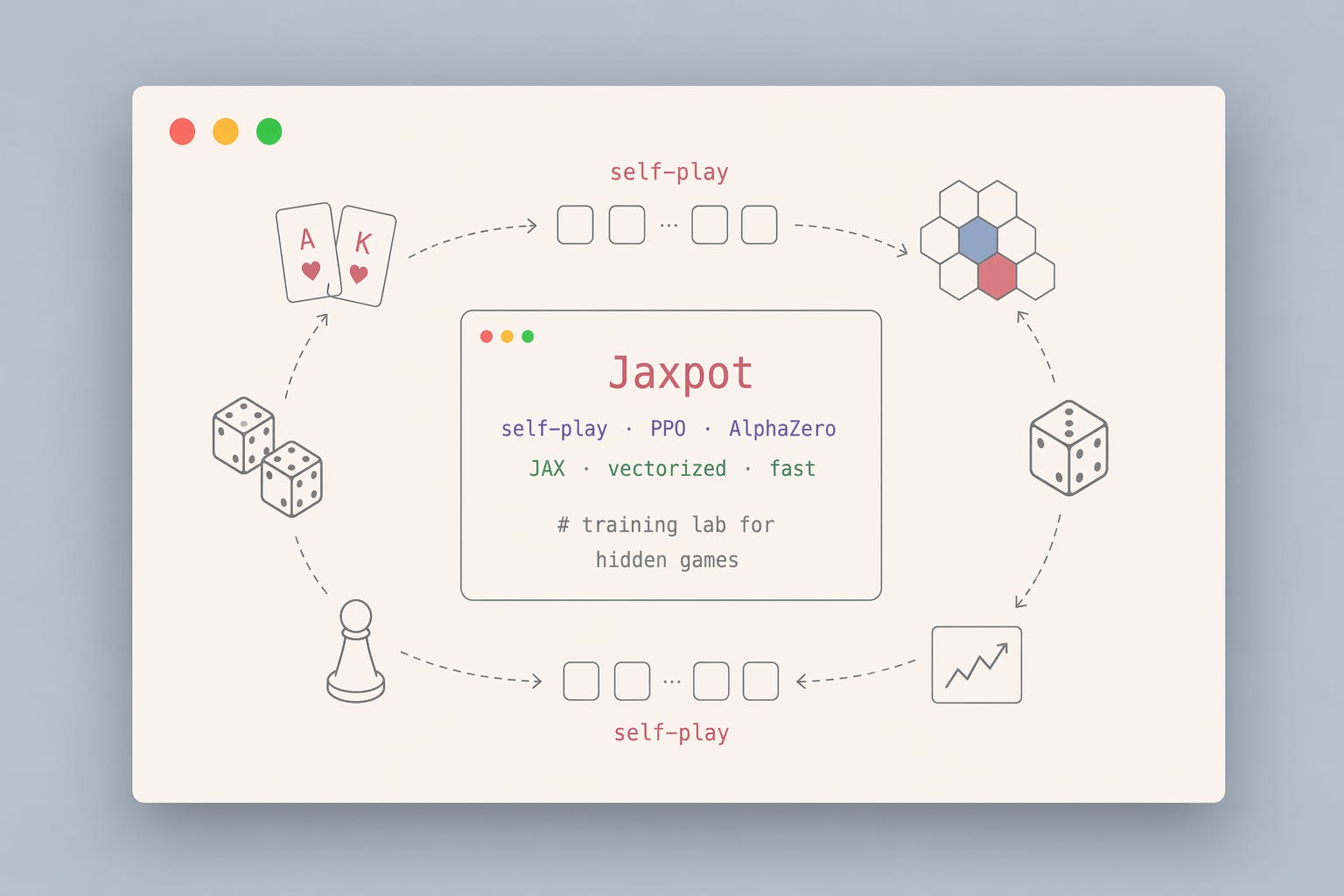
We got hired to build a poker bot.
We quickly realized we needed to run a ridiculous number of games. Around 1M+… so speeding up the process was worth it. That’s why we choose Jax.
For the training pipeline we needed self-play (PPO and AlphaZero style), league training, imperfect-information environments, and the ability to iterate fast without rewriting the training loop.
So we built all of that. Now we’re opensourcing it as Jaxpot.
In this post you will learn how to efficiently train agents on GPU like this:
here’s the replay of selfplay between 1900 and 1800 iteration of the Dark Hex agent trained with Jaxpot.
