Apache Hudi is an open-source data lakehouse platform with database-like capabilities, like ACID transactions and indexing. It is the most performant framework for handling upserts at PB-scale data in cloud storage.
A Bloom filter is a probabilistic data structure for set membership testing. To the question “Is this item currently in the set?”, a Bloom filter provides one of two answers:
No: The item is guaranteed to be absent.
Maybe: The item is likely present, but you must verify it against the master data.
It offers massive memory savings at the cost of occasional false positives (maybe case). Refer to Bloom Filters page for an interactive explanation.
Apache Hudi uses Bloom filters to skip files during upserts. When a record arrives, Hudi must determine if it already exists (update) or is new (insert). Reading record keys from every file would require too much I/O.
Instead, Hudi stores Bloom filters of its record keys in the metadata footer of data files. During record key lookups, Hudi first queries the Bloom filter. The entry point for this check is HoodieKeyLookupHandle, which processes records during the write phase:
apache/hudi:HoodieKeyLookupHandle.java#L80-L90

If the Bloom filter says “no,” the file is skipped. If it says “maybe,” the record key is added to the candidate list for verification against actual data.
mightContain tests if a key is possibly in the filter:
apache/hudi:HoodieDynamicBoundedBloomFilter.java#L102-L105

→ apache/hudi:InternalDynamicBloomFilter.java#L115-L128

→ apache/hudi:InternalBloomFilter.java#L153-L167

A standard Bloom filter requires upfront capacity.
google/guava:BloomFilter.java#L411-L435

The expected number of elements and desired false positive rate must be specified to size the filter - number of bits and hash functions to allocate - correctly.
google/guava:BloomFilter.java#L525-L554

