Today we're launching dreaming in Claude Managed Agents as a research preview. Dreaming extends memory by reviewing past sessions to find patterns and help agents self-improve. We're also making outcomes, multiagent orchestration, and webhooks available to developers building with Managed Agents. Together, these updates make agents more capable at handling complex tasks with minimal steering.
Build self-improving agents with dreaming
Dreaming is a scheduled process that reviews your agent sessions and memory stores, extracts patterns, and curates memories so your agents improve over time. You decide how much control you want: dreaming can update memory automatically, or you can review changes before they land.
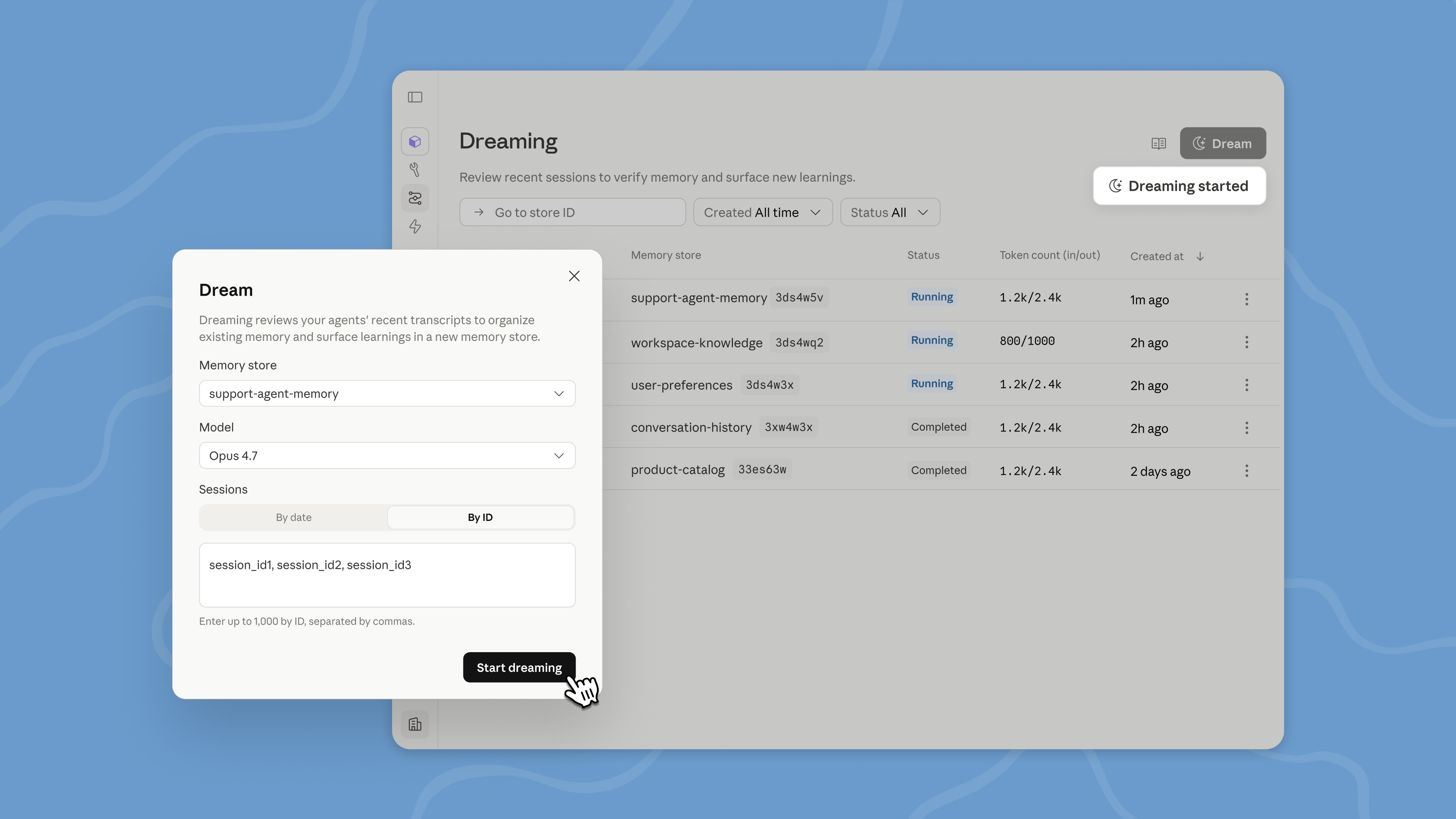
Dreaming surfaces patterns that a single agent can’t see on its own, including recurring mistakes, workflows that agents converge on, and preferences shared across a team. It also restructures memory so it stays high-signal as it evolves. This is especially useful for long-running work and multiagent orchestration.
