Formal verification is one of the hardest things in software engineering. You need fluency in a proof assistant, deep understanding of invariant discovery, and months – sometimes years – of dedicated effort. This expertise barrier has limited formal verification to a handful of well-funded teams working on a handful of high-value targets. Formal verification is a labour constrained activity – very costly, highly educated labour has been required to perform painstaking work of the kind few have both the skill and the patience to perform.
I’ve been wondering: what if that barrier could be removed? And what role can repository automation play in this?
So over the past few weeks I’ve developed 📐Lean Squad, a GitHub Agentic Workflow to play around with automated formal verification. And I don’t mean just “automatically proving a theorem”. I mean automating everything to do with the application of formal verification to a particular repository, including:
- Researching the codebase
- Deciding what formal verification to try to do
- Deriving a formal implementation model from the actual code (or creating a formal implementation model and documenting its correspondence to the code)
- Formulating informal and formal specifications
- Iterating on proofs
- Critiquing the work
- Maintaining the definitions and proofs under change
- Writing reports about the work.
Imagine you hire a group of formal verification professionals. You put them in a room, give them some coffee, and ask them to work diligently and relentlessly, doing whatever they do. At the extreme, the idea is that you – the “user” – might not need to know anything more. You might barely know what formal verification is. You might not know if it’s useful to your codebase. You might not really know what a specification is. You just decide you want some formal verification done, so you hire a team to do it.
Fully automated end-to-end software verification squads for hire. Maybe it’s useful. Maybe it’s not 🤷. The aim of this post is to present this form factor, this packaging, this delivery modality, this concept. It’s not to say “this is how we should do formal verification today” or even that it’s at all useful. But somewhere in the near future this is how formal verification will be delivered. So we may as well start playing around with it today.
Note: The idea of having the AI do everything came through conversation with the wonderful Cédric Fournet at Microsoft Research, who asked “where will the specs come from once we can automate the proofs and automate the correspondence?” This work doesn’t answer that question definitively, but does explore the shape of one possible answer to that question.
What is Lean Squad?
📐Lean Squad is a GitHub Agentic Workflow that applies Lean 4 formal verification to your codebase progressively and optimistically — without requiring any prior FV expertise. Each run it selects tasks weighted to the current phase of FV progress, from initial research all the way through to completed proofs, correspondence reviews, project reports, and even a LaTeX conference paper. Maybe it finds a bug; maybe it proves something; either way, it makes forward progress.
Lean Squad is the same architecture as 🌈Repo Assist, my all-singing, all-dancing repository assistant that has helped me skip and jump through green fields of software maintenance with the joy of a spring lamb. That is, Lean Squad is a declarative workflow specification that orchestrates an LLM coding agent to do a weighted selection of tasks as a scheduled GitHub Actions job – but instead of repository maintenance, it does formal verification in Lean 4. Autonomously. On a schedule. With near-zero human involvement.
You can edit and adjust the tasks in Lean Squad as you see fit, on each install. What it does is plainly laid out and fully under your control. You can also change it to use other formal verification tools, or even a mix of tools.
Lean Squad uses Copilot CLI as its coding agent by default, with its automatic model selection, though you can optionally use Claude Code, Codex or Gemini CLI.
Installing Lean Squad is just two commands (the second will ask you for an LLM API key – it costs tokens!):
That’s all there is to it.
Once installed, it runs on a schedule (every 8 hours by default). Each run:
- Reads persistent repo-memory to recover target state, phase status, and prior decisions
- Draws two tasks from a phase-weighted probability distribution over ten task types (Research, Informal Spec, Formal Spec, Implementation, Proof, Correspondence Review, Critique, CI, Report, Paper)
- Installs the Lean toolchain
- Executes the tasks – researching, writing Lean files, running `lake build`
- Creates a pull request with outputs (documents, definitions, proofs, CI files, reports)
- Updates the status issue
The weight scheme adapts automatically. When no FV work exists, Research dominates. As specs accumulate, Proof rises. Once proofs are done, reflective tasks (Critique, Correspondence Review) gain weight. Persistent memory ensures each run builds on the last.
