Your container images are tar archives compressed with gzip. That single design decision, made in the Docker era and inherited by OCI, means that reading any file requires downloading and decompressing the entire layer from byte zero. For a 12GB ML image, that’s 2-8 minutes of cold-start time before a single inference request, depending on your bandwidth to the registry.
Lazy-pulling fixes this by fetching only the bytes you need, when you need them. The concept has existed since 2019. Multiple implementations are in production today. They all solve the same byte-level problem and they all require the same infrastructure change: swapping containerd’s snapshotter, deploying a FUSE daemon on every node, and accepting that your registry just became a runtime dependency.
This post starts with why the problem is harder than it looks at the byte level, then surveys the major approaches and what they trade off. The core of the post is a hands-on experiment: I deploy an in-cluster registry, convert images to eStargz, patch containerd with a custom snapshotter, and measure something nobody benchmarks properly. Not just pull time, but readiness, the moment a container can actually serve its first request.

A note on scope. This post is about container image layers, the runtime, libraries, and application code that make up the OCI image. Model weight delivery is a different topic and won’t be covered here.
A container image layer is a POSIX tar archive. Tar was designed for tape, literally Tape ARchive, and it shows. There is no central directory, no file index, no way to find a file without scanning from the beginning:
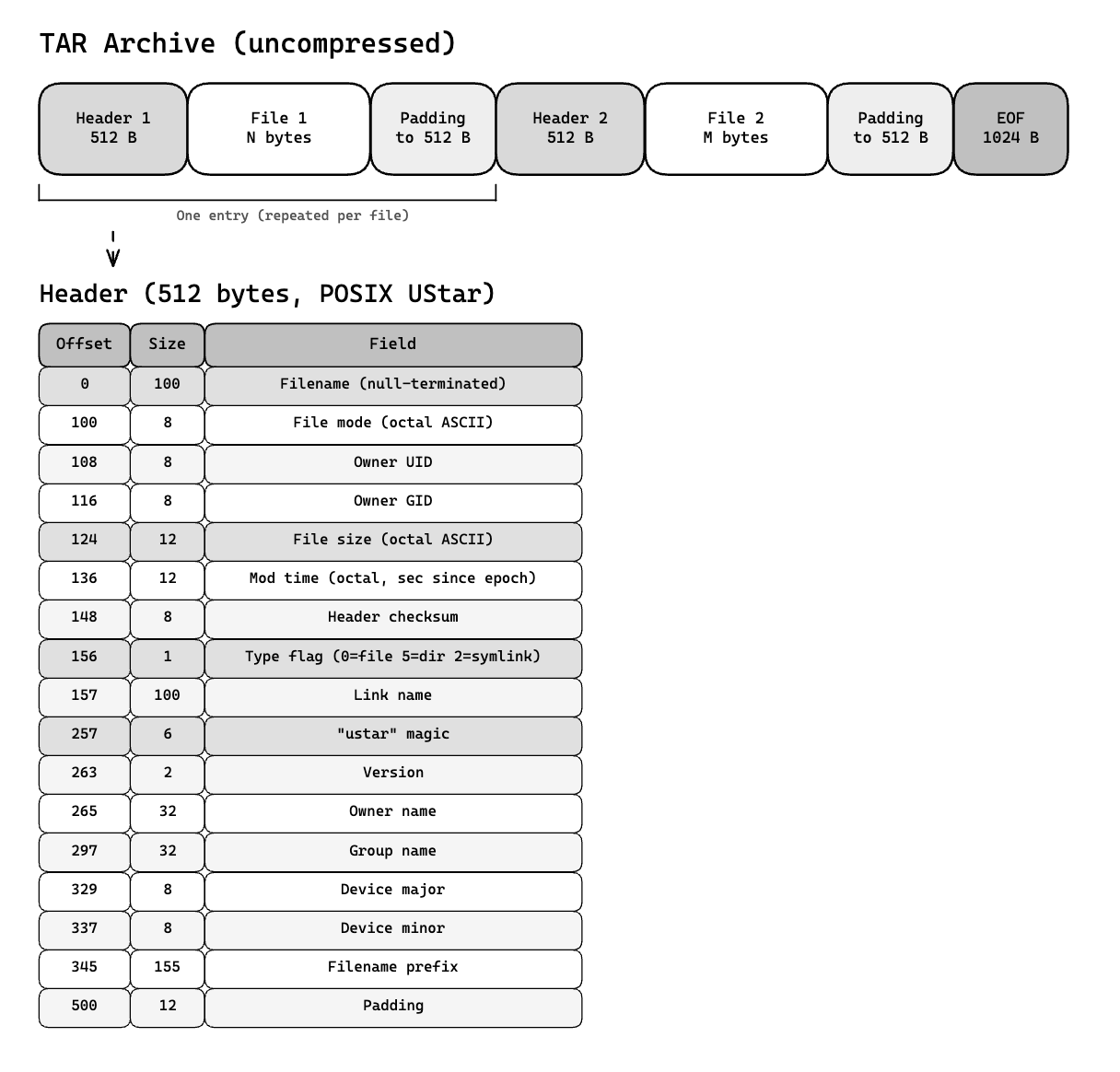
To find /usr/bin/python3 in a tar archive, you read the first header (512 bytes), check the filename, skip past the file data (reading the size field to know how far), read the next header, and repeat until you find your target or hit EOF. For a layer with 10,000 files, that’s potentially scanning through gigabytes of file data you don’t care about.
This is already slow. Gzip makes it worse.
Container layers are tar.gz, the tar archive above compressed as a single gzip stream. GZIP uses DEFLATE compression (RFC 1951), which combines two techniques:
LZ77 (sliding window) replaces repeated byte sequences with back-references. Instead of storing “the quick brown fox” twice, the second occurrence becomes a (distance, length) pair pointing back to the first. The window size is up to 32KB. Any byte in the output can reference up to 32,768 bytes before it.
Huffman coding uses variable-length encoding where frequent symbols get shorter codes. The coding tables can be static (pre-defined) or dynamic (computed per block and embedded in the stream).
