Context isn’t a graph. It never was.
The industry spent years drawing knowledge graphs and DAGs to explain how AI “thinks.” Edges connecting nodes. Semantic relationships. Pretty visualizations that made investors feel like they understood something. Foundation Capital recently published a thoughtful piece calling “context graphs“ the next trillion-dollar opportunity—a “living record of decision traces stitched across entities and time.”
It’s a compelling framing. But I think it mistakes the map for the territory.
What’s actually emerging looks nothing like a graph. It looks like a virtual machine.
Consider what a context window actually does in production today. It allocates memory in discrete chunks—200K tokens at a time, scaling to a million. It tracks utilization rates. It implements garbage collection through summarization. It maintains state across invocations. It manages cache hierarchies with warm and cold tiers.
This isn’t prompt engineering. This is systems programming.
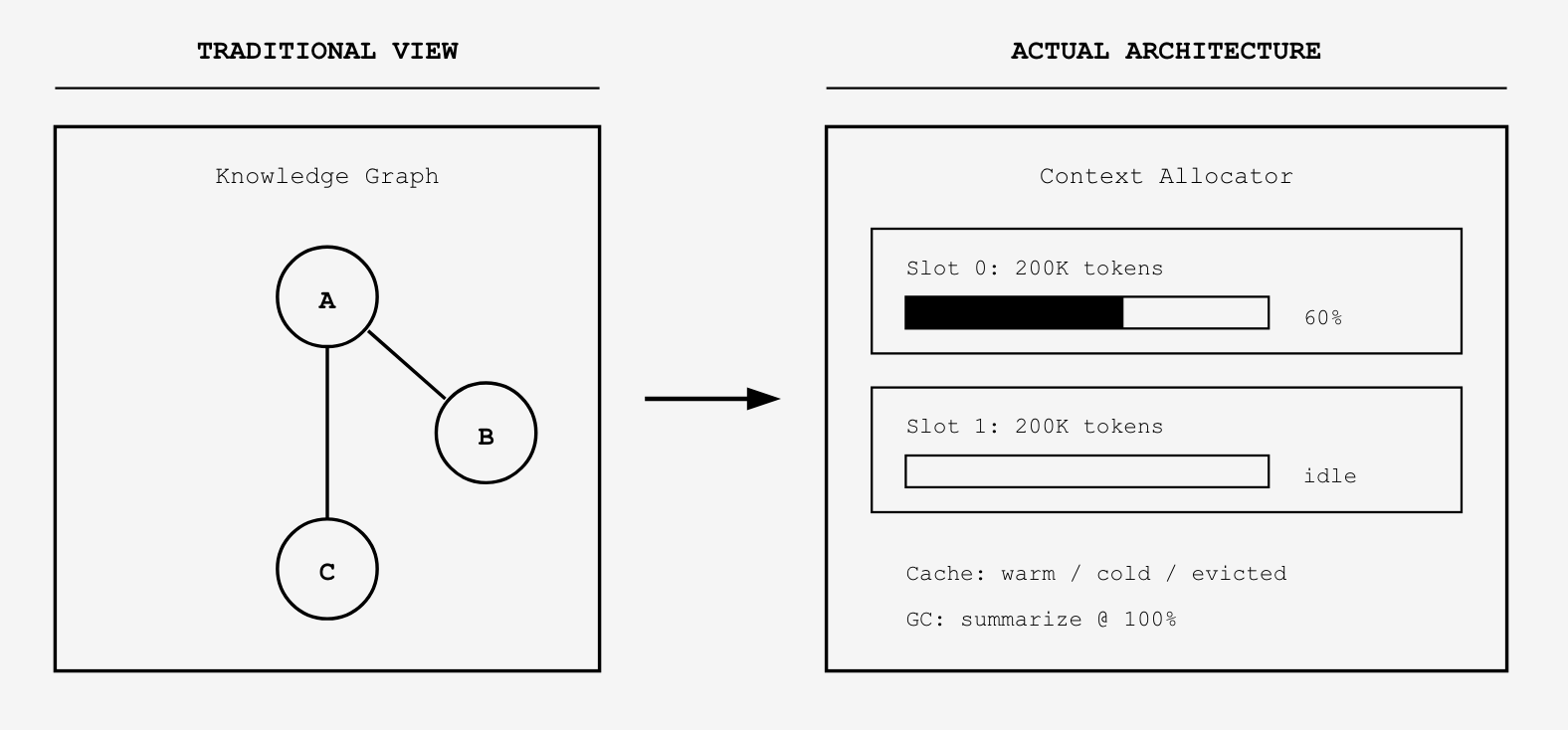
The Foundation Capital thesis suggests the valuable layer is “decision traces”—capturing why decisions were made, not just what happened. They’re right that this matters. But framing it as a “graph” obscures what you actually need to build.
