Training to GPT-2 level performance on CORE metric 1Marginnote recent_benchmark1https://github.com/karpathy/nanochat/discussions/481 ↩ has dropped from $43K in 2019 to $73 in 2026. I wanted to train Nanochat 2Marginnote nanochat2“The best ChatGPT that $100 can buy.” Nanochat Repository ↩ on spot instances, where Karpathy mentions the cost can be even lower to $20 on 8xH100 GPUs. But, on Runpod, I was confronted with a choice - H100 PCIe, SXM or NVL. Each at varying price points.
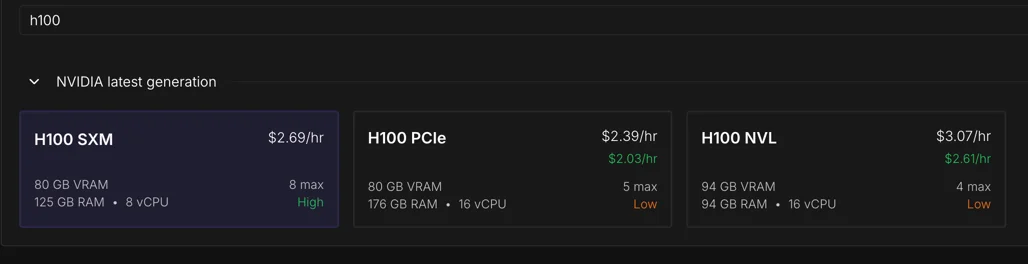
I knew these were different network interconnect options from the CS336 course 3Marginnote cs3363lecture 5 https://www.youtube.com/watch?v=6OBtO9niT00 ↩ and that NVLink 4.0 was supposed to be fast.
Prof. Percy Liang mentions in the first lecture of CS336, the mindset while training LLMs is to squeeze most performance of the hardware. This mindset from the course, led me to examine what each of these interconnect variants has to offer.
To train the model cheaply, is the cheapest instance the best choice to complete the training run? I decided to benchmark all three.
TL;DR
I benchmarked 8xH100 on SXM, PCIe and NVL offerings across Runpod and Vast.ai SXM, although expensive per hour, is the clear choice to train Nanochat within 3 hours at ~$37. Making it 2x cheaper than PCIe and 3x cheaper than NVL. But, even SXM can regress if GPUs are split across NUMA nodes.
Why care about the network interconnect?
While training on multiple GPUs, most parallelism techniques use the interconnect to transfer gradients at every step.
The current implementation of Nanochat takes about 3 hours to train on an 8xH100. The optimizer is the only distributed component.
Nanochat uses a combined Muon + AdamW optimizer 4Marginnote distmuonadamw4DistMuonAdamW optim.py ↩. Muon handles all large 2D matrices5Marginnote muon_ops5Muon handles - Attention projections (Q, K, V, O) and MLP weights (c_fc, c_proj) plus the tiny Value Embedding Gates. ↩, the transformer block essentially. AdamW for the rest: input token embeddings (wte), LM head, Value embeddings, and two small residual addition scaling parameters (x0_params and resid_params). The optimizer runs in two stages: phase 1 is for reduce ops and phase 2 is for gather ops.
Phase 1 averages gradients across devices6Marginnote devices6Think of devices as a host having multiple GPUs. Each GPU has a rank (its ID) ↩.
all_reduce and reduce_scatter primitives are used for this.
In Nanochat, all_reduce is used for tiny parameters (under 1024 elements), each rank receives the full averaged gradient in a single collective.
Since these are just a few KB, the overhead to send them to all ranks is negligible.
reduce_scatter the sharded alternative, handles rest of the parameters, each GPU receives 1/8 of the averaged gradient.
Phase 1
reduce_scatter(grads)
GPU 0 → avg_grad[0:N/8]
GPU 1 → avg_grad[N/8:2N/8]
...Then in phase 2, each rank runs the optimizer on its shard in isolation, producing updated parameters for that slice.