Together, these create a decompression dependency chain:
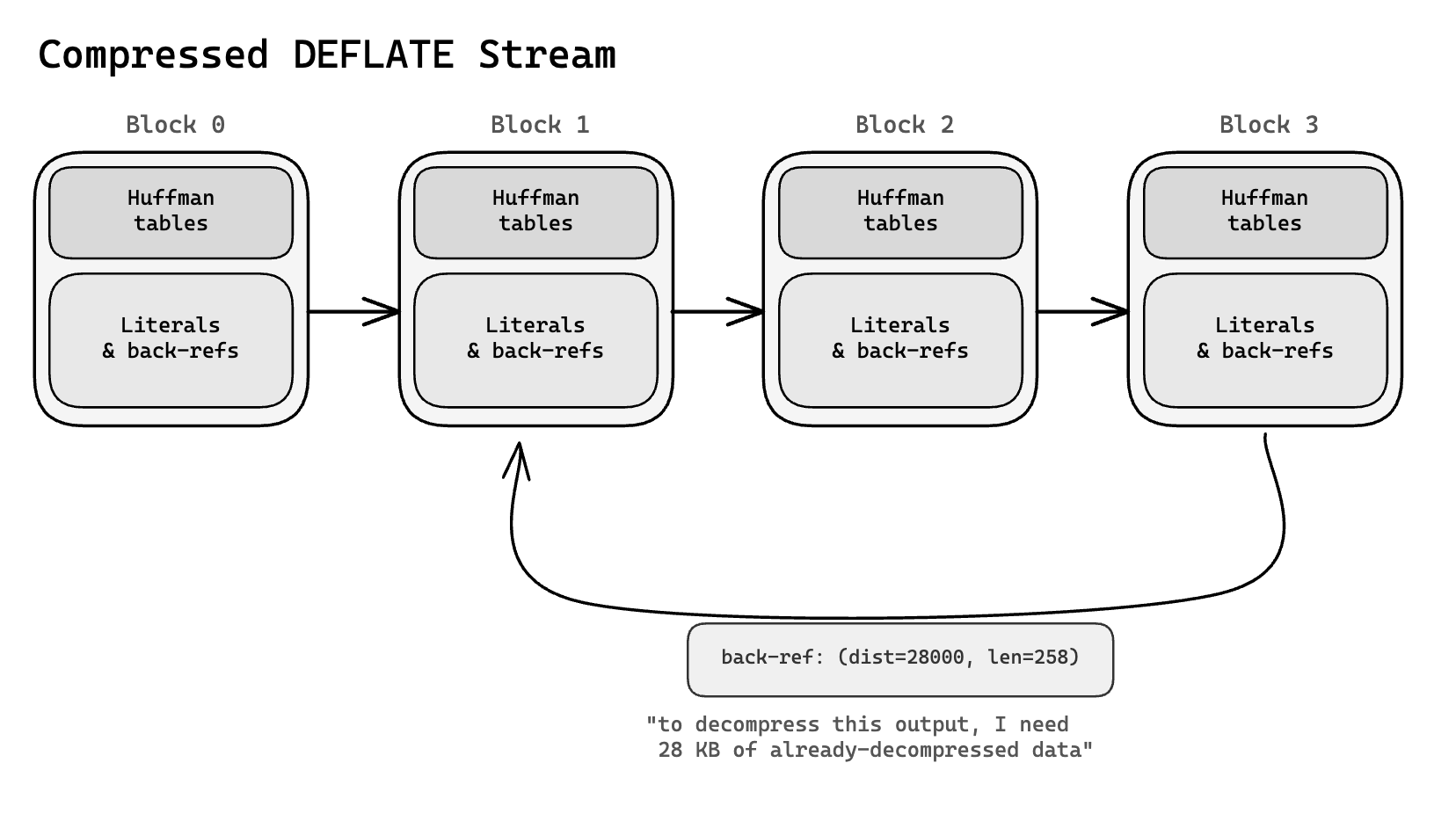
To decompress Block 3, the decompressor needs the Huffman tables for Block 3 (embedded in the block header, or the static tables), up to 32KB of previously decompressed output (the sliding window) for resolving back-references, and the current bit position in the compressed stream (DEFLATE is bit-aligned, not byte-aligned).
The decompressor state at any point is a function of everything that came before. There is no way to start decompressing at Block 3 without either decompressing Blocks 0-2 first or having a saved snapshot of the decompressor’s internal state at the Block 3 boundary.
This is the fundamental problem. A 5GB compressed layer containing 10,000 files is a single DEFLATE stream. To read the last file, you decompress from byte 0. There’s no shortcut within the format.
For a modern LLM serving image (think vLLM, SGLang, or TensorRT-LLM), excluding model weights which are typically mounted separately or pulled from object storage:
Runtime layers: 12.3 GB compressed, 28.5 GB uncompressed, 5 layers
├── Base OS (Ubuntu)
├── CUDA runtime + cuDNN
├── Python + pip packages
├── PyTorch
└── vLLM application code
Traditional pull sequence:
1. Download 12.3 GB → 2-8 min (depends on link speed)
2. Decompress 12.3 GB → 28.5 GB → 2 min (CPU-bound)
3. Write 28.5 GB to overlayfs (5 layer extracts) → 3 min (IO-bound)
────────────────────────────────────────────────────────────────────
Total: ~7-13 minutes to container Running state
What the container actually reads at startup:
Python interpreter + stdlib + torch + vllm imports ≈ 150 MB
That's 1.2% of the uncompressed image.You download 12.3 GB of runtime layers to read 150 MB. The remaining 98.8% sits on disk, fully decompressed, waiting for requests that might never come. On GPU nodes costing $3-30/hr, those minutes of idle accelerator time add up, and that’s before you’ve even started loading model weights.
Every lazy-pulling solution addresses the same problem, which is making individual files accessible without downloading the entire layer. They differ in where they break the DEFLATE dependency chain and what they require at the format level.
