Unleashing the Power of Large-Scale Unlabeled Data
1HKU 2TikTok 3CUHK 4ZJU
† project lead * corresponding author

Depth Anything is trained on 1.5M labeled images and 62M+ unlabeled images jointly, providing the most capable Monocular Depth Estimation (MDE) foundation models with the following features:
- zero-shot relative depth estimation, better than MiDaS v3.1 (BEiTL-512)
- zero-shot metric depth estimation, better than ZoeDepth
- optimal in-domain fine-tuning and evaluation on NYUv2 and KITTI
We also upgrade a better depth-conditioned ControlNet based on our Depth Anything.
Depth Anything is trained on 1.5M labeled images and 62M+ unlabeled images jointly, providing the most capable Monocular Depth Estimation (MDE) foundation models with the following features:
- zero-shot relative depth estimation, better than MiDaS v3.1 (BEiTL-512)
- zero-shot metric depth estimation, better than ZoeDepth
- optimal in-domain fine-tuning and evaluation on NYUv2 and KITTI
We also upgrade a better depth-conditioned ControlNet based on our Depth Anything.
Comparison between Depth Anything and MiDaS v3.1
Please zoom in for better visualization on some darker (very distant) areas.
Better Depth Model Brings Better ControlNet
We re-train a depth-conditioned ControlNet based on our Depth Anything, better than the previous one based on MiDaS.


Depth Visualization on Videos
Note: Depth Anything is an image-based depth estimation method, we use video demos just to better exhibit our superiority. For more image-level visualizations, please refer to our paper.
Depth Anything for Video Editing
We thank the MagicEdit team for providing some video examples for video depth estimation, and Tiancheng Shen for evaluating the depth maps with MagicEdit. The middle video is generated by MiDaS-based ControlNet, while the last video is generated by Depth Anything-based ControlNet.
Abstract
This work presents Depth Anything, a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, we aim to build a simple yet powerful foundation model dealing with any images under any circumstances. To this end, we scale up the dataset by designing a data engine to collect and automatically annotate large-scale unlabeled data (~62M), which significantly enlarges the data coverage and thus is able to reduce the generalization error. We investigate two simple yet effective strategies that make data scaling-up promising. First, a more challenging optimization target is created by leveraging data augmentation tools. It compels the model to actively seek extra visual knowledge and acquire robust representations. Second, an auxiliary supervision is developed to enforce the model to inherit rich semantic priors from pre-trained encoders. We evaluate its zero-shot capabilities extensively, including six public datasets and randomly captured photos. It demonstrates impressive generalization ability. Further, through fine-tuning it with metric depth information from NYUv2 and KITTI, new SOTAs are set. Our better depth model also results in a much better depth-conditioned ControlNet. All models have been released.
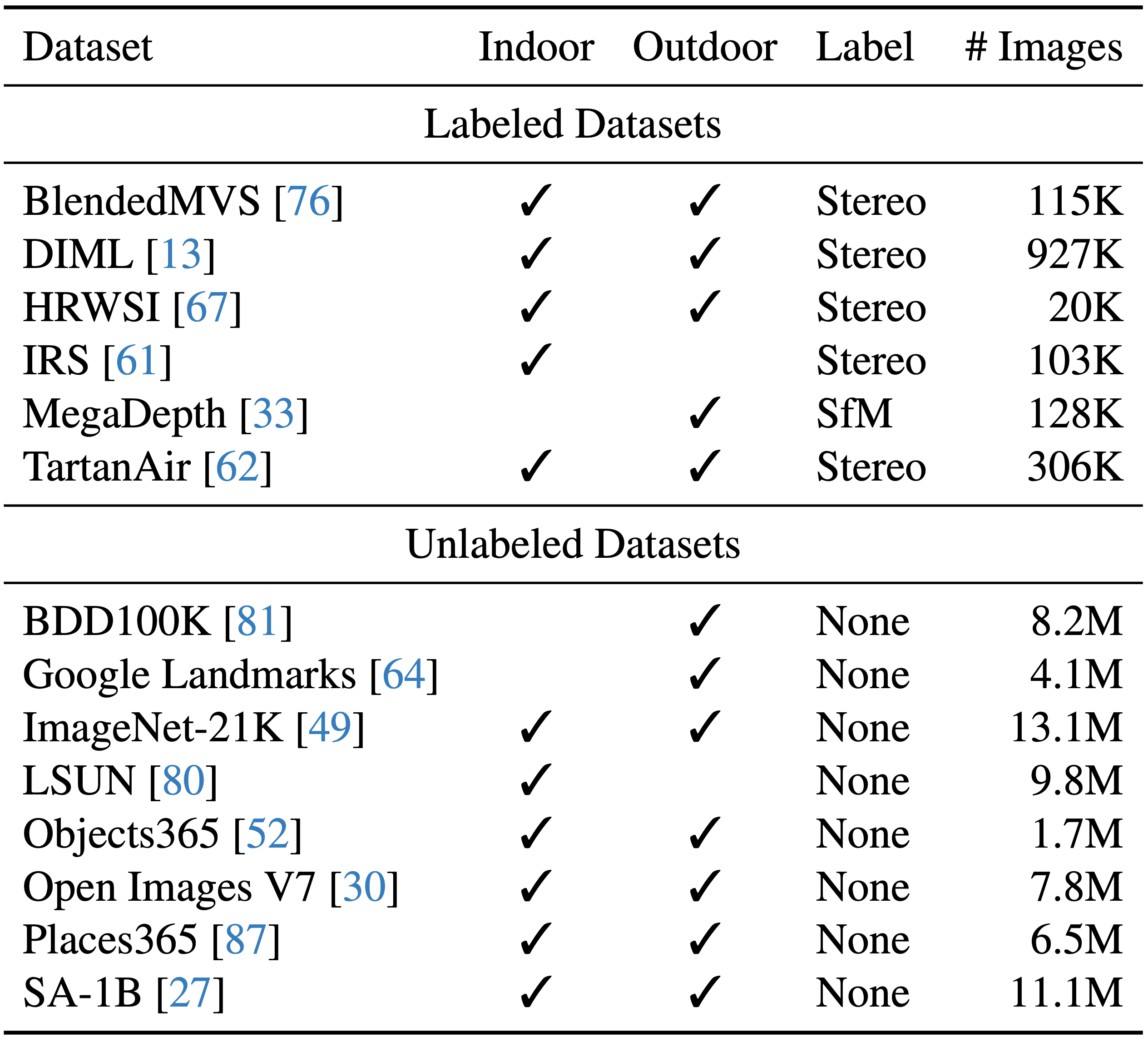
Data Coverage
Our Depth Anything is trained on a combination set of 6 labeled datasets (1.5M images) and 8 unlabeled datasets (62M+ images).
Zero-shot Relative Depth Estimation
Depth Anything is better than the previously best relative MDE model MiDaS v3.1.

