Imagine setting out to build something great; putting your blood, sweat and (computational) tears into building an image autoencoder, from scratch. Spending hours and hours tuning hyperparameters until everything fits in perfectly and the loss just keeps going down and down and down.
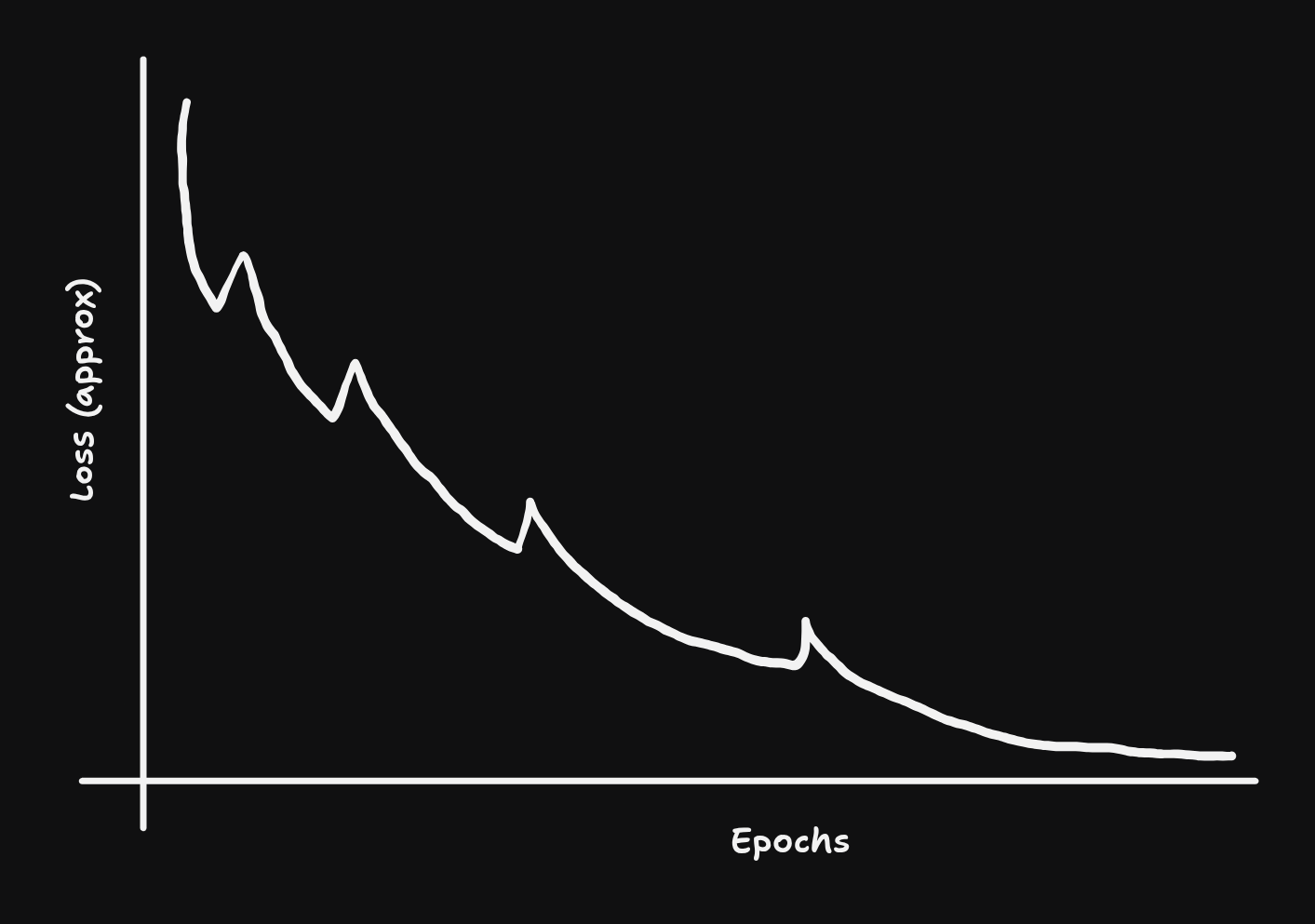
And after 12+ hours or arduous training, you realize you built a model that just replaces dog features with cat features.
The results are at the bottom of the page. Feel free to skip to them, the rest of the article is more of a story of how I got here.
Only slight dog features eg. the nose were converted into more cat-like features.

The reason for this is most likely because the model was trained solely on cat images; while it did learn some general image compression, it also got good at compressing feline-specific features such as the nose, ears, etc. These two compressions (general purpose and feline-specific) compete and caused this dog’s nose to turn out a little different in the reconstruction.
Here’s a short story about how I ended up needing ~30,000GB VRAM for a hobby project. Not kidding.
It was a different time back then: ChatGPT wasn’t half as popular as it is now, and most companies hadn’t even heard of the acronym “AI”, much less worried that it might destroy their business model.
I remember thinking: there’s no way a computer program could talk in natural language more than predefined conversation paths. No way this “AI” could ever understand or make decisions or even just execute npm run dev on it’s own.
Right?
Then I saw this Veritasium video. And I built one of those rectangle-or-circle classifiers.
And it blew my mind.
Fast forward a couple of months. I learnt about backpropagation and convolution and attention. I read about diffusion models for image generation. Looked up a guide. Copy-pasted the code. Got a dataset of Forza Horizon 5 images. Hooked everything up. Whoops! Got an error. What is it? Let’s have a look…
RuntimeError: CUDA out of memory. Tried to allocate 29.06 TiB (...)
I don’t know about you, but I usually don’t have 30TB of VRAM lying around on my desk.
Naturally, I Googled the error. I did the usual torch.cuda.empty_cache() and that obviously didn’t work. After hours of finagling, I finally realized my mistake.
I needed an autoencoder.
If you don’t already know, diffusion models are really resource-intensive for large images. Virtually all diffusion models available today, including Stable Diffusion and FLUX, are trained on a compressed latent space instead of normal pixel space.

This latent space is constructed by training a specialized model called an autoencoder. You train a network to reconstruct an image, and over thousands of images, it learns to compress information into a smaller latent space. Instead of encoding specifics of the pixels, the latent space encodes general information and structure (or at least, that’s the goal). The Stable Diffusion autoencoder acheives 48x compression — that’s a 48x decrease in resources required to train the diffusion model!
I got right to work on that: building my own autoencoder. This went on and off over the last couple of years: I’d learn something new, try to implement it, fail horribly and then give up. I’d usually end up with a horrible mangled mess.

Then, a couple of weeks ago, I tried to actually understand what was going on instead of just copy-pasting: what all the loss functions did, what worked with what, what had to be thrown out the window. And a little more than 12 hours of training gave me (drumroll please)…

The autoencoder was trained solely on cat images from this Kaggle dataset.
Naturally, my first question was: how would it perform on images different from what it had seen during training?
While I do intend to share some secrets regarding autoencoder training shortly (subscribe to know when that comes out), here are some results for now. Originals on the left, reconstructions on the right.










A couple of these images were from Unsplash, others from various sources:
{kind=link}
{kind=link}