Quesma, a Third-Party Auditor, Validates Blitzy's Best-in-Class SWE-Bench Pro Public Score
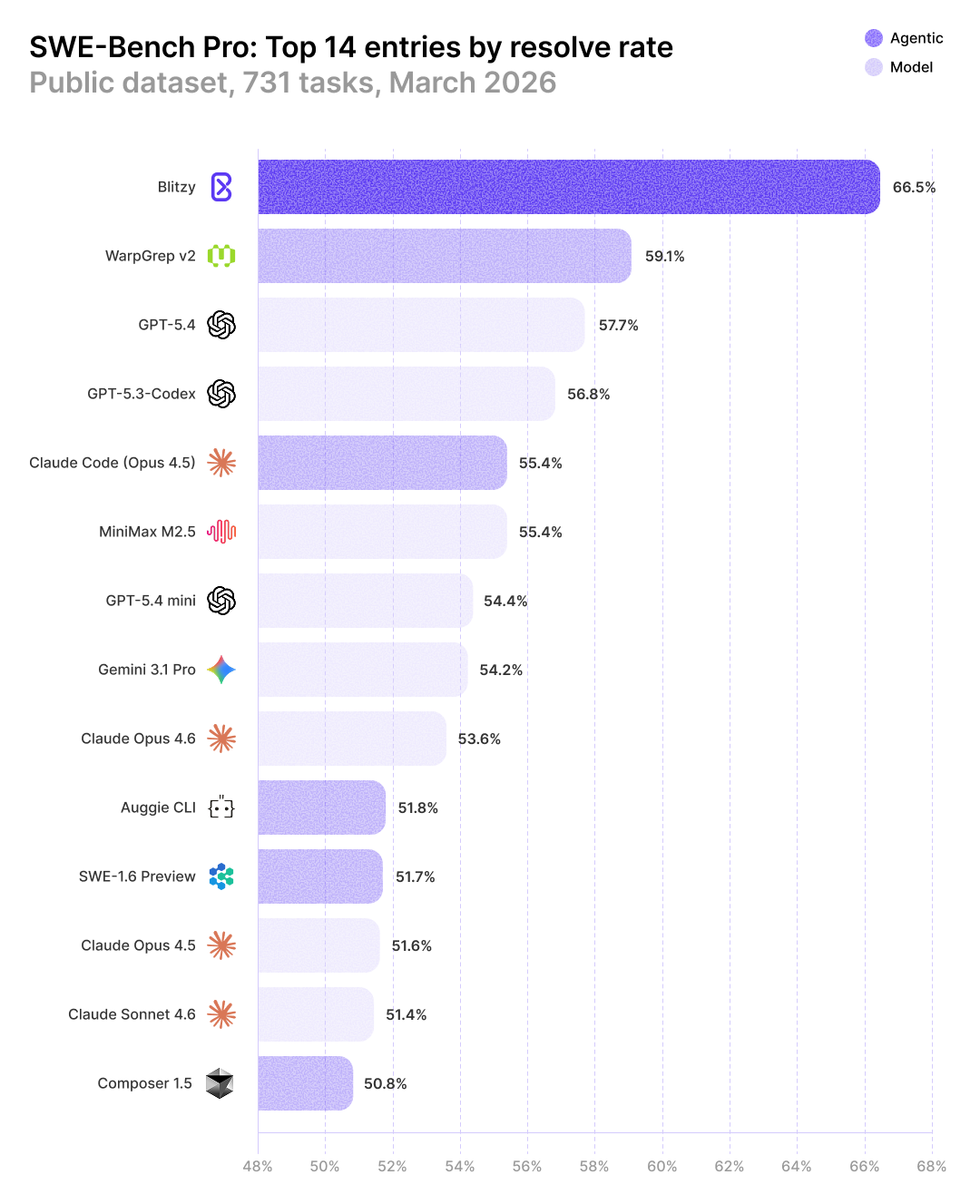
Blitzy is now the top performer on SWE-Bench Pro Public, achieving a record score of 66.5%. To put this milestone into perspective, the next highest-scoring agent framework is WarpGrep at 59.1%. Blitzy also significantly outperforms the industry's most advanced frontier models: OpenAI's state-of-the-art GPT 5.4 scored 57.7% in early March 2026, followed by the runner-up, Claude Code (Opus 4.5), at 55.4%.
We asked Quesma, an independent AI research team behind CompileBench, BinaryAudit, and OTelBench, to audit our results. We provided access to our agent trajectories, our methodology, and our research team to ensure the process and results were accurate.
Key Audit Findings
- Quesma independently tested and verified that Blitzy scored 66.5% on SWE-Bench Pro Public.
- Quesma selected and comprehensively evaluated trajectories for 20 tasks (AI agent interactions planning and creating the solution). Of these, half were not solved by GPT 5.4.