Zero-shot Metric Depth Estimation
Depth Anything is better than the previously best metric MDE model ZoeDepth.

In-domain Metric Depth Estimation
Transferring Our Encoder to Semantic Segmentation
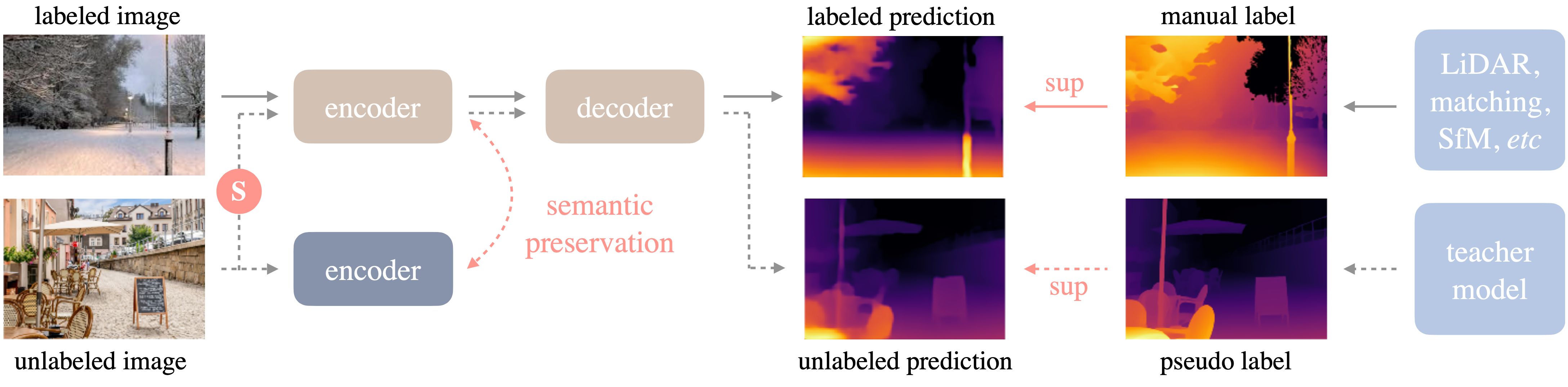
Framework
The framework of Depth Anything is shown below. We adopt a standard pipeline to unleashing the power of large-scale unlabeled images.
Citation
@inproceedings{depthanything,
title={Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data},
author={Yang, Lihe and Kang, Bingyi and Huang, Zilong and Xu, Xiaogang and Feng, Jiashi and Zhao, Hengshuang},
booktitle={CVPR},
year={2024}
}