The human can, at any stage, comment on an existing issue with /lean-squad COMMENT, or create an issue with a similar body. We call this a “nudge”, an example is here, where I wrote /lean-squad Address these concerns from critique.md, plan out rest of work, write theorems even if unproven, get the project on trajectory to completion....
Five principles underpin the design:
- Zero human involvement necessary. The agent handles everything.
- The human oversees, nudges and guides. The human merges PRs and nudges through comments.
- Optimistic. Start where the code is, find what can be verified.
- Incremental. A spec with `sorry` today becomes a proof next week.
- Critique. Steps critiquing the value of the work are built-in.
I’ve now applied it to three repositories. The results have surprised me.
raft-rs: 443 Theorems, Three Nudges
The first target was raft-rs, a production Rust implementation of the Raft distributed consensus protocol (derived from TiKV’s raft-rs). This is serious infrastructure code — 52 source files covering quorum arithmetic, log management, flow control, membership changes, and configuration validation.
I installed Lean Squad, set it to run every 8 hours, and largely walked away.
Over 34 runs spanning about 3 weeks, I watched as the automated agentic workflow:
- Surveyed the codebase and identified 22 verification targets
- Designed a six-layer proof architecture (data structures → quorum arithmetic → protocol operations → cross-module composition → Raft safety → reachability)
- Wrote all 22 informal specifications
- Wrote and proved 443 theorems across 23 Lean 4 files
- Caught one formulation bug through the “sorry” discipline
- Found no implementation bugs
The agent REPORT.md contains some nice Mermaid diagrams of the proof architecture, this from Layer 4:
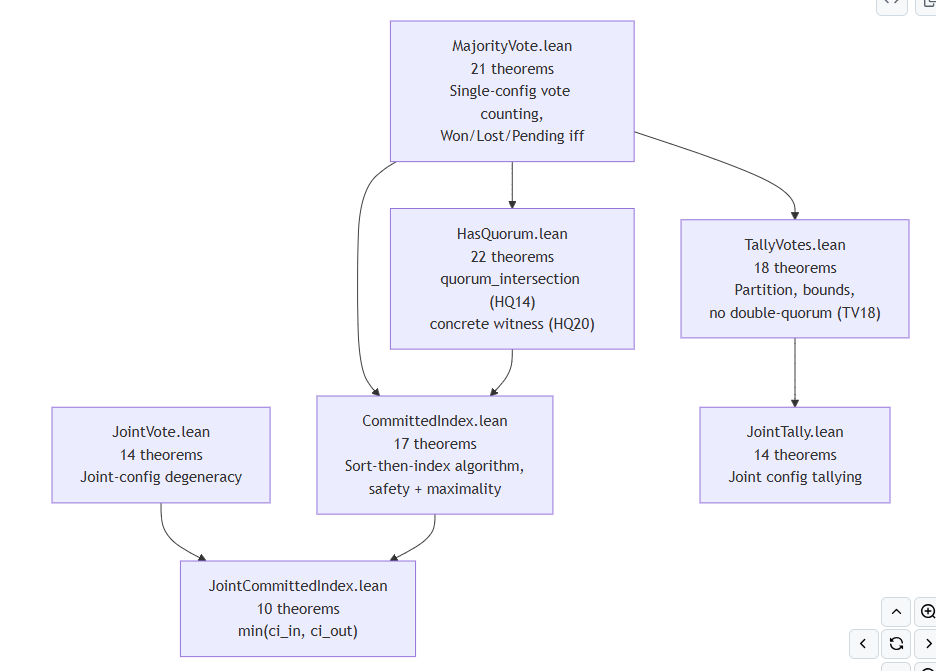
You can read the results of the agent here:
- RESEARCH.md – initial codebase survey and target rationale
- TARGETS.md – prioritised target list with phase status
- REPORT.md – comprehensive project report with proof architecture and theorem inventory
- CORRESPONDENCE.md – Lean-to-Rust mapping with all known divergences
- CRITIQUE.md – “honest” assessment of proof utility
- Lean proofs – all 23 files, 7,440 lines of Lean
The top-level formal result is raftReachable_safe: for any cluster state reachable via valid Raft transitions from an empty initial state, no two nodes ever apply different log entries at the same committed index. That’s qualified state-machine safety for Raft, machine-checked by Lean 4 with zero “sorry”.