- Quesma verified and confirmed that the trajectories and the evaluation procedure follow best benchmarking practices and offer a fair comparison against other models and agents.
Why This is Important
As of March 2026, there are two major AI software development benchmarks: SWE-Bench Pro and Terminal Bench 2.0. SWE-Bench Pro measures an AI system's ability to solve real-world GitHub issues across complex codebases and is the gold standard for measuring AI software engineering capability. That is precisely the capability we wanted to measure.
On February 23, 2026, OpenAI's Frontier Evals team endorsed SWE-Bench Pro as the replacement for the previous industry consensus benchmark, SWE-bench Verified. SWE-Bench Pro is harder, spans multiple languages and real-world repositories, and is purpose-built to resist the contamination issues that led to the deprecation of Verified.
Verified had previously served as the primary metric for AI coding capability, but frontier models were posting up to 76.8%, with other agents up to 79.2% (Blitzy scored 86.8%). At that level, the benchmark no longer shows the edge of the frontier.
What is Blitzy
Blitzy is an autonomous enterprise software development platform purpose-built for large, legacy codebases. Unlike IDE or terminal-based tools that work file-by-file, Blitzy starts by ingesting the entire codebase and constructing a dynamic knowledge graph of the system: every dependency, every pattern, every architectural decision mapped and queryable. Blitzy's "infinite code context" allows our system to understand codebases in excess of 100M lines of code.
From there, our platform takes a technical specification and orchestrates thousands of dynamically created agents combining all the foundation models, fused with the knowledge graph. Every agent writes code with a comprehensive understanding of the system it's working within.
The result is spec-and-test-driven development at the speed of compute. Our platform is designed to stand up to the rigor of large, complex enterprise codebases and autonomously execute large amounts of work.
Audit Methodology and Validation
Blitzy solved 486 out of 731 SWE-Bench Pro Public tasks (66.5%). Quesma's first step was to independently verify the score. They evaluated the patches themselves and verified them as correct solutions.
They then performed a targeted audit of 20 tasks, selecting the most difficult ones, to determine whether there were any potential data leaks or signs of reward hacking.
Blitzy and Quesma worked closely to ensure the results provided were above board. Blitzy provided artifacts used or generated by the agent (such as summaries generated by Blitzy) and trajectories (sequences of interactions between AI model, codebase, and available tools) both for planning and edit steps.
One of the biggest sources of problems when running benchmarks is internet access. It introduces a risk that agents find existing solutions to the provided tasks, discover tests used for evaluation, or obtain other hints that would give an unfair advantage. Quesma vigilantly analyzed Blitzy's traces and found no such behavior. In particular, Quesma verified that:
- While there was internet access, it was solely used for installing packages.
- There were no web searches of any kind throughout the process.
- No signs of mysteriously "knowing" a solution. There were no signs of any context of issue numbers, PR descriptions, validation tests, or solutions from the golden patch.
In 1 case out of 20, there was a commit containing the solution that was visible in the log. However, Quesma verified this appeared after the agent had already committed its own solution, and the agent's patch did not reference it. Consequently, the score was not affected.
At the end of the audit, Quesma's lead researcher Piotr Migdal concluded that "no sign of reward hacking was observed in any of these traces."
Why Blitzy Succeeded Where GPT 5.4 Failed
To calibrate what "hard" means, Quesma ran OpenAI's GPT 5.4, the state-of-the-art base model, on the same 20 tasks at maximum reasoning effort (xhigh).
Quesma expected spectacular failures: the model chasing red herrings, misunderstanding the codebase architecture, or hallucinating APIs. What they found was more subtle and more interesting.
Every incorrect GPT 5.4 solution was close. The model identified the right area of the codebase, understood the general idea of a fix, and produced patches that were structurally reasonable. Where GPT 5.4 failed was on intricate details or corner cases.
GPT 5.4 works from a single pass through the code. Blitzy, by contrast, had already spent hours building the knowledge graph before it set off to solve the task. When Blitzy encountered the same boundary condition or module interaction, it had the context to get the details right and write a correct solution.
Conclusion
Foundation models are improving rapidly. Advancements at the harness layer can unlock larger performance gains.
The race for individual-developer AI tools is well underway. The race for enterprise, where codebases are large, requirements are precise, and "move fast and break things" is not an option, is just heating up.
Our SWE-Bench Pro score is a strong signal, but it is only one data point. What it validates is the thesis we have been building around since day one: that serious software engineering demands deep codebase understanding and a multi-model, dynamic agent architecture. That is what we have built, and that is what we will continue to prove.
We proactively commissioned Quesma to audit our submission. They verified the score, analyzed our hardest solves, and found the results to be fair. Blitzy will continue to submit to independent audits as we take on new benchmarks. Our platform exists to accelerate enterprise software development, but benchmark performance serves an important purpose: it gives our customers measurable proof that our engineering team is pushing the frontier, and it builds the trust required to deliver on the promise of fully autonomous software development.