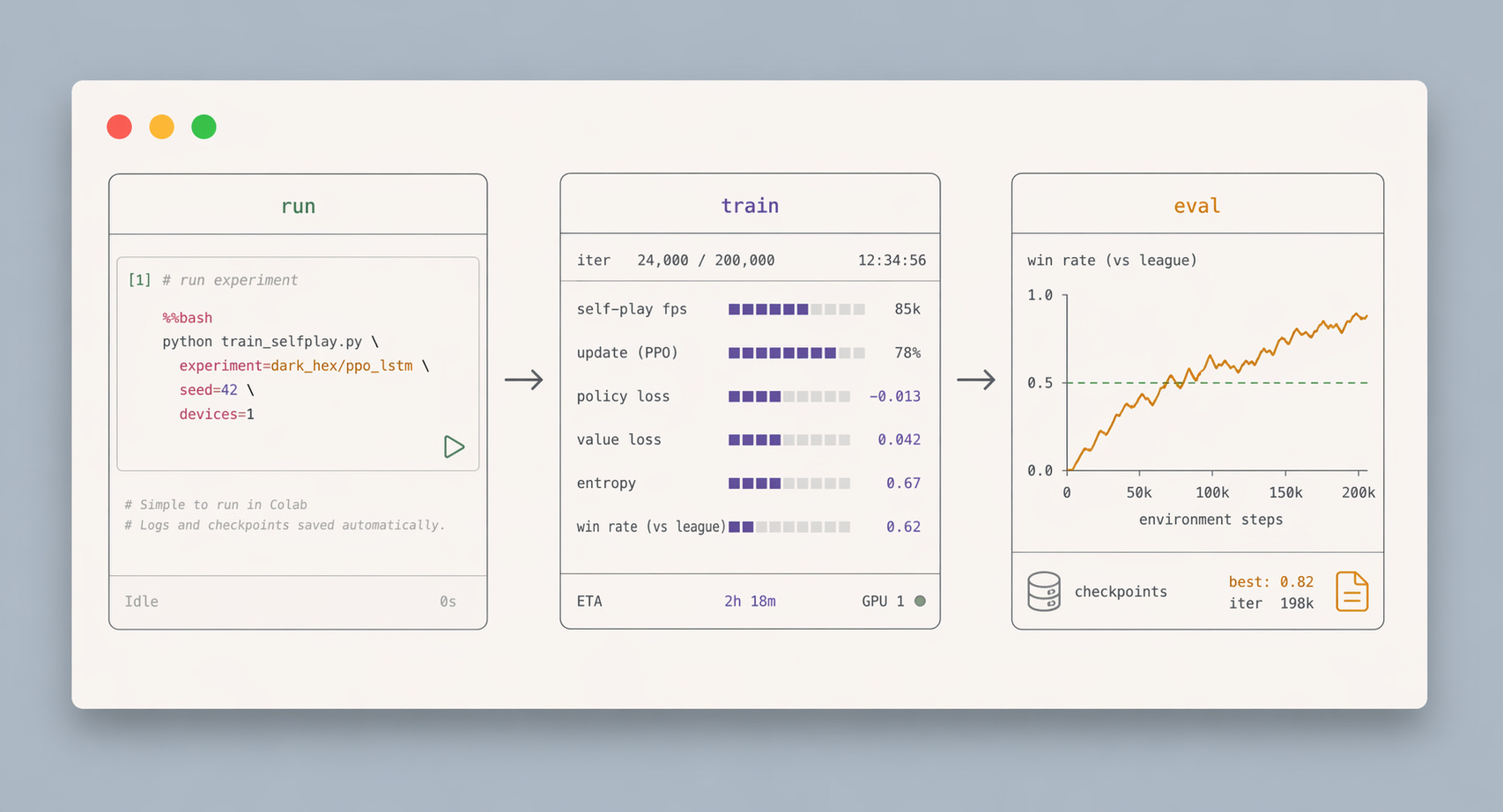
We’ll start with simple self-play agent. It takes about 90 seconds on a free Colab GPU. After that, you’ll switch config and train on Dark Hex, a simple imperfect-information game.
Here’s the notebook. Run the training pipeline and come back to read the rest!
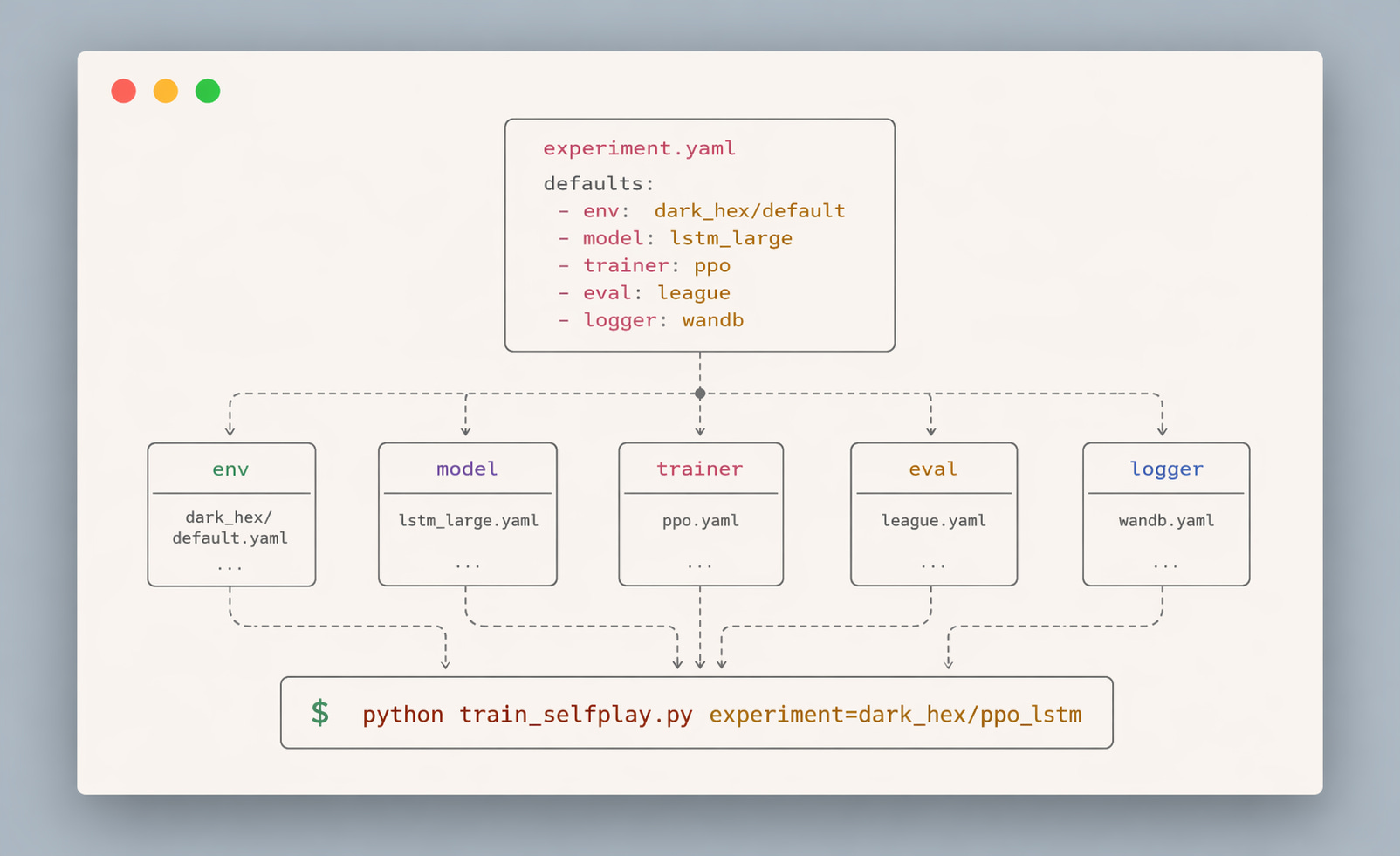
