OUTER JOIN is a typical plague of ORM-based PostgreSQL configurations: the planner is still relatively poor at optimising it. At the same time, ORM frameworks — and 1C as a prominent example — often generate outer joins from standard templates, which opens the door to targeted optimisations. In this article, I dig into one such template — polymorphic reference resolution: what the pattern is, where it comes from (Rails, Django, Hibernate, Salesforce — not just 1C), how widespread it is, and why its structural properties make it possible to significantly speed up execution.
Think of the homepage of a typical online store — say, Amazon. Personally, on my homepage, I see ads for several products:
An air fryer
Magnesium Citrate + B6
Protein brownies
and so on.
Thinking like a database developer, I can roughly imagine that this page is built from the results of a query like:
Planning such a query efficiently is no easy task — and in my experience, this is confirmed by user reports from the 1C world, since PostgreSQL is currently not rich in LEFT JOIN optimisations. At the same time, the properties of this pattern enable the development of various techniques to improve execution efficiency. I've managed to implement several straightforward optimisations of this template. But first, let's understand what polymorphic references actually are, where they come from, and how common they really are. That's the gap I'm trying to fill with this post.
Many real-world data models contain references that can point to one of several target entity types. An order line may reference a physical product, a digital download, a gift card, or a subscription. An activity record in a CRM system may be linked to a contact, a company, or a deal. An audit log entry may refer to any entity in the system.
Relational schemas have no built-in mechanism for such references. The most common encoding uses a discriminated foreign key — a pair of columns that jointly identify the target table and the row within it:
Here item_type may contain 'product', 'gift_card', or 'subscription', and item_id stores the primary key of the corresponding table. No single FOREIGN KEY constraint can enforce referential integrity across all three target tables, so the database engine treats item_id as a plain integer column.
To resolve the reference — say, to get the human-readable name of the ordered item — the query must join against each possible target table, gated by the discriminator:
For each row in order_lines, at most one of the three LEFT JOINs finds a match; the other two return NULLs. As the number of target types grows, so does the fan of LEFT JOINs. This query form can be named the polymorphic reference resolution pattern.
The pattern has a precise structure that distinguishes it from an arbitrary collection of outer joins:
1. Mutual exclusion. The discriminator predicates in the join conditions are pairwise disjoint: for any row of the base table, the discriminator predicate of at most one join evaluates to true. In the example above, item_type = 'product', item_type = 'gift_card', and item_type = 'subscription' cannot simultaneously be true for the same row. This guarantees that at most one LEFT JOIN produces a match for each base table row. Note that if a row's discriminator value isn't represented by any join in the query (e.g., item_type = 'coupon' with no corresponding join) or the discriminator is NULL, then no join matches — the row passes through all joins with NULLs in all target table columns. The invariant is "at most one," not "exactly one."
2. Inner-side key uniqueness. The join key on each target table's side is its primary key (or at least a unique key). This is verifiable by the query planner via pg_catalog metadata. Combined with mutual exclusion, this guarantees that each LEFT JOIN produces at most one match per base table row — no join duplicates rows.
3. Column usage constraint. Every reference to a target table T_i's column in the SELECT list sits inside a COALESCE or CASE expression that evaluates to NULL when the discriminator doesn't match T_i. No target table column is used outside such a folding expression. Moreover, each folding expression must contain a contributing column from every target table participating in a LEFT JOIN in the query: if a COALESCE includes p.name and g.name, it must also include s.name — unless the LEFT JOIN contributes no column to that particular folding expression.
Thus, given invariants 1–3, for a subset of base table rows filtered by discriminator = c_k, the LEFT JOINs to all other auxiliary tables can be safely removed from the plan.
This claim covers the flat SELECT case. When a polymorphic resolution query is embedded in a larger query with GROUP BY or aggregate functions, the interaction between join elimination and aggregate semantics requires additional analysis — that's a direction for further research.
The pattern is widespread across application domains and frameworks. It appears in two distinct forms that coincide at the query level but differ in schema properties.