The core insight. RFC 1952 says a gzip file can contain multiple concatenated members. Standard decompressors treat them as a single stream. But each member has its own independent DEFLATE state.
eStargz recompresses each file (or chunk of a large file) as a separate gzip member:
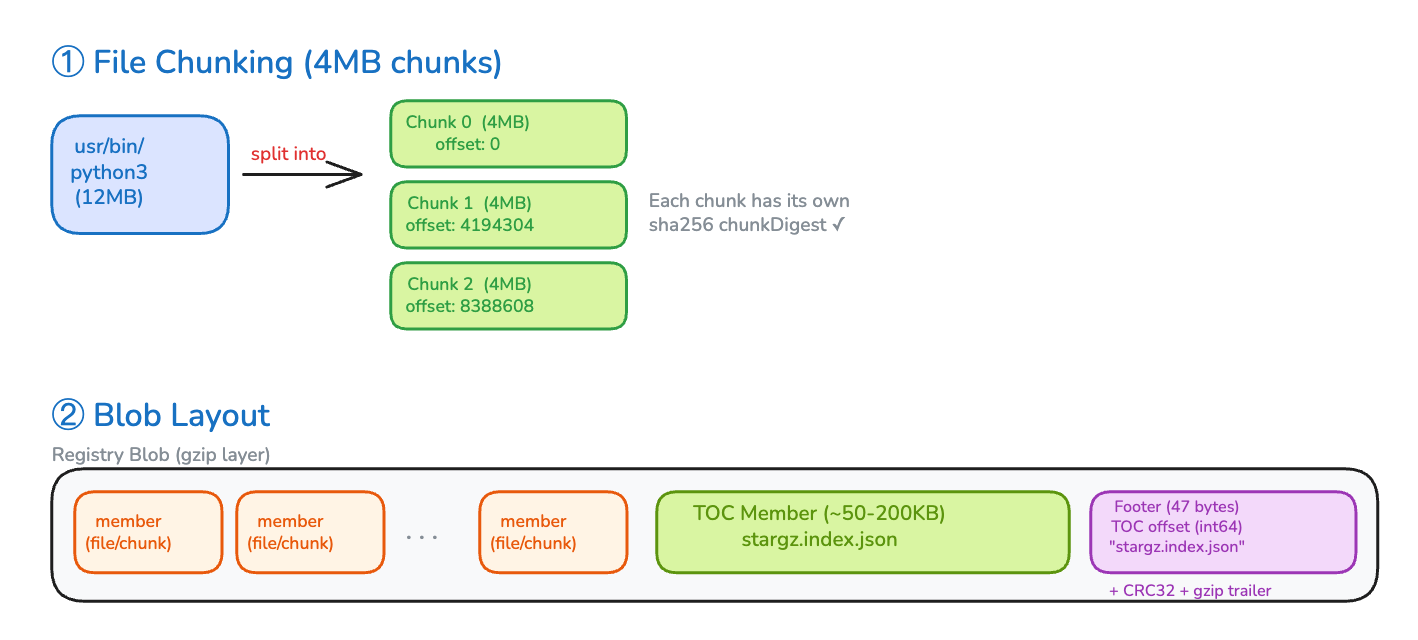
The TOC (Table of Contents) is a JSON document stored as the final gzip member. It maps every file to its compressed byte offset.
The DiffID preservation trick. eStargz changes compression boundaries but not content. When you concatenate and decompress all gzip members, you get a byte-identical tar stream to the original. The DiffID (the layer’s identity in the image config) is preserved. The blob digest changes (different compressed bytes), but the layer identity doesn’t.
The cost. every image must be converted at build time. The conversion recompresses the entire layer. Compression ratio may differ slightly (independent members can’t reference data in other members, losing some LZ77 efficiency). In practice, the overhead is ~2% larger blobs.
eStargz is the approach I use in the experiment later in this post, but it’s not the only one. Three other approaches are worth knowing about.
AWS SOCI takes a different angle entirely. Instead of recompressing the image, it creates an external index (the zTOC) that stores periodic snapshots of the zlib decompressor’s internal state. These checkpoints let you resume decompression from any 4MB boundary instead of from byte zero. The index is stored as a separate OCI artifact linked via the Referrers API, so the original image stays completely unmodified. The tradeoff is that reads may need to decompress up to 4MB of unwanted data to reach the target file, and the index must be explicitly copied alongside the image when promoting across registries.
Nydus replaces tar.gz entirely with RAFS (Registry Acceleration File System), a purpose-built format with separated metadata and content-addressable chunks. Its key differentiator is cross-layer chunk deduplication, which can reduce total download by 20-30% for ML images with overlapping runtime layers. Nydus also offers an EROFS kernel backend (Linux 5.19+) that eliminates FUSE from the data path, dropping per-operation latency from ~100-500μs to ~10-50μs. The cost is that images must be converted, and the pure Nydus format isn’t backward-compatible with standard runtimes (though a “zran” compatibility mode exists).
Azure Artifact Streaming and Google Image Streaming build the seekability index server-side, transparently, with no user-visible conversion step. Azure’s implementation is based on OverlayBD, which operates at the block device level via TCMU rather than using FUSE. Google generates an opaque index automatically on push and uses a custom containerd plugin backed by FUSE with aggressive multi-level caching. Both are closed implementations that require their specific managed Kubernetes service and container registry.
Every solution, open-source or proprietary, modifies the same component in containerd’s snapshotter.
containerd’s image pull pipeline has a clear separation of concerns.
Image Pull Pipeline:
1. Resolver → Converts image reference to manifest digest
2. Fetcher → Downloads blobs from registry → Content Store
3. Unpacker → Reads blobs from Content Store → Snapshotter
4. Snapshotter → Materializes layer diffs into mountable filesystem
5. Runtime → Mounts filesystem, creates containerSteps 1-3 operate on blobs as opaque bytes. The Snapshotter (step 4) is where bytes become files. This is the only point where lazy-pulling can be inserted. You intercept the moment containerd tries to materialize a complete filesystem from a layer blob and instead provide a virtual filesystem that fetches on demand.
The default overlayfs snapshotter’s Prepare() call is synchronous and complete:
// overlayfs snapshotter: Prepare returns after full extraction
func (o *snapshotter) Prepare(ctx context.Context, key, parent string, opts ...Opt) ([]mount.Mount, error) {
// ... (layer already fully extracted to disk)
return []mount.Mount{{
Type: "overlay",
Source: "overlay",
Options: []string{
fmt.Sprintf("lowerdir=%s", lowerDirs),
fmt.Sprintf("upperdir=%s", upperDir),
fmt.Sprintf("workdir=%s", workDir),
},
}}, nil
}A lazy-pulling snapshotter can return a FUSE mount instead:
// remote snapshotter: Prepare returns immediately, content fetched on demand
func (s *remoteSnapshotter) Prepare(ctx context.Context, key, parent string, opts ...Opt) ([]mount.Mount, error) {
// 1. Fetch TOC/index (small metadata, fast)
// 2. Start FUSE daemon for this layer
// 3. Return mount point where FUSE serves content on demand
return []mount.Mount{{
Type: "fuse.rawBridge",
Source: "stargz",
Options: []string{"ro", fmt.Sprintf("mountpoint=%s", mountDir)},
}}, nil
}From containerd’s perspective, both return []mount.Mount. The OCI runtime (runc) mounts them identically. The container process sees a normal filesystem either way. The difference is entirely in what backs those mounts.