After this, all_gather lets every rank collect all the shards, so each rank has the full updated parameter tensor for next forward pass.
Phase 2
optimizer(shard) → updated params
all_gather(params)
GPU 0 → params[0:N/8]
GPU 1 → params[N/8:2N/8]
...
→ all ranks get full params[0:N]This is the Zero-2 7Marginnote zero_27Zero Stage 2 Paper ↩ pattern. Each GPU only needs optimizer state (momentum, variance buffers) for its shard, cutting memory to 1/world_size8Marginnote world_size8world_size - Total number of GPUs ↩. I strongly recommend watching Lecture 7 9Marginnote lecture79Lecture 7 - CS336 ↩ in CS336 to get a deeper idea.
All figures above are from Nvidia’s NCCL documentation, which has great visualisation to understand this.
Analytical estimates of the data transfer for d26 Nanochat
From the Nanochat model architecture, we can estimate the data transfer required for each parameter group. The optimizer moves data in two phases: ReduceScatter to average gradients, then AllGather to distribute updated parameters.
Each optimizer step transfers roughly 7.1 GB across the interconnect. ~3.6 GB in AllGather (bf16), ~3.6 GB in ReduceScatter (split between bf16 and f32), and a negligible AllReduce for the two small lambda parameters. We get this value by adding the tensor sizes across all parameter groups - lm_head, wte, value_embeds, and the Muon-managed transformer blocks.
Per-group communication volume & NCCL op summary (per optimizer step)
| group | kind | num_params | padded_count | elements_per_param | total_elements | RS (MB) | AG (MB) | AR (MB) |
|---|---|---|---|---|---|---|---|---|
| lm_head | adamw | 1 | 1 | 54,525,952 | 54,525,952 | 109.1 | 109.1 | 0 |
| wte | adamw | 1 | 1 | 54,525,952 | 54,525,952 | 109.1 | 109.1 | 0 |
| value_embeds | adamw | 13 | 13 | 54,525,952 | 708,837,376 | 1417.7 | 1417.7 | 0 |
| resid_lambdas | adamw | 1 | 1 | 26 | 26 | 0 | 0 | 0 |
| x0_lambdas | adamw | 1 | 1 | 26 | 26 | 0 | 0 | 0 |
| muon (13, 32) | muon | 13 | 16 | 416 | 6,656 | 0 | 0 | 0 |
| muon (1664, 1664) | muon | 104 | 104 | 2,768,896 | 287,965,184 | 575.9 | 575.9 | 0 |
| muon (1664, 6656) | muon | 26 | 32 | 11,075,584 | 354,418,688 | 708.8 | 708.8 | 0 |
| muon (6656, 1664) | muon | 26 | 32 | 11,075,584 | 354,418,688 | 708.8 | 708.8 | 0 |
NCCL op summary per step (compare with nsys CUDA GPU Kernel Summary)
| nccl_op | dtype | calls_per_step | total_MB | avg_MB_per_call | min_MB_per_call | max_MB_per_call |
|---|---|---|---|---|---|---|
| AllGather | bf16 | 19 | 3629.4 | 191 | 0 | 708.8 |
| AllReduce | bf16 | 2 | 0 | 0 | 0 | 0 |
| ReduceScatter | bf16 | 15 | 1635.8 | 109.1 | 109.1 | 109.1 |
| ReduceScatter | f32 | 4 | 1993.6 | 498.4 | 0 | 708.8 |
That 7.1 GB is the tax every single training step pays.
Choice of H100
Back to our first question, which H100 instance to choose? Most providers offer the H100 in two form factors SXM and NVL 10Marginnote h100_offering10Nvidia H100 specification ↩.
SXM variant is a custom baseboard from Nvidia, whereas NVL is installed through the PCIe dual-slot. The Hopper architecture introduced FP8 which also led to the faster training time on the Nanochat leaderboard. At that precision SXM delivers 3,958 TFLOPS vs NVL’s 3,341.
