero — Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model (161 pts) — DeepMind’s successor to AlphaZero
- EfficientNet — Rethinking Model Scaling for Convolutional Neural Networks (119 pts) — compound scaling, set the new CV SOTA
- XLNet — Generalized Autoregressive Pretraining for Language Understanding (79 pts) — briefly dethroned BERT
- PyTorch: An Imperative Style, High-Performance Deep Learning Library (113 pts) — the NeurIPS paper formalizing PyTorch’s design
- On the Measure of Intelligence (80 pts) — Chollet’s ARC / “human-like intelligence” manifesto
It’s too early to know which 2023-2026 papers will hold up, so I asked Claude to guess:
- DeepSeek-R1 — Incentivizing Reasoning Capability in LLMs via RL (1,351 pts) — first open recipe for o1-style reasoning via pure RL on verifiable rewards
- Generative Agents — Interactive Simulacra of Human Behavior (391 pts) — the canonical “Smallville” paper, template for LLM agent architectures
- The Era of 1-bit LLMs — BitNet b1.58, ternary parameters for cost-effective computing (1,040 pts) — first credible case for low-bit inference as the default
- Differential Transformer (562 pts) — attention with a noise-cancelling term, clean architectural contribution with a real theoretical story
- LK-99 cluster — room-temperature superconductor preprints (2,408 + 1,690 pts) — landmark meta-science, not physics: open-science-at-wire-speed and the canonical case of crowdsourced replication
That was fun. Thanks, Claude.
Citation
BibTeX citation:
@online{castillo2026,
author = {Castillo, Dylan},
title = {LLM Research on {Hacker} {News} Is Drying Up},
date = {2026-04-24},
url = {https://dylancastillo.co/til/llm-research-on-hacker-news-is-dying.html},
langid = {en}
}
For attribution, please cite this work as:
Castillo, Dylan. 2026. “LLM Research on Hacker News Is Drying Up.” April 24. https://dylancastillo.co/til/llm-research-on-hacker-news-is-dying.html.