For FUSE-based solutions (eStargz, SOCI, Nydus default, Google), you end up with this node topology:
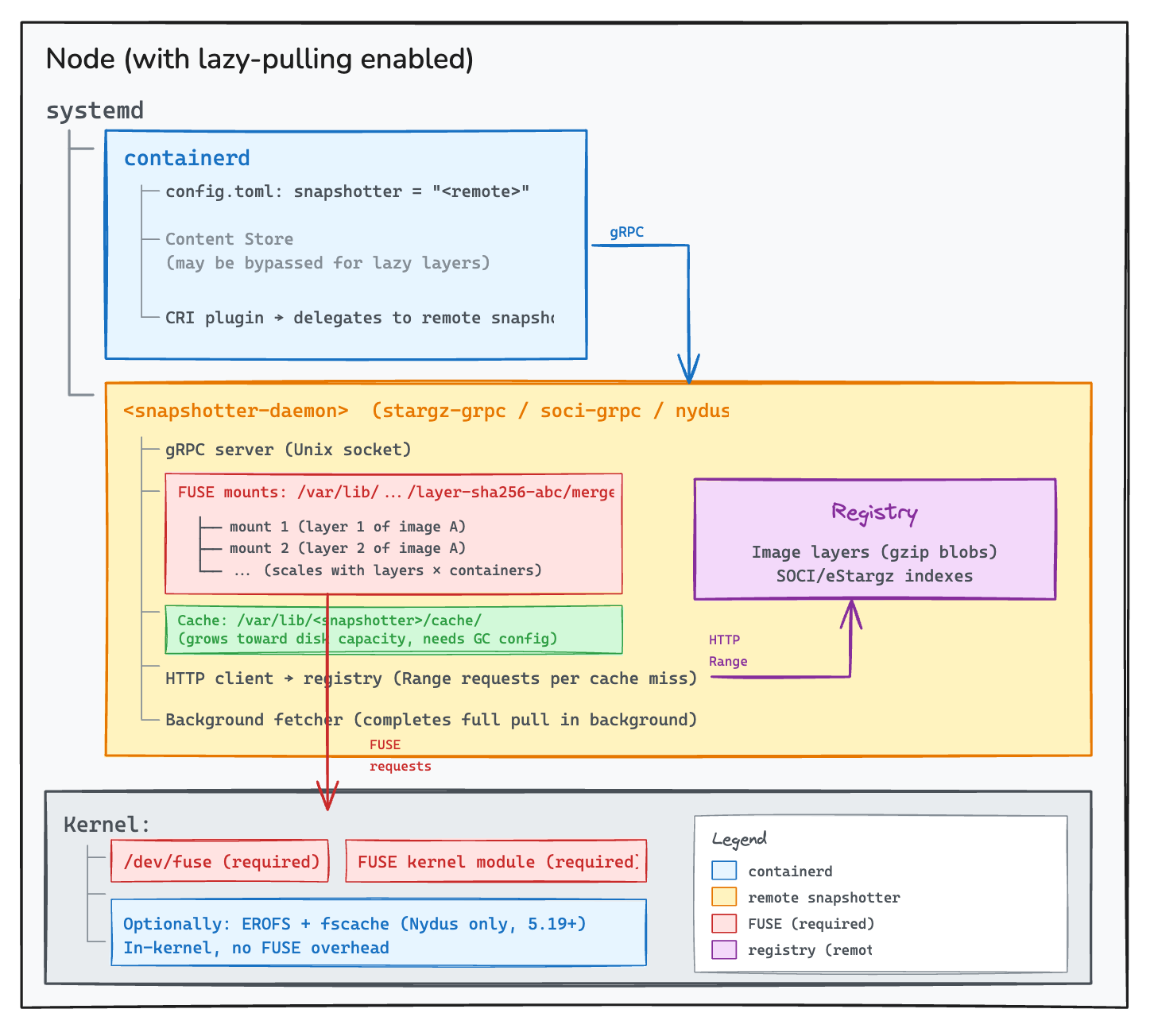
The config.toml change is simple. What it implies is not.
Process dependency ordering: The snapshotter daemon must be running before containerd starts accepting CRI calls. If the daemon crashes during node boot, containerd silently falls back to overlayfs. Your containers start, but slowly, and the only signal is startup latency, not an error.
FUSE mount lifecycle: Each lazy layer creates a FUSE mount. These mounts are tied to the snapshotter daemon’s process. If the daemon restarts, existing mounts become stale. Reads return ENOTCONN. Every container using those mounts breaks.
Cache management: Every solution caches fetched chunks locally. Without explicit GC configuration, the cache grows until the disk fills. On GPU nodes with expensive local NVMe, that’s capacity competing with model weights, checkpoints, and scratch space.
Most lazy-pulling benchmarks report a single number: image pull time. Pull goes from minutes to sub-second, the chart looks dramatic, and the blog post ends. But pull time is a misleading metric for lazy-pulling because the cost doesn’t disappear. It shifts.
With a traditional full pull, the container starts with every file already on disk. With lazy-pulling, the container starts with nothing on disk. The first time the process reads a file, whether loading a binary, opening a shared library, or importing a Python module, that read blocks on a FUSE cache miss, which triggers an HTTP Range request to the registry, which adds network latency to what should be a local filesystem operation.
The metric that actually matters is readiness: the moment the container can serve its first request. We define it as the time from container create to a successful HTTP response on the health endpoint. This captures the full cost: pull, start, and all the on-demand file fetching that happens before the process is functional.
Readiness reveals the tradeoff that pull-time-only benchmarks hide.