These GPUs can be interconnected through NVLink or PCIe. NVLink offers 900 GB/s (bidirectional) on SXM vs 600 GB/s on NVL, and just 128 GB/s on PCIe. One important note is that on NVL instances, only two GPUs can be connected through NVLink. Within a pair, NVLink on NVL gives 300 GB/s per direction, and cross-pair traffic falls back to PCIe. On SXM instances, NVSwitch connects all GPUs in a mesh providing 450 GB/s per direction (900 GB/s bidirectional).
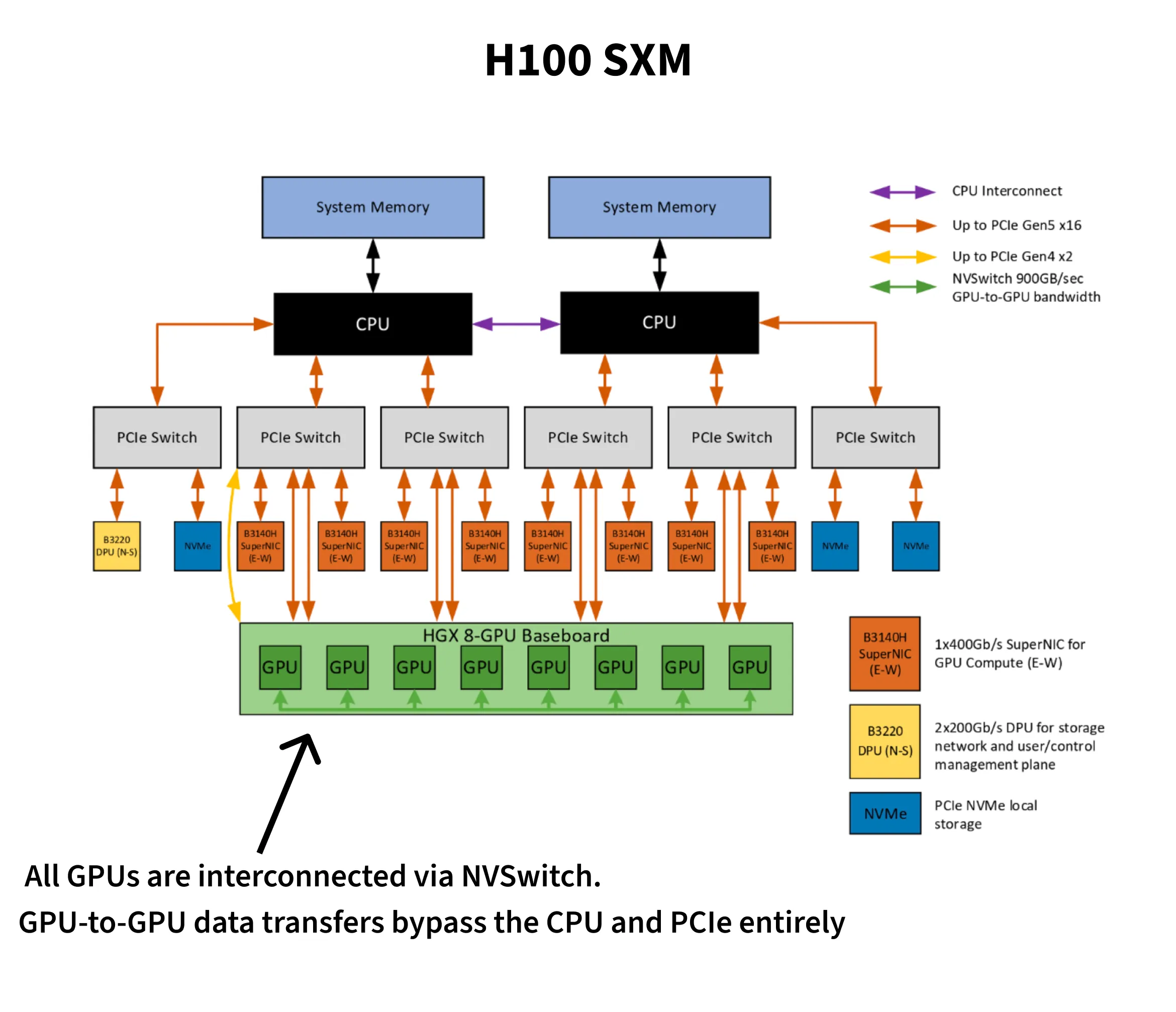
