It’s been about a year since we launched the private preview of the Postgres CDC connector in ClickHouse Cloud as part of ClickPipes, built on the integration of PeerDB, which we acquired in 2024. Since then, it has gone through several iterations, progressed through public beta, and reached GA in May. I want to reflect on that journey, the learnings and experiences from integrating a product post-acquisition, how customer adoption shaped the connector, the features I’m most excited about, the gaps we’re tackling next, and the key lessons along the way. So let’s get started.
The primary goal of this connector was to make it easy for customers to integrate two open-source database technologies, each purpose-built for a specific use case, Postgres and ClickHouse.The idea was simple: give customers a straightforward way to sync transactional data from Postgres to ClickHouse and seamlessly offload analytics to ClickHouse.
Keeping the above goal in mind, ClickHouse acquired PeerDB, a state-of-the-art open-source product built specifically for Postgres CDC, in July 2024. Within just four months, PeerDB was fully integrated into ClickHouse Cloud and became the engine powering the Postgres CDC connector in ClickPipes.
As part of the acquisition, we made an important decision: not only to keep PeerDB open source, but also to maintain it as a distinct, modular component powering ClickPipes. In other words, you can think of PeerDB as the open-source DB CDC engine for ClickHouse, while ClickPipes CDC is the managed-service implementation of PeerDB in ClickHouse Cloud. In retrospect, this decision was critical for engineering velocity and management - allowing each piece to evolve independently yet cohesively, while ensuring that all enhancements made to ClickPipes flow back into the open-source project for the broader community.
To validate the impact of this decision on velocity, I pulled up a comparison based on the GitHub activity of PeerDB versus another popular and well-known OSS CDC tool, Debezium, over the past year.
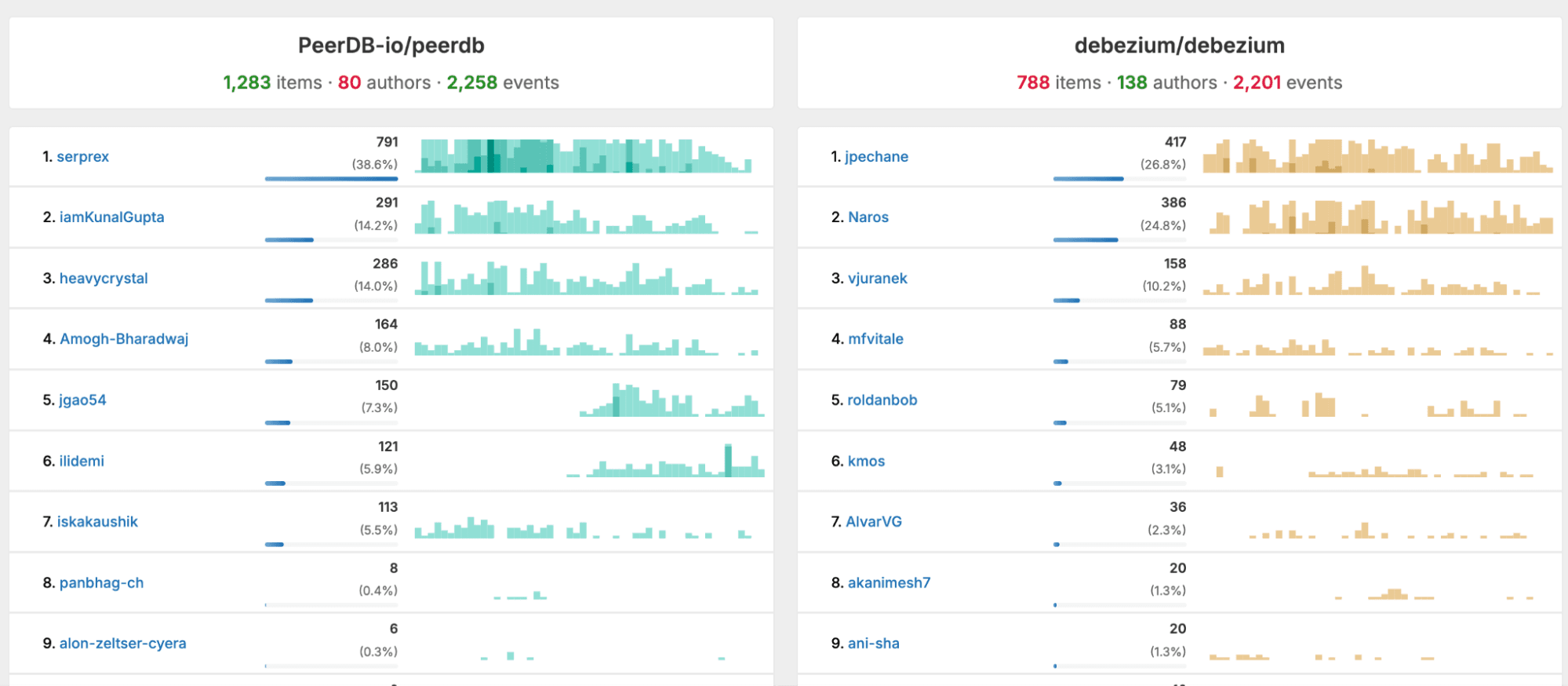
Since the PeerDB acquisition, Postgres CDC into ClickHouse has grown nearly 100×. We went from a handful of companies running PeerDB before the acquisition to more than 400 using it today through ClickPipes, collectively replicating over 200 TB of Postgres data to ClickHouse every month. This spans companies such as AutoNation, Seemplicity, Ashby, Vapi, SpotOn, and many others using ClickPipes at scale. Many organic open-source users also rely on PeerDB for Postgres to ClickHouse replication, including Cyera, a large cybersecurity company, LC Waikiki, the largest retailer in Turkey, and a few other enterprise companies.