We built an in-cluster test harness to compare three configurations head-to-head, measuring readiness on each. The goal: isolate what lazy-pulling actually changes by controlling for network, registry, and image variables.
The experiment deploys three components into a Kubernetes cluster:
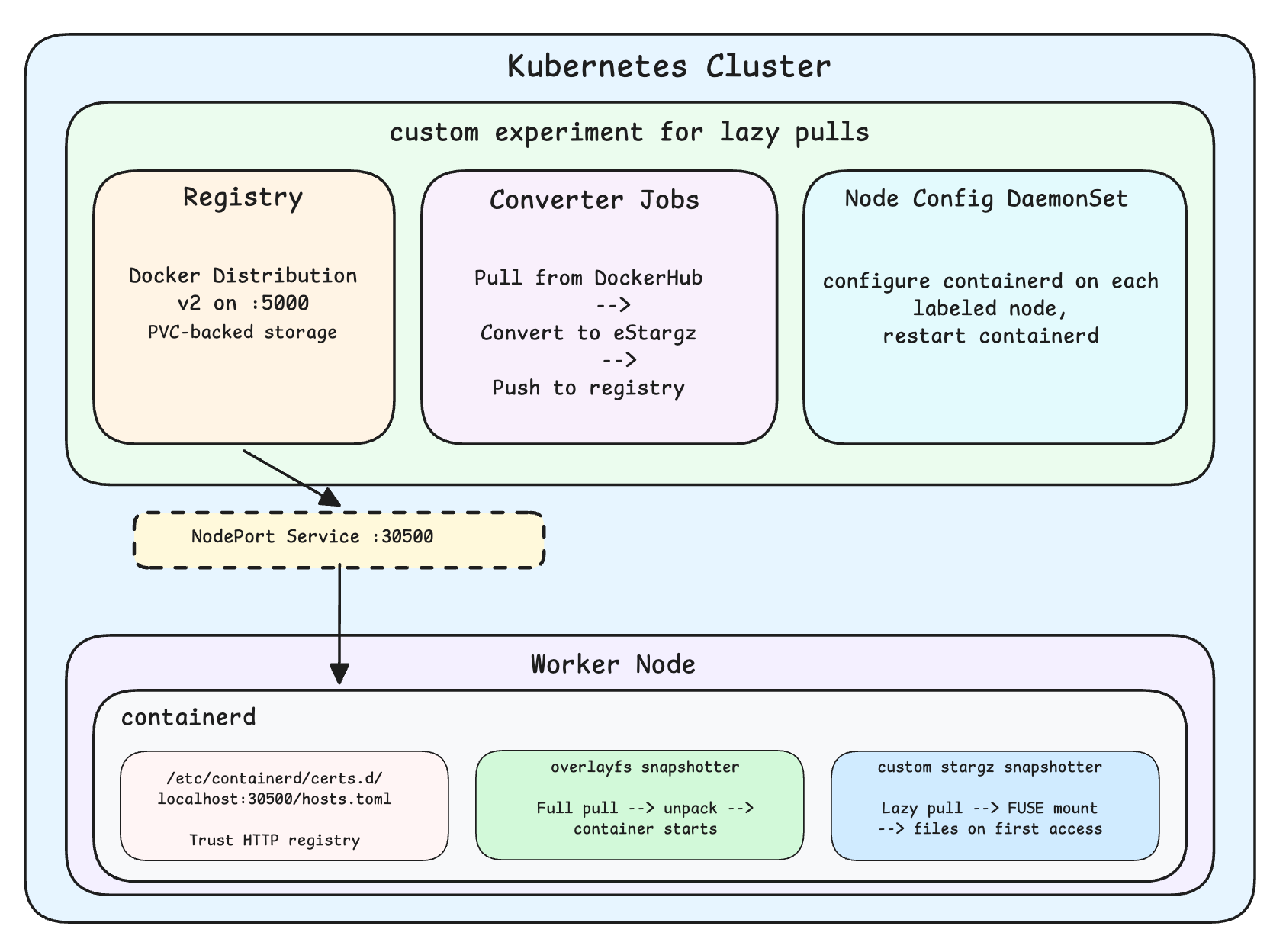
Local registry. A standard Docker Distribution v2 registry runs as a Deployment, backed by a PVC, exposed via NodePort on port 30500. Since kube-proxy binds NodePort on 0.0.0.0:<port> on every node, the registry is reachable at localhost:30500 from any node without DNS, ingress, or TLS. This eliminates internet variability from the measurement.
eStargz conversion. A Helm post-install Job converts each source image: pulls from DockerHub, rebuilds each layer with a TOC using the containerd/stargz-snapshotter/estargz Go library, and pushes the result to the local registry. The converted image is backward-compatible; any OCI runtime can pull and unpack it normally. The TOC is only used by snapshotters that understand it.
Node patching. A privileged DaemonSet writes the hosts.toml for the local registry and restarts containerd via nsenter into the host PID namespace. This makes containerd trust plain HTTP pulls from localhost:30500.
