tldr; with the DeepClause harness it’s possible increase benchmark performance of small models such as qwen3.6-35b-a3b by as much as 90%! If you’re a local LLM user and you want to get the last bit of performance out of your model, then consider trying DeepClause and especially its planning capabilities.
[The following is mostly written by a real person ;-]
It’s been a bit of common wisdom these days that non-SOTA models can be pushed towards better performance if they are paired with the right harness. As my very own (somewhat) opinionated harness called DeepClause has finally reached a more or less stable state, I’ve decided to try and see how well it would fare on a benchmark.
But let’s first try to understand what makes DeepClause different.
The core of DeepClause consists of a domain specific language (DSL) called “DeepClause Meta Language” (DML). It is build on top of Prolog and its main purpose is to concisely express LLM-based workflows and agent logic. The core predicates allow precise control of context (=the messages[] array) and orchestration of agent loops.
Here is a very short example:
tool(run_code(Code, Output), "Execute code in a sandboxed VM") :-
exec(vm_exec(code: Code), Output).
agent_main :-
system("You are a helpful coding assistant."),
user(UserMsg),
task("Help the user with their coding request.", string(Response)),
answer(Response).Some explanations are in order here:
tool/2defines a tool that the LLM can call during atask. Here it wrapsvm_exec— arbitrary code execution in a sandboxed VM. The LLM decides when to call it and what arguments to pass.system/1sets the system prompt — the instruction the LLM sees first.user/1adds that text to the conversation memory. From this point on, every subsequenttask/Ncall inherits it as context.task/Nsends the accumulated memory (system prompt + user messages) to the LLM and gets a response. During execution, the LLM can call any definedtool/2— and the arguments it passes are shaped by everything in its context.
The execution semantics of DML are those of Prolog, of course. This means that we can define branches for any predicate (including agent_main), so that failures in tasks or deterministic code will trigger backtracking. This makes DML very suitable for expressing plan and search logic (in the classical AI sense). Also, this also allows us to implement all sorts of test time compute strategies.
When it comes to local models or more generally smaller and cheaper models, we can often observe that they struggle with executing long running tasks. Even though the supported context length itself is not much of an issue anymore, it’s relatively safe to say that smaller models struggle to keep track of multi step plansinvolving e a large amount of tools calls. So, I do believe it does make sense to try to find a mechanism that constrains them in their execution logic, but leaves enough freedom to actually find a solution. This is where DML comes in. It is a simple and concise language that lends itself to express exactly those long horizon plans where small models fail. And since it can be executed deterministically, we can increase the chances of successfully finishing a longer task even with a less than SOTA model. Moreover, we can easily let a SOTA model do the planning and execute using a smaller, faster model.
The DeepPlanning Benchmark (https://arxiv.org/abs/2601.18137) is a recent benchmark that tests model long horizon planning capabilities. It is quite a challenging benchmark and a suitable candidate to test how we can improve upon base model capabilities with a smart harness.
To attack the benchmark we can now run the following steps:
Define the planner module: We write a short DML program that reads the user request incl. all constraints and produces as output an executable plan in the form of a DML program. This program can be considered as an auto generated agent tailored to a specific task.
For each problem instance in the benchmark we run the planner and execute the generated plan.
Although we could generate the DML plans in one go using an LLM with a typical coding-agent style loop, we choose a much simpler approach for the first step: Our planner DML prompts the LLM to output a list of steps as natural language descriptions and then have the planner deterministically convert the results into DML. Compared to using a full coding-agent-style loop (which DeepClause also supports) this is both simple and robust and saves us a great deal of tokens.
The generated plans then look as follows:
As we can see from this, this enforces a clear structure on what our travel planning agent can do in each task instance. Alternatively, if we were to give the request directly to an LLM plus basic harness that just runs one big agent loop, then it would be much more likely that the model would at some point struggle with executing all steps in the correct order, while simultaneously correctly reasoning about what to do with all those tool call results.
To verify this claim, let’s look at what this gives us in the case of the travel planning benchmark, which tests long-horizon agentic planning with verifiable constraints (time, budget, geography). The benchmark requires agents to gather information via tool calls, reason about local constraints, and produce globally coherent multi-day itineraries evaluated across 8 commonsense dimensions and personalized hard constraints.