Polymorphic associations (no referential integrity). Ruby on Rails popularised the term "polymorphic association," implemented as a pair of _type / _id columns in the referencing table. A foreign key declaration is impossible because the target table differs for each row. When a query needs to resolve the reference, the ORM generates discriminator-gated LEFT JOINs to all candidate tables. Django's django-polymorphic library uses the same approach and documents the resulting query overhead. GitLab's engineering guidelines outright forbid this form, citing loss of referential integrity and query performance degradation observed in production.
Joined table inheritance (with referential integrity). Hibernate's @Inheritance(strategy = JOINED) places each subclass in a separate table whose primary key is also a foreign key to the parent table. The discriminator is stored in the parent table. When loading a base entity, Hibernate generates LEFT OUTER JOINs to all subclass tables in the hierarchy. Community forum threads document queries with 30–40 LEFT OUTER JOINs from hierarchies of moderate depth. Django's multi-table inheritance produces an analogous structure. Unlike polymorphic associations, joined inheritance provides referential integrity constraints between parent and child tables — but the resolution query shape remains identical.
PostgreSQL's table inheritance mechanism (INHERITS) is a partial schema-level solution to the same problem: queries against the parent table automatically include rows from child tables without explicit joins. However, INHERITS has significant limitations — no foreign key constraints on child tables, no unique constraints spanning the hierarchy, and poor interaction with some planner optimisations — which limit its applicability here.
CRM platforms. Salesforce provides polymorphic lookup fields (WhoId, WhatId) for the Activity object. A single WhatId field can reference Account, Opportunity, Campaign, or any of dozens of custom objects. Salesforce offers a TYPEOF operator in SOQL to handle polymorphic resolution without explicit joins to each target type.
Quantitative benchmarks that isolate the overhead of the polymorphic resolution pattern are rare in the peer-reviewed literature. However, developer communities and framework documentation provide substantial qualitative evidence that the cost is real.
Hibernate community forums feature discussions where developers report that loading a single entity from a JOINED inheritance hierarchy generates queries with dozens of LEFT OUTER JOINs, and that these queries dominate response time under read-heavy workloads. The django-polymorphic documentation dedicates a separate section to performance, recommending that developers use .non_polymorphic() when the specific type isn't needed. GitLab's warning on polymorphic associations is explicitly motivated by query performance degradation observed in production.
A related body of work shows that multi-join queries are inherently prone to plan-quality degradation. Leis et al. (2015) showed that cardinality estimation errors accumulate multiplicatively as they propagate through a join chain, often reaching several orders of magnitude even on well-analysed tables. The polymorphic resolution pattern with its N outer joins is susceptible to exactly this kind of error accumulation.
The database literature proposes several types of hierarchy modelling strategies that avoid the discriminated foreign key. Fowler (2002) catalogued three practically oriented patterns:
Class Table Inheritance — a common parent table plus one per subtype, with subtype primary keys serving as foreign keys to the parent. Preserves referential integrity but adds one join per query and requires two writes per insert (one to the parent, one to the subtype table).
Single Table Inheritance — all subtypes collapsed into one wide table. Avoids joins entirely but produces a wide, sparse table: columns from other subtypes are NULL for a given row, wasting disk space and complicating indexing.
Concrete Table Inheritance — completely independent tables for each subtype. Eliminates both joins and NULLs, but requires UNION ALL across all subtype tables for polymorphic queries, and schema changes to common columns must be propagated to each table independently.
Karwin (2010) devoted a chapter in SQL Antipatterns to the discriminated foreign key, calling it "Polymorphic Associations," arguing that the approach sacrifices referential integrity and query performance for schema simplicity. He recommends Class Table Inheritance ("Common Super-Table") as the preferred alternative.
Despite these alternatives, the discriminated foreign key remains dominant in practice. ORM frameworks generate it by default, and retroactive schema changes in large production systems are prohibitively expensive. Therefore, practically meaningful optimisations must accept the schema as given and work at the query execution level.