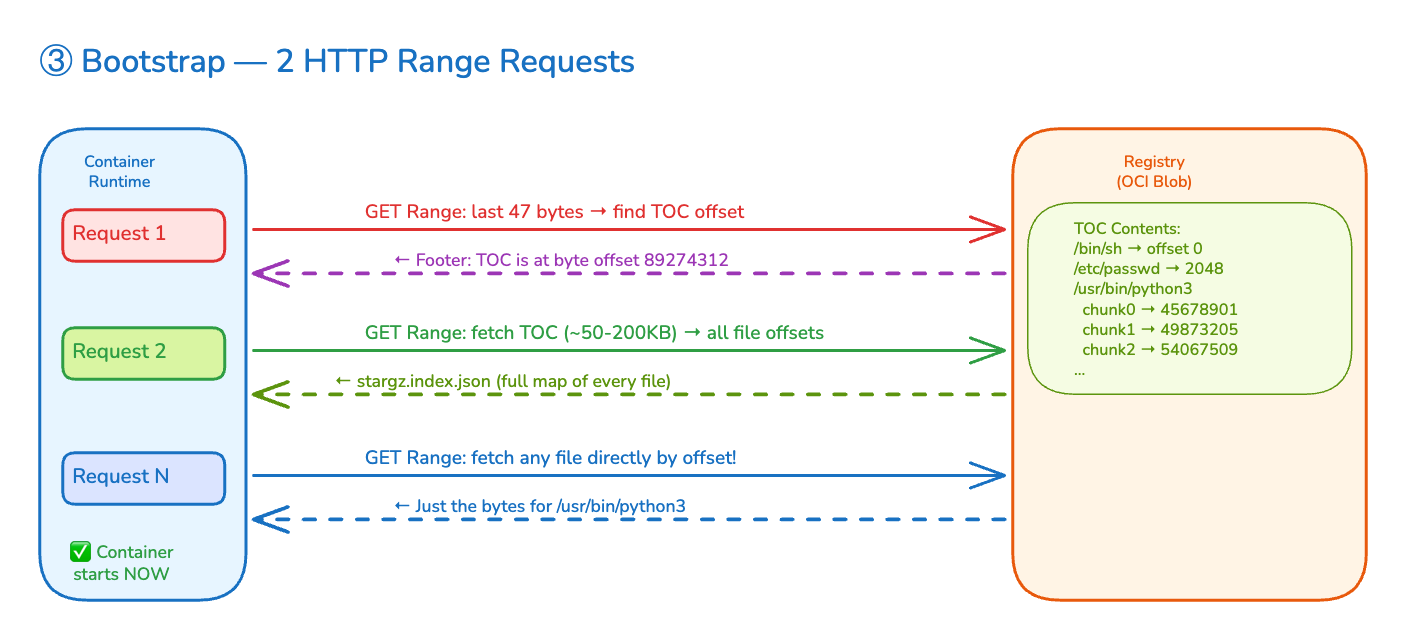
stargz-snapshotter. For the FUSE lazy-pull configuration, the custom stargz-snapshotter runs as a containerd proxy plugin on the worker node. On pull, it fetches only the TOC from each layer (milliseconds). It mounts a FUSE filesystem instead of extracting layers to disk. On file access, it fetches individual files from the registry via HTTP Range requests, decompresses the specific byte range, and returns them to the process.
We test three cold-start paths against the same image (nginx:1.25, ~70MB compressed), each starting with a clean image cache:
DockerHub full pull. Standard path: containerd pulls all layers from DockerHub over the internet, decompresses them, writes them to overlayfs. Container starts with all files on disk.
Local registry + overlayfs full pull. Same full-pull mechanics, but the registry is in-cluster. This isolates the network improvement: same decompression and extraction, no internet round-trip.
Local registry + FUSE lazy pull. eStargz image, stargz-snapshotter active. Pull fetches only the TOC. Container starts immediately. Files are fetched on-demand through FUSE as nginx loads its binary, shared libraries, and config.
Benchmarks run at the containerd level using ctr and ctr-remote, bypassing the Kubernetes CRI path. This eliminates kubelet scheduling, readiness probe interval, and CRI overhead from the measurement, giving us a clean view of the pull → start → ready pipeline.
For each configuration, we measure three phases:
Image Pull (time to complete the pull/lazy-pull operation)
Container Start (time from pull completion to process running)
HTTP Readiness (time from container start to a successful HTTP response on
/healthz).
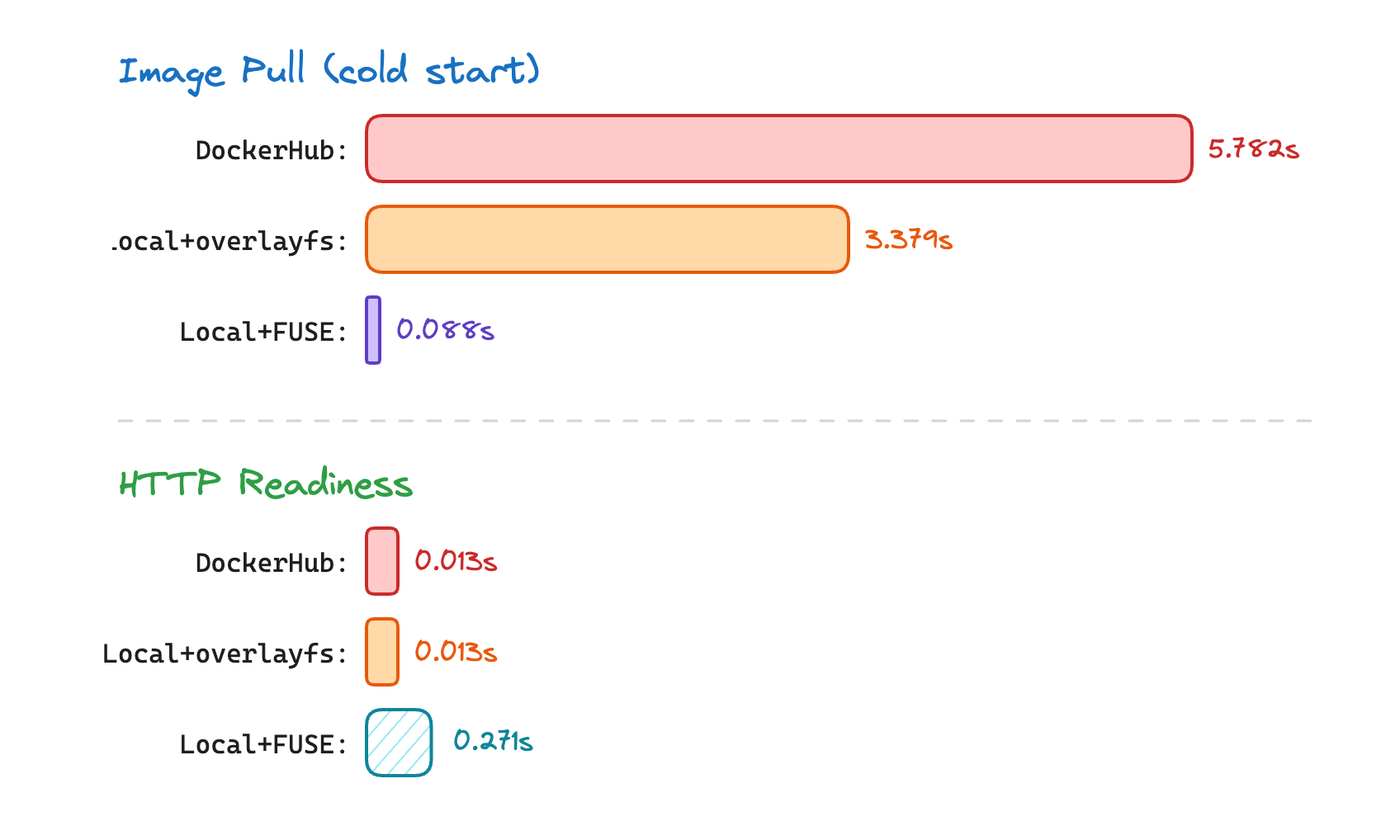
Pull is 65x faster with FUSE (0.088s vs 5.782s). Only the TOC and image manifest are downloaded, not the actual layer data. This is the number most benchmarks report and stop.