My total intervention: three GitHub nudge comments.
- Nudge 1: “Address these concerns from critique.md, plan out rest of work, write theorems even if unproven, get the project on Trajectory to completion: ‘The main remaining gap is the state-machine level: no end-to-end Raft safety theorem exists yet for the full protocol, and joint-config analogues of SafetyComposition have not been attempted.’” (NOTE: my use of ‘write theorems if unproven’ was clumsy, see below)
- Nudge 2: “Now FV is complete, please update critique, correspondence etc. and write a final REPORT.md project report. Include mermaid daigrams in the project report to help us undersand WTF you’ve done” (NOTE: the verification was definitely not complete at this point, see below)
I never selected a target, wrote a specification, suggested a proof strategy, or debugged a failing proof. I didn’t need to know Lean. I didn’t need to know formal methods. I just needed to design the workflow and merge PRs.
There is a major caveat to this: the results proved are “bits and pieces” and not all the results are fully composed together. On later analysis, while writing this blog post, I read some of the critique more carefully and realised some major elements were missing. A later analysis added this:
The
RaftReachable.stepconstructor inRaftTrace.leanbundles 5 hypotheses as axioms about each protocol transition. …. Until concrete Raft transitions…,raftReachable_safe(RT2) is conditionally correct only: it proves safety given the hypotheses, but the hypotheses themselves are axioms rather than proved facts.~60–70% of the components needed for a fully self-contained Raft safety proof exist. The quorum arithmetic, log operations, safety composition, and CCI-threading layers are complete and correct. The missing connecting tissue is the election model — term management, vote-granting conditions, and the leader-completeness composition that would discharge
hqc_preserved. Closing the gap would require approximately 3–5 new Lean files and 100–200 additional theorems. This is the hardest single remaining part of Raft verification.
In retrospect the automated “critique” step I implemented was not strong enough, and the process allowed a form of “pseudo-completion” where key assumptions were actually present in the preconditions to the headline theorem. This secondary critique has since been applied as a further nudge and the Lean Squad is at work processing it as I write. It will be interesting to see what it comes up with next. Lesson: repeated critique is needed, and final “results” may rest on assumptions.
The total token cost of this activity was (very approximately) $240 total (this is estimating $7 per run × 34 runs, Claude Opus 4.6 pricing, though in practice the much cheaper Claude Sonnet 4.6 may be been the model used for most of the runs, I haven’t checked in detail).
Cloudflare’s quiche: 518 Theorems, An Ord Violation
My second target was cloudflare/quiche, Cloudflare’s production QUIC and HTTP/3 implementation in Rust. This is the library that powers Cloudflare’s edge network, Android’s DNS resolver, and curl’s HTTP/3 support. It’s a very different codebase from raft-rs – byte-level framing, congestion control algorithms, stream reassembly, connection ID management.
Same workflow. Same install process. Same hands-off approach. The results are at https://github.com/dsyme/quiche/tree/master/formal-verification.
After 85 runs, the agent has proved 518 theorems across 24 Lean 4 files with only 3 `sorry` remaining (two related to 8-byte varint round-trips, one for a full packet-header buffer round-trip). The self-assessment of the agent claims the proofs cover many things:
- Byte framing: QUIC varint codec round-trips, big-endian integer decode, cursor operations, cross-module write-then-read round-trips for all integer widths
- Protocol algorithms: RFC 9000 §A.3 packet-number decoding correctness (
decode_pktnum_correct), stream-ID classification laws, ACK deduplication via sorted-disjoint range-set invariants - Congestion control: NewReno single-halving per RTT, CUBIC window reduction, PRR rate bounds
- Stream I/O: full 5-clause stream-reassembly invariant (
insertAny_inv– the agent self-assessed this to be the hardest proof in the suite), flow-control safety (emitN_le_maxData), retransmit offset bounds
The only bug found was an “Ord” antisymmetry violation in StreamPriorityKey::cmp. For two incremental streams at the same urgency level, both a.cmp(b) = Greater and b.cmp(a) = Greater hold simultaneously. This violates the Rust Ord contract. It may be intentional (and the intrusive red-black tree may tolerate it), but it’s the sort of thing worth digging into.