As the founder of PeerDB, watching that growth over the past year has been both surreal and humbling. A lot of it came down to two things: a) the very real “better together” story between Postgres and ClickHouse and our conviction in it and b) our ClickHouse Team. I’ve learned a lot from going through an acquisition and integrating a product into a larger platform — plenty of good, some hard parts too ;). .I’ll write more about that separately in a different blog!
Over the past year, we’ve seen two important use cases emerge. The first is real-time customer facing analytics. Many customers initially started with Postgres to power both the transactional and analytical use cases of their real-time apps. But as their businesses scaled, Postgres started becoming slow for analytics. Some of them evaluated Postgres extensions, but they quickly realized these solutions aren’t performant or scalable enough. They come with several caveats, including limited SQL coverage and cannot match the speed and scale of a purpose-built analytical database (References: [1] and [2]).
At that point, they turned to ClickHouse, a complementary open-source database optimized for fast and efficient analytics. The Postgres CDC connector made it easy to keep Postgres and ClickHouse in sync, allowing teams to use the right tool for the right job: Postgres for transactions, and ClickHouse for analytics.
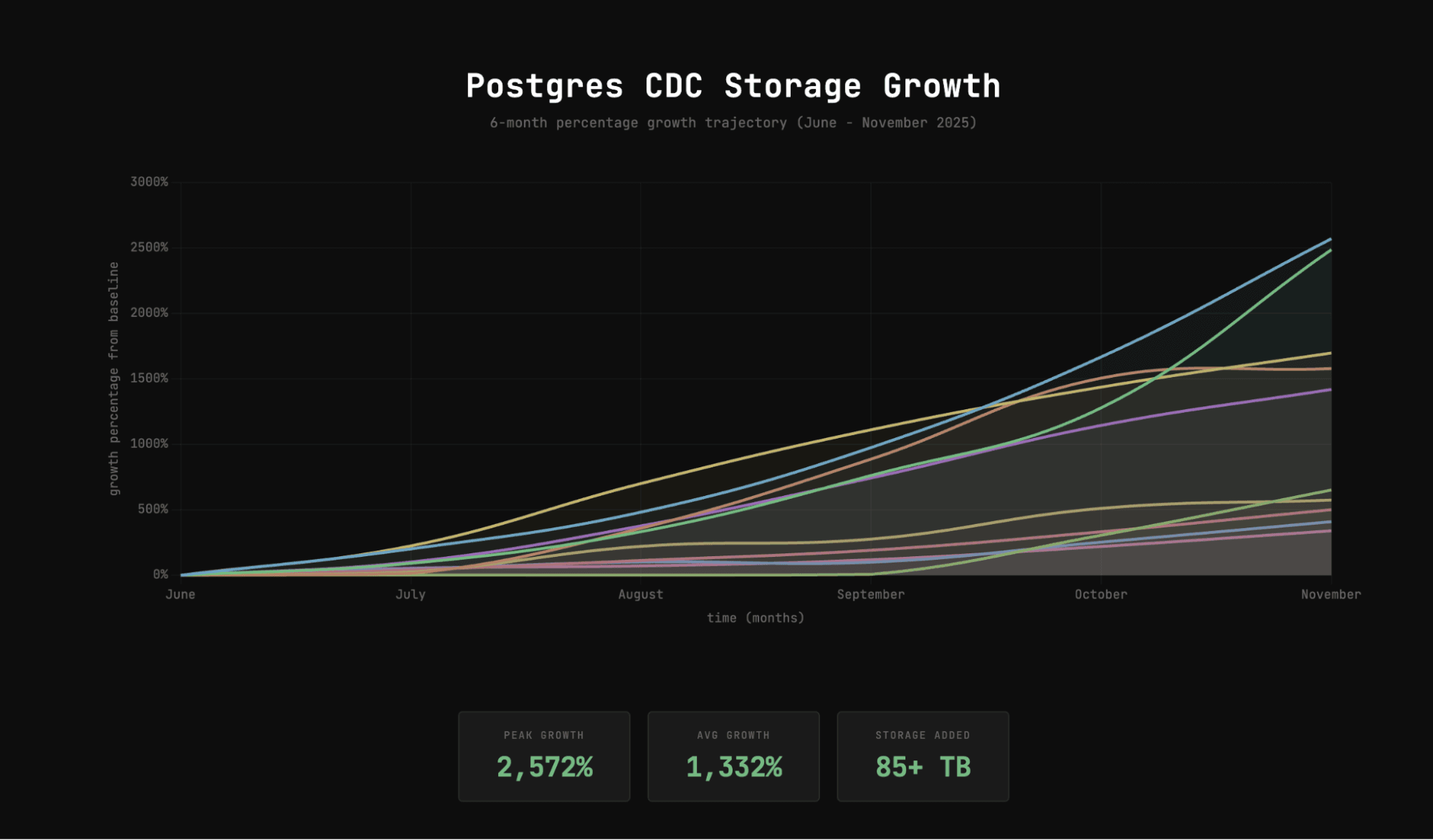
An interesting observation is that teams are hitting Postgres’s analytical limits much sooner than before, largely due to AI-driven workloads where both data volume and query rates have increased dramatically. My speculation is that the time it takes for Postgres deployments to grow beyond terabyte-scale has shrunk from multiple years to just a few month and this trend will only accelerate. With this in mind, planning for scale and specialization from day one becomes increasingly important.