Below you can see four Hydra config files - this is the recipe for our experiment
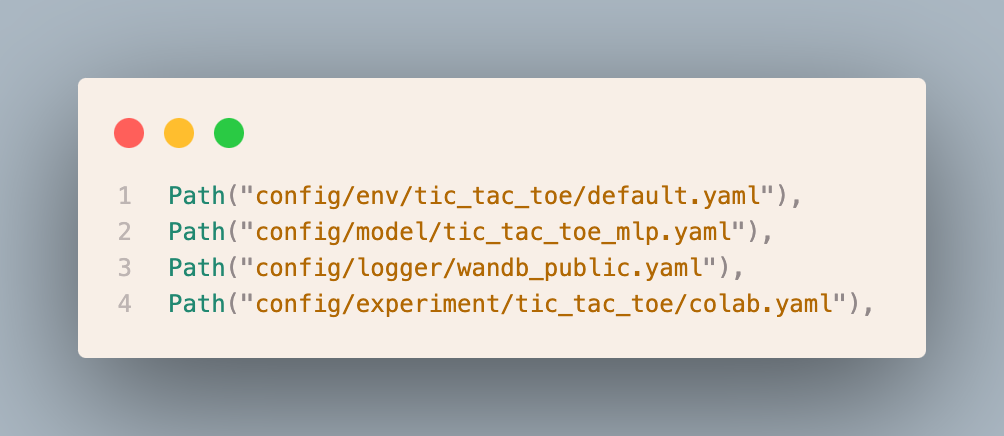
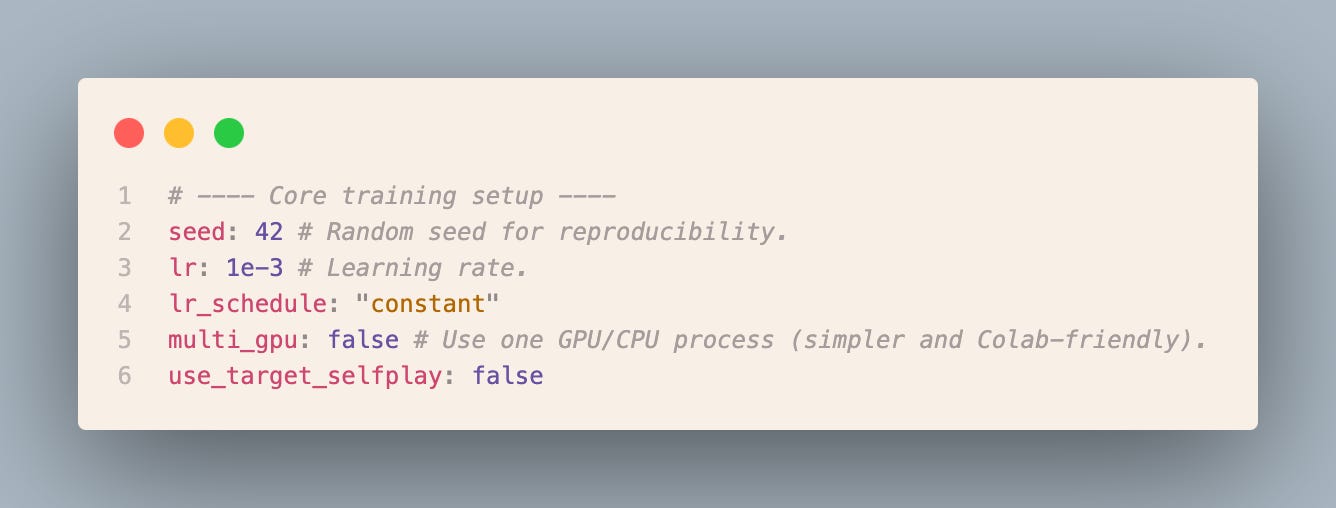
Let’s first open the model definition from config/model/tic_tac_toe_mlp.yaml
because it’s a simple MLP (Multi Layer Perceptron) definition is very short! It’s just 2 hidden layers of the shape 64.