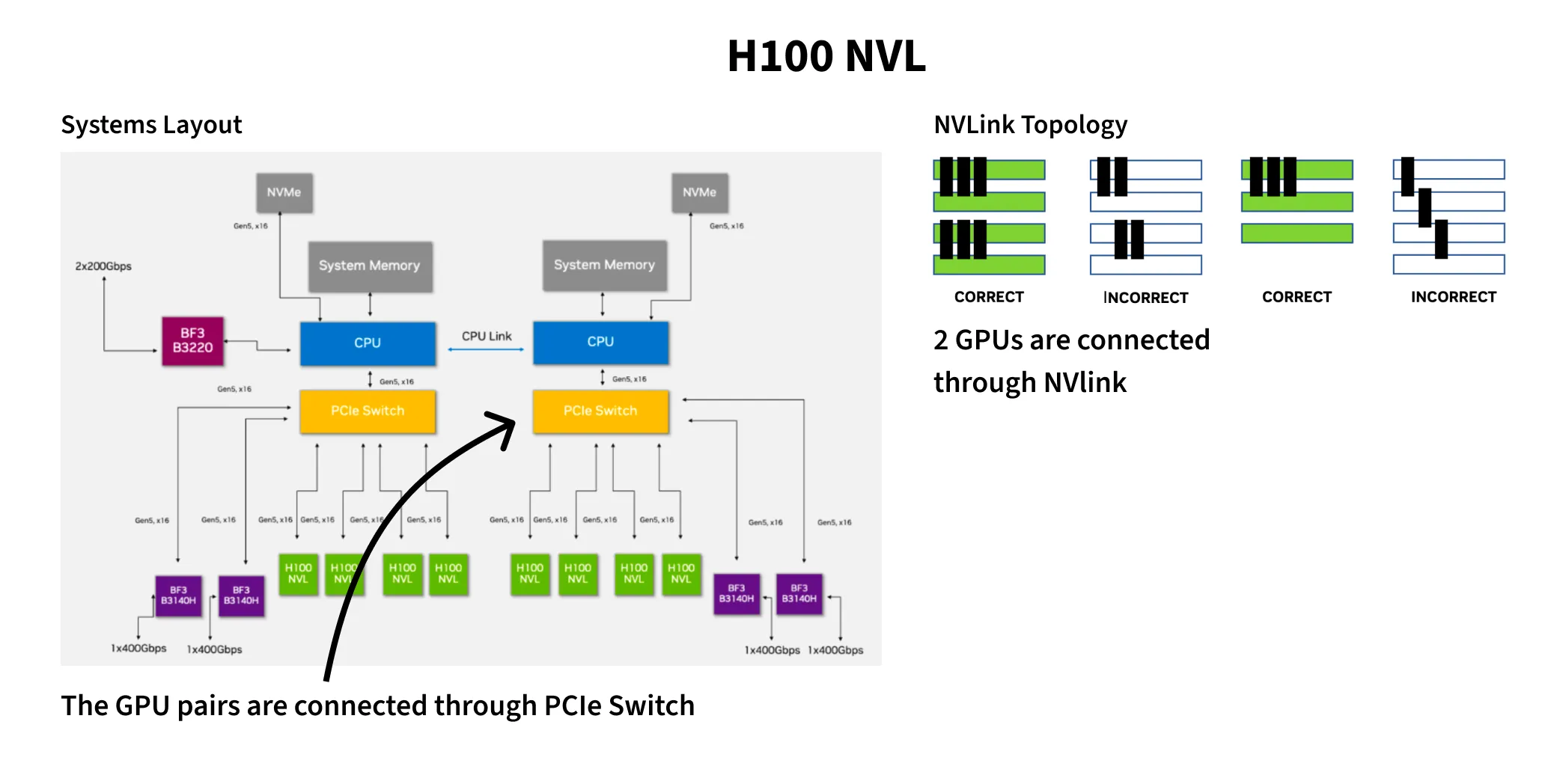
They also differ in max thermal design power (TDP). SXM can go up to 700W while NVL peaks at 400W. Higher power draw unlocks better clock speeds and, in turn, better FLOPs per dollar. Horace He explores this in a fun blog11Marginnote horace_he11https://www.thonking.ai/p/strangely-matrix-multiplications ↩ about how data values affect power draw. Predictable data - complete zeros or ones flip fewer transistors, leading to less dynamic power and in turn better clock speeds.