To validate this speculation, I pulled a graph showing data growth for the top 10 companies using the Postgres CDC connector. The graph was exponential - over six months, they saw an average data increase of more than 1,000%, adding over 85 TB, and most of these companies are AI-native.
The second major use case is data warehousing. We’ve also seen customers use this connector to consolidate Postgres data into ClickHouse, frequently combining it with other key data sources, some of which are already supported natively in ClickPipes. They then use ClickHouse to power critical internal BI and analytics needs for data analysts, data scientists, and other internal stakeholders.
Now that we have gone through the goal, roots, and customer adoption of Postgres CDC, let’s double-click on features and gaps. I’d like to highlight my five favorite features and enhancements added to the Postgres CDC connector over the past year. This isn’t to diminish the importance of the others, these are just the ones that, in my view, had the biggest impact or intrigued my curiosity the most.
This is one of the earlier features, but an important one. While building native Postgres CDC with logical replication, we realized that reconnecting the replication connection was extremely costly for some of our largest customers—sometimes taking minutes or even hours before data reading could resume. We discovered that on reconnect, Postgres would start reading the replication slot’s WAL from the restart_lsn—effectively the beginning—rather than from the last processed position. For workloads with long-running, large, or interleaved transactions, this meant unnecessarily re-reading large portions of WAL and drastically impacting replication lag.
To fix this, we made a key infrastructure change ensuring that the replication connection is never relinquished, avoiding these expensive restart cycles. This drastically reduced issues with our largest customers - replication slots used to get drained at a much faster rate and replication lags were always kept in check.