Full artefacts:
- REPORT.md – 518 theorems, 187 examples, proof architecture
- CORRESPONDENCE.md – Lean-to-Rust mapping
- CRITIQUE.md – proof utility assessment
- RESEARCH.md — codebase survey
- TARGETS.md — target list with phase status
- Lean proofs
This verification was only of marginal interest to me, but I’ve left it running and if others would be like to help me nudge it I’d be happy to collaborate.
PX4 Autopilot: 259 Theorems, Two Bugs
My third target has been PX4-Autopilot, the open-source autopilot stack for drones and unmanned vehicles. This is safety-critical C++ code – math libraries, signal filters, ring buffers, state machines, CRC algorithms. The kind of code where bugs can crash a drone.
After 54 runs, the agent has proved 259 theorems across 20 Lean 4 files. And here, unlike raft-rs and quiche, it found what might be considered real bugs:
- Bug 1 —
signNoZero<float>: NaN returns 0. The function is supposed to always return ±1 (never 0). ButsignNoZero(NaN)returns 0, because IEEE 754 comparisons with NaN are all false. Callers that use the result as a divisor can divide by zero when the input is NaN.
- Bug 2 —
negate<int16_t>: involution error.negate(negate(-32767))returns -32768, not -32767. The C++ unnecessarily special-casesINT16_MAX → INT16_MIN; onlyINT16_MIN → INT16_MAXis needed (since-INT16_MINoverflows). The extra case breaks involution.
Both bugs were found autonomously by the agent through formal reasoning. Both are the kind of subtle edge case that testing rarely catches. The first is the most interesting, and the agent did an analysis of callers as to its possible impact:
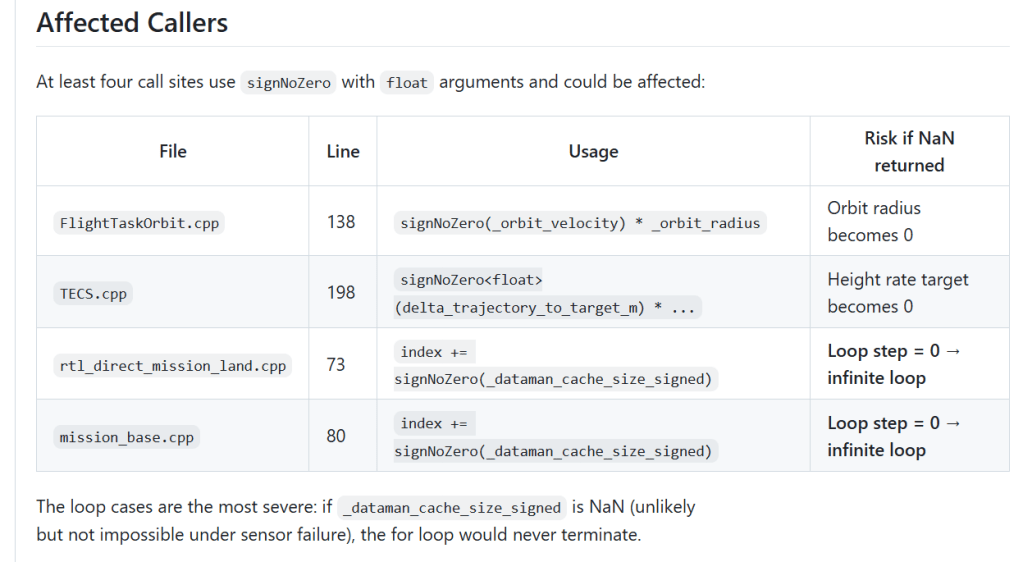
To me “Orbit radius becomes zero” sounds a bit like “Mars Orbiter crashes”. At least, it seems worth looking into.