Runpod is one of the few providers to offer all three - SXM, NVL and PCIe. The cost for SXM is higher than PCIe but cheaper compared to NVL. Vast.ai also has SXM configuration at varied price points for both on-demand and spot instances, in many cases, cheaper than Runpod’s SXM.
Prices as of early March 2026, US regions. Cloud GPU pricing changes frequently.
| Runpod PCIe | Runpod NVL | Vast.ai SXM | Runpod SXM | |
|---|---|---|---|---|
| 8-GPU node/hr (on-demand) | $19.12 | $21.52 | $12.85 | $21.5 |
| 8-GPU node/hr (spot) | $10 | $13.2 | $7-$10 | $14 |
The theoretical bandwidth ratio between NVLink (~450 GB/s per direction on SXM) and PCIe 5.0 (~64 GB/s per direction) is roughly 7x 10. If that ratio holds in practice, SXM should recoup its price premium on interconnect savings alone.
Benchmarks
My initial hypothesis was SXM instances were more expensive per hour, but they would be cheaper to complete the training run.
From the nanochat leaderboard12Marginnote leaderboard12d26 + FP8 link ↩, the d26 GPT-2 record uses --target-param-data-ratio=8.5 with FP8, training on ~7.8B tokens at batch size 524,288 for 14,889 steps to reach CORE 0.2578 (original GPT-2: 0.2565).
Each step has the model forward, backward and the optimizer step.
My first benchmark used PCIe (starting with the cheapest option) which gave a baseline of ~1400ms. Next, when I ran the with SXM, it was just a minor improvement to ~1200ms. PCIe would be a better choice to complete the training run at this level. These results were starkly different to my hypothesis.
The first difference between the two instances was PCIe had 252 vCPUs and SXM only 160 vCPUs. Then I found a Vast.ai offering for 256 vCPUs for SXM, which outperformed PCIe at 700ms. Finally in the promised land of performance.
To check if this improvement was purely due to vCPU sizing, I ran with 128 vCPUs SXM on vast.ai and found it match the 256 vCPUs SXM run. In later sections, I detail about this disparity and the possible causes in the apparent regression of SXM 160 vCPUs on Runpod. And finally, I benchmarked the NVL configuration for completeness.
In the results reported, I only talk about the three variants - SXM 128 vCPUs (on vast.ai), PCIe 252 vCPUs and NVL 128 vCPUs on Runpod. The experiments that failed are in the final section.
I wrote this profiling script here 13Marginnote profile_comms.py13profile_comms.py ↩ which performs a warmup of 3 steps and then profiles 10 steps.
I use torch.cuda.Event to time each step.
This also isolates the optimizer’s average time, revealing network overhead.
I measured compute and network time separately, even though they overlap during normal training.
The measured times will be slightly higher than actual Nanochat training.
Along with this, I also added Nvidia’s nsys to tool annotate specific parts of the script.
Through torch.cuda.nvtx.range_push each operation’s timing is broken down.
The nvtx ranges and cuda events are split into three phases - Phase 1-Reduces, Phase 2-Compute+Gather, Phase 3-WaitGathers.
Phases 1 and 2 are GPU-intensive. They perform network collectives and fused optimizer kernels.
Phase 3 is a synchronization step where CPU waits on network completion.
