A few months ago, I wrote what I thought was the final chapter of Zedis. The benchmarks had landed within 5–8% of Redis, and that felt like a natural place to step back.
But I had one more thing I wanted to try. I was waiting on Zig 0.16 to land before touching the TCP layer again, the new release had implications for the command parser and connection pool, and zero-copy. That’s genuinely hard to get right. As it turned out, I didn’t end up doing it anyway, Io.Evented didn’t make it into this release, which was the piece the whole approach depended on.
Zig’s release cadence is still pre-1.0, which means they broke the APIs every 6 months. It sometimes sucks.
This is where I applied a technique Alex Padula of TidesDB walks through here: a background thread that refreshes a cached timestamp every few milliseconds. The idea is simple, if you need the current time frequently, polling a local value is far cheaper than paying for a syscall each time.
The more interesting change is the concurrency model.
Zedis adopts a hybrid model built on Zig’s std.Io.Threaded runtime:
Main thread: initializes the threaded IO runtime, reads config, builds the server, and runs the TCP accept loop.
Store thread: a single dedicated thread that drains a shared
CommandQueueand executes commands against theStore.Client connection tasks: each accepted connection runs as an
Io.Group.async(...)task, handling socket reads, RESP parsing, and socket writes concurrently.
The key design decision here is keeping command execution serialized on a single store thread while connection handling is concurrent. This is exactly how Redis works under the hood: a single-threaded command executor, concurrent network I/O. At some point, I'd like to test the shared-nothing architecture, but it's a major undertaking.
Here’s how a command travels through the new architecture:
The listener accepts a TCP connection.
Zedis allocates a client slot from a fixed pool.
The client task reads from the socket and parses RESP.
The parsed command is copied into heap-owned buffers and enqueued to the shared command queue.
The store thread executes the command against the shared store.
The store thread encodes the response and pushes it into the client’s mailbox.
The client task drains the mailbox and flushes responses to the socket.
The mailbox is the elegant part. Instead of the store thread writing directly to the socket (which would require locks or careful coordination), it drops the response into a per-client queue. The client task owns the socket and picks up the response on its own time. Clean separation of concerns.
Pub/Sub used to be the awkward part of this architecture. You have subscribers waiting for messages, and publishers pushing to channels—crossing thread boundaries in ways that are easy to get wrong.
The fix is the same primitive. Publishers push messages into subscriber mailboxes. Subscribers drain them. No shared locks between the store thread and the client tasks for pub/sub delivery. The coordination primitive does the work.
This is a pattern worth internalizing. When you have multiple producers and a single consumer (or vice versa), a mailbox/queue is almost always the right abstraction. It localizes synchronization, keeps each party’s logic simple, and scales naturally.
Part 4 mentioned that Zedis aimed for zero allocations during command execution—an aspiration borrowed from TigerBeetle’s famous “no dynamic memory” approach. The new architecture is honest about where that goal stands today.
Zedis now uses multiple allocation domains rather than a single global allocator:
base_allocator: general server allocations—client slot storage, command queue nodes, response serialization buffers, mailbox message nodes.KeyValueAllocator: wraps the base allocator and enforces the store memory budget. When an allocation would exceed the budget, it tries eviction first. Withnoevictionpolicy, you geterror.OutOfMemory.temp_arena: an arena-backed allocator used during startup for AOF and RDB loading.Per-client parse arena: each client handler gets an
ArenaAllocatoron top ofstd.heap.page_allocator, reset after every command.
The honest note in the new memory architecture doc is worth quoting in spirit: the older claim that command execution performs no runtime allocation is no longer accurate. The parser still allocates argument buffers. The client duplicates parsed arguments before enqueueing. The store thread builds response buffers. These are real allocations in the hot path.
Each domain has a clear owner and lifecycle. Store data is budgeted and eviction-aware. Parsing scratch space is short-lived and isolated per client. Startup scratch space is isolated in a one-shot arena.
This is a clearer memory model than a single unconstrained allocator, even if it’s not the zero-allocation ideal. It might be more feasible when I port it to Io.Evented.
Part 4 compared Zedis against Redis. This time, the benchmark baseline is Valkey 9.0.3—the open-source Redis fork that’s been gaining traction since the Redis license change. Same benchmark script, same port, different reference implementation.