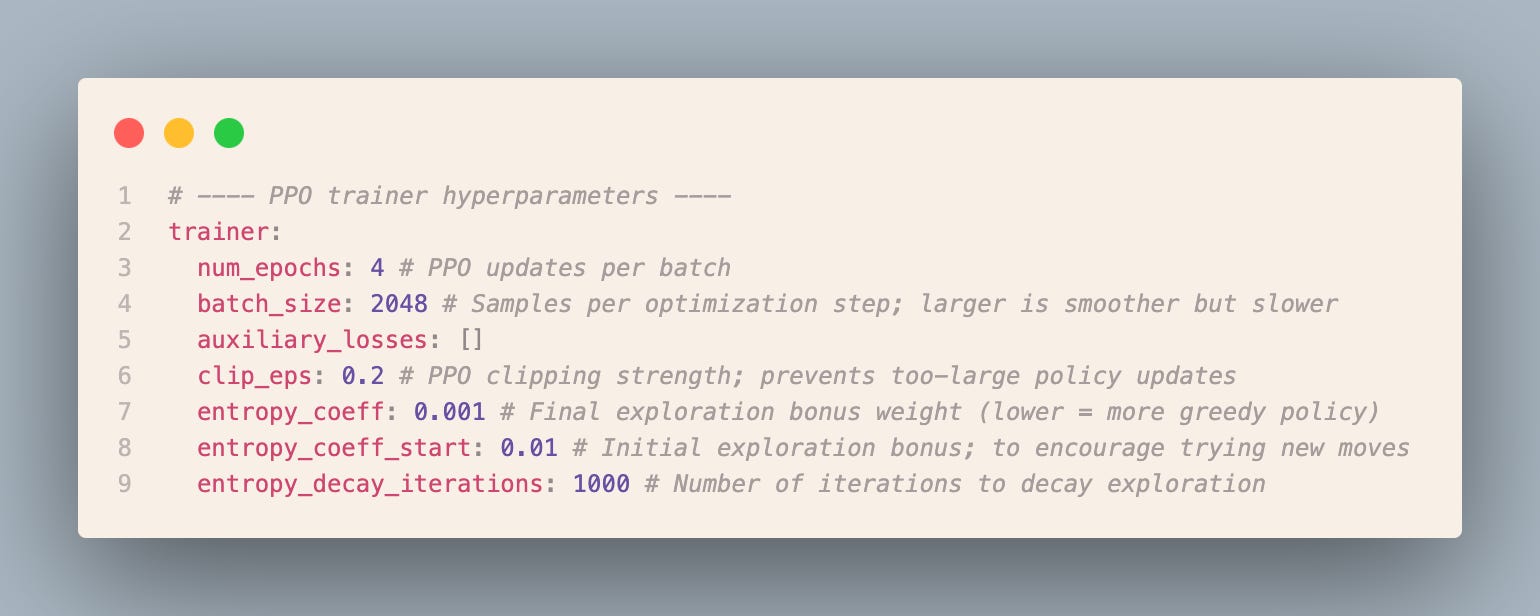
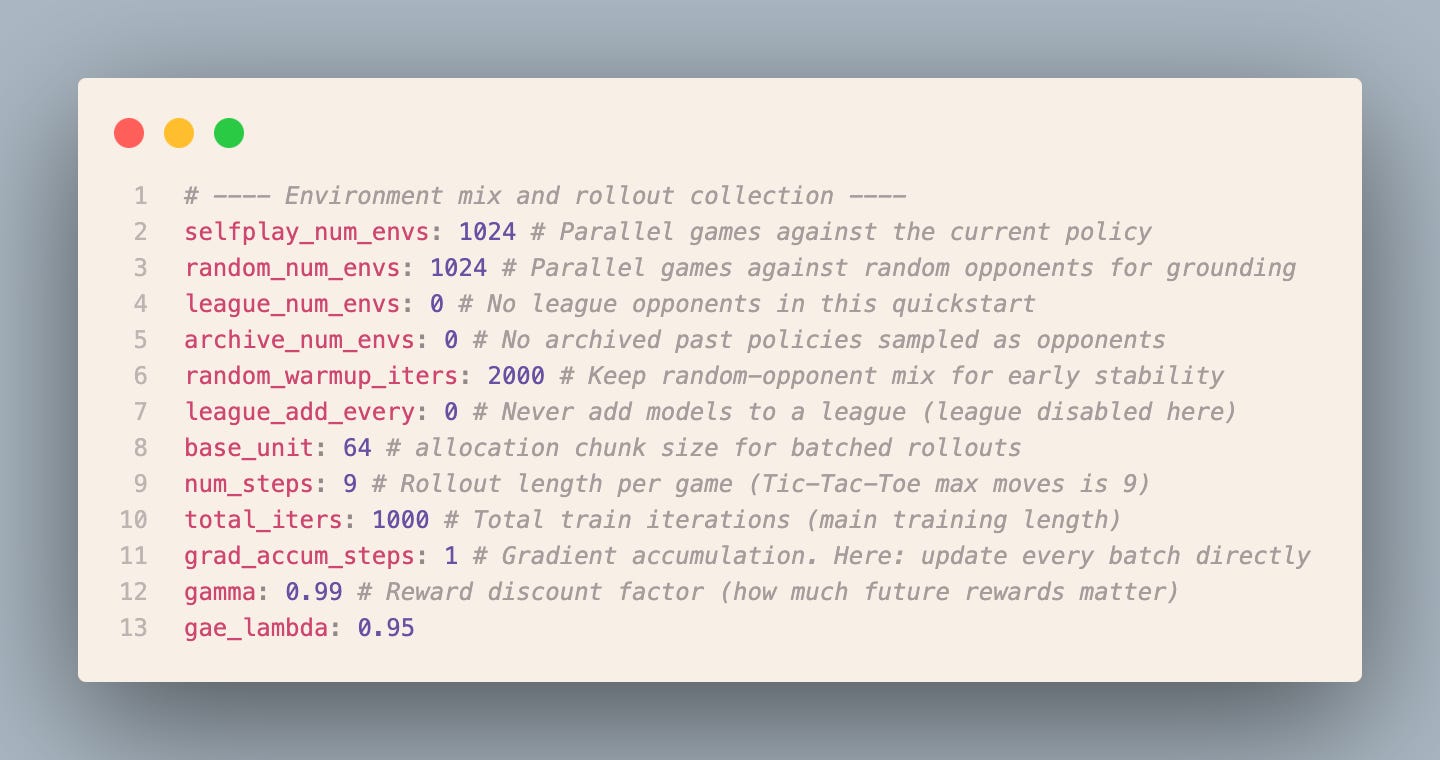
Next let’s inspect the config/experiment/tic_tac_toe/colab.yaml file. This is the tic tac toe experiment adjusted to fit on T4 GPU available for free on Colab. Let’s