I trained 1,500 parallel bots to play DDNet, a cooperative 2D platformer with grappling hooks, freeze mechanics, and maps that take actual players hours to complete. This is what it looks like:
In this video you can see my army encroaching agents running through the initial section of a Tutorial map that teaches basic movements and adds difficulty incrementally. It’s designed for someone who’s never played before, lends itself well for reinforcement learning.
I grew up playing this game. Back in high school I watched SethBling’s MarI/O, a neural network learning to play Super Mario World, and immediately thought: what if I could do this for DDNet? Years later, Yosh’s RL agent teaching itself TrackMania brought the idea back. By that point I’d studied computer science and actually had the tools to try. So I did.
If you’re not familiar with reinforcement learning, Lilian Weng’s overview and OpenAI’s Spinning Up are great starting points. For the uninitiated, we train an agent by rewarding (or punishing it) for it’s interaction with the environment. The agent learns to maximize its reward over time, which can lead to complex emerging behaviours, but also some hilarious fails. In our case, the reward boils down to “reach the end of the map as fast as possible”.
The First Attempt
DDNet is a C++ codebase with 40k+ commits dating back to 2007. There’s no Python API, no gym environment, no convenient env.step(). My first idea was to keep everything in C++ and run neural network inference directly in the game server using ONNX Runtime. No inter-process communication, no serialization, everything in one process.
After getting everything running without any errors, the policy just kept collapsing. The agent learned to output the same action regardless of the observation.
Debugging a neural network in C++ with limited tooling is not fun, especially if you’re on unfamiliar terrain. After what felt like an eternity I scrapped the approach and started over.
Cleaning up the Reinforcement Learning Workflow
Since I know python a lot better than anything C++-related, i moved the inference to Python (better debugging, TensorBoard, fast iteration). To avoid any more latency issues, I moved the bots into the game server process. This also avoids having to spawn a client process for each bot.
Originally, I wanted to be able to swap between different game modes (like pvp-modes). Since each game mode is essentially a fork o fthe original server code, I wanted to avoid modifying the server directly.
I modified the DDNet server to run 127 headless bots per process and communicate with Python through /dev/shm (shared memory, no sockets, no serialization overhead). I left one slot open so I can join the server as a human and observe the agents, which allowed me to record these videos.
With 8-12 server processes running in parallel, that’s 1,000-1,500 bots training simultaneously.
The basic flow looks like this:

How it works each tick
- The C++ server extracts observations (tile grid, player state, checkpoint info) and writes them to shared memory
- Python reads the observations, runs neural network inference, and writes actions back
- The server applies the actions, steps the physics, and calculates rewards
- Frame-skip of 3: the agent decides every 3rd tick, with rewards accumulating between decisions
Claude Code saved me a ton of time setting up the communication between C++ and Python. I think this is the least interesting part about this project, so I don’t feel bad about vibe-coding this.
What the agent sees and does
The observation space consists of a tile grid, player state (like hook state, freeze state, velocity) and some information about checkpoints.
The action space consists of direction (left, right, none), jump, hook, and a continuous aiming angle. Discretizing aim into angular buckets felt wrong here, because some maps require very precise aim.