A graph implies relationships between entities. Nodes and edges. Query patterns that traverse connections. That’s a fine abstraction for some problems—recommendations, fraud detection, social networks.
But context management isn’t a graph traversal problem. It’s a resource allocation problem. The questions that matter aren’t “what entities are connected?” but “what fits in working memory right now?” and “what do we evict when we’re full?” and “how do we maintain coherence across multiple execution contexts?”
These are operating system questions. And they require operating system answers.
Here’s something the benchmarks don’t tell you. Performance doesn’t degrade linearly with context utilization. It falls off a cliff around 60+% capacity.
Pack a 200K window to 120K tokens and watch what happens. Attention scores spread thin. The model starts “forgetting” things in the middle—not because the information is gone, but because it can’t allocate enough computational attention to retrieve it. The system isn’t out of memory. It’s thrashing.
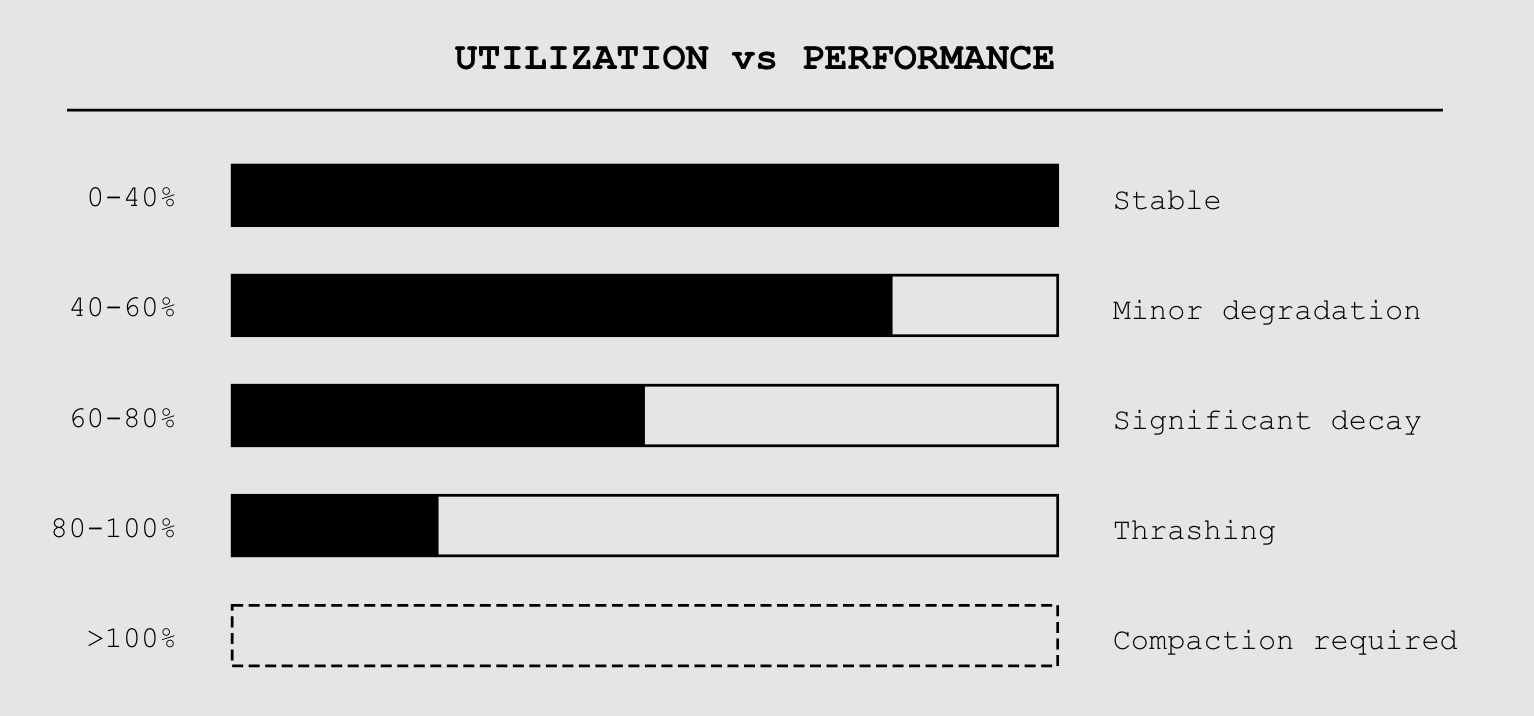
This is cache coherence, whether we call it that or not.