If more elements are inserted than the capacity, the false positive probability increases sharply. For most data workloads, predicting record counts per file is nearly impossible. Sizing the filter to a maximum possible value causes waste in memory and storage.
How do you get probabilistic membership checks without knowing your dataset size ahead of time?
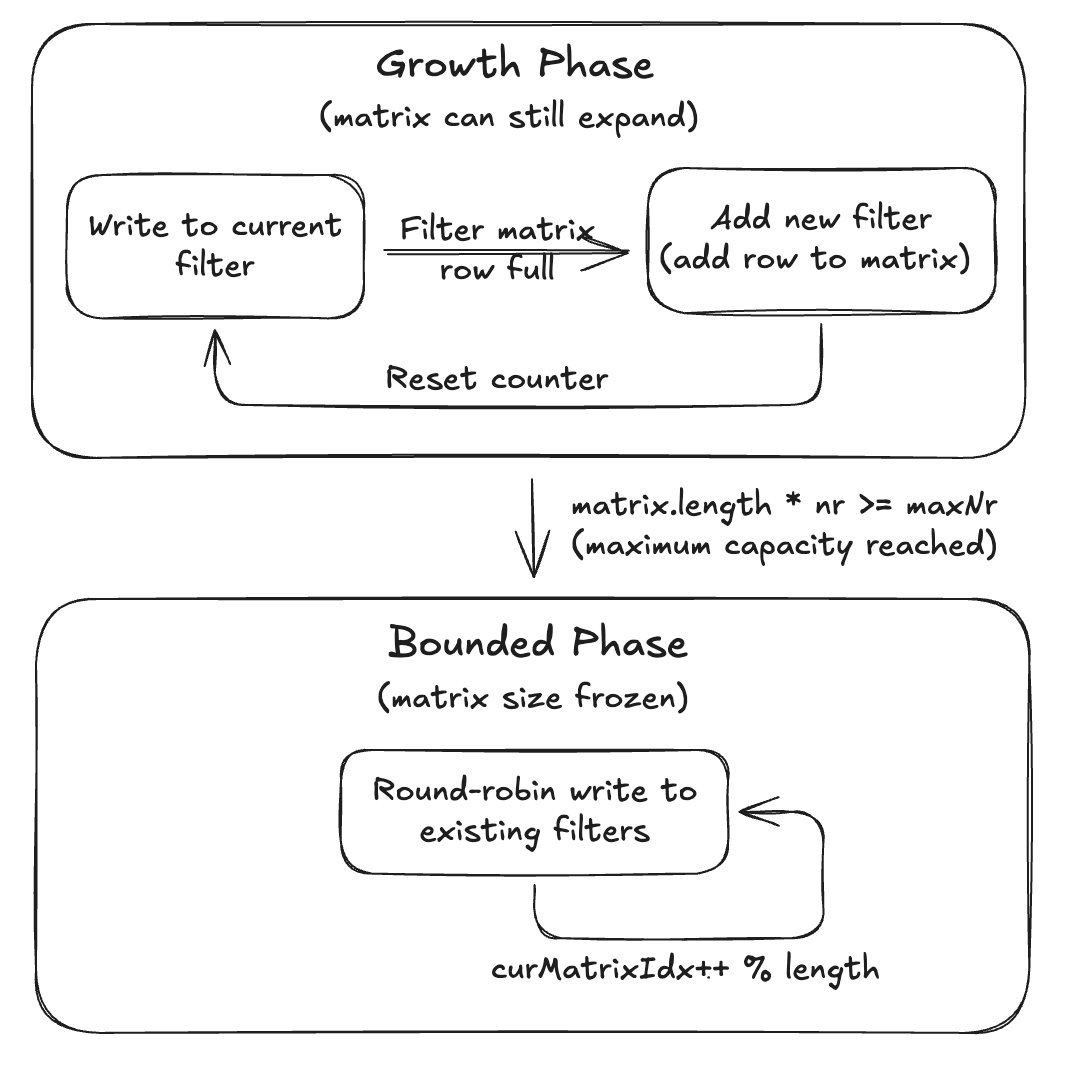
Hudi uses a chained array of standard Bloom filters that grows on demand to a configurable bound. The solution is composed of two phases:
Growth phase: When the number of records exceeds the current filter’s capacity, allocate a new filter and chain it. Each filter maintains its original false positive guarantees.
Bounded phase: Once the number of records reaches the maximum capacity, stop growing and write to existing filters using round-robin. False positive rates degrade, but memory usage stays predictable.
This design prefers degradation over the risk of OOM from “unlimited growth”.
InternalDynamicBloomFilter uses an array called matrix where each element is an InternalBloomFilter containing a bit vector. It starts with one filter. An array is used instead of ArrayList to avoid memory overallocation during expansion.
apache/hudi:InternalDynamicBloomFilter.java#L56-L75

nr (Number of Records per filter) is the capacity of each filter - when exceeded, a new filter is created. maxNr (Max Number of Records total) is the hard ceiling across all filters combined.
Hudi routes each record to the appropriate bloom filter based on current capacity and growth limits.
apache/hudi:InternalDynamicBloomFilter.java#L236-254

The three branches in the above code are:
reachedMax == true: Maximum capacity reached. Subsequent inserts are distributed across filters viacurMatrixIndex++ % matrix.length.Current filter full, capacity remaining: Returns null to signal the caller to allocate a new filter.
(matrix.length * nr) < maxNrchecks if growth budget remains.Current filter has capacity: Returns
matrix[matrix.length - 1], the most recently added filter.
Below is a state diagram.
The add() method adds a record key to the active Bloom filter.
apache/hudi:InternalDynamicBloomFilter.java#L77-L94

getActiveStandardBF() return value of null indicates that the current filter is full. A new filter is added to the matrix by the addRow() call.
apache/hudi:InternalDynamicBloomFilter.java#L210-218

To check if a key exists, every filter in matrix must be tested. If any returns true, the key might exist.
apache/hudi:InternalDynamicBloomFilter.java#L115-128

Query time scales linearly with filter count, but with a reasonable bound, the overhead is small compared to I/O savings from skipping files.
Each element in matrix is an InternalBloomFilter object, adapted from Apache Hadoop’s implementation.
apache/hudi:InternalBloomFilter.java:L108-L120

A key is added by hashing it and setting the corresponding bits in the bits vector.
apache/hudi:InternalBloomFilter.java#L122-L139