The polymorphic resolution query as presented above has no WHERE clause: the base table is scanned in full, and every row passes through N LEFT JOINs. In practice, the query often includes an EXISTS subquery filtering the base table — for example, restricting order lines to orders placed within a certain date range:
The EXISTS subquery here references only columns of the outer table — a common case in practice. How the planner handles it has a significant impact on performance, and the result depends on whether the subquery is converted to a semi-join and on the join_collapse_limit / from_collapse_limit settings.
Case 1: EXISTS remains a SubPlan (no pull-up). When the planner doesn't convert EXISTS into a semi-join — for example, because the subquery contains constructs that prevent pull-up — it's typically evaluated as a filter at or near the base table scan level. Each order_lines row is checked against the SubPlan before entering the join tree. Rows that fail the EXISTS check are discarded immediately, so only filtered rows reach the N LEFT JOINs. This is the favourable case: the base table filter prunes the fan early.
Case 2: EXISTS is converted to a semi-join (within join_collapse_limit). PostgreSQL normally converts a simple EXISTS subquery into a semi-join (see the picture below).
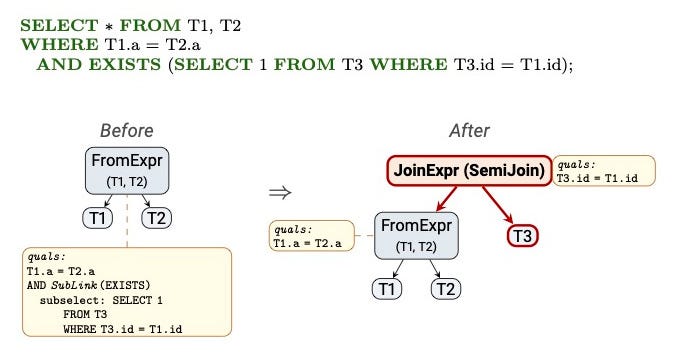
After pull-up, the semi-join's relation (orders) becomes one of the base relations that the planner considers when enumerating join orders via dynamic programming (or GEQO). The planner can consider all valid join orderings. Since the semi-join clause references only order_lines columns, and the LEFT JOINs also require order_lines an on the outer side, the planner can, in principle, place the semi-join early — joining orders with order_lines before any of the LEFT JOINs fire. With accurate selectivity estimates, the planner typically chooses exactly this early placement, preserving the filtering effect.
Case 3: join_collapse_limit exceeded. Adding the pulled-up semi-join brings more tables to the join tree. When this exceeds join_collapse_limit (default 8 in PostgreSQL), the planner preserves the syntactic JOIN nesting from the parser instead of flattening all relations into a single list for exhaustive enumeration. The limit exists because the number of join orderings grows super-exponentially with the relation count, making exhaustive search impractical for moderately large relation counts.
The LEFT JOINs form a left-deep JoinExpr tree that the planner treats as a single block, executing joins in their syntactic order. The semi-join relation, added to the top-level FromExpr During pull-up, sits outside this nested block. The planner can't wedge the semi-join into the unflattened LEFT JOIN chain — it can only attach the semi-join to the block as a whole. Result: the semi-join is evaluated against the full output of the LEFT JOIN chain. Every base table row passes through all N LEFT JOINs, and only then does the EXISTS filter check whether the order was placed this year. For large base tables with a selective EXISTS predicate, this can degrade performance by orders of magnitude compared to Case 1.
This is felt especially acutely during upgrades, when a new type of pull-up blocks early filtering of base table rows and leads to noticeable query degradation that can only be overcome by rewriting the query.
This query pattern turns out to be quite widespread. And there's no point blaming ORM systems for excessive complexity — that's just the nature of the domain and the limitations of the relational model. Performance-wise, it will execute more or less efficiently if the right indexes are in place (especially on the base table), and will immediately start dragging if the base table filter isn't covered by an index. So there's optimisation work to be done, and in future posts I'll try to describe a set of hacks for the PostgreSQL optimiser that target this pattern.
What do you think about this pattern? Do you agree with the analysis?
THE END.
May 18, 2026, Madrid, Spain.