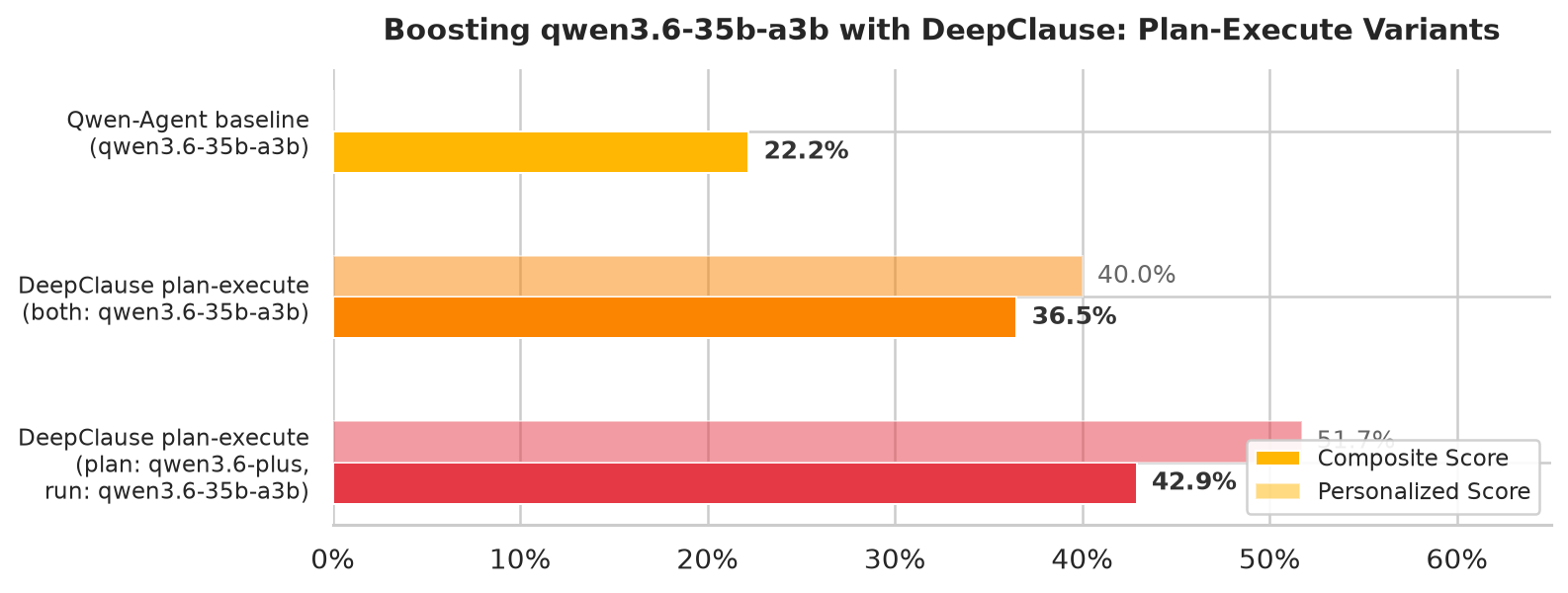
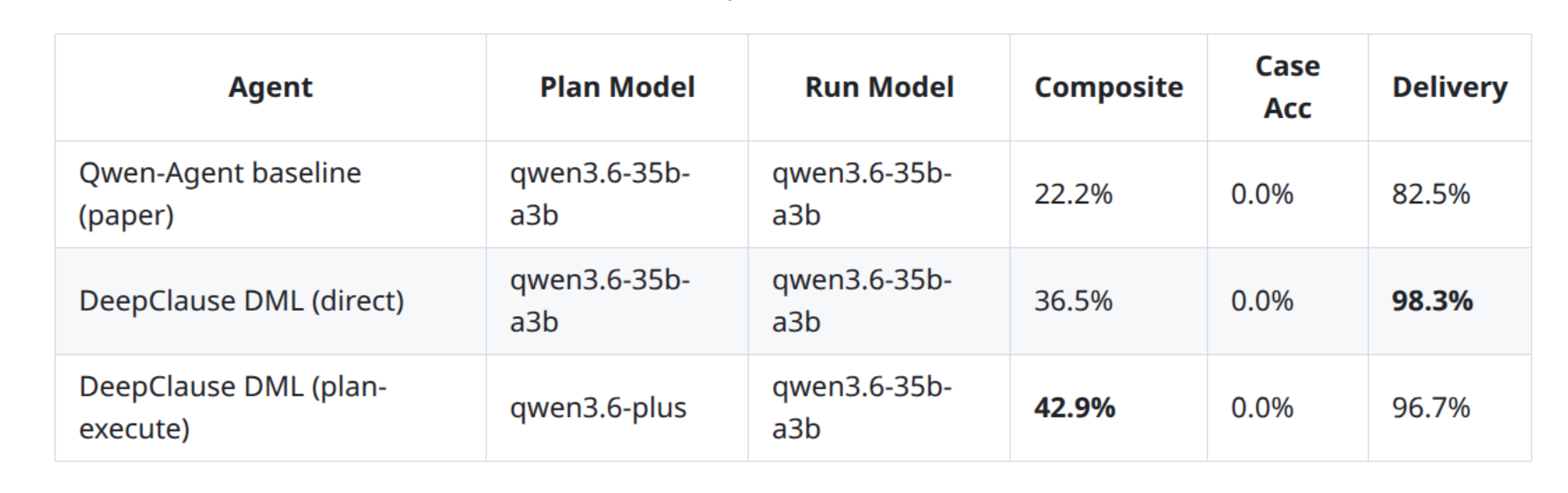
Here are the results for qwen3.6-35b-a3b:
Keypoints:
As we can see, we get an impressive boost in performance on the composite score of more than 90%!
Also, we can see that the baseline agent has a much lower delivery rate, this means it fails completely (without any result) with a higher probability than the DeepClause agent.
