Introduction
Building, testing, and documenting REST APIs involves many complexities and coordination. Without a common reference point, code, documentation, and tests tend to drift apart over time. OpenAPI (formerly Swagger) offers a solution: a single, machine-readable contract that becomes the authoritative source for your API’s behavior.
When you treat an OpenAPI specification as your single source of truth, teams can streamline development, keep documentation current, and ensure QA tests align with what the API actually does. An OpenAPI spec isn’t just documentation gathering dust in your repo. It can drive your entire API lifecycle from initial design and implementation through testing, maintenance, and publishing.
Here’s what makes this approach work: when every team member and tool references the same OpenAPI definition, miscommunication drops significantly. Frontend developers, backend engineers, QA testers, and external API consumers all work from one agreed-upon contract. Your OpenAPI spec can generate interactive documentation, client SDKs, server stubs, and test cases. And they’ll all be consistent because they come from the same source. This means what’s described in the docs matches what’s implemented in code and what’s being validated in tests. The result is a workflow where fixes or changes need to be made in only one place (the spec) and automatically propagate everywhere else. The sections below dive into how OpenAPI makes this unification possible across design, documentation, testing, and code generation.
Design-First/Contract-First API Development and Alignment
One of the best ways to leverage OpenAPI as a single source of truth is through design-first (or contract-first) development. In this approach, you write the API’s specification before you write a single line of implementation code. This OpenAPI contract defines the endpoints, request/response schemas, and error codes upfront, becoming the blueprint everyone builds from.
I’ve worked with teams using this approach and seen great collaboration. The API spec becomes a discussion point that all stakeholders can review and agree on before coding begins. Tools like Swagger Editor or Stoplight Studio help here, letting you draft the OpenAPI definition in a user-friendly way and preview documentation as you design.
Whether you go design-first or code-first, the critical part is maintaining one definitive source for your API contract. Don’t duplicate API information in multiple places (like code annotations AND a separate YAML file). That’s a setup that leads to drift and bugs down the road. The OpenAPI Initiative recommends keeping a single source of truth to avoid scenarios where one version gets updated while another doesn’t. And I underline this also from experience. OpenAPI spec files must live in version control. Period.
If you generate an OpenAPI spec from code (a common code-first practice), avoid separately hand-editing a different copy. Some teams handle this by automating spec generation from code comments and adding CI verification that the code and spec stay consistent.
Design-first development with OpenAPI has a significant advantage: it enables parallel work with mock servers and stubs. Since the spec is your plan, you can generate skeleton server code or spin up a mock API directly from the OpenAPI definition before the real implementation exists. This means frontend developers and QA engineers can start working while the backend team builds the actual API.
Tools like Stoplight’s Prism, Wiremock or other mock server generators let teams simulate API endpoints from the spec and begin integration testing or UI development against that mock service. The backend team then implements the real API according to the same spec. Everyone stays on the same page because the OpenAPI spec is the contract that all implementations and tests must follow. The spec drives the development process, making sure the code that gets written actually adheres to what was agreed upon in design.
Consistent Documentation Generation
One of the most visible benefits of using OpenAPI as your source of truth is automatic, up-to-date documentation. An OpenAPI file can be fed into documentation tools to produce human-readable API docs that stay in sync with your code. No more maintaining separate wiki pages or PDF docs for your API reference. The spec becomes the reference. When the spec changes, for example, a new field added to a response or a new endpoint introduced, regenerating the docs will reflect it immediately.
Developers commonly use tools like Swagger UI, Redoc, Readme.io to transform an OpenAPI JSON/YAML into a polished documentation website. Swagger UI renders a web page where each API operation is documented and provides a “Try it out” feature for making test calls directly from the browser. Redoc and Readme.io generates an elegant, responsive API reference from the same spec, often embedded in developer portals. Since these docs are derived from the spec, they can’t go stale as long as the spec is maintained.
What’s even better is that OpenAPI schema includes rich details: endpoint descriptions, parameter explanations, request/response examples, etc., so the generated documentation is comprehensive by default. Many documentation generators will integrate examples and even code snippets into the docs. You can annotate your OpenAPI spec with example requests and responses, and tools like Redoc and Readme.io will display those examples to help users understand exactly what to expect. Some platforms even let you embed auto-generated SDK code samples for each endpoint based on the spec.
All of this translates to a better developer experience for API consumers. They get interactive, accurate docs, and your team doesn’t have to manually write and update documentation in multiple places. The OpenAPI spec change is the only change needed. Everything else flows from there.
This is a sample structure I use recurrently in all my projects that involve APIs. Example is in Java, but it can be extended to other languages in a similar way.
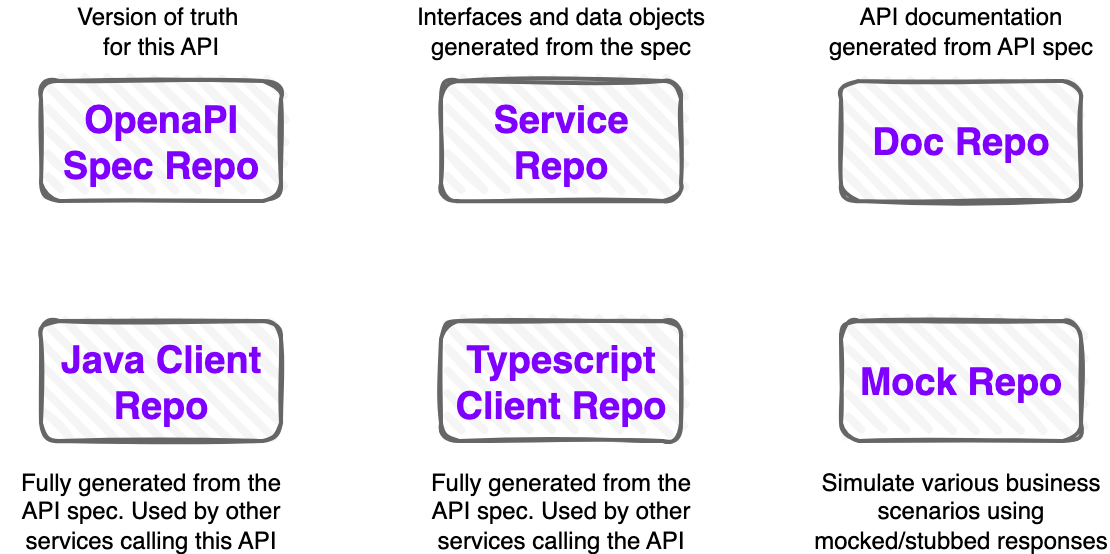
- OpenAPI Spec Repo: holds the OpenAPI spec file(s). It’s bundled in a JAR file and published to a Maven repository. Each version is published as a new release.
- Service Repo: holds the API implementation code. API interfaces and data objects are automatically generated from the spec file on each build.
- Doc Repo: holds the API documentation. It’s generated from the spec file on each build. A contract version update will trigger it.
- Java Client Repo: contains only a pom.xml file. It generates a Java client library from the spec file on each build. It’s published to a Maven repository. Each version is published as a new release. A contract version update will trigger it.
- Typescript Client Repo: contains only a script file. It generates a Typescript client library from the spec file on each build. It’s published to a NPM repository. Each version is published as a new release. A contract version update will trigger it.
- Mock Repo: contains a mock server for the API. It gets updated with each contract version.
This approach is quite granular, but you can equally use a single repo with all the above components as modules.
Automated Testing and QA Validation
Quality assurance can also revolve around the OpenAPI spec, which is where things get really interesting. Because the spec precisely defines what the API should do (the endpoints, expected inputs/outputs, and error conditions) it serves as a contract that tests can validate against. This practice goes by names like contract testing or * specification-based testing*. The concept is straightforward: if the implementation ever diverges from the contract (the spec), tests should catch it before anyone else notices.
There are tools that read your OpenAPI definition and automatically test your live API for conformance. For example, Stoplight Prism can take an OpenAPI spec and attempt every request defined, then check that the actual responses match the spec’s expectations (status codes, response schemas, etc.). Similarly, Postman can import an OpenAPI file to create a collection of requests. Testers can then write assertions for each request/response, or even generate some automatically. This ensures your test cases cover every endpoint defined in the contract, using the correct request structure defined by the spec.
Using OpenAPI makes it possible to validate API responses against predefined schemas with minimal effort. If the spec says a field should be an integer and your API starts returning a string, a contract test will flag that discrepancy immediately. No more “works on my machine” moments when the API quietly changes behavior.
Automated contract tests give teams real confidence that the API implementation and documentation are in lockstep. Contract tests essentially compare the expected response (based on the OpenAPI spec as the source of truth) to the actual API response, ensuring you’re building exactly what was planned and documented. This way, nobody has to wonder whether the documentation is accurate or if the code has mysterious, unapproved changes lurking around. The tests will enforce the alignment.
Another huge advantage is catching breaking changes early. Picture this: a developer updates the API code (maybe a field name changes or an endpoint gets removed) but forgets to update the OpenAPI spec. A good contract test suite (or even a simple spec-vs-implementation validator in CI) will fail when it detects that the code and spec are out of sync. This prompts the team to either update the spec or adjust the code before the change ever reaches production, avoiding those “oh no” moments that keep you up at night.
Many teams integrate these OpenAPI-based checks into their continuous integration pipeline, so every API build or deployment runs the spec validation. The moment something deviates from the single source of truth, the CI tests alert everyone. By treating the OpenAPI spec as the ground truth for testing, you maintain a tight feedback loop that keeps implementation and expectations aligned.
Beyond Conformance: Chaos and Edge-Case Testing
Most contract testing tools validate whether your API implementation strictly conforms to the OpenAPI spec. Tools like Prism check that responses match the expected schemas and status codes. Postman can import an OpenAPI file to generate collections for manual and automated tests, ensuring that the API behaves as documented.
But real-world clients don’t always send perfect requests. Unexpected payloads, invisible Unicode characters, extreme boundary values, or malformed JSON can still cause failures.
This is where chaos-driven testing tools add serious value. For example, Dochia is an open-source CLI that takes an OpenAPI spec and automatically generates negative and boundary test cases. Instead of stopping at conformance, it actively probes the API with unusual, edge-case inputs to reveal how resilient your service is under less-than-ideal conditions. While tools like Prism verify “does this API match the contract?”, Dochia asks “what happens when the client goes completely off the rails?”
Dochia isn’t alone in this space. Tools such as Schemathesis (property-based testing for OpenAPI) or fuzzing libraries for specific languages pursue a similar goal: uncovering issues that contract tests alone might miss. Together, these approaches create a more robust safety net: conformance testing ensures the API works as specified, and * chaos-driven testing ensures it also behaves predictably* when faced with the completely unpredictable.
Code Generation for Clients and Servers
Here’s where OpenAPI really shows its power as the single source of truth: automated code generation. The OpenAPI ecosystem includes generators that can produce server stubs, client libraries (SDKs), and other integration code directly from the spec. This means once you have a well-defined OpenAPI file, you can get a serious head-start on implementation and integration across multiple languages without writing those pieces by hand.
Swagger Codegen (and its more recent fork, OpenAPI Generator) can read your API spec and spit out boilerplate server code in frameworks like Node/Express, Java/Spring, Python/Flask, and dozens more, covering all the paths and operations in your spec. It can similarly generate client SDKs for tons of languages (JavaScript, Python, Java, C#, and many others) so that consumers of your API don’t have to manually write HTTP calls. They can just use the auto-generated library and get on with their lives.
All this generated code is consistent with the spec by definition. Which is kind of cool when you think about it. When using these tools, the OpenAPI document remains the source of truth for the API’s interface, and the generated code is a direct reflection of that source. If you later update the spec (say you add a new endpoint or change a data model), you simply re-run the generator to update the server stubs, tests, or client libraries accordingly, instead of hunting through code files trying to remember everywhere you need to make changes.
Because the spec drives generation, you avoid the absolute nightmare of “multiple sources of truth” in code. A developer doesn’t have to implement a change in the API and then separately remember to update an SDK and the docs - with an OpenAPI-centric workflow, one spec change can update them all through automation. This drastically reduces human error ( and the associated facepalming).
Here’s a concrete example: if you had to change a route URL or parameter name, you would normally need to change the server code, update any written documentation, adjust test cases, and update any client code that consumes the API. That’s at least four places where you could mess up. With OpenAPI, you change the spec (or code, then regenerate the spec), and then run code generation and doc generation tools. The updated server stub, new client library, and refreshed docs all come out consistent with that one change. No more bug hunting from a missed route change that seemed so simple at the time. And edge-case tests cases too. Dochia will automatically pick up the change, as tests are generated on the fly.
Generated code is often a starting point. Developers will fill in the business logic on a generated server stub, or perhaps tweak a generated SDK for better usability. But because those pieces are rooted in the spec, it’s easy to regenerate and update them when the API evolves. Some workflows even integrate code generation into CI pipelines: when the OpenAPI spec in the repository changes, a CI job can automatically re-generate the SDKs and even publish them, ensuring clients are always in sync with the latest API version.
In summary, code generation via OpenAPI not only speeds up development and integration, it ensures consistency. Client and server code speak the same language defined by the single source of truth.
Maintaining the Source of Truth in Practice
Using OpenAPI as a unifying artifact does require some discipline and process. But it’s the good kind of discipline that saves you headaches later. The OpenAPI spec should live alongside your code and be updated whenever the API changes. Treat the spec like code: use version control, code reviews, and tests for it. In fact, OpenAPI descriptions are first-class source files and should be among the first files committed, since they can drive many automated processes (code generation, testing, documentation rendering).
Many teams adopt a policy that any API change must include a corresponding OpenAPI update, and vice versa. It sounds strict, but it’s one of those rules that keeps everyone sane in the long run.
Continuous Integration can help enforce the single source of truth. For example, you can run validation tools in your CI pipeline to ensure the implemented API still conforms to the spec. If someone updates the spec file, CI can run a suite of contract tests or at least a linter/validator to ensure the spec is valid and perhaps even deploy a preview of the docs. If someone updates the API code without updating the spec (in a code-first scenario), a diff tool or test can catch the discrepancy before it becomes a problem. By automating these checks, you ensure the OpenAPI stays trustworthy. Remember, the spec can only be the source of truth as long as it actually contains truth, so make consistency checks part of your development workflow.
Finally, make the OpenAPI spec easily accessible to everyone who works with the API. Host the latest version in a
repository and/or an API developer portal, so there’s never confusion about where to find the authoritative API
contract.
Some teams even expose the spec via the API itself (at a URL like /openapi.json) for complete transparency. With
everyone referencing the same up-to-date spec, development and testing conversations become much clearer (“according to
the spec, this field is required; our tests and code should reflect that”).
Sample Pipelines
These are some pipelines that I’ve used in many projects:
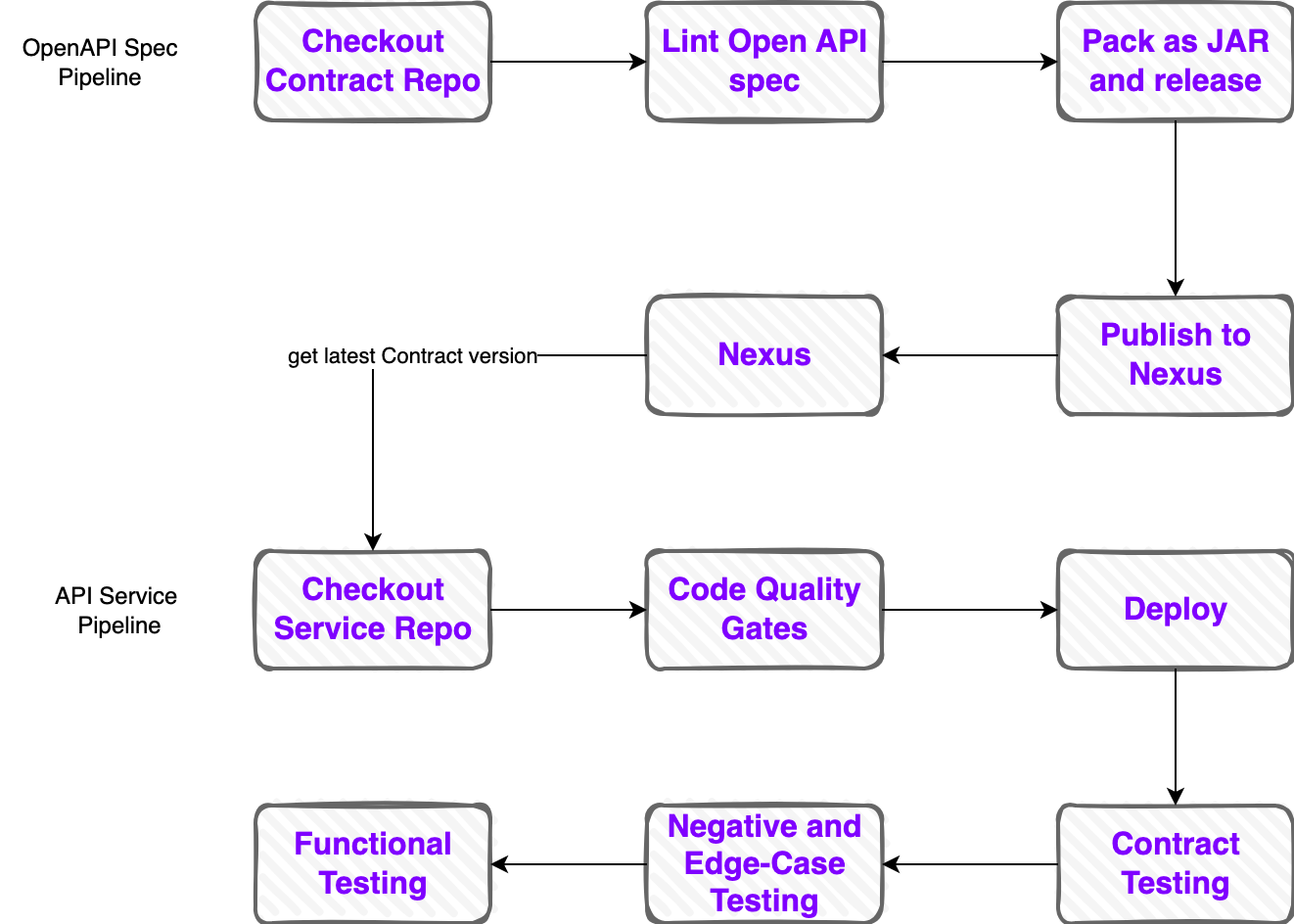
OpenAPI Spec Pipeline:
- Linting is the key stage here. It’s main purpose is make sure the API aligns with the agreed standards (naming conventions, response codes, etc.)
- Once linting is done, the contract can be released, version and publish the Nexus so that everyone can consume it
API Service Pipeline:
- Once a new contract version is published, the API service can pick it up and build the service
- Code Quality Gates run to make sure the code is of good quality
- After deployment, contract tests (e.g. Pact, Prism) run to make sure the API is still conforming to the contract
- Next is negative and edge-testing (e.g. Dochia) to make sure service does not break under unexpected conditions
- Next is functional testing (e.g. Rest Assured) to make sure the API is working as expected
Similar to the API Service Pipeline, once a contract version is published, the other pipelines will trigger automatically:
- Documentation Pipeline: publishes a new version of the Dev Portal
- Different Clients Pipeline: publishes a new version of the clients (e.g. Java, Python, etc.)
- Mock Server Pipeline: publishes a new version of the mock server
Conclusion
OpenAPI has evolved from a simple description format into the backbone of modern API development workflows. By using an OpenAPI specification as a single source of truth, organizations ensure that their code, tests, and documentation is always in sync. The spec-first approach promotes clarity in design, auto-generated docs improve developer experience, contract tests catch integration issues early, and code generators eliminate tedious boilerplate - all stemming from one source: the OpenAPI contract. The result isn’t just saved time, but higher quality and confidence in the APIs you deliver.
In our fast-moving development environment, this kind of alignment is valuable. Changes are less error-prone, onboarding new team members or partners is easier (they can read the spec and trust it), and **tooling support continues to improve **. This isn’t about any single vendor or product - it’s an open standard supported by a broad ecosystem of tools like Swagger Codegen, Redoc, Stoplight, Postman, and others. Each tool leverages the same OpenAPI spec to do its part, whether spinning up a test environment or rendering a documentation site. This neutrality and widespread support mean you can choose tools that fit your stack, confident that your OpenAPI spec will work with them.
Embracing OpenAPI as your single source of truth requires some upfront effort and a commitment to keep the spec updated. But the payoff is a unified development cycle where documentation, QA, and code all stay in sync by design. In the end, an accurate and well-maintained OpenAPI spec becomes the backbone of your API’s quality and clarity - a single truth everyone can rely on.