DROID: A Large-Scale In-the-Wild
Robot Manipulation Dataset
DROID Dataset Team (hover to display full author list)
*Co-Lead

Getting Started
Dataset Quickstart (Colab)
import tensorflow_datasets as tfds
ds = tfds.load("droid",
data_dir="gs://gresearch/robotics", split="train")
for episode in ds.take(5):
for step in episode["steps"]:
image = step["observation"]["exterior_image_1_left"]
wrist_image = step["observation"]["wrist_image_left"]
action = step["action"]
instruction = step["language_instruction"]Abstract
The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350h of interaction data, collected across 564 scenes and 86 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance, greater robustness, and improved generalization ability. We open source the full dataset, code for policy training, and a detailed guide for reproducing our robot hardware setup.
✨ Updates ✨
- April 2025: We provide improved camera calibrations for 36k episodes of the DROID dataset on HuggingFace -- check our updated paper for how we computed these calibration values!
- December 2024: We provide an updated set of DROID language annotations on HuggingFace -- 3 natural language annotations for 95% of all successful DROID episodes (75k episodes)
The DROID Robot Platform
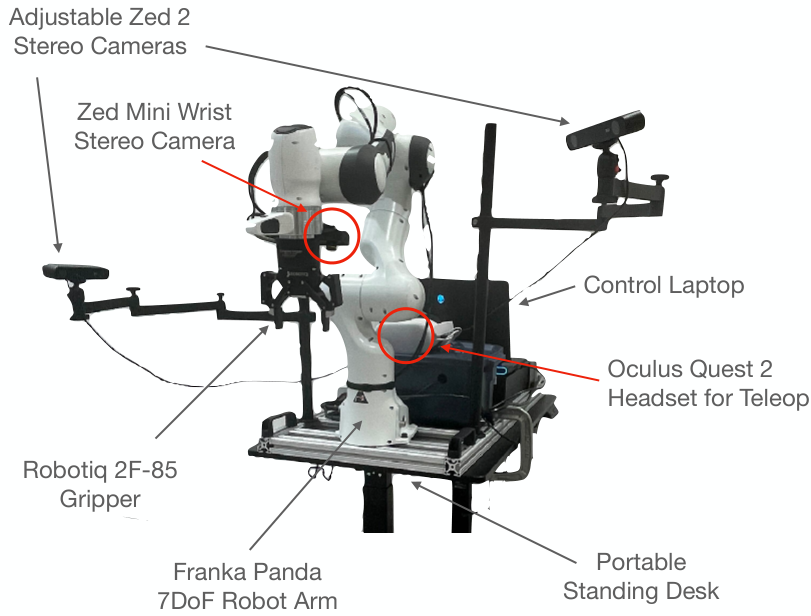
DROID uses the same hardware
setup across all 13 institutions to streamline data collection while
maximizing portability and flexibility. The setup consists of a Franka
Panda 7DoF robot arm, two adjustable Zed 2 stereo cameras, a wristmounted Zed Mini stereo camera, and an Oculus Quest 2 headset with
controllers for teleoperation. Everything is mounted on a portable,
height-adjustable desk for quick scene changes.