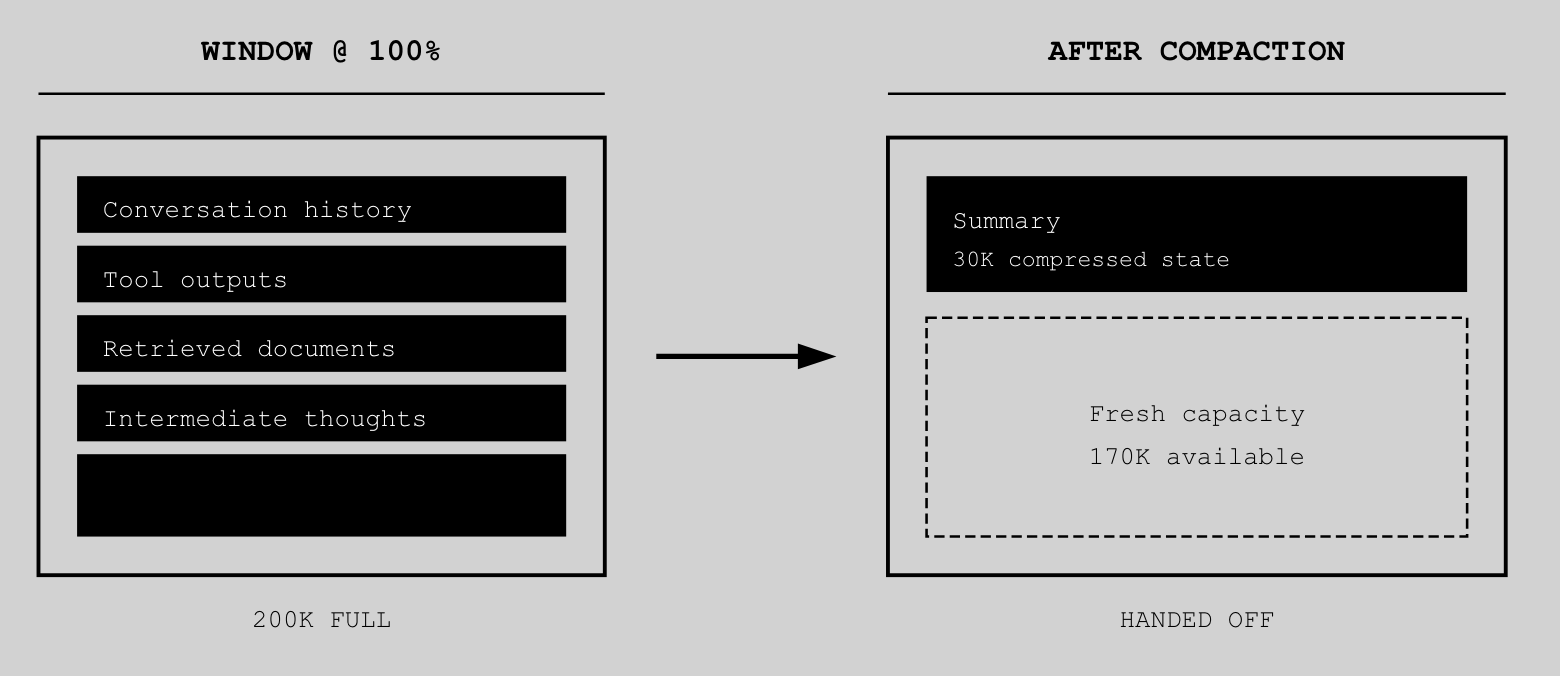
When a context window hits 100% utilization, something interesting happens. The system doesn’t crash. It compacts.