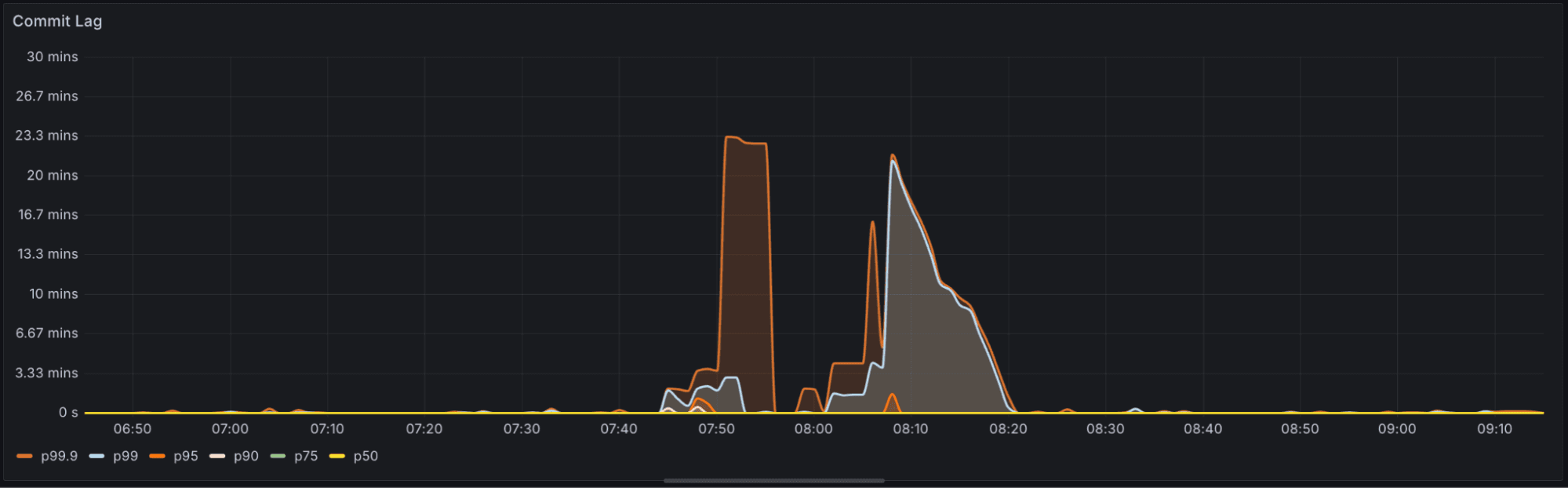
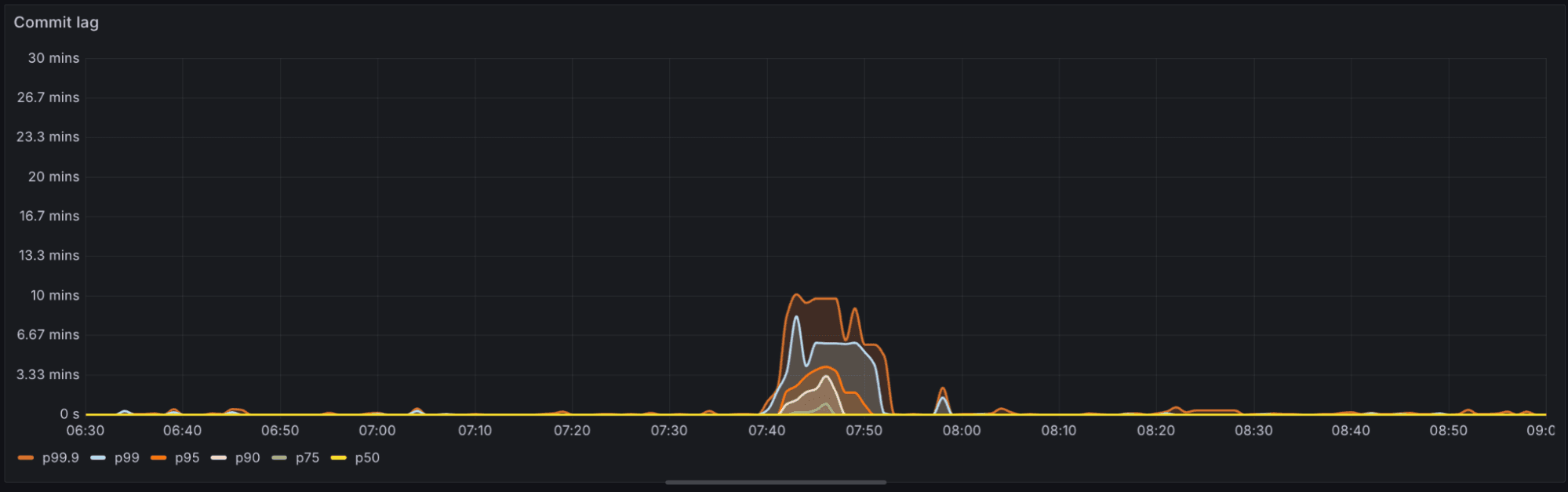
The replication-lag graph below shows the drop in replication lag during long-running transactions before and after avoiding reconnections. In the few scenarios where commit lag previously spiked, it now falls off sharply.