A debug-script that allowed me to render the observation space in my terminal helped immensely:
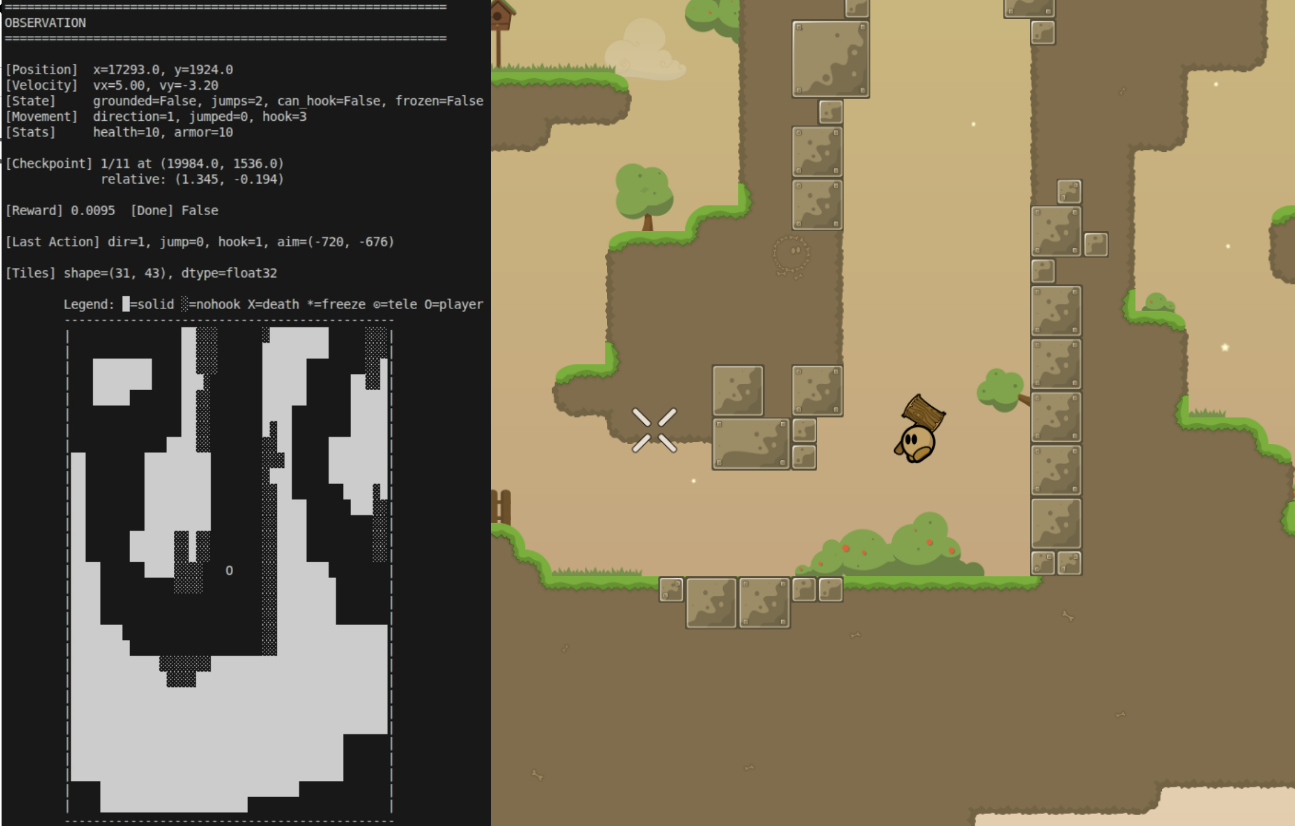
When the Agent Confidently Goes the Wrong Way
With the architecture working, I wrote a simple reward function: scan the map for checkpoint tiles, reward the agent for reaching them in order. Seemed reasonable.
One of the first training runs ended like this:
The agents just kept jumping towards this same spot. Some quick investigation in-game revealed why: there’s an unreachable teleporter way off the intended course, and the reward function was happily guiding the agent toward it.
