llm gpt-oss-120b benchmark data-analysis
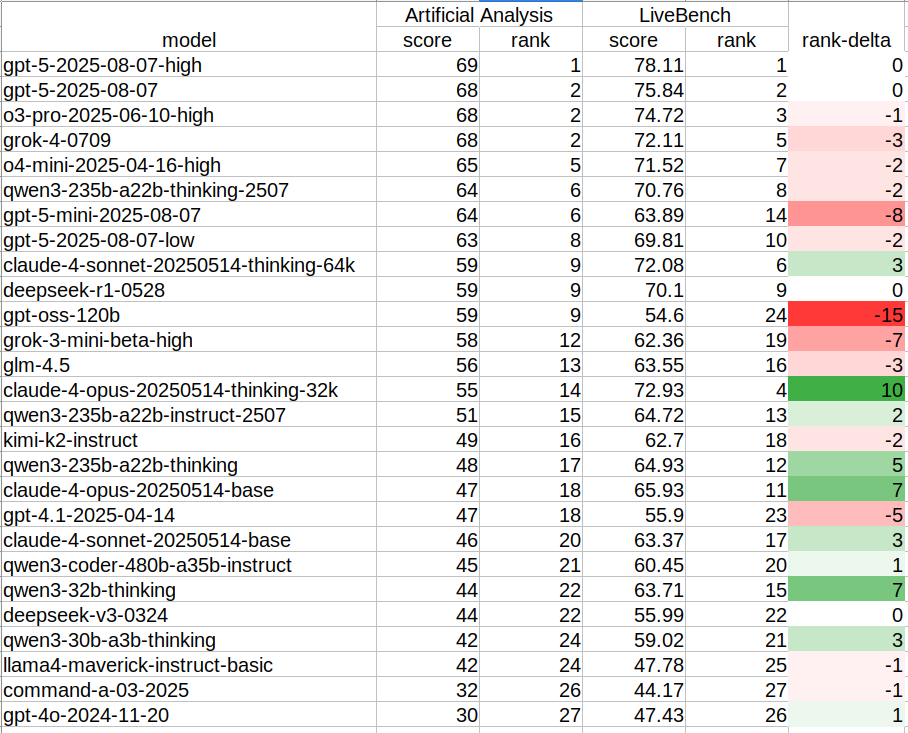
Let me just explain how I got here.
- I looked for the intersection of LLMs that have scores on both: 1
- The Artificial Analysis Intelligence Index, a composite score of several benchmarks. 2 Most of these benchmarks have public questions and answers that an AI lab could train their models on directly, if they wanted to inflate their score (or even by accident).
- LiveBench, a high-quality private (contamination-free) benchmark that releases its questions only after a three-month delay. The current questions and answers are secret. It’s a test that’s much harder to cheat on.
- I ranked these models (relative only to each other) by their AA score, and then also by their LiveBench score.
- For each LLM, I calculated the difference between the two rankings. 3
The above chart shows:
- A negative number (red) if a model moved down the ranking list (getting worse relative to the others) as we move from public to private benchmark.
- I would expect to see this if the lab trained that model directly on public benchmark questions, which would result in better scores on public benchmarks relative to that model’s ’true’ capability (as the private benchmark would reveal).
- A positive number (green) if a model moved up the ranking list (getting better relative to the others) on the private benchmark. 4
The new gpt-oss-120b jumps out as getting the most worse on LiveBench. It moved 15 positions down the list, from 9th place (a tie with DeepSeek R1 and Claude 4 Sonnet Thinking) down to 24th place. On LiveBench it ranks below the previous-gen Qwen 3 variants (dense 32B and sparse 30B-A3B). Both of these are 4x smaller parameter count than gpt-oss-120b, and run on my 2-year-old laptop.
This seems bad. What is going on?
To put my own bias on the table, I care about American AI labs releasing open-weights models that are worth using relative to our other choices. Regardless of what else I may think about OpenAI, I want them to do a great job of this. July was a crazy month of strong, permissively-licensed, open-weights Chinese models, with yet more in the first week of August. DeepSeek R1 continues to shine at the heavy end of the spectrum, months after its last revision. Qwen 3’s 32B and 30B-A30B variants continue to shine for use on a sufficiently-capable laptop. These are great models to help with writing, programming, and all sorts of other tasks. Meanwhile, it’s been four long months since the Llama 4 release, with its unfortunate license and unfortunate syncophancy-maxxing.
We’ve waited all summer for better open-weights models from an American lab, and last week it appeared that OpenAI delivered. The gpt-oss models looked really good on release day – the 120B one seemed to compete with DeepSeek R1 using 5x fewer total parameters. They passed Simon Willison’s initial sniff test (and my own). But then a bunch of critical reports showed up on /r/LocalLLaMA (a difficult crowd to please, for sure). Then it got a pretty ugly score on LiveBench – not much better than Llama 4 Maverick.
I’m hoping gpt-oss-120b shows up on Kagi’s private benchmark. LiveBench is good but we need more independent testing.
This analysis is a very rough sketch that begs for methodological improvement. 5 I used ancient data analysis software called a spreadsheet. There is probably at least one mistake. It’s not nearly thorough or vetted enough to accuse OpenAI of any particular shenanigans, so please don’t do that (or say that I’m doing it) on account of this blog post alone.
gpt-oss models aside, is this worth polishing into a real proper meta-benchmark that tries to measure overfitting in a more robust way? Should we be calling it “cheating” or does that presume too much?