Readiness is 20x slower with FUSE (0.271s vs 0.013s). When nginx tries to serve /healthz, the FUSE filesystem must fetch the nginx binary, shared libraries (libc, libssl, libpcre), and config files from the registry over HTTP. Each file read becomes a network round-trip. With full-pull approaches, those files are already on disk and readiness is essentially instant.
The local registry alone gets you some of the improvement (5.981s → 3.577s total) with zero containerd configuration changes, no FUSE, no snapshotter swap. It’s the boring optimization that often gets skipped in the rush toward lazy-pulling.
Total readiness is still best with FUSE (0.589s vs 5.981s). For nginx, the pull savings vastly outweigh the readiness penalty. But the gap narrows as image complexity grows:
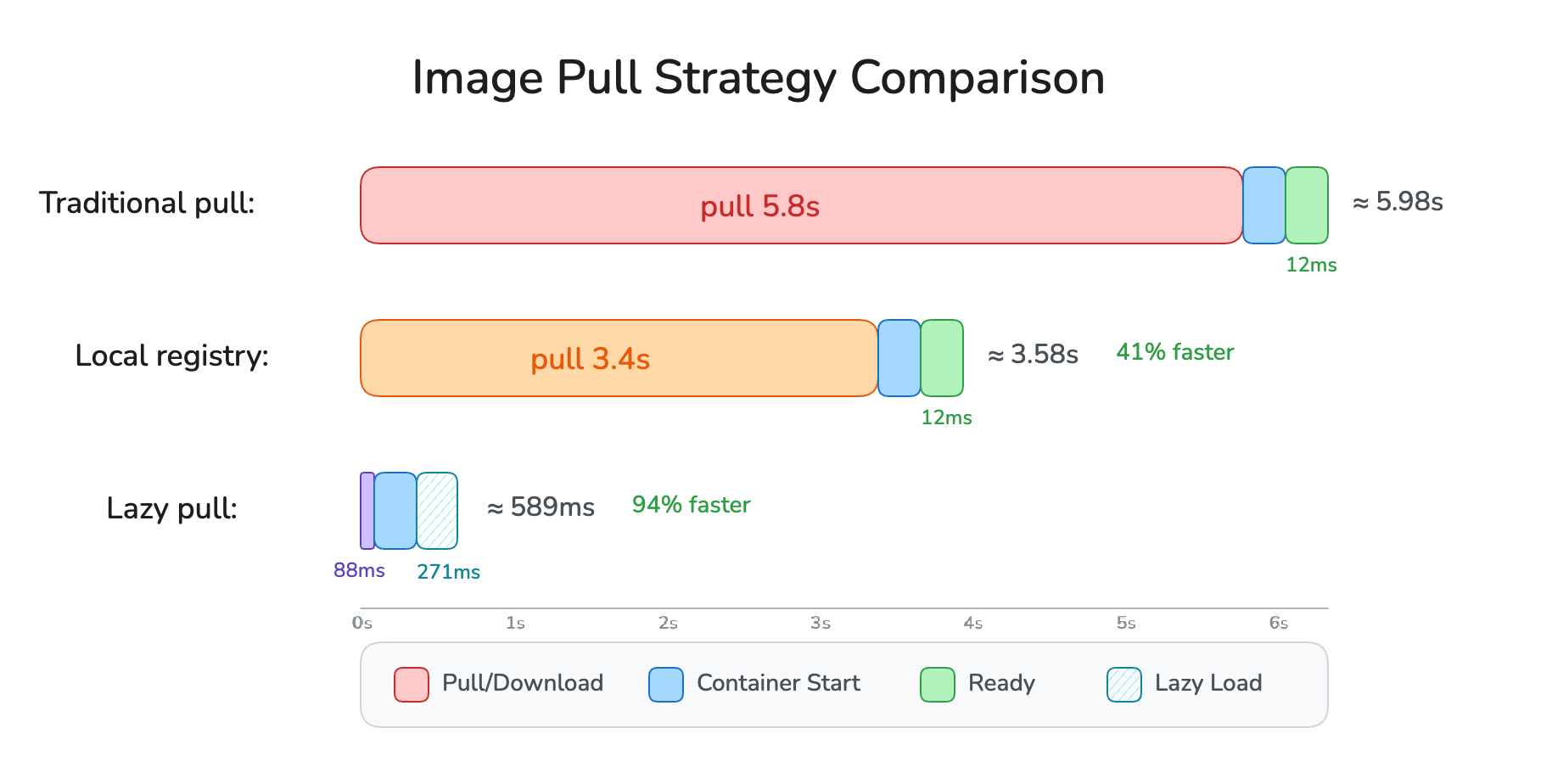
For a PyTorch image where the process imports hundreds of Python modules at startup, each triggering a FUSE cache miss and a network round-trip, the readiness phase grows proportionally. The pull savings are still enormous (minutes to sub-second), but the readiness penalty can reach seconds as the FUSE daemon serializes dozens of HTTP Range requests.
The stargz-snapshotter works as a containerd proxy plugin that speaks the snapshotter gRPC API. In containerd v1.x, this worked seamlessly through CRI. Containerd v2 (v2.2.0, used in my test cluster with K8s v1.35) introduced a new TransferService that handles image pulling and unpacking, and requires snapshotters to register unpack platform support. The stargz-snapshotter doesn’t implement this yet, so CRI-based pulls fail with “no unpack platforms defined.” The same limitation applies to SOCI.
