100 hard browser tasks, one leaderboard
To truly understand our agent performance, we built a suite of internal tools for evaluating our agent in a standardized and repeatable way so we can compare versions and models and continuously improve. We take evaluations seriously. As of now, we have over 600,000 tasks run in testing.
This is our first open source benchmark. BU Bench V1: 100 hand-selected tasks that are hard but possible, drawn from five established sources.
| Source | Tasks | Description |
|---|---|---|
| Custom | 20 | Page interaction challenges (iframes, drag-and-drop, complex forms) |
| WebBench | 20 | Web browsing tasks |
| Mind2Web 2 | 20 | Multi-step web navigation |
| GAIA | 20 | General AI assistant tasks (web-based) |
| BrowseComp | 20 | Browser comprehension tasks |
Every task was run many times with different LLMs, agent settings, and frameworks. Too-easy tasks were removed. Tasks majority-voted impossible and never completed were removed. What's left is hard and verified completable.
The task set is encrypted to prevent LLM training contamination.
The judge
Real websites can't be judged deterministically. We use an LLM judge (gemini-2.5-flash) with a simple true/false verdict. Rubric-based scoring sounds better in theory, but in practice LLMs give middling scores to both successes and failures. Binary verdicts are more reliable.
We hand-labeled 200 traces and measured alignment. The judge agrees with human judgments 87% of the time, differing only on partial successes and technicalities.
To ensure consistency across models, the same judge LLM, prompt, and inputs are used for every evaluation.
Results
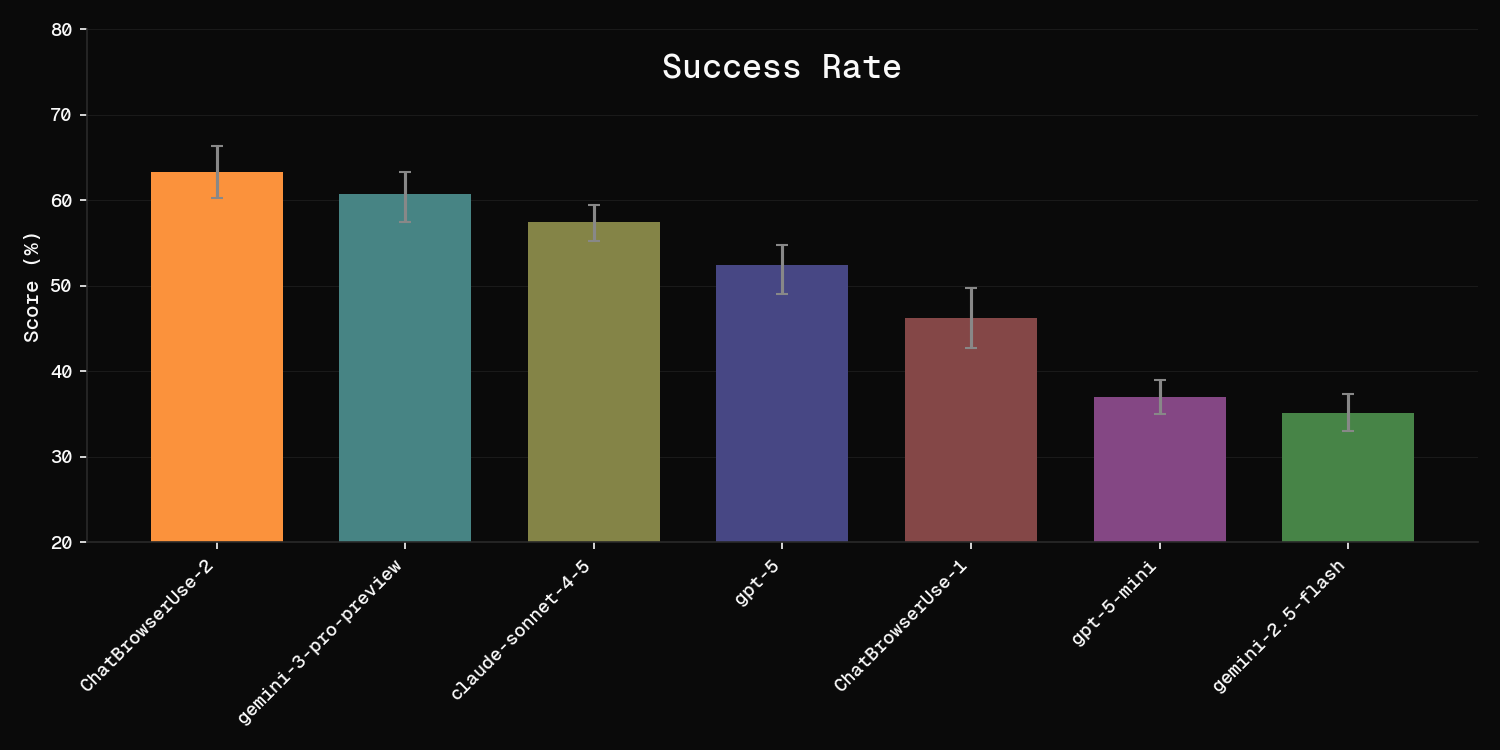
| Model | Type | Score |
|---|---|---|
| claude-fable-5 | Open Source | 80.0% |
| Browser Use Cloud (bu-ultra) | Cloud | 78.0% |
| OSS + BU LLM (ChatBrowserUse-2) | OSS + Cloud LLM | 63.3% |
| claude-opus-4-6 | Open Source | 62.0% |
| gemini-3-1-pro | Open Source | 59.3% |
| claude-sonnet-4-6 | Open Source | 59.0% |
| gpt-5 | Open Source | 52.4% |
| gpt-5-mini | Open Source | 37.0% |
| gemini-2.5-flash | Open Source | 35.2% |
Browser Use Cloud leads at 78%, 16 points ahead of the best open-source model. Each model was evaluated multiple times and results include error bars (standard error).