Measured Step Times for d26
Profiled at device_batch_size=32, total_batch_size=524,288 (no gradient accumulation). The d26 GPT-2 record (Run 2) uses the same batch size with device_batch_size=16 and grad_accum=2, which produces equivalent step times.
SXM completes each step in ~702ms. Nearly half the time of PCIe, and a third of NVL.
| Platform | vCPUs | Avg Step Time | Optimizer Step | Comm Overhead | Relative | Training Time |
|---|---|---|---|---|---|---|
| SXM (NVSwitch) | 128 | 701.9 ms | 57.8 ms | 8.2% | 1.00x | 2.90 hours |
| PCIe | 252 | 1411.6 ms | 375 ms | 26.6% | 2.01x | 5.84 hours |
| NVL | 128 | 2031.5 ms | 395.6 ms | 19.5% | 2.89x | 8.40 hours |
From the earlier section, we know SXM’s NVSwitch mesh gives every GPU full bandwidth to every other GPU. PCIe is limited to ~64 GB/s per direction, and NVL only has NVLink within pairs, cross-pair traffic falls back to PCIe. The results echo the same.
NCCL Communication
Measured GPU kernel execution times from Nsight Systems. All three runs produced the same total kernel call counts, enabling direct comparison of total times.
The measured 7.3x difference in total NCCL kernel time between SXM and PCIe lines up almost exactly with the spec sheet’s 7x bandwidth ratio.
Per-Kernel Average Latency
From nsight, I exported the NCCL calls from the CUDA GPU Kernel Summary across all configurations.
SXM performs the best here. NVL has NCCL kernel times nearly identical to PCIe.
NVL step time (2031 ms) is 44% worse than PCIe (1412 ms) even though NCCL kernel times are nearly identical.
One plausible explanation: on NVL, inter-pair traffic shares the PCIe bus with host-to-device transfers, starving both. However, I did not verify this with nvidia-smi topo -m on the NVL node, nor did I check whether the NVL instance had a NUMA split similar to the SXM regression described later. This anomaly deserves deeper investigation.
Model Size Sensitivity (d12 vs d26)
Does a smaller model show the same interconnect sensitivity? I profiled d12 (286M params, device_batch_size=32, grad_accum=1) alongside d26 for two configurations.
Smaller models are more communication-sensitive because their compute-to-communication ratio is lower — less time in matmuls means the interconnect bottleneck becomes a larger fraction of each step. d12 spends 23% of step time in communication on SXM vs d26’s 8.2%. Surprisingly, Phase 1 time of NVL is faster than SXM for d12 likely because the small reduce volume fits within a single NVLink pair’s bandwidth, avoiding NVSwitch overhead.
d12 Optimizer Phase Breakdown
| Platform | Phase 1 | Phase 2 | Phase 3 | Total Optimizer |
|---|---|---|---|---|
| SXM 128 vCPU | 4.2 ms | 25.2 ms | 11.7 ms | 41.2 ms |
| NVL 128 vCPU | 2.7 ms | 36.3 ms | 23.4 ms | 62.3 ms |
Takeaways
For a total of 14,889 steps, SXM completes the training in nearly half the time of PCIe and a third of NVL. At $12.85/hr on Vast.ai, it’s also the cheapest per-hour option.
| Provider | Config | $/hr (8-GPU) | vCPUs | Step Time | Training Cost (projected) |
|---|---|---|---|---|---|
| Vast.ai | SXM | $12.85 | 128 | 701.9 ms | $37.27 |
| Runpod | PCIe | $19.12 | 252 | 1411.6 ms | $111.66 |
| Runpod | NVL | $21.52 | 128 | 2031.5 ms | $180.77 |
These projected costs assume linear scaling (hourly rate × training hours) and do not account for environment setup, compilation, data loading, or potential spot instance preemptions requiring restarts. Actual costs will be somewhat higher depending on the startup scripts.