Hardware: AMD Ryzen 9 7900X (12 cores / 24 threads, up to 5.74 GHz), 30 GiB RAM, NVMe storage.
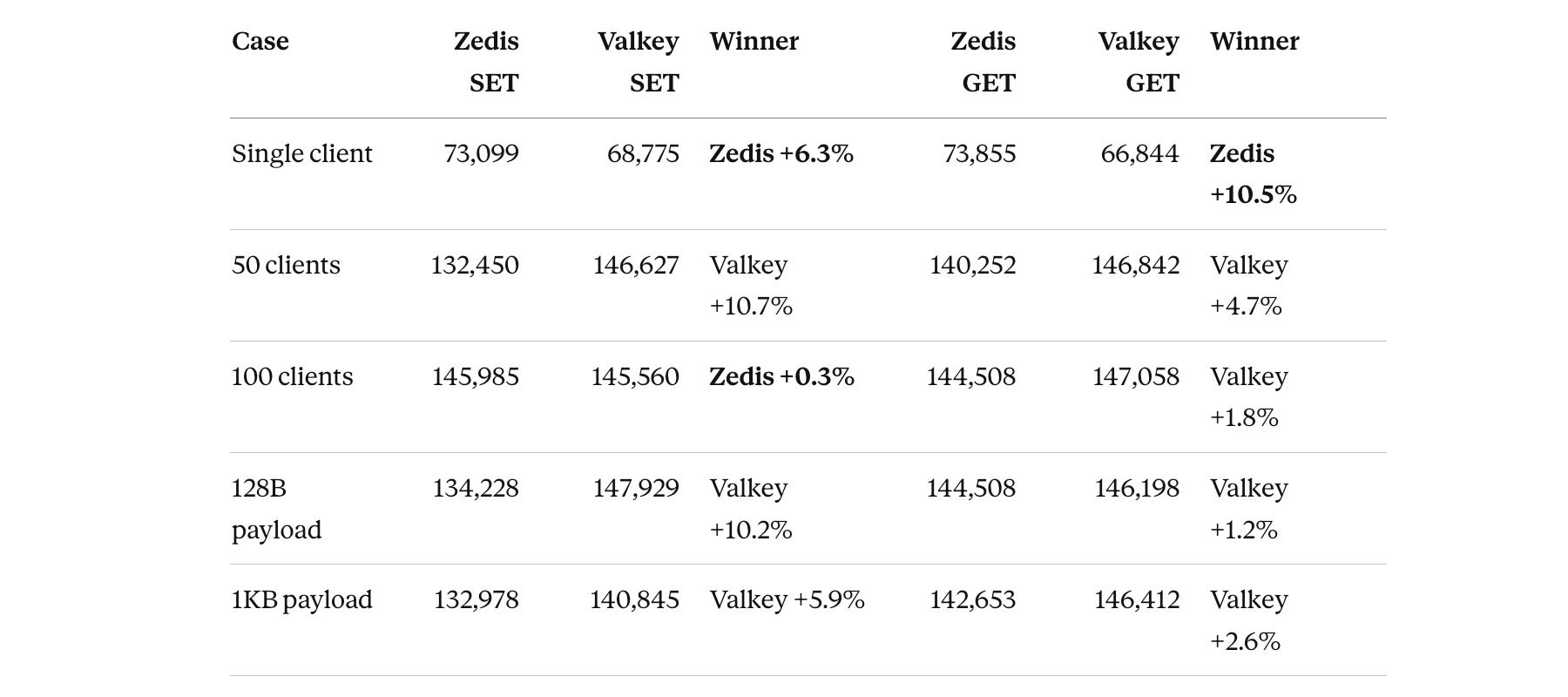
The story here is clear: Zedis beats Valkey in the single-client case—by a meaningful margin on GET. At high concurrency, Valkey pulls ahead, which makes sense. Valkey is multi-threaded and optimized for concurrent load. Zedis serializes all command execution on a single store thread.
What’s interesting is how competitive the numbers are at 100 clients. The gap nearly closes for SET. This suggests the serialized store thread isn’t the bottleneck at that concurrency level on this hardware—the network and parsing work takes up enough time that the store thread isn’t the constraint.