Together, memory and dreaming form a robust memory system for self-improving agents. Memory lets each agent capture what it learns as it works. Dreaming refines that memory between sessions, pulling shared learnings across agents and keeping it up-to-date.
Dreaming is available in Managed Agents on the Claude Platform; developers can request access here.
Deliver better outcomes
With outcomes, you write a rubric describing what success looks like and the agent works toward it. A separate grader evaluates the output against your criteria in its own context window, so it isn't influenced by the agent's reasoning. When something isn't right, the grader pinpoints what needs to change and the agent takes another pass.
Agents do their best work when they know what "good" looks like. For example, a structural framework, a presentation standard, or a set of requirements that need to be met. With outcomes, agents can check their work against that bar and self-correct until the output is good enough, without a human needing to review each attempt.
Outcomes is particularly useful for tasks that require attention to detail and exhaustive coverage. It also works for subjective quality, like whether copy matches a brand voice or a design follows visual guidelines. In testing, outcomes improved task success by up to 10 points over a standard prompting loop, with the largest gains on the hardest problems. Outcomes also improved file generation quality, with +8.4% task success on docx and +10.1% on pptx in our internal benchmarks.
You can also now define an outcome, let the agent run, and get notified by a webhook when it's done.
Handle complex tasks with multiple agents
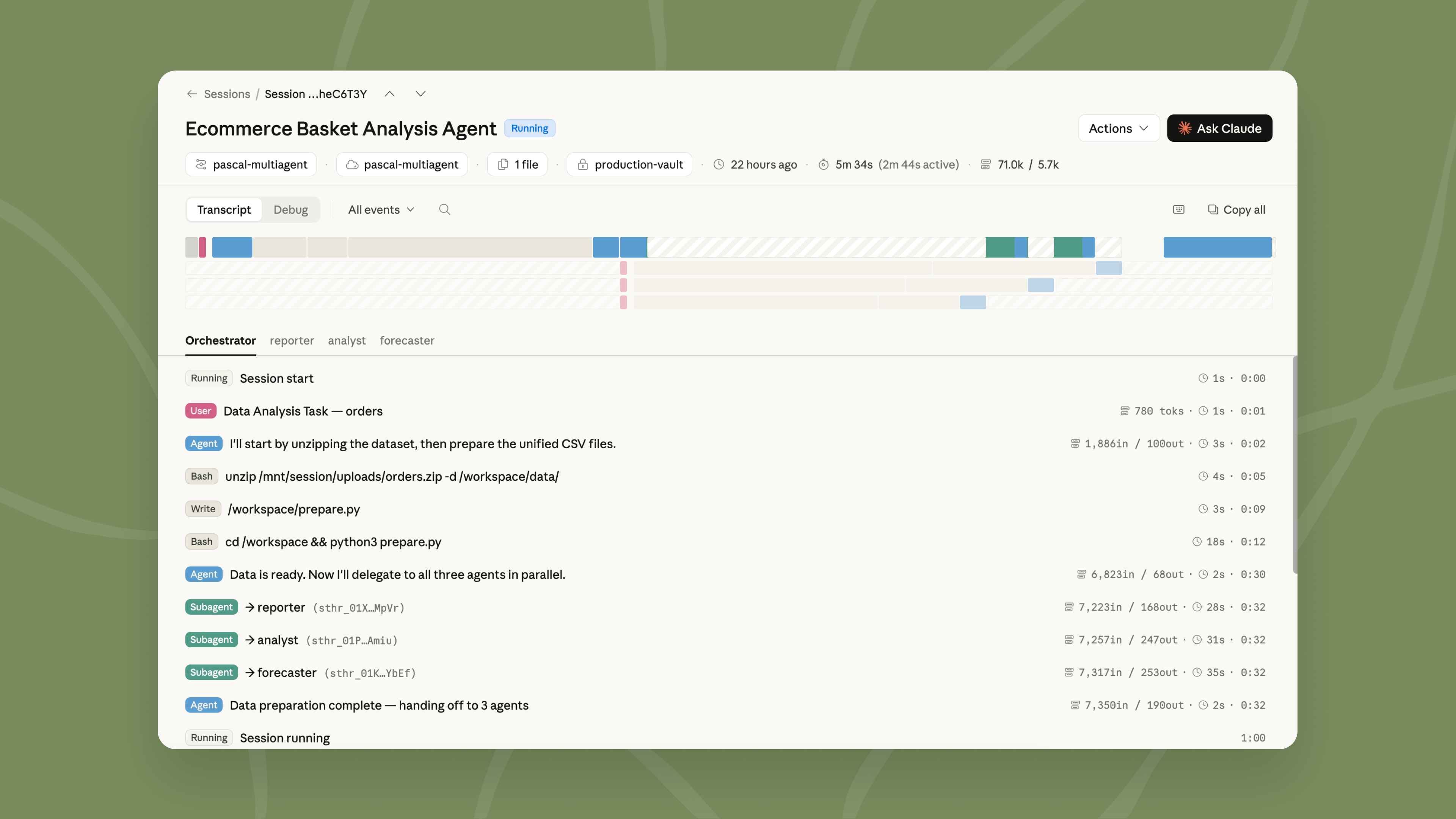
When there is too much work for a single agent to do well, multiagent orchestration lets a lead agent break the job into pieces and delegate each one to a specialist with its own model, prompt, and tools. For example, a lead agent can run an investigation while subagents fan out through deploy history, error logs, metrics, and support tickets.