DROID Dataset Analysis
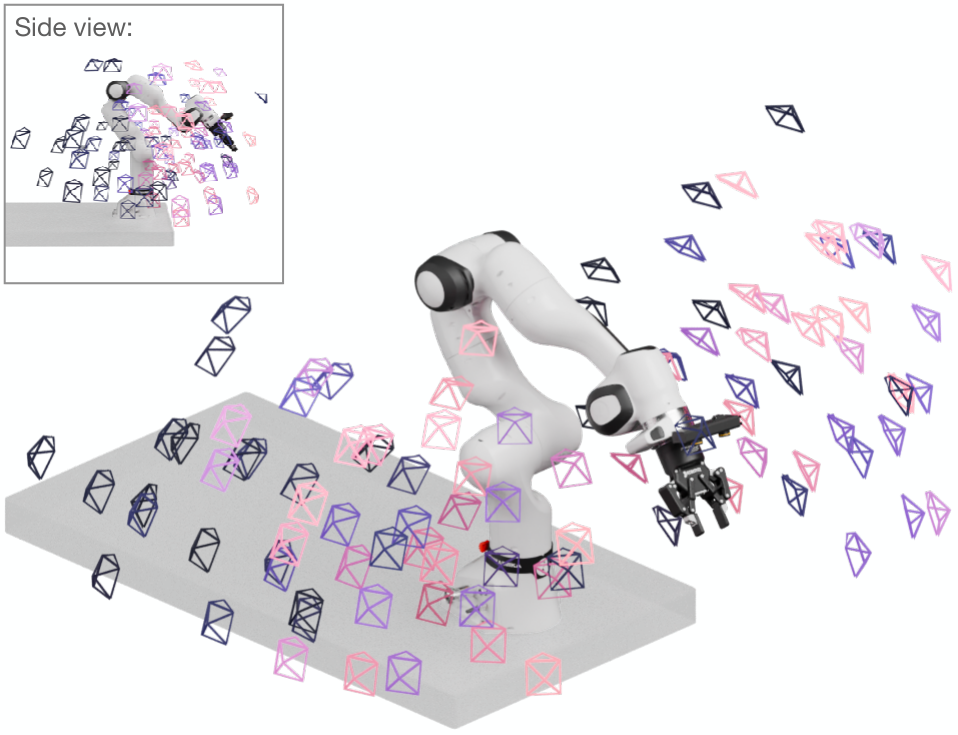
Third-person camera viewpoints in DROID (subsampled).
DROID episodes cover a total of 1417 camera viewpoints along
with intrinsic and extrinsic stereo camera calibration. Brighter colors
indicate regions of higher viewpoint density.
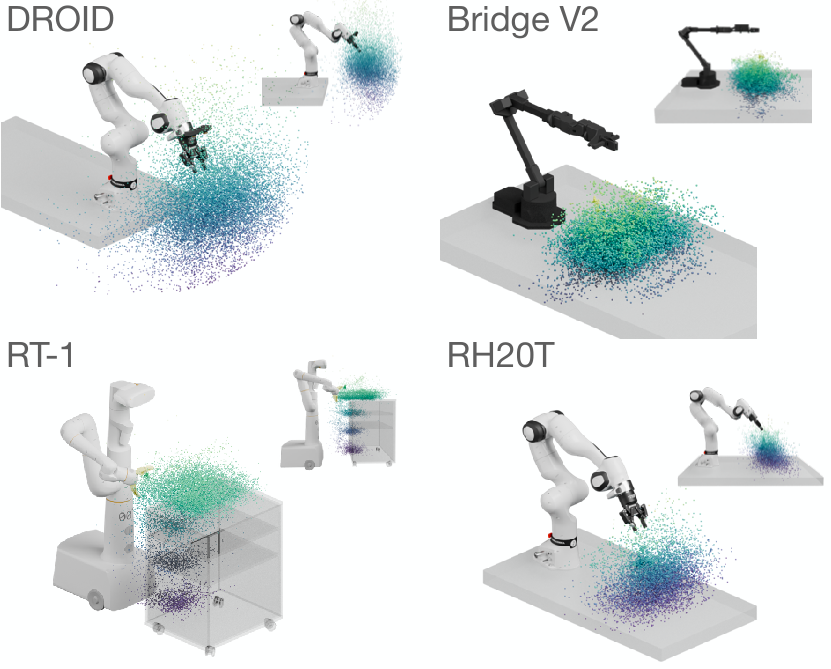 Visualization of 3D interaction points relative to the robot
base.
We visualize the 3D location at which the gripper first closes in
each trajectory, since closing the gripper often indicates meaningful
object interactions. DROID’s interactions cover a larger part of the
robot’s workspace, since the robot is moved freely between collection
sessions instead of being placed in front of repetitive tabletop scenes.
Visualization of 3D interaction points relative to the robot
base.
We visualize the 3D location at which the gripper first closes in
each trajectory, since closing the gripper often indicates meaningful
object interactions. DROID’s interactions cover a larger part of the
robot’s workspace, since the robot is moved freely between collection
sessions instead of being placed in front of repetitive tabletop scenes.