SXM configurations seem to be the norm from most providers. Runpod was the only provider to have all three configurations and also offered them as spot instances. Vast.ai is a bit of a lucky draw essentially, since it’s a marketplace not all the configurations are available consistently. For shorter training runs like Nanochat, it is the best fit. Lambda.ai has 208 vCPU count and offers only SXM, Modal also offers only SXM and has a configurable CPU count since they are serverless.
Through this exercise, I now have a better intuition on how to train with spot instances.
I wrote this profile_comms.sh script to fail fast.
It runs three checks before installing or downloading anything
- CUDA sanity check calls
nvidia-smiandtorch.cuda.init()to catch driver mismatches or broken GPU state early. - NCCL communication check runs a dummy
torchrunacross all GPUs (nccl_check.py) to verify inter-GPU communication works. This catches SHM bugs and misconfigured network interfaces before any real profiling begins. - NUMA topology dump logs the full GPU-to-NUMA-node mapping via
nvidia-smi topo -mand PCI sysfs lookups, so you can immediately spot a NUMA split without manual debugging. - Additionally, keeping an eye on the internet download speed before starting the instance is a good check. Vast.ai has some instances that are quite slow, this increases the cost of the training run since the GPUs sit idle.
Only after these pass does the script install dependencies, download data, and run the actual nsys profiling for d12 and d26.
Mistakes I made and issues I ran into
1. CPU starvation on the SXM run and NUMA socket pinning
My benchmark on SXM with 160vCPUs on Runpod clocked 1295ms per step, barely faster than PCIe’s 1412ms with 252 vCPUs. With higher FLOPs and faster interconnect SXM should have been a massive step-up, not a minor improvement.
Assuming it’s CPU starvation, I found a 256 vCPUs instance on vast.ai and got 702ms, 2x improvement.
Through Nsight Systems, I found the GPU kernels themselves were fast, but they spent long stretches idle, waiting for the CPU to signal the next chunk in NCCL’s ring protocol.
The pthread_cond_signal count was 1.58 million in a 10-step profile on the 160vCPUs, vs ~4,000 on a healthy instance with 256 vCPUs.
Running more experiments on Runpod with NVL and PCIe, I ran into multiple issues - slow internet on the VM, CUDA driver issues and also NCCL misconfigurations.
To ensure I was not fitting data to my narrative, I re-ran on Vast.ai with 128 vCPUs and got 701.9ms. Identical to the SXM with 256 vCPUs. The CPU was not the only bottleneck. Dumping the machine topology revealed the most striking difference: Runpod split GPUs 4+4 across two NUMA14Marginnote numa14Non-Uniform Memory Access is a memory layout design used in data center machines. Link ↩ nodes, while Vast.ai placed all 8 on NUMA node 0. There were also CUDA driver version differences (560 vs 570) and different kernel configs between the two hosts, so I can’t attribute the regression to a single cause. That said, the NUMA split is the strongest hypothesis, and here’s why.
Multi-socket15Marginnote socket15A CPU socket is the physical connector on the motherboard that holds one CPU chip. A dual-socket server has two CPUs, each with its own local memory and PCIe lanes. ↩ servers have a NUMA (Non-Uniform Memory Access) architecture, each CPU socket has its own local memory.
Accessing local memory takes ~10ns, but reaching memory on the other socket crosses the UPI (Ultra Path Interconnect) at ~100ns.
When GPUs are split across NUMA nodes, NCCL’s CPU-side coordination threads, the ones signaling pthread_cond_signal and holding mutexes, pay this cross-socket penalty on every ring protocol step.
The OS scheduler makes it worse: without explicit pinning, it can schedule a thread managing GPU 5 (socket 1) onto a core on socket 0, turning every memory access and signal delivery into a cross-UPI hop.
numactl --cpunodebind=N --membind=N pins processes to a specific socket, but NCCL spawns its own internal threads which may not respect this.
The clean fix is what Vast.ai had: all 8 GPUs on a single NUMA node, so cross-socket latency never enters the picture.
GPU-to-GPU NVLink communication is unaffected by NUMA since the bits travel over NVSwitch (data plane), never touching the CPU.