analyze selected sections from this file
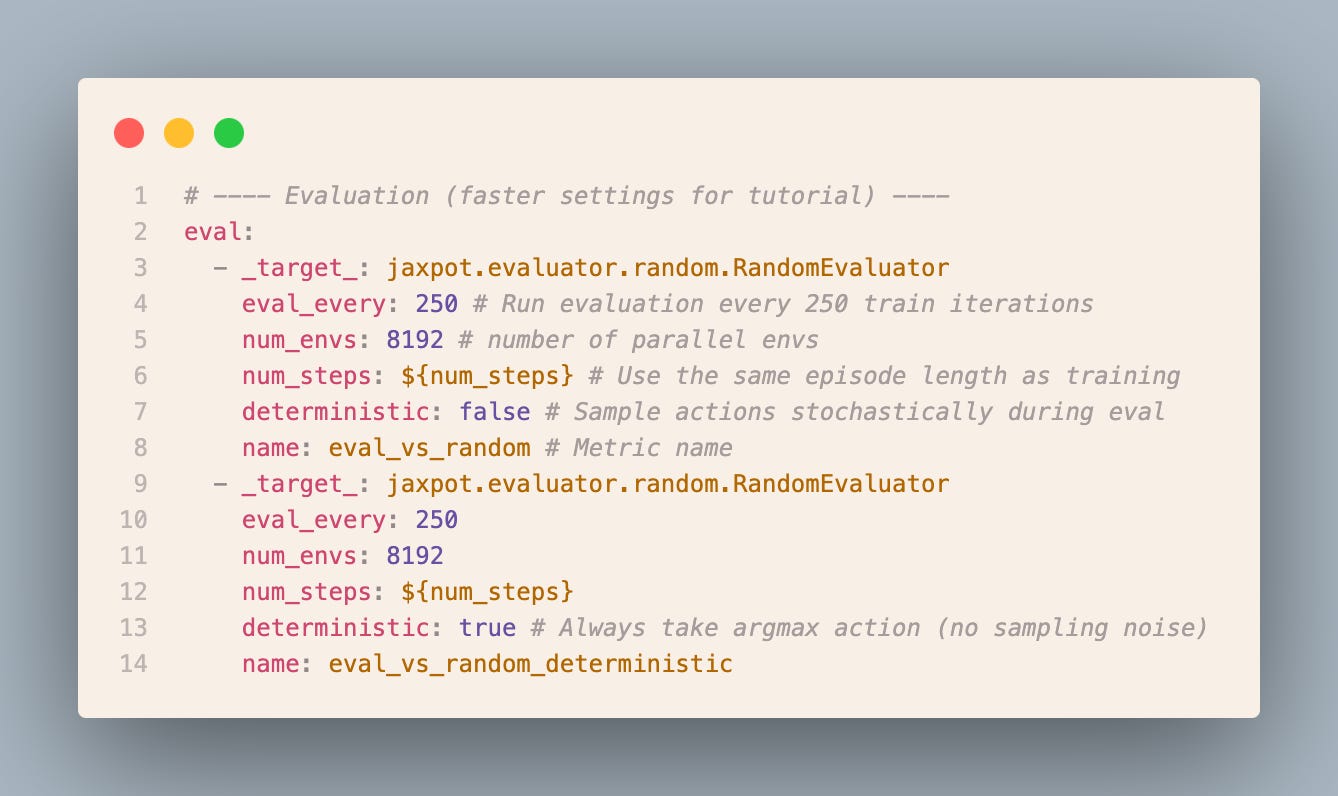
With the config ready we just need to log in to Weights & Biases to later inspect the training metrics. You can also use TensorBoard instead, but we prefer wandb.