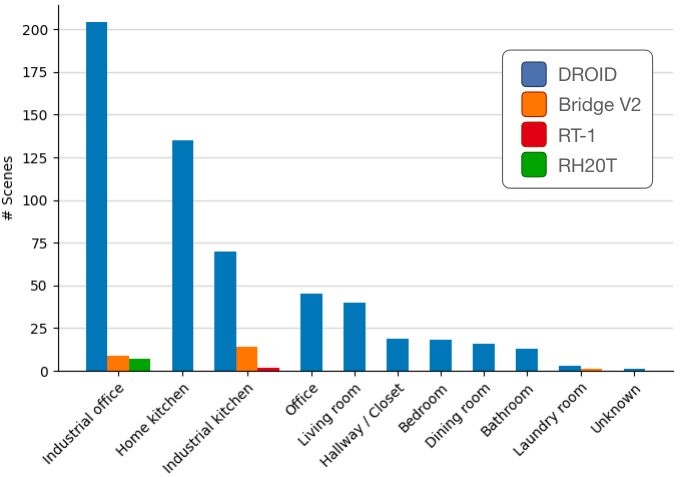
Number of scenes per scene type. DROID has an order of
magnitude more scenes than other large robot manipulation datasets,
spanning a much wider range of scene types.
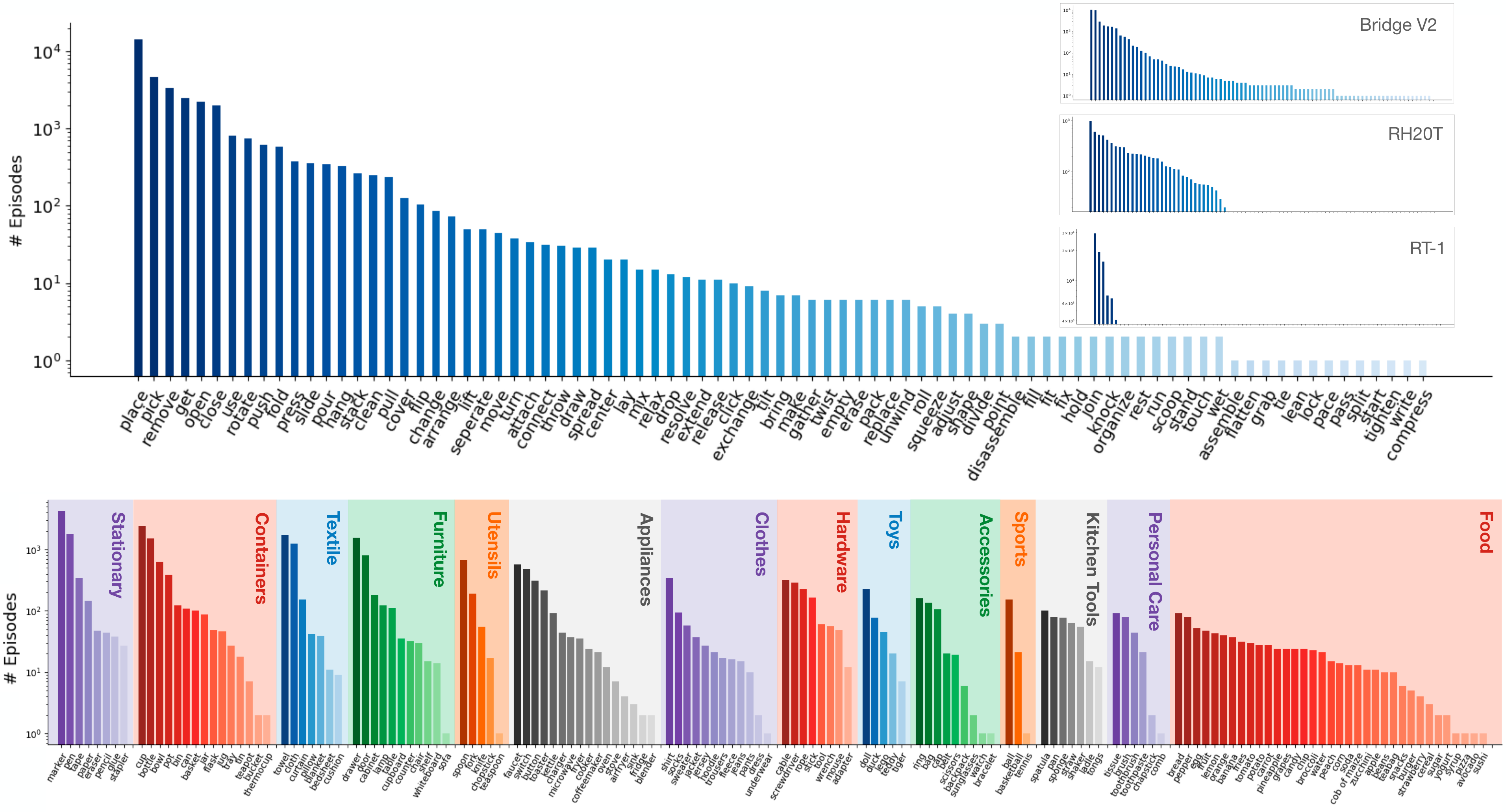
Distribution of verbs and objects in DROID
Top: Distribution of skills in DROID.