Beyond bugs, the agent self-assessed that the proofs cover some useful safety properties of the underlying math routines as follows (note, this is agent written claims, but gives a feel for what the AI thinks its proving and why it relates to drone software):
-
slewUpdate_no_overshoot: the actuator slew-rate limiter never overshoots the target
-
rbPush_count_le_size: ring-buffer element count never exceeds capacity (eliminates a class of buffer overruns)
alphaIterate_formula: closed-form IIR filter convergence `state_n = target + (state₀ – target)·(1-α)ⁿ`, proved by strong induction with no Mathlib
superexpo_denom_pos: the denominator in the super-expo RC stick curve is always strictly positive – division by zero cannot occur
update_tf_delay_lb/update_ft_delay_lb: if a hysteresis transition committed, the dwell time was met
Full artefacts:
- REPORT.md — 259 theorems, 123 examples, 2 bugs found
- CORRESPONDENCE.md — Lean-to-C++ mapping
- CRITIQUE.md — proof utility assessment
- RESEARCH.md — codebase survey
- TARGETS.md — target list with phase status
- Lean proofs
Again I’ve left this application of formal verification progressing, and if anyone is interested in helping me nudge it I’d enjoy the collaboration.
What’s This is and Isn’t
So, we’ve shown that the same automated workflow can, in some sense, be applied to three very different kinds of software, resulting in limited kinds of end-to-end formal verification activity automatically, without the human knowing much at all, for relatively low costs.
I want to be honest about what this is and isn’t.
The proofs are real. Every theorem is machine-checked by Lean’s kernel. The sorry counts are exact. lake build passes in CI on every PR.
The definitions are AI written. Every definition and every statement of every theorem is AI written. There is no guarantee that these are “good” definitions.
The implementation models are based on the code. The ideal setup is that the AI proves facts directly about the implementation. To do this the AI must come up with Lean definitions for the implementation. In Lean Squad, it can do this either by “Path A” – using the automated tool Aeneas to translate Rust code to Lean, or “Path B” – “Path A” – writing new Lean definitions that “correspond” to the implementation code. Unfortunately I was unable to get Aeneas to successfully process the codebases from the first two examples, so Path B was chosen for both. If Path B is chosen, it is possible the AI will “make up some garbage implementation that’s easy to prove something about”. But at some level, the process originates in the code and and is rooted in it. In theory every divergence between implementation and abstraction is documented in CORRESPONDENCE.md, but the AI may miss something or make mistakes when writing this analysis.
The implementation models are still abstractions. The Lean code doesn’t model every aspect of the Rust or C++ implementations. In PX4, IEEE 754 NaN/rounding semantics are not modelled except in the case where a bug was detected by informal analysis. Again the divergence between implementation and abstraction is documented in CORRESPONDENCE.md, but may contain omissions, mistakes or hallucinations.
The theorems may have assumptions. In raft-rs, concrete message types and leader election are abstracted into the “RaftReachable” step hypotheses. This points to a need for further, stronger critique.
Not everything is modelled. In quiche, concurrency, crypto, and network I/O are not modelled. Likewise in PX4 most the implementation of the drone autopilot software is not analyzed at all.
Most theorems are glorified testing. The majority of theorems proven are very directly obvious from the code.
Training data overlap exists. Claude Opus 4.6 was almost certainly trained on Raft verification papers, QUIC RFCs, PX4 source code, and Lean 4 proof artefacts. How much this influenced the agent’s choices is hard to measure. But the proofs are machine-checked regardless of how the agent arrived at them – training data cannot produce a false positive in Lean.
All surrounding analysis is written by AI. The Reports, Correspondence and Research are all written by AI. It’s not that I “trust” the AI. I don’t, at some level, trust any of this besides the Lean proofs. This post is about the overall form factor, and how we might begin to fully automate the end-to-end, including enough critique steps to begin to make this useful.
The cost is real but falling. Approx $7 per long run at Claude Opus 4.6 pricing is not free. But compare it to the alternative: a proof engineer who knows Lean, understands distributed systems or flight control or network protocols, and is available for months. That person costs orders of magnitude more, and there aren’t many of them.