Summarization isn’t a feature—it’s garbage collection. The model distills what it knows, compresses the representation, and hands off to the next allocation unit. A 200K window full of raw conversation becomes a 30K summary that gets loaded into a fresh 200K slot.
This is exactly how operating systems manage memory pressure. Except instead of swapping to disk, we’re swapping to a more compressed representation of the same information. The fidelity loss is real but manageable—similar to lossy compression, you keep what matters and discard what doesn’t.
The context window is becoming addressable. Not byte-addressable like RAM, but chunk-addressable in ways that matter.
Different regions of context serve different functions. System instructions persist at fixed addresses—they’re loaded first and evicted last. Conversation history occupies a rolling buffer. Tool outputs get injected and then aged out. Retrieved documents get pinned temporarily, then released.
This is memory segmentation. We’re implementing .text, .data, and .stack equivalents inside a token stream.

Multi-agent systems have reinvented thread scheduling without admitting it.
When you have multiple agents coordinating on a task, what you actually have is a work queue with multiple consumers. Agents pull tasks, process them in their own context windows, and push results back to a shared state. Sound familiar? It’s the fork-join model wearing a lab coat.
The “orchestrator” agent is just a scheduler. The “tool-calling” mechanism is just syscalls. The “shared memory” between agents is just message passing. We’ve rebuilt concurrent programming from first principles, but with worse tooling.
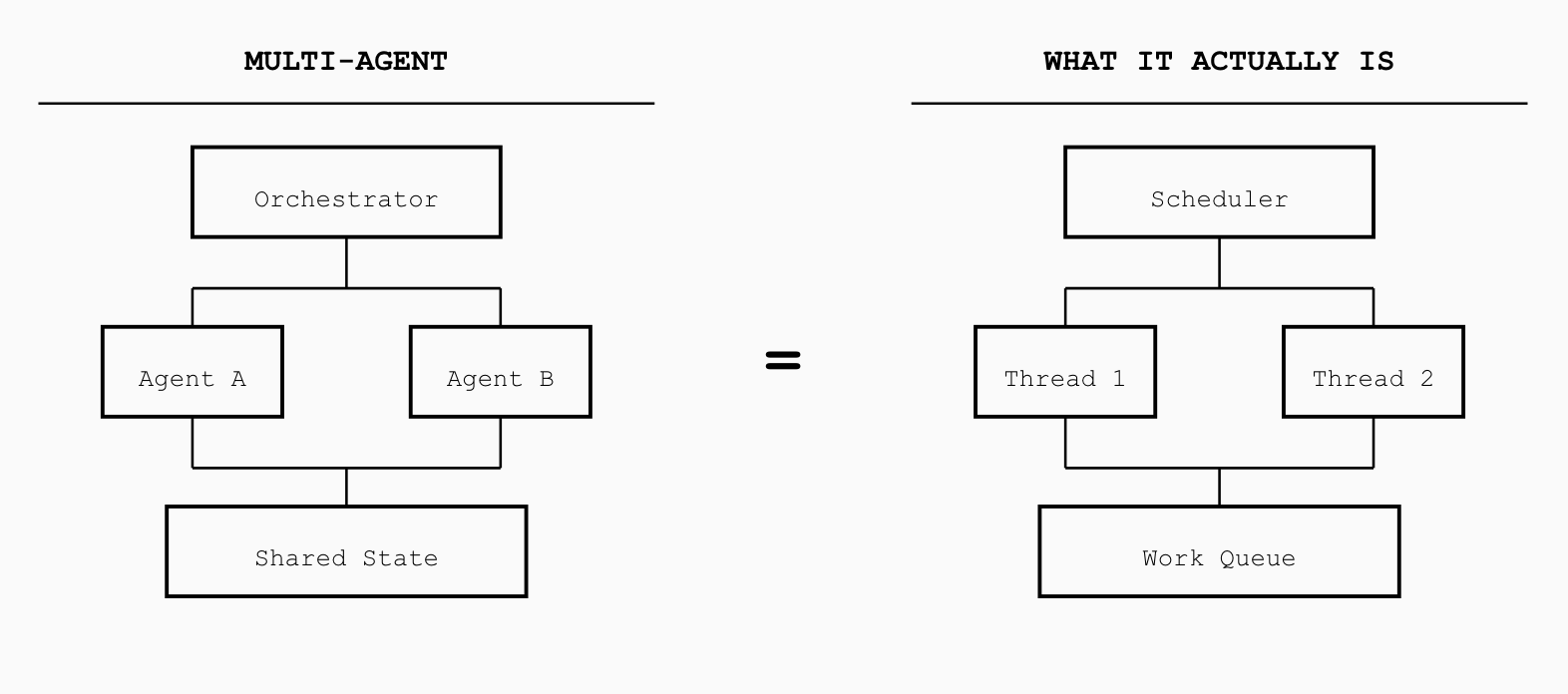
Here’s the problem nobody wants to talk about: when multiple agents share context, you need cache coherence. Agent A modifies the shared state. Agent B reads it. Did B see A’s changes? When? In what order?
This is where the “context graph” framing breaks down most clearly. Foundation Capital suggests that “systems of agents startups have a structural advantage” because they “sit in the execution path” and can capture decision traces. True enough. But capturing traces and maintaining coherence are different problems.