A short script that will trigger our training pipeline. You can see in the notebook that we will overwrite some of the experiment parameters here for the ease of use in the tutorial. Try changing these parameters and see how it impacts the training!

When the run starts, Jaxpot prints a TUI dashboard.
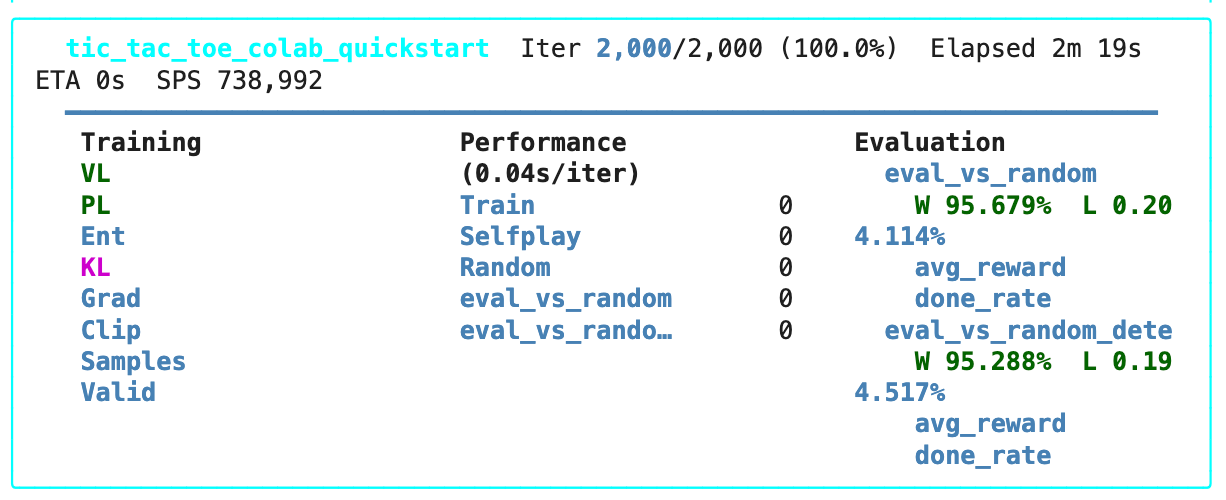
The dashboard is useful while the run is active, but curves are better for understanding training. You should see something like this after the run:
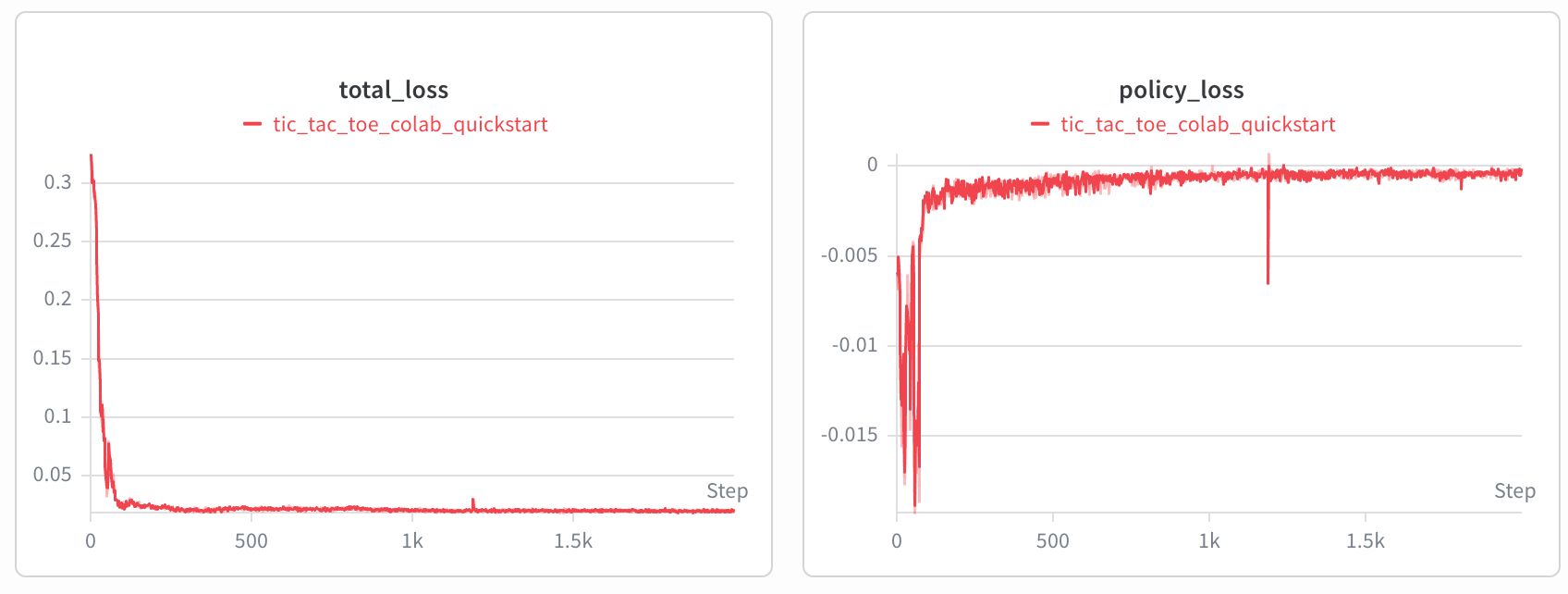
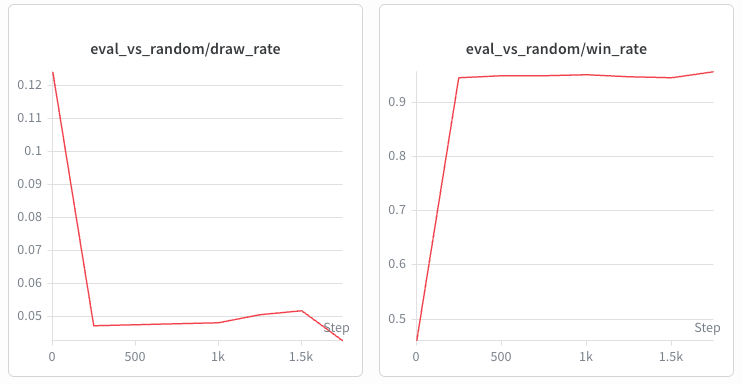
For Tic-Tac-Toe, a random opponent is very easy to exploit, so the win rate climbs quickly. It is a sanity check - the training loop works, and the evaluation pipeline is reporting.