These specialists work in parallel on a shared filesystem and contribute to the lead agent's overall context. The lead agent can check back in with other agents mid-workflow because events are persistent and every agent remembers what it's done. You can also trace every step in the Claude Console: which agent did what, in what order, and why, giving you full visibility into how your task was delegated and executed.
What teams are building
Teams are using dreaming, outcomes, and multiagent orchestration to ship agents that verify their own work, learn across sessions, and parallelize complex jobs:
- Harvey uses Managed Agents to coordinate complex legal work like long-form drafting and document creation. With dreaming, their agents remember what they learned between sessions, including filetype workarounds and tool-specific patterns. Completion rates went up ~6x in their tests.
- Netflix's platform team built an analysis agent that processes logs from hundreds of builds across different sources. With changes that affect thousands of applications, what matters is finding the issues that recur across many of them. Multiagent orchestration lets the agent analyze batches in parallel and surface only the patterns worth acting on.
- Spiral by Every is using multiagent orchestration and outcomes to power the writing agent behind their new API and CLI. The lead agent runs on Haiku: it fields incoming requests, poses quick follow-up questions when needed, then delegates the drafting to subagents running on Opus. When a user asks for multiple drafts, the subagents run in parallel. Writing quality is Spiral's core value, so they use outcomes to enforce it. Each draft is scored against a rubric of Every's editorial principles and the user's voice, both pulled from memory. Only drafts that clear the bar are returned.
- Wisedocs built a document quality check agent on Managed Agents, using outcomes to grade each review against their internal guidelines. Reviews now run 50% faster, while staying aligned with their team's standards.
Getting started
Dreaming is available in research preview, outcomes, multiagent orchestration, and memory are available in public beta as part of Managed Agents. To get started with dreaming, request access here. Explore our documentation to learn more or visit the Claude Console to deploy your first agent.