DROID features a long tail of diverse verb classes that is only matched by Bridge V2, while the RH20T and RT-1
datasets have a more constrained set of skills.
Bottom: Distribution of interacted objects in DROID, grouped by category. The robot interacts with a wide range of everyday objects.
Experiments
We investigate whether DROID can be used to boost policy performance and robustness across a wide spectrum of robot manipulation tasks and environments. To this end, we train policies across 6 tasks in 4 different locations including lab, office, and household settings, to reflect the diversity of real world robotic research use cases. All experiments use representative, state of the art robot policy learning approaches. Across the board, we find that DROID improves policy success rate while increasing robustness to scene changes like distractors or novel object instances.
Qualitative Comparison
Qualitatively, we find that policies that leverage DROID during training are notably smoother and precise than other comparisons.
Qualitative Comparison (OOD Evaluations)
We also find policies co-trained with DRIOD to be more robust to distractors and novel object instances.
Quantitative Comparison

Robot setups for policy evaluation.
We cover a wide range of tasks and scenes, from lab evaluations to offices and real households, to
reflect the diversity of use cases in real robot research.
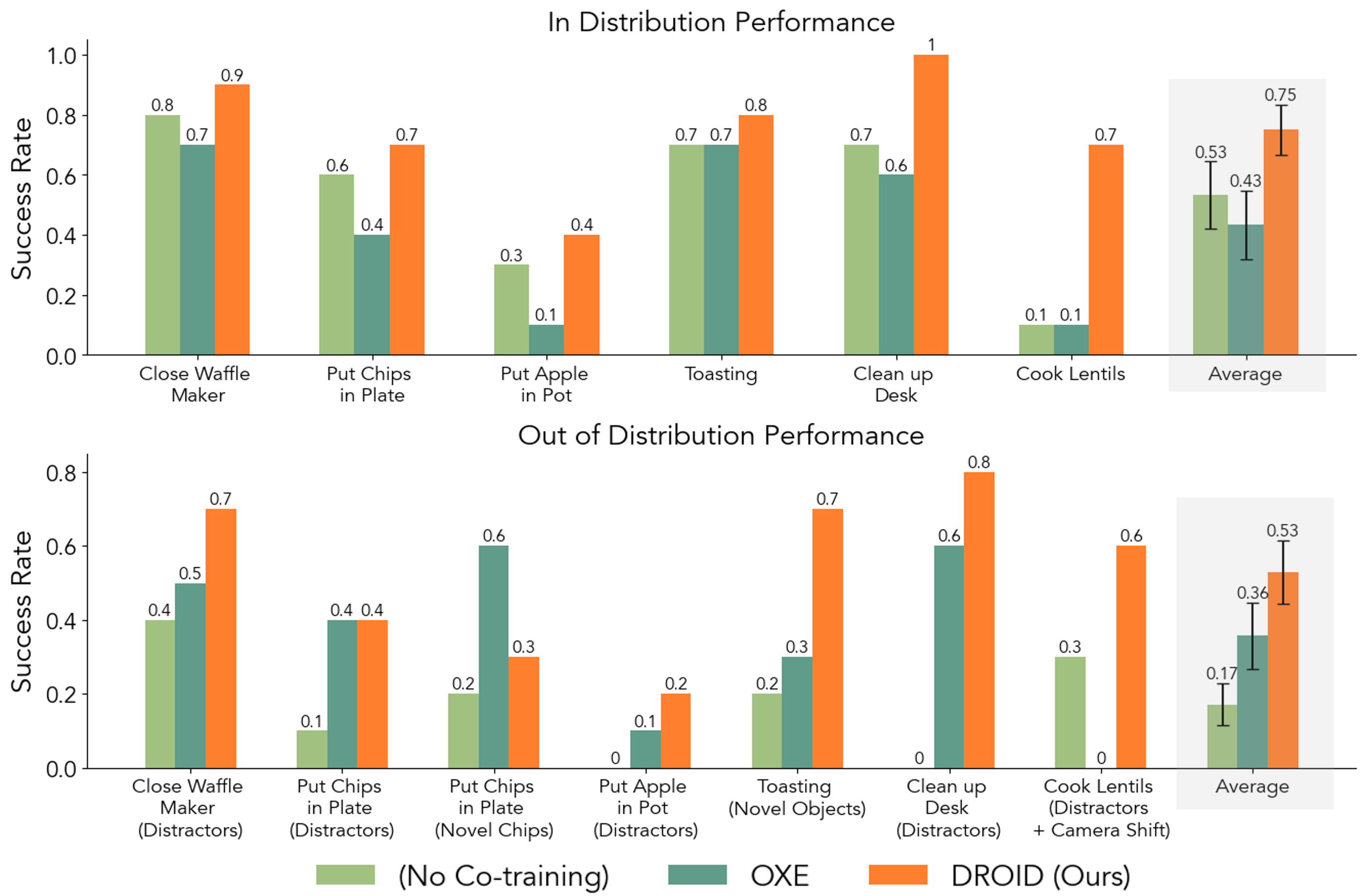
Does DROID Improve Policy Performance and Robustness?
We find that across all our evaluation tasks, co-training with DROID
significantly improves both in distribution and OOD performance over both no co-training and co-training with the Open-X dataset. We
compare success rate averaged across all tasks with standard error, and find DROID outperforms the next best method by 22% absolute
success rate in-distribution and by 17% out of distribution.
BibTeX
@article{khazatsky2024droid,