Before:
After:
Postgres CDC to ClickPipes involves hundreds of edge cases and a wide variety of pitfalls that users can run into. Over the past year, we invested heavily in building in-product validation to surface most of these issues before the replication pipeline starts. This has significantly improved the user experience by allowing customers to address problems upfront rather than waiting for a pipe to fail.
These enhancements include 50+ pre-flight checks such as verifying Postgres replication is configured correctly, ensuring tables have primary keys or replica identities, confirming the CDC role has the right permissions, detecting duplicate tables in ClickHouse, validating Postgres version compatibility, ensuring publications exist, the ability to read from standby, and much more. Here goes the Open Source reference to our validation logic.
One of the product’s biggest strengths has always been its ability to backfill data fast. We routinely move tens of terabytes into ClickHouse in a few hours instead of weeks, thanks to parallel snapshotting, which logically partitions a large table and processes those partitions in parallel.
But there was an architectural flaw hiding underneath: to compute those partitions, the system ran heavyweight COUNT and window-function queries to produce evenly sized partitions. On multi-terabyte tables, these queries could take hours and put real pressure on the source database. In some cases, generating partitions took longer than the actual data transfer.
A major open-source contribution from Cyera, one of our largest open-source users, fixed this. Instead of relying on expensive analytical queries, they introduced a simple heuristic-based approach: a block-based partitioning strategy on the CTID column. Partition generation went from 7+ hours to under a second. Same parallelism, zero database strain, orders-of-magnitude faster startup time. Huge shout out to Alon Zeltser from Cyera for the design and the initial POC.
This one has to be on the list. Our Postgres CDC team embraced the “do things that don’t scale” mindset, very much coming from PeerDB’s Y Combinator roots. We built internal alerts for almost every user action and error so every engineer could see exactly how customers were using the product and where issues surfaced. It worked amazingly well through our first 100 customers, and the product improved by leaps and bounds.
But beyond that point, the volume became unmanageable. On-call load spiked, and the customer experience began to suffer. We observed that most errors were user-related (e.g., incorrect configuration, missing settings), and many of them were avoidable. To address this, we introduced user-facing alerts via Slack and email. We grouped errors into over 10 categories and provided customers with clear, actionable messages explaining what went wrong, how to fix it, and how to escalate the issue. These categories include issues such as unexpected replication slot size, the source database being unreachable, incompatible downstream Materialized Views (MVs), and more.
The result: on-call load dropped by orders of magnitude, and customers became empowered and better educated about the product, enabling them to troubleshoot issues in a self-serve manner. The graph below shows the reduction in the number of on-call alerts pre and post introducing user facing alerts.
Our ethos of staying close to the customer remains constant. We regularly review these user-facing alerts to inform product improvements, and at any given time, we stay in close contact with at least 10–20 customers to understand their issues and gather deeper insights.
As we iterated on the product across hundreds of customer use cases, we added increasing levels of configurability to Postgres CDC ClickPipes, empowering customers as much as possible. This includes hundreds of options such as advanced connectivity (PrivateLink, SSH tunneling), data modeling choices (ordering keys, table engines, support for hard deletes), table-level configurability (adding or removing tables before or after pipeline creation), switching connectivity methods, and many more. These enhancements made the overall ClickPipes experience far more comprehensive and enterprise-ready.
A key learning for me was understanding the true complexity of data-movement / ETL systems. Delivering a stable, reliable, and enterprise-grade CDC experience depends on hundreds, sometimes thousands, of smaller capabilities and edge cases working together. Reaching that level of reliability requires sustained iteration and refinement, and there are still many gaps we need to close to take the system to the next level.
A few other features I’d like to call out—though they didn’t make the top-five list—include performance enhancements such as faster ingestion into ClickHouse through chunking and parallel replicas; usability improvements like a Prometheus/OTEL endpoint for native Postgres CDC metrics (including replication slot growth, commit lag, and more); and reliability improvements through disk spooling and better Go channel management for more efficient memory handling.
Now that we have gone through my favorite features and a lot of product improvements, let’s come to the gaps in the current Postgres CDC / integration experience with ClickHouse. I’d like to highlight a few big gaps that we see across customers and how we plan to address them in the near future.
The biggest gap we see across customers is the data modeling overhead involved in migrating analytics workloads from PostgreSQL to ClickHouse. Even when this isn’t particularly advanced and is palpable, it still creates friction. Smaller customers often spend a few weeks on migration; larger, more complex deployments can take months. Our goal is to bring that down to just a few days.