Update (June 2026): Anthropic's claude-fable-5 set a new high score of 80.0% running on the open-source library, beating the next-best frontier model (GPT 5.5) by 12 points — though at $580.87 in API cost per 100-task run. See the full breakdown in our Claude Fable benchmark post.
The "Open Source" column means running the open-source Browser Use library with that LLM. "OSS + Cloud LLM" means the open-source library using our ChatBrowserUse-2 model, which is specifically optimized for browser automation. "Cloud" is the fully managed Browser Use Cloud agent.
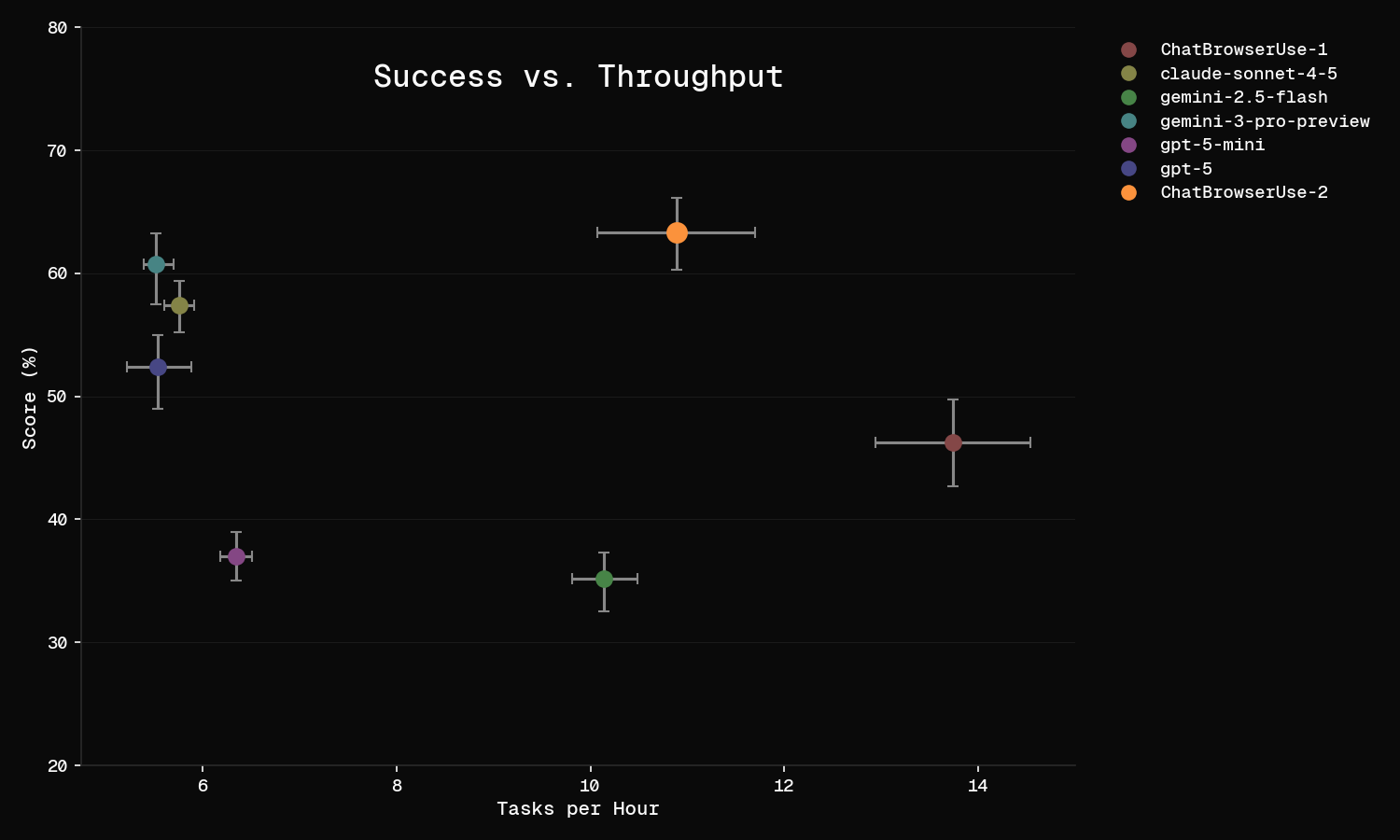
The throughput plot tells the rest of the story. Browser Use Cloud (bu-ultra) is both the most accurate and the fastest at ~14 tasks per hour. GPT-5 is the slowest at ~6 tasks per hour. Each bu-ultra step is slower than a smaller LLM, but it completes tasks in far fewer steps, so total wall-clock time is lower. Speed matters in production.
Why Cloud scores higher
Browser Use Cloud is not just a model. It combines a purpose-built agent with our own browser infrastructure: stealth proxies, CAPTCHA solving, persistent filesystem, and optimized tool orchestration. The 16-point gap over the best open-source model comes from this full-stack optimization, not just a better LLM.
For users who need custom tools or self-hosting, the open-source library with ChatBrowserUse-2 (63.3%) still outperforms every standalone open-source model.
Using the benchmark
The benchmark is open source at github.com/browser-use/benchmark. Clone the repo, set your API keys, and run uv run python run_eval.py.
A single run of 100 tasks takes ~3 hours and costs ~100 in LLM API calls per run.
We want LLM providers to use this benchmark to test and improve their models on real agentic browsing tasks. If you need to run evaluations at larger scale, contact support@browser-use.com.