You can have a perfect record of every decision that was made. But if two agents made conflicting decisions based on stale views of each other’s state, your graph just contains a detailed history of how things went wrong. The audit trail is immaculate. The system is still broken.
Traditional operating systems solved this with memory barriers, atomic operations, and cache coherence protocols. AI systems are solving it with... hope. And timeouts. And retries.
We’re running distributed systems without distributed systems guarantees. Every multi-agent deployment is eventually consistent at best, and silently corrupt at worst. A graph doesn’t fix this. A coherence protocol does.
Context windows are ephemeral by design. Each invocation starts fresh—a clean boot every time. But production systems need persistence.
So we bolt on RAG systems. Vector databases. Conversation stores. Long-term memory modules. Each one is an attempt to give the context window a filesystem—somewhere to persist state across invocations, to load context from durable storage.
The Foundation Capital piece frames this as a “decision trace” opportunity: capture the why behind decisions and you’ve built a new system of record. There’s something to this. But it confuses storage with access.
You can store every decision trace perfectly. The question is: can you load the right traces into a finite context window when you need them? At what latency? With what relevance? Under what memory pressure?
This is the gap between “we have a graph” and “we have a working system.” A database that stores everything but can’t surface the right 30K tokens in 200ms is just an expensive archive. The retrieval problem is harder than the storage problem, and the storage problem is what graphs solve.
The abstractions are leaking. What we’re building isn’t a collection of independent systems. It’s a storage hierarchy pretending to be separate products.