But NCCL’s control threads, which orchestrate these transfers, run on the CPU (control plane).
There is active discussion on PyTorch to include NUMA pinning to torchrun - Link.
I haven’t isolated whether NUMA, drivers, or kernel config dominates. I’ll cover it in a follow-up post with controlled experiments.
Run
nvidia-smi topo -mon every new instance before benchmarking. If GPUs span multiple NUMA nodes, expect NCCL overhead. And always profile before trusting step times, a bad instance can masquerade as “SXM isn’t worth it.”
2. Spot instances being preempted mid-profile
Spot instances are 30 to 50% cheaper than on-demand instances. But the trade-off is they can be shut down at any point with a 5-second notice. Since the profiling takes roughly 12 minutes including installation, env setup and actual profiling, I was confident I could get the work done on spot instances. But I did run into shutdowns a couple of times.
3. Broken Nodes throwing CUDA errors
I ran into this issue a few times, where the host has not been configured correctly. Likely CUDA driver or GPU state was broken due to driver mismatch. Fixing this issue on the pod that is billed by the second is expensive. Shutting it down and trying at a later time is the best alternative.
>>> import torch, sys, os
>>>
>>> print(f'PyTorch {torch.__version__}, built with CUDA {torch.version.cuda}')
PyTorch 2.8.0+cu128, built with CUDA 12.8
>>>
>>> torch.cuda.init()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.12/dist-packages/torch/cuda/__init__.py", line 379, in init
_lazy_init()
File "/usr/local/lib/python3.12/dist-packages/torch/cuda/__init__.py", line 412, in _lazy_init
torch._C._cuda_init()
RuntimeError: CUDA unknown error - this may be due to an incorrectly set up environment, e.g. changing env variable CUDA_VISIBLE_DEVICES after program start. Setting the available devices to be zero.4. NCCL connection issues on NVL
On one of the community instances of 8xH100 NVL on Runpod, there was a NCCL communication issue.
The instance was unable to use SHM (Shared Memory), a fast inter-process transport using /dev/shm.
I tried benchmarking anyway by disabling SHM through NCCL_SHM_DISABLE=1.
NCCL selects a transport for each GPU pair based on what the hardware supports. On an 8-GPU NVL node, only 4 of the 28 GPU pairs share NVLink, those pairs use the NVLink transport directly.
For the remaining 24 pairs, NCCL tries P2P over PCIe first; when direct P2P isn’t available (common in multi-root PCIe topologies), it falls back to SHM (shared memory via /dev/shm), which copies data through host memory as an inter-process transport 16Marginnote nccl_details16NCCL transport selection hierarchy: NVLink → P2P (PCIe) → SHM (host memory IPC) → NET (sockets). See the NCCL source and this paper for details. ↩.
Disabling SHM with NCCL_SHM_DISABLE=1 removes this fallback, forcing those 24 pairs onto IP sockets, which are orders of magnitude slower. Since most ring hops on an NVL node cross non-NVLink pairs, this effectively cripples the majority of the communication path.
So, I had to do another run on the secure cloud of Runpod which also had a NVL instance. This performed much better.
| Metric | NVL (128 vCPUs) | NVL no SHM (152 vCPUs) | Degradation |
|---|---|---|---|
| Step time | 2031.5 ms | 6495.1 ms | 3.2x |
| Optimizer step | 395.6 ms | 5402.9 ms | 13.7x |
| Comm overhead | 19.5% | 83.2% | — |
| Total NCCL (10 steps) | 30.08s | 430.58s | 14.3x |
| AllGather avg | 8.715 ms | 142.656 ms | 16.4x |
| RS f32 avg | 30.937 ms | 393.702 ms | 12.7x |
| AllGather max | — | 1040 ms | — |
NCCL degrades by 14.3x when SHM is disabled. Note: the no-SHM instance had slightly more vCPUs (152 vs 128), which should have helped, making the SHM effect even more dramatic than the raw numbers suggest.