I keep being surprised by DuckDB.
In today’s experiment, I will be doing the following:
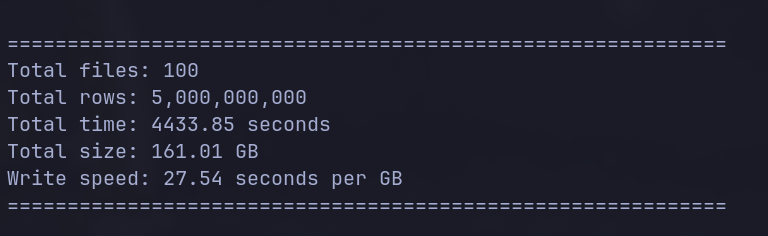
generating 100 parquet files at 50M rows each in a folder.
testing to see how long it takes to query all of the parquet files.
After running my gen_data py script for about an hour, 100 parquet files were created in my volumes/data folder.
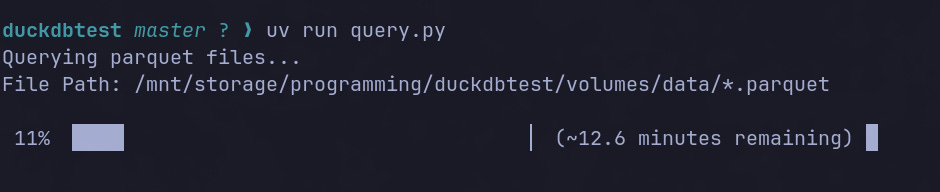
Then, I ran the query.py file, which uses DuckDB to scan the parquet files, and gets the sum of a random value column and row count for each date.
DuckDB allows you to enable progress bars which is super neat.
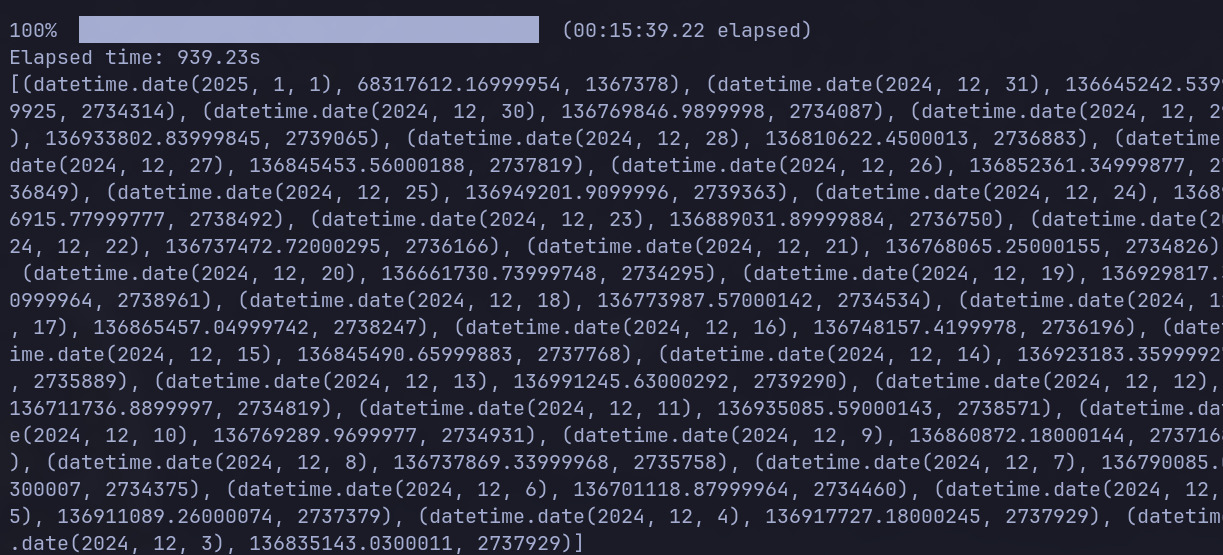
After roughly 15 minutes passed, the query returned the results. Not bad for 5B rows! :)
While this experiment was interesting, integrating this into existing data environments requires extra development. For example, it’s common to have application writes going to an existing sql server, oracle or postgresql database. If you want to plug in DuckDB into your stack, you could mimic the schema, table organization as folders, enable cdc in the transactional database, then do a full load + cdc into each folder, allowing parquet files to stream in. After that, you can set up jobs to materialize tables periodically.
In summary, DuckDB is proving to be a scalable analytics solution. I can’t wait to see it continue to grow in popularity and use cases.
Github repo here.