You can start the training for Dark Hex from the same notebook and read the rest of article while it’s training.
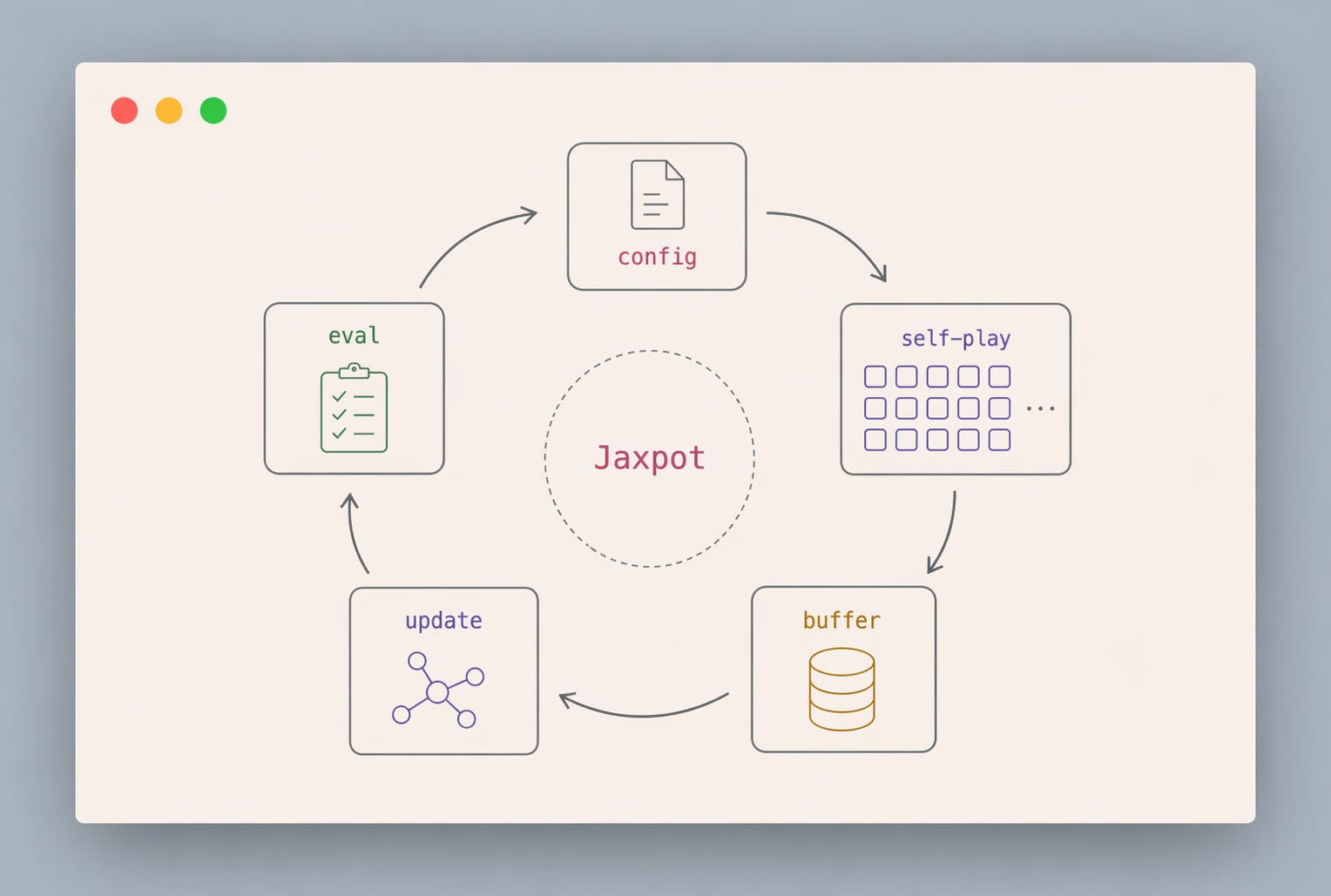
It is built around three practical ideas:
PPO and AlphaZero-style training. PPO gives you a strong policy-gradient baseline for self-play. AlphaZero-style components are useful when you want search and value-guided planning.
JAX. Vectorized rollouts and training, compiled, and run efficiently on accelerators. Pushing the training speed to the hardware limit.
Hydra configs. Experiments are composed from small config files for the game, model, trainer, evaluator, and logger. Changing the game or training setup requires just changing the config.