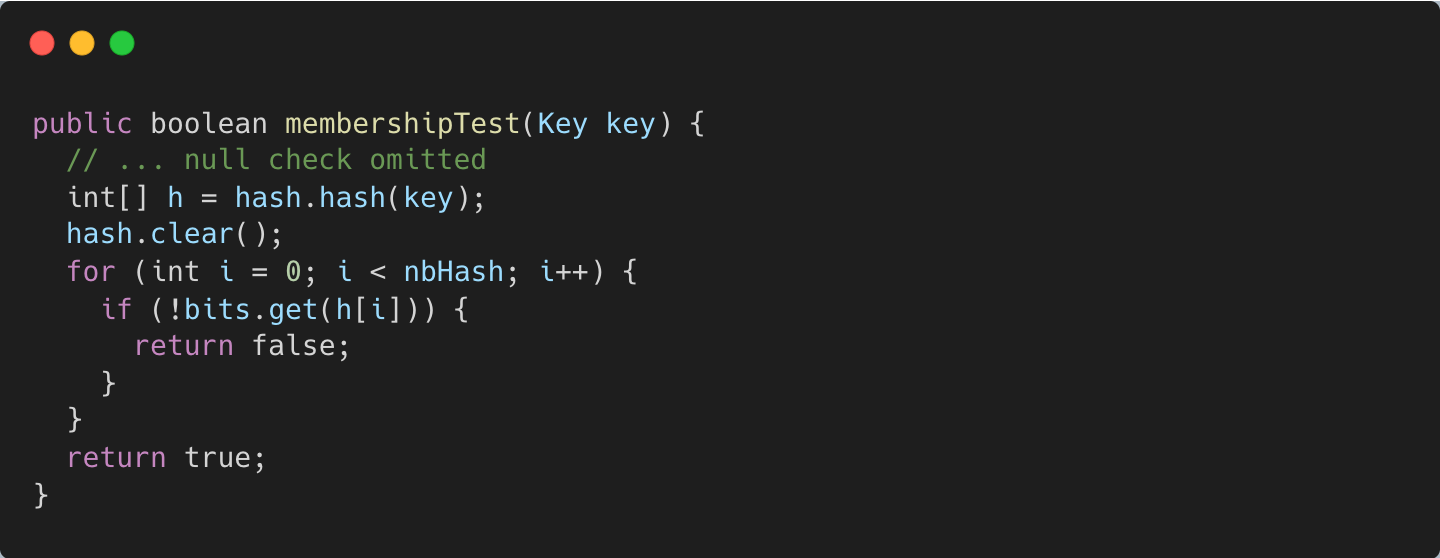
Membership - whether the key is in the set - is tested by checking all nbHash bit positions. If any bit is 0, the key was never added, since add() sets all nbHash bit positions for a key to 1.
apache/hudi:InternalBloomFilter.java#L153-L167
Soft Failure over Hard Failure. In distributed processing, unbounded memory growth leads to OOM crashes. Hudi prefers higher false positives (causing more I/O) rather than crashing executors. Data spikes degrade performance but don’t compromise availability.
Predictable Write Latency. Standard resizable Bloom filters can trigger expensive re-hashing of existing entries. Hudi avoids this by chaining new filters without re-hashing.
Balanced Degradation. Once full, writes are distributed via round-robin rather than filling one filter. If one filter reaches ~100% bit saturation, it always returns “maybe”, effectively providing zero filtering value. Round-robin keeps all filters at similar fill ratios, so they remain partially useful longer and false positive rates rise gradually.
Dynamic Bloom filters allow Hudi to skip files during upserts without knowing record counts upfront. Users don’t need to tune filter sizes per workload because the filter adapts automatically within configured bounds. This enables Hudi’s indexing layer to handle PB-scale upserts across varying data volumes.
PR #976: [HUDI-106] Adding support for DynamicBloomFilter by @nsivabalan (Sivabalan Narayanan)
PR #9649: [HUDI-6826] Port BloomFilter classes from Hadoop library by @yihua (Y Ethan Guo)
Please let me know if I missed any other major contributors to Hudi’s dynamic Bloom filter!