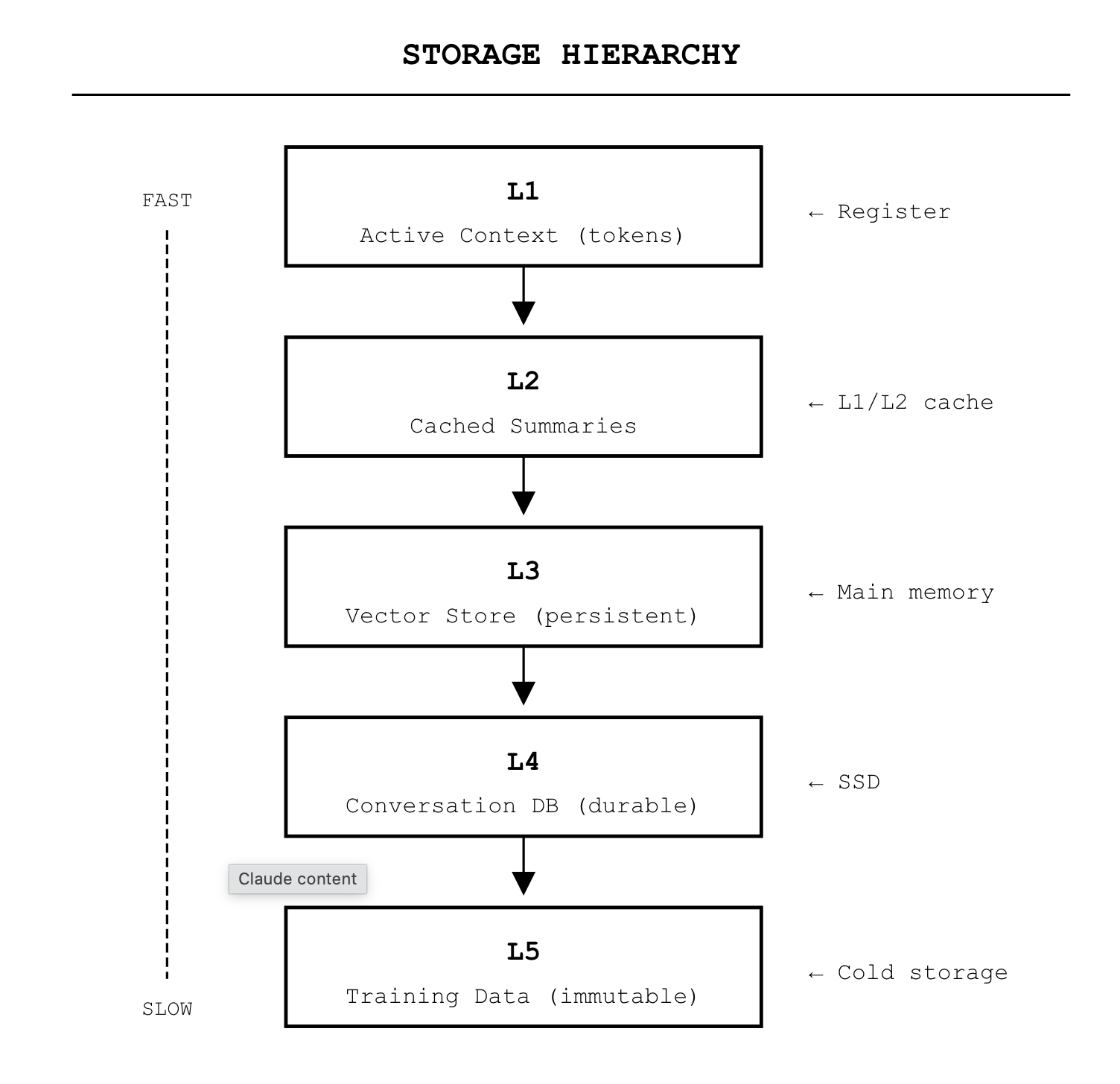
The context window isn’t becoming like a virtual machine. It is a virtual machine. We just haven’t admitted it yet.
This matters because operating systems theory is a solved problem. We know how to build schedulers. We know how to implement memory management. We know how to handle cache coherence. We know how to build storage hierarchies.
The AI industry is rediscovering all of this through trial and error, inventing new vocabulary for old concepts—”context graphs” for what are really just event logs with indexes, “decision traces” for what operating systems call audit trails, “orchestration layers” for what we used to call schedulers.
New names don’t make new problems. And new names definitely don’t make new solutions.
There’s an alternative. Take the metaphor seriously. Build context management systems that actually look like memory managers. Build multi-agent coordination that actually looks like thread scheduling. Build persistence layers that actually look like storage hierarchies.
The abstractions are there. The theory exists. We just need to stop pretending that “AI is different” and start applying what we already know.
We’re working on exactly this at Modiqo—treating context as a managed resource with proper allocation, coherence, and persistence semantics. If you’re interested in what AI infrastructure looks like when you take the operating system metaphor seriously, reach out: ask@modiqo.ai