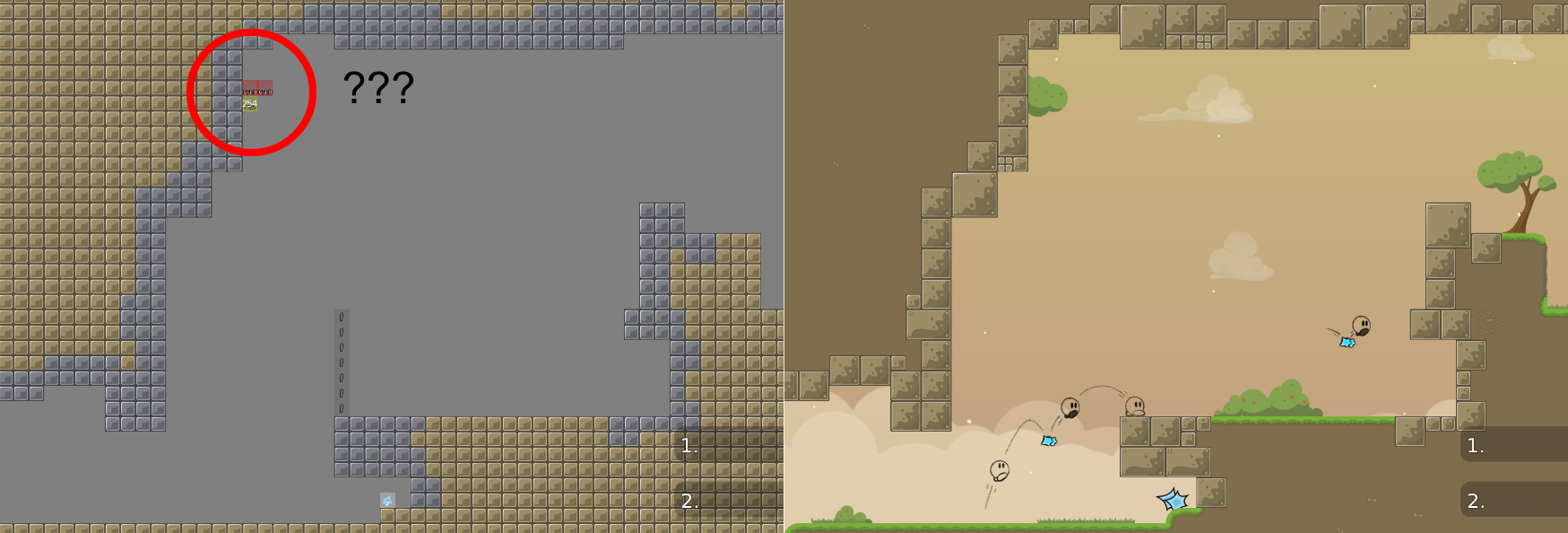
This is a DDNet-specific problem. The game has existed since 2007 and maps have been made for over 15 years. Every map author places checkpoints, teleporters, and freeze tiles differently. It’s the wild west. A reward function that assumes sequential, reachable checkpoints will break on maps that don’t follow that convention. And a lot of maps don’t.
The DDNet community helped a lot here. Without people who actually understand mapping, I would have spent a lot longer figuring out why things were breaking.
Reward Engineering
Version 1: Checkpoint rewards
The first real reward function scanned the map for time checkpoint tiles at startup:
- +10 for reaching a new checkpoint
- Continuous progress signal: reward proportional to distance-toward-next-checkpoint improvement (high water mark only, no penalty for backtracking)
- Small velocity bonus toward the checkpoint direction
- Penalties for death tiles, freeze, and time
This works well in principle, but as you could see earlier, it doesn’t work for every map. I wanted something that can guarantee success on any map.
Version 2: Waypoint-based rewards
Instead of trusting map designers, I instead decided to trace the actual path through the map.
I built two tools for this: a A decoder for the ghost replay format (.gho files, they use a static frequency table baked into the engine) to extract waypoints from human replays, and a tile-level BFS pathfinder that respects teleporters and avoids death tiles.
The reward became:
- Progress along the waypoint path (high water mark, no backtrack penalty)
- Distance-from-path penalty with a 128-unit grace zone (~4 tiles, enough slack for different movement styles)
- +100 finish bonus
This handled teleporters correctly because the waypoint path encodes the actual route. This is important, because some maps use mandatory teleporters between checkpoints, interrupting the path.