To work around this, I implemented a custom snapshotter that implements containerd v2’s Transfer Service, registering the necessary unpack platform handlers so that lazy-pulling works through the standard CRI path. The benchmarks above use this custom snapshotter.
This is the single most important operational change that lazy-pulling introduces, and it’s consistently underemphasized in vendor documentation.
With traditional pulls, the registry interaction is bounded: download all blobs, verify digests, done. The container runs entirely from local disk. Registry outages don’t affect running workloads.
With lazy-pulling, every uncached file access is a live HTTP request to the registry:
Timeline of a lazy-pulled container:
t=0s Container starts (TOC fetched, FUSE mounted)
t=0.1s Python interpreter loaded (prefetched, cached)
t=0.5s torch imported (prefetched, cached)
t=2.0s Model loaded, serving requests
t=3600s User uploads file triggering rare code path
→ import obscure_module
→ FUSE: cache miss for /usr/lib/python3.11/obscure_module.py
→ HTTP Range request to registry
→ Registry is in maintenance window
→ read() returns EIO
→ Python: ModuleNotFoundError
→ 500 error to user
The container has been running for an hour.
The failure looks like a missing file, not a network issue.
kubectl describe pod shows nothing.
The pod is in Running state.Every solution mitigates this with background fetching, downloading the complete image content in the background after the container starts. The race condition is the window between container start and background fetch completion. For a 12GB image, that window can be anywhere from 2 to 8 minutes depending on registry bandwidth. Any uncached file access during that window hits the registry live.
The deeper issue: background fetching eliminates the lazy-pulling benefit over time. Once the full image is downloaded, you have exactly the same disk usage as a traditional pull. Lazy-pulling optimizes time to first request, not steady-state resource consumption. If your containers run for hours, you’re carrying the operational complexity of lazy-pulling for a one-time startup improvement.
Most open-source solutions and Google’s proprietary implementation use FUSE in the data path. Azure’s OverlayBD-based approach is a notable exception. Some characteristics of FUSE in production:
Per-operation latency includes scheduling. A FUSE read is: kernel sends request to FUSE device, userspace daemon wakes up and reads from /dev/fuse, daemon processes the request, daemon writes response back, kernel completes the syscall. The wake-up and write-back are context switches. On CPU-saturated GPU nodes, FUSE response latency becomes a function of CPU contention.
Mount count scales multiplicatively. A node running 20 containers, each with 5 image layers, creates up to 100 FUSE mounts. Each maintains kernel-side state. The aggregate matters on nodes already tracking thousands of cgroups, network interfaces, and device mappings.
Observability is split. strace shows slow read() syscalls. iostat shows nothing unusual (FUSE isn’t a block device). The actual bottleneck, a cache miss triggering an HTTP request inside the snapshotter daemon, is visible only through the daemon’s own metrics, which may or may not be exported in your monitoring stack.
Failure mode is unfamiliar. When a FUSE daemon crashes, existing mounts go stale. Reads return ENOTCONN, “Transport endpoint is not connected”, on what the application thinks is a local file. This error doesn’t appear in most applications’ retry logic because local filesystem reads are assumed to be reliable.
Nydus with the EROFS backend (Linux 5.19+) is the only solution that eliminates FUSE from the data path entirely. The cached read path goes through kernel VFS → EROFS driver → page cache, with zero extra context switches. The on-demand fetch path uses the fscache subsystem’s userspace daemon, but this runs asynchronously. EROFS can serve other cached reads while waiting for a fetch to complete.
The result is ~10x lower per-operation latency and no stale mount failure mode. The catch: you need a kernel with CONFIG_EROFS_FS_ONDEMAND enabled, and many minimal cloud-native node OSes still don’t enable this config flag by default.
Container image lazy-pulling is a solved problem at the format level. We have four proven approaches spanning backward-compatible (eStargz), non-invasive (SOCI), high-performance (Nydus/EROFS), and fully-managed (Google, Azure). The format diversity is healthy: different tradeoffs suit different environments.
What remains unsolved is the integration story. Every solution requires replacing the containerd snapshotter on every node, running a long-lived daemon with its own lifecycle and failure modes, FUSE or TCMU or a specific kernel configuration, persistent cache with GC policy, and monitoring for a new class of failures (registry-as-runtime-dependency, stale FUSE mounts, cache pressure).
The cloud provider’s answer is to absorb this complexity into managed services, which works but gates the benefit behind a specific registry and Kubernetes distribution. The open-source answer is to install and operate the snapshotter yourself, which works but adds operational surface that compounds with every containerd and kernel upgrade.
The piece that’s missing is an upstream-native lazy-pulling snapshotter in containerd. Not a proxy plugin over a Unix socket, but a built-in snapshotter that speaks the OCI distribution spec, understands SOCI-style external indexes (so images don’t need modification), and uses EROFS where available with FUSE as fallback. The OCI Referrers API provides the standard metadata attachment mechanism. EROFS is in mainline Linux. The stargz-snapshotter is already in the containerd GitHub organization. The building blocks exist. The assembly is the hard part.
In container infrastructure, the hardest problems aren’t the algorithms or the formats. They’re making the operational integration invisible enough that teams adopt it without needing a dedicated infrastructure engineer to babysit it. Our readiness experiment shows that even the simplest lazy-pulling setup (eStargz + stargz-snapshotter) delivers a 10x improvement in total cold-start time, but only if you understand that the cost shifts from pull to runtime, measure accordingly, and plan for the registry dependency.
Everything in this post addresses the container runtime side of cold-start, meaning the OS, libraries, interpreters, and application code baked into OCI layers. For GPU workloads, that’s often only half the story. Getting multi-gigabyte model weights to the right node at the right time is a different problem with different constraints, and outside the scope of this post.
We often talk about lazy-pulling as a “startup speed” hack, but that misses the bigger picture. This is about resilience and yield.
When a spot instance vanishes or a node kernel panics, a 5-minute pull time is a 5-minute outage. Lazy-pulling turns that catastrophe into a 10-second hiccup. That difference is the margin between a seamless failover and a user-visible incident.
Simultaneously, every minute an H100 sits idle waiting for tar extraction is capital burned. I’m curious—how are you modeling this trade-off? Is the operational tax of running FUSE daemons worth the reclaimed GPU time and the slash in MTTR? Or is the risk of a runtime registry dependency too high for your SLA? bill?