New Era, New Work
I’ve spent decades thinking about programming languages and type systems, and my PhD was on formal verification. The lessons from this stay with you forever. I’ve had long, wild dreams about LCF theorem provers and they form a major part of the heritage of and background to the design of the F# programming language. They’re part of who I am, and I recognise their beauty and truth in the design choices in Lean. The dream of foundational, provable mathematical trust is a powerful, almost ethereal one – and step by step it is becoming real and more practical.
However I am not currently “a formal verification guy”, and in truth I have not, in recent years, been “a believer” – I’m what’s known as “a refugee from formal verification” (thank you Jim Grundy for that gem!). That is, like many others I came, during my PhD and my time at industrial research labs, to believe that the value of formal software verification has been wildly over-estimated by generations of proponents, vis.a.vis the cost of actually doing it in industry. This has been a harsh but realistic perspective: unless you’re part of the cult, it’s pretty clear that the labour cost of doing formal verification is astronomically high, and the rate of bug finding is relatively low. There is another reason to be skeptical, which is that FV has historically often been justified under a “safety” and “reliability” agenda, while often guaranteeing only technical properties. And yet, the depth of insight in the formal verification agenda is genuine – the number and quality of publications you can generate through publishing about the underlying techniques is high, and the insights deeply profound. And there are undoubtedly good and important practical uses of formal verification for the most critical software designs and implementations.
So, prior to the era of AI-assisted proof, I have always said this: formal verification is a wonderful area of research, and it deserves long term funding. It should be applied to hardware design and some super-critical codebases. But for the vast majority of software (measured by developer time), it has been too expensive. This means “belief” and “hope” in FV has been both well-founded (because of research insights and practical utility on super-critical codebases) and delusional (falsely claiming broad practical utility or higher level “safety”). Both these things can be true at the same time, though as always when it comes to things mathematical, people tend to be quite emotive about this and fall on one side or another of this divide.
Will formal verification be routinely adopted if the costs are lowered and “whole task” automation achieved? Will formal verification be broadly and routinely useful, if its cost reduces dramatically? Will hybrid forms of AI-powered formal verification emerge that seriously contribute to much higher level system properties of “safety” and “reliability” that actual delivered software systems need? These questions are unanswered by this post – and in many ways I remain skeptical. The proof is still in the pudding, but some bits of the pudding are certainly now a whole lot easier to make.
As software construction and maintenance prices drop, formal verification will also compete for token spend with other validation techniques, e.g. automated AI code analysis, automated AI code review, automated AI test coverage improvement, automated AI UX testing, automated AI penetration testing, automated AI performance engineering, and specialised automated AI techniques for testing concurrent software. All of these will also burn tokens, and possibly find more bugs. So even if, by today’s prices, formal verification now looks cheap, it may still be “squeezed out” of the practical, routine path. If software costs $20 to create, and $40 to comprehensively test, should we spend $200 to formally verify parts of it? Sometimes! Or will there be better things to spend that $200 on? Time will tell how this plays out.
One thing I’m sure of is that we’re seeing the emergence of new high-skilled work that simply wasn’t being done before. The idea of AI leading to job losses is worrying a lot of people. But there is a flipside to increasing productivity: work that wasn’t economically tractable before may now become tractable, leading to new work, new jobs. This applies to all of supervised automated performance engineering, supervised automated repository maintenance and, here, supervised automated formal software verification. The process of applying formal verification appears more tractable than ever before. But it clearly requires skill, thought, diligence, observation, critique, oversight. A new job of the future might be to apply automated formal verification to 10s or 100s of repositories simultaneously.
Is this the end of human proof engineering or formal verification with strong human guidance (e.g. where humans write the specifications)? No, not at all, because any guidance given by talented formal engineers will massively benefit the whole process, and real questions remain about how much human input is optimal in shaping and guiding the entire process. But the assumptions have changed. Getting started with a first-pass on formal verification of real software has never been easier.
Resources
You can find me on BlueSky or drop a comment below.