Most of this overhead traces back to a few core data-modeling considerations in ClickHouse, the largest being data deduplication. Postgres CDC uses the ReplacingMergeTree engine, which speeds up ingestion by replicating UPDATEs as appends and handling deduplication asynchronously. This means customers must explicitly account for deduplication—usually via the FINAL clause or more advanced patterns. While this is not super advanced, the conceptual overhead is real for Postgres users: they need to understand how ReplacingMergeTree behaves and adjust their application queries accordingly.
We’re working on closing this gap from multiple angles. We’re evaluating lightweight UPDATE support in Postgres CDC, enabled by recent low-latency UPDATE improvements in ClickHouse. We’re also actively tracking unique index support on ReplacingMergeTree tables to provide synchronous deduplication based on primary/unique keys.
A few other enhancements we are actively working on to make data modeling as seamless as possible include a Postgres-compatible layer/extension to reduce query-migration effort; continued improvements to JOIN performance to better support relational/normalized schemas—an area that has already seen major gains over the past year and has been critical for hundreds of existing Postgres CDC customers; improved onboarding and observability for Materialized Views; and more.
A few important platform-level features consistently come up in customer conversations, including support for OpenAPI and Terraform for Infrastructure as Code, expansion of ClickPipes Postgres CDC to additional clouds such as GCP and Azure, BYOC support, and more. We’ve made meaningful progress in these areas: OpenAPI support is currently in beta; Terraform support is planned for next quarter; work on GCP expansion is underway; and for BYOC, we introduced a temporary solution via PeerDB Helm charts, which will eventually power ClickPipes DB BYOC.
We plan to invest heavily in these capabilities over the next year to ensure a truly enterprise-grade Postgres CDC experience for customers.
Over the past year, we’ve seen customers run into a handful of footguns, a lot of them rooted in the inherent complexity of the problem. Examples include partial schema change support (we support ADD/DROP COLUMN, but not CHANGE TYPE), earlier bugs where nullability changes didn’t propagate when adding tables (now fixed), and operational issues like long-running table additions that couldn’t be interrupted.
We’re tracking every one of these footguns and have either already resolved them or are actively working on fixes. This builds on the hundreds of iterative improvements we made last year, and we remain committed to continually refining the Postgres CDC experience.
We’ve strengthened our unit-testing framework and are close to full code coverage. We’re also evaluating a new initiative to give customers a data-consistency view, offering full visibility into how Postgres CDC transforms and replicates their data.
We’re beginning to see early signals from several of our largest customers that they will need deeper improvements in Postgres logical replication as they scale to higher throughputs and more complex workloads. One capability we believe could meaningfully improve support for advanced use cases, especially those involving large or highly interleaved transactions, is adding support for Postgres Logical Replication V2 in Postgres CDC.
Logical Replication V2 allows reading changes from a replication slot before a transaction commits. This can substantially reduce load on the WAL sender process, dramatically increase throughput, and improve replication-slot draining. We plan to invest in this capability in the coming months to ensure customers can continue scaling seamlessly.
We’ll also be investigating support for consuming the replication slot while the initial snapshot and resync are running, allowing both processes to happen simultaneously and enabling more efficient replication-slot flushing. Although initial snapshots are typically fast, customers with high-volume workloads often report significant replication slot growth during large backfills.
We also plan to step up our contributions to upstream Postgres. For example, last year we resolved a complex logical-replication bug related to replicating from standbys—an area where we intend to remain actively involved.
Over the past year, building and scaling Postgres CDC has been a reminder of how deceptively deep this space is. From the outside, CDC looks straightforward - “just read the WAL” - but real workloads expose a very different reality: long-running transactions, replication slot backpressure, schema changes, network quirks, and the kind of edge cases you only discover when a customer hits them at midnight.
The surprising part wasn’t the technical complexity itself, but the amount of iteration required to make the system feel boring, in the sense that good infrastructure should be. Reliable, invisible, fast.
This past year also reinforced something we suspected early on: Postgres and ClickHouse are a natural pair for building real-time applications, especially as data volumes surge in the AI world. CDC laid the foundation for that pairing, but it’s only the first step. The long-term goal is to unify these two amazing databases as components of a single stack rather than separate databases. That means a more solid replication layer, far less data-modeling overhead, a smoother path for application and query migration, and a lot more. We’re heading in that direction, and there will be some meaningful announcements on this front next year.
To conclude, here are a few links you can use for future reference on Postgres CDC and ClickPipes.