Why is Case Accuracy = 0? This means that none of the produced travel plan actually satisfied all constraints imposed by the benchmark. So, this Benchmark is actually very hard, even for SOTA LLMs! According to the original benchmark paper, even Gemini 3 Pro Preview only scored a measly 0.7% on this metric! This also suggests that there are plenty of more things to try with the DeepClause approach (DML natively supports constraint logic programming after all!)
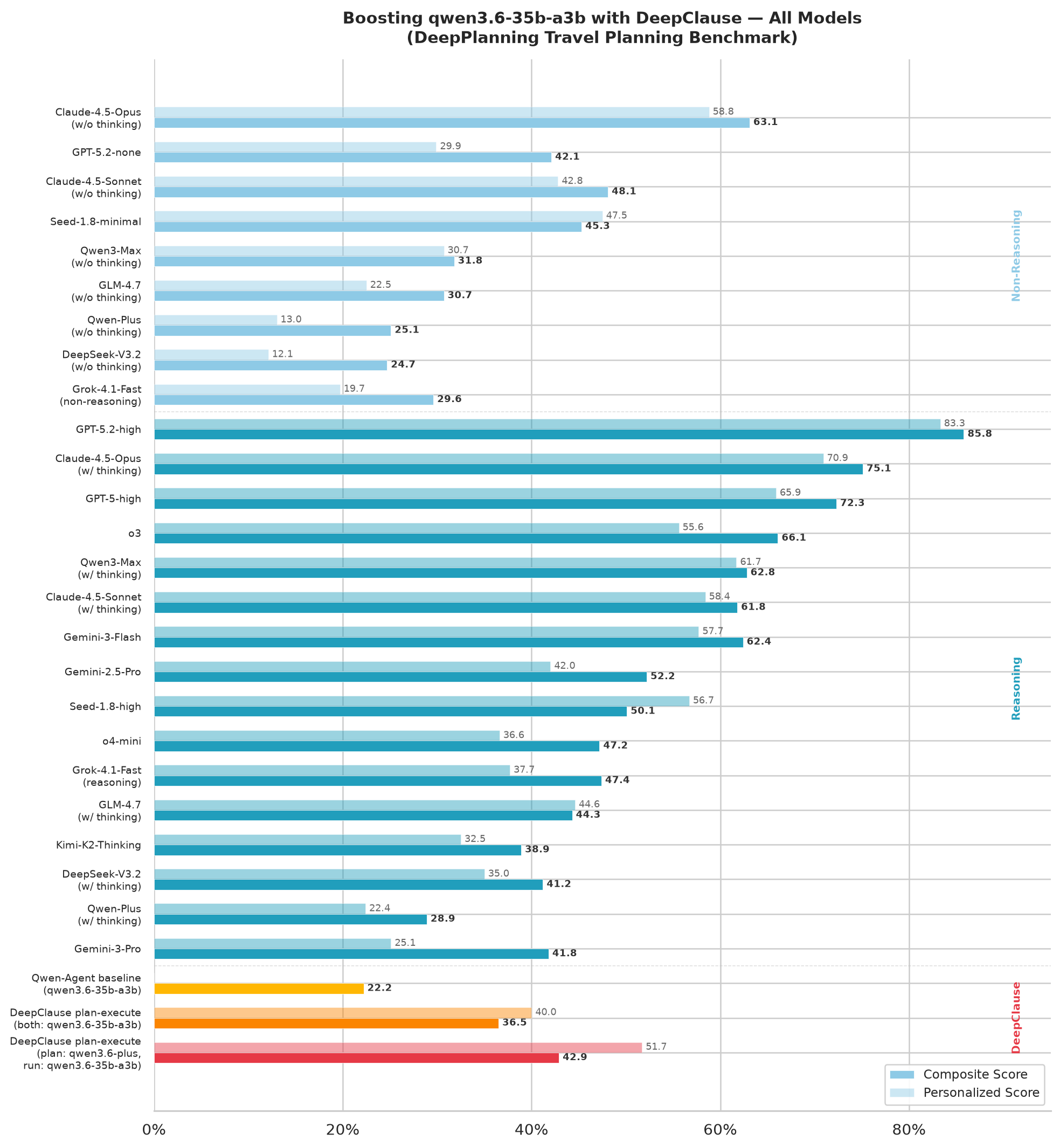
Benchmark Reference: https://arxiv.org/abs/2601.18137
Is this a groundbreaking result? Well, probably no. But it is yet another data point for the claim that we can reach acceptable performance at much lower costs (and even with local models!) if we combine the right harness with the right model
A lot of the magic happens behind the scenes: during execution, when the Prolog interpreter encounters a task predicates, it yields back to the calling Javascript loop, where the actual agent loop is implemented. This bit of code is optimized to work with smaller models (retry loops, nudging, …)
These are the results for specific model only, there are plenty of more experiments to run (Also, this is a blog post, not a paper). Anybody wants to help?
How well will this work for me and my particular use case"?? I have no idea, please try and let me know how it goes!