Years before I came to Amazon, I worked in restaurants. I held numerous positions, including server, line cook, bartender, and delivery driver. I noticed that most of the places I worked at dealt with the load of busy events, like the lunch rush, in similar ways. When I started working at Amazon, I was struck by how much the approaches to solving problems of load in restaurants resembled how we build resilient systems in the cloud.
In restaurants, usually all customers could be seated and served quickly. However, under certain circumstances, even when it wasn’t that busy, temporary problems could cause significant delays. This happened when many customers either arrived or ordered at the same time, or when mistakes caused rework (such as dropping a plate of food, and unfortunately, I’ve dropped a few). When it did get busy and the number of customers exceeded our capacity to serve them, we would create a queue of customers waiting for a table. Both of these situations made them unhappy. To manage these problems, we employed a number of strategies to help provide a predictable and consistently good customer experience.
My experience working in restaurants also shaped how I behaved when I went out to eat. I wanted to limit my impact on the restaurant’s load, so if there were a queue at the door, I might choose to come back later or go somewhere else. If I asked a server for something, and they were really busy and forgot, I would politely ask again. If there were a minor problem with my order when it was really busy, I might just not eat the cold broccoli instead of sending my whole order back. I wanted to avoid creating further delays and extra wait times for myself and others. In short, I wanted to be a well-mannered restaurant patron. And without knowing it, I’d experienced what overload is like from both the server-side and client-side perspectives in distributed systems, as well as a few strategies to deal with those situations before I ever entered the technology industry.
After trading my “server-full” experience for serverless technologies in the cloud, I continued to draw upon my experience both as a restaurant worker and a restaurant customer. At Amazon, one of the areas I’ve focused on is how to make systems more resilient, in particular, how to control excessive load. I observed how spikes in load could affect systems in the cloud. It was similar to the way overload affected the quality of service in restaurants. However, I also saw a significant difference. Cloud services are elastic and can rapidly add capacity in response to increased demand, whereas capacity in restaurants, such as square footage, is static and can take years to scale. So, while overload events at restaurants can be quite common, at Amazon, we go to great lengths to prevent overload events from ever occurring.
Automated capacity forecasting and auto scaling help ensure our services stay ahead of demand by significant margins. We favor being over-provisioned to provide a buffer in capacity. This relieves customers from traditional on-premises capacity planning and allows them to build elastic services in the cloud. For example, in our services, we plan for extremely unlikely events, such as the loss of capacity of a single Availability Zone, and we have enough capacity pre-provisioned in other Availability Zones to seamlessly absorb the additional work and forecasted usage, as shown in the following figure.
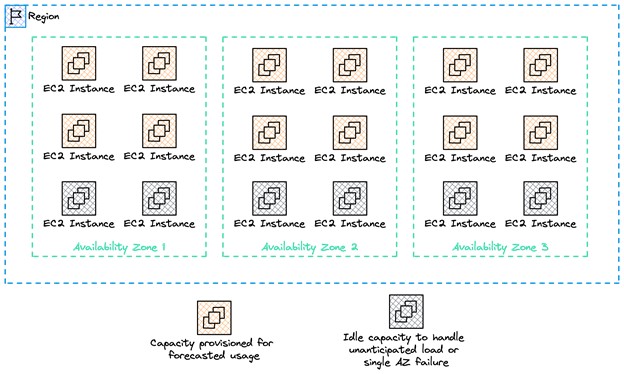
This also means that under normal circumstances our services have sufficient capacity to handle significant variations in load. In the cloud, true overload scenarios are rare events. But when things don’t go to plan, and one of these exceptional events does occur, we need to be prepared to prevent impact to our customers’ experience.
At Amazon, we use a combination of strategies to prevent overload, and we’ve described some of them in detail in Amazon Builders’ Library articles, which I’ll discuss later. Many of these strategies describe how we build well-protected services. Some of them are operational strategies for reacting to overload situations after they have been detected by our observability systems. Others are architectural strategies that are part of the design of our services to prevent overload from occurring. Additionally, our services typically interact with dependencies, and we employ strategies to be well-behaved clients. The specifics of the various techniques we use across these three areas are complex topics that we don’t have the space to go into here. However, we will provide links to articles that provide deep dives on them.
This article will give you a high-level overview of some of our most common strategies for controlling load, describe when and why we use each strategy, and identify the pros and cons of each. I hope this will help you choose the right combination of strategies for controlling load in your own systems to build well-protected services, well-behaved clients, or both.