Here’s the result:
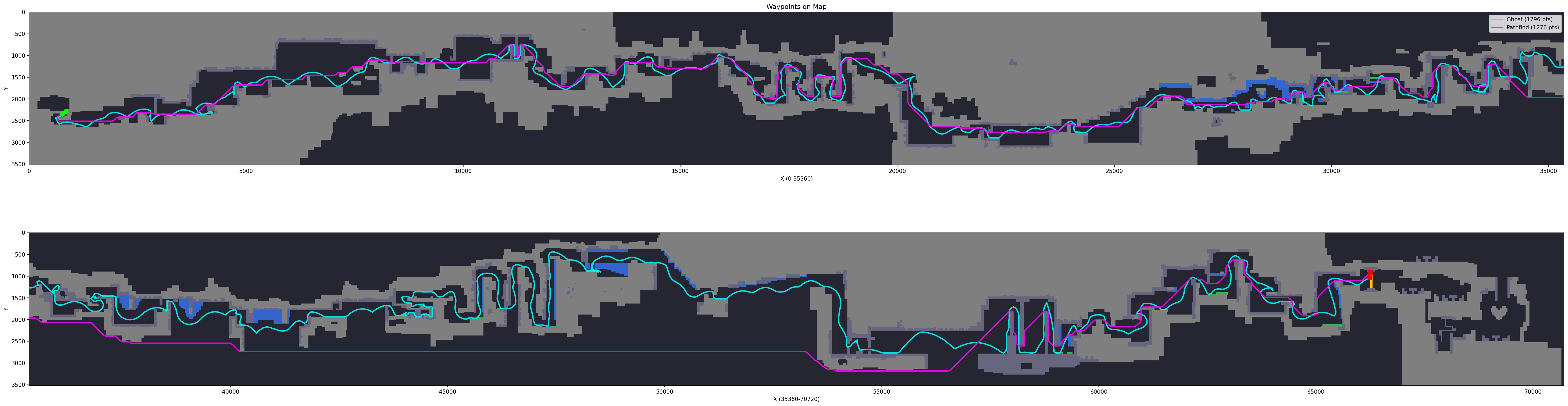
Cyan is the route calculated based on a ghost (an actual player completing the map), magenta is a naive BFS based on just the map data. In the second half of the map, magenta just goes out of bounds, which is why we can’t just rely on map data.
The big downside to this is that now you have to finish the map yourself first. I would also have to come up with a loop-detection algorithm, because you would get reset at certain checkpoints quite often.
Checkpoint Respawning
Early in training the agent dies within the first few seconds. Later it can reach checkpoint 10 but still restarts from checkpoint 0 every episode. Most training time is spent re-doing sections the agent has already mastered.
To address this I added adaptive checkpoint respawning, which is quite similar to an algorithm called Go-Explore.
- Track a rolling buffer of episode outcomes (highest checkpoint reached)
- On reset, sample a spawn position from the top-performing episodes
- 20% of resets still start from the beginning to maintain full-map skill
- Spawns are capped at a “frontier”, the highest checkpoint proven reachable from the start, so the agent can’t spawn ahead of its actual capability
This is similar to curriculum learning but driven by the agent’s own performance data rather than a manual schedule.
Some people might be asking: Why implement this whole frontier-thing instead of distributing spawns uniformly across all checkpoints? Honestly, it just felt like cheating to me. I wanted the agent learning experience to be as close as possible to what a human would get.
What’s Next
Curriculum learning across maps
Right now every agent is trained on a single map. The goal is to start on easy maps and gradually introduce harder ones, so the agent builds transferable skills instead of memorizing one route.
Throw more compute at it
35-minute runs were enough to validate the approach and tune hyperparameters, but they barely scratch the surface. I did do some over night training runs on my measly 3080, but the difference wasn’t significant. I’d have to rent some compute to see if that actually makes a difference.
Different Game Modes
What I always loved about this game is the variety in game modes. There’s many different pvp modes, solo race, and cooperative race modes. This could lead to all sorts of interesting projects like multi-agent reinforcement learning.
Learnings
When I started this project, I wanted to build a bot I can in theory let loose on random servers and maps. I wanted a generalist agent that can race on any map competitively or a super-human training buddy for PvP modes. Over the course of development, I realized that bit off a lot more than I could chew. I learned that reinforcement learning largely consists of ground work: You need to add Infrastructure, Logging, Debugging and optimization before you can actually get down to business. I had to make a lot of concessions I didn’t think I’d have to make.
However, in the end, I’m satisfied with my initial results. There is still a lot of room for improvements and I will surely revisit this problem in the future. But for now, I’ll move on.
References
- Lilian Weng: A (Long) Peek into Reinforcement Learning, solid RL overview
- OpenAI Spinning Up, for anyone who wants to go deep on RL fundamentals
- Yosh: TrackMania RL, one of the projects that inspired this work
- SethBling: MarI/O, the video that planted the seed
Related Work: