As part of the Brokk Power Ranking of coding models coming next week, we’re pleased to present the first independent numbers for GPT-OSS performance!
Update: the full Power Ranking results are available here: https://brokk.ai/power-rankings.
To put it in context, we’ve included the performance of the other recent open model releases, as well as o4-mini and Gemini Flash 2.0 as known-quantity comparisons.
Correction, 08/06/25. Initially we allowed OpenRouter to balance between all of its GPT-OSS providers, which included at least one with a misconfigured inference stack, causing GPT-OSS to perform dramatically worse than its real capabilities. The numbers shown below are the corrected results.
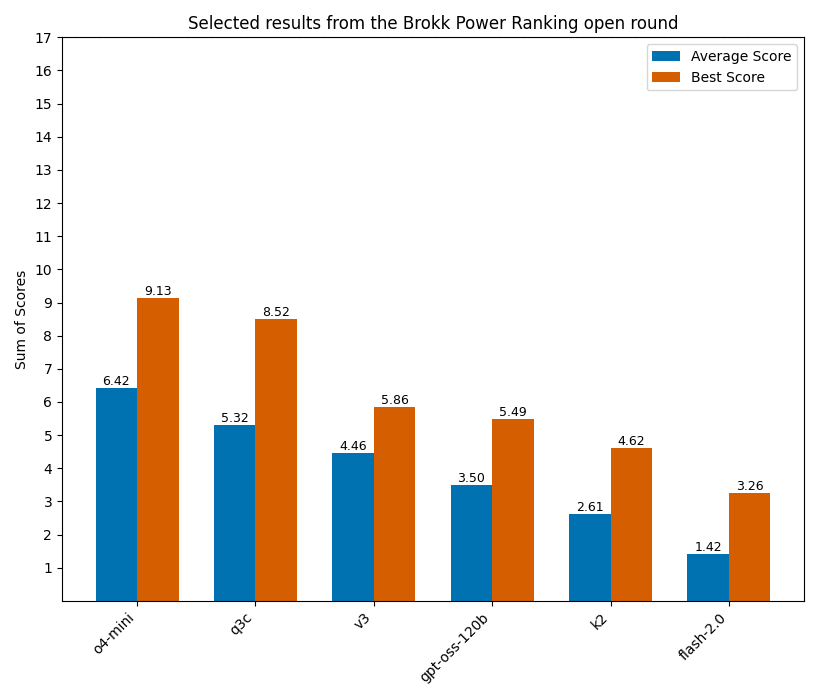
GPT-OSS slides in midway between DeepSeek-V3, a strong open coding model, and Kimi K2, another recent release. A decent result, if nowhere near the level of o4-mini that we might have hoped for from OpenAI's launch post.
But if we look at price/performance, GPT-OSS is quite impressive. It's 1/3 the price of the current cost king, DeepSeek-V3, and a significantly stronger coder than Gemini Flash 2.0, which is roughly the same price.
Turning to the other open models here, Kimi K2 is just bad. You may remember Kimi showcasing K2 handily beating DeepSeek-V3 at other coding benchmarks. When the discrepancy between the performance in and older benchmark and a new one is this large, it’s hard to avoid the conclusion that Kimi trained K2 against the test.
By contrast, Qwen 3 Coder (480B, unquantized) is the real deal and finally dethrones DeepSeek-V3 as the best non-thinking model for coding. Nobody has yet figured out how to serve Qwen 3 Coder inference at the same level of cost-effectiveness as DeepSeek-V3, but stay tuned for the full Brokk Power Ranking, where we'll look at (among many others!) Q3C quantized to fp8, which is available for about the same price as V3.
Where do these numbers come from?
The Brokk Power Ranking is a new coding benchmark focused on Java. Our goal is to measure how effective each model is at generating code in a large, real-world codebase, given the correct context by a human supervisor. Each model attempts each task 3 times; hence the difference between average performance and best.
BrokkPR tasks are generated from code that was written in the past six months in the following projects:
- Brokk itself
- Apache Cassandra
- Apache Lucene
- Langchain4j
- JGit
To get the full Brokk Power Ranking results on release, sign up below!
Get the Latest from Brokk
Subscribe to receive tips, tutorials, and updates from the Brokk team.
No spam. Unsubscribe anytime.