In perfect information games like Chess, Go, and standard Hex, both players see the full board. The game state is public.
Imperfect-information games split the state into public and private parts. Poker hides cards. Liar’s Dice hides dice. Dark Hex hides opponent stones unless you collide with them.
That changes everything. The optimal strategy is not a single fixed policy. A poker bot that always plays the highest win-rate line becomes predictable and easy to exploit.
Self-play already helps: the opponent keeps changing, so the policy cannot overfit to a fixed strategy. Entropy scheduling keeps the policy exploring early in training, which matters when the game demands mixed strategies.
On top of that, Jaxpot supports League play. The agent trains against frozen snapshots of itself from earlier in the run, and opponents it struggles against get higher sampling weight. That prevents the policy from “forgetting” how to beat older versions of itself. When the league fills up, surplus opponents move to an archive that can reactivate if the agent starts losing to them again.
In the video you can see a 1900 step model playing against 1800 step model both trained with Jaxpot. Keep in mind the black stones are not visible for the pink player. We can see them only in the replay. This is the difference between Hex and Dark Hex.
Now let’s switch to a game that is still small enough to understand, but much more interesting.
Dark Hex is an imperfect-information version of Hex.
In normal Hex, both players see the whole board. In Dark Hex, each player sees:
empty cells according to their own view
their own stones
opponent stones only when revealed through failed placement attempts
The true board exists, but the agent does not get to see it. This is a much better demonstration of why environment design matters. The agent is acting under uncertainty.
Jaxpot already includes the Dark Hex environment so you can start the training in the same notebook as before. Just scroll to the bottom of the notebook. Let’s see if you can improve the Dark Hex Agent winrate by changing the parameters? After some changes you should see a training run like this:
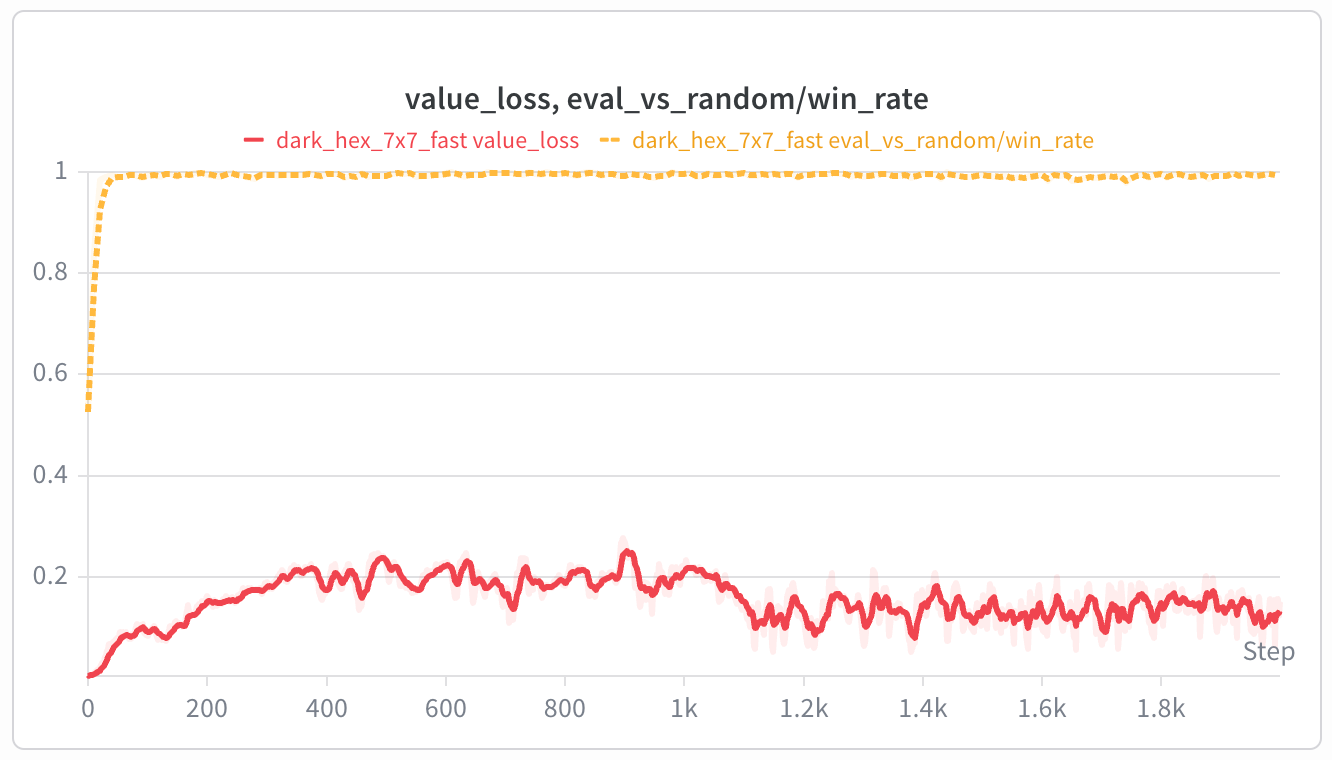
The yellow line shows the winrate against random opponent. You can see the model immediately started always winning agains it. Using random for training is a easy way to teach model how to exploit the opponent’s mistakes.
The Red line shows the loss of the value head. It keeps improving despite the fact the winrate with random opponent is flat.
Let us know what game agent you would like to see next!