title = {DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset},
author = {Alexander Khazatsky and Karl Pertsch and Suraj Nair and Ashwin Balakrishna and Sudeep Dasari and Siddharth Karamcheti and Soroush Nasiriany and Mohan Kumar Srirama and Lawrence Yunliang Chen and Kirsty Ellis and Peter David Fagan and Joey Hejna and Masha Itkina and Marion Lepert and Yecheng Jason Ma and Patrick Tree Miller and Jimmy Wu and Suneel Belkhale and Shivin Dass and Huy Ha and Arhan Jain and Abraham Lee and Youngwoon Lee and Marius Memmel and Sungjae Park and Ilija Radosavovic and Kaiyuan Wang and Albert Zhan and Kevin Black and Cheng Chi and Kyle Beltran Hatch and Shan Lin and Jingpei Lu and Jean Mercat and Abdul Rehman and Pannag R Sanketi and Archit Sharma and Cody Simpson and Quan Vuong and Homer Rich Walke and Blake Wulfe and Ted Xiao and Jonathan Heewon Yang and Arefeh Yavary and Tony Z. Zhao and Christopher Agia and Rohan Baijal and Mateo Guaman Castro and Daphne Chen and Qiuyu Chen and Trinity Chung and Jaimyn Drake and Ethan Paul Foster and Jensen Gao and Vitor Guizilini and David Antonio Herrera and Minho Heo and Kyle Hsu and Jiaheng Hu and Muhammad Zubair Irshad and Donovon Jackson and Charlotte Le and Yunshuang Li and Kevin Lin and Roy Lin and Zehan Ma and Abhiram Maddukuri and Suvir Mirchandani and Daniel Morton and Tony Nguyen and Abigail O'Neill and Rosario Scalise and Derick Seale and Victor Son and Stephen Tian and Emi Tran and Andrew E. Wang and Yilin Wu and Annie Xie and Jingyun Yang and Patrick Yin and Yunchu Zhang and Osbert Bastani and Glen Berseth and Jeannette Bohg and Ken Goldberg and Abhinav Gupta and Abhishek Gupta and Dinesh Jayaraman and Joseph J Lim and Jitendra Malik and Roberto Martín-Martín and Subramanian Ramamoorthy and Dorsa Sadigh and Shuran Song and Jiajun Wu and Michael C. Yip and Yuke Zhu and Thomas Kollar and Sergey Levine and Chelsea Finn},
year = {2024},
}