For several years now, I've been convinced that blockchain solutions will bring new innovations, particularly in the decentralization of cloud computing.
Having never been a big fan of big tech Cloud providers. I saw the emergence of Decentralized Web3 Cloud solutions as a huge breath of fresh air.
With disruptive and innovative concepts for storing our precious files on the blockhain ... what a bright future for any decentralized solution enthusiast ....
I've been wating to take a closer look at these technologies for a long time, especially StorJ, FileCoin and Sia Coin, to name but a few.
I’ve spend some hours to deep dive on the Whitepaper with Notebook LLM 😁 And test the solution as user.
Now Let's take a look at StorJ
StorJ does not store your data on the blockchain ! ⛓💥 #
So sorry but your data is absolutely not protected with something like a hash of the commit transaction secured into an Layer 2 on a Ethereum Token.
Not so "Web3" finally ...
Worse than that, it's practically useless.
I don't even know why there's still an Erc20 Ethereum token. StorJ Token
It's even now possible to store data paying by credit card ... in fiat currency. Which is a good thing for adoption but break a bit the “Cryptocurrency myth / web3”
Data is stored with now commonly used (but state of the art) concepts. Nothing disruptif on the tech, this is Erasure Coding + Distributed Hastable.
The only disruptive element, compared to a traditional Cloud provider, is that anyone can participate in the network and set up a node to help expand capacit.
In exchange by providing ressource to support the network you'll be rewarded with the StorJ token.
Ressources provided by Anyone ?
By anyone It means you have to run a solid server with plenty of CPU/RAM and Disks backed by a fast bandwith to contribute on the network.
Don't expect to deploy a node or satellite on a Raspberry or an Intel N100 🍇
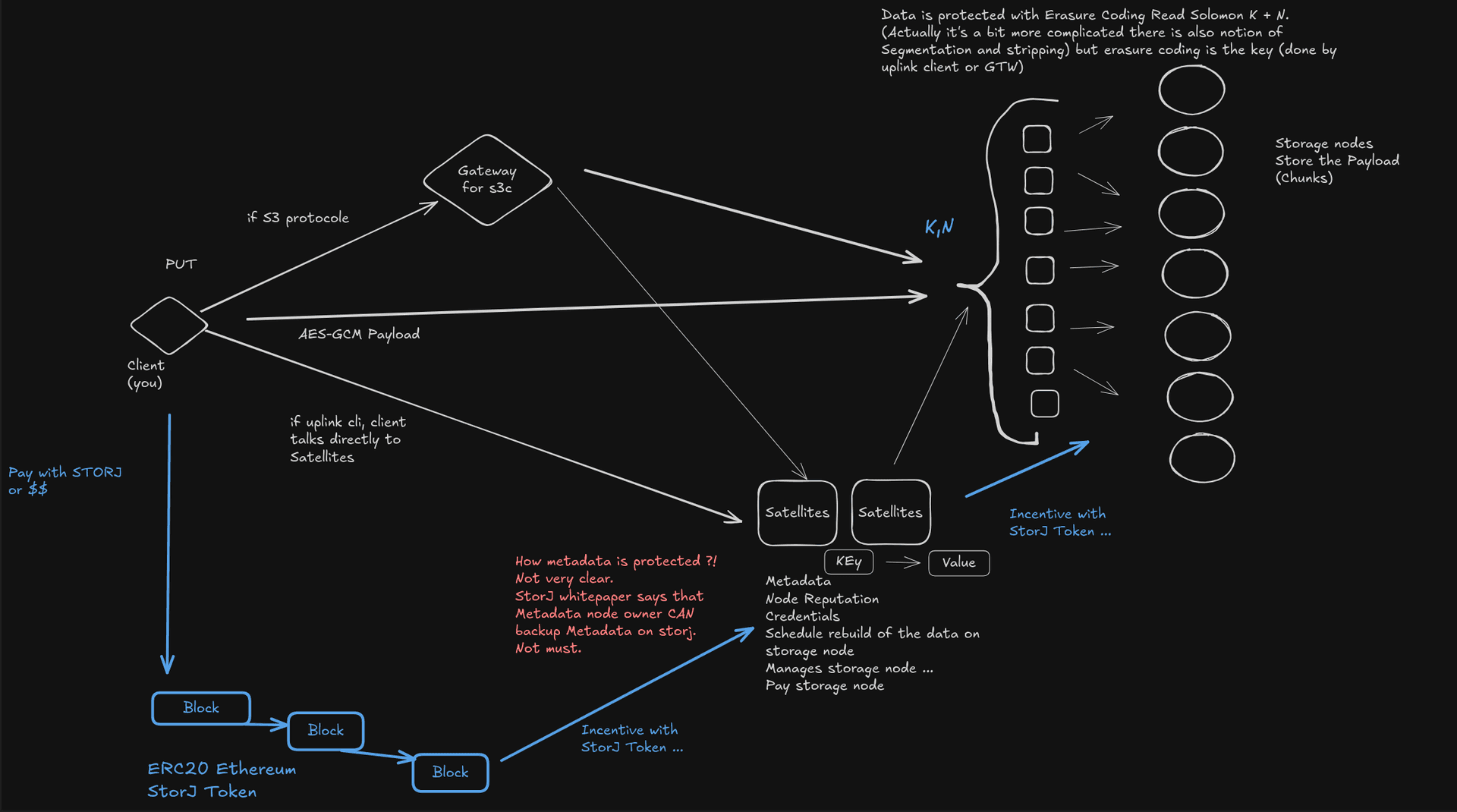
Architecture #
Or should I say what I’ve understood by reading the whitepaper.
You have 3 major components
- The Storage nodes (Store the payload and protect the data with Erasure-Coding Read Solomon)
- The Satellites (Kind of “orchestrator” that also have the role of Metadata database)
- The Gateway (purpose is to convert S3 Requests into “Storj” understandable protocole for Satellites)
But a picture is worth a thousand words. :
Prices : #
Currently you can set up an account for free if you want to test StorJ
- Upload and download 25GB free for 30 days.
- Integrate with any S3 compatible application.
- No credit card required.There is limitation with Free Trial :
- 1 project (Kind of account-like at AWS)
- 25GB storage included
- 25GB download included
- 10,000 segments included
- Fixed monthly usage limits
- Unlimited team members
- Share links with Storj domainBut after your trial period the prices on 2025-04 are :
- Storage $0.004 Per GB/month
- Egress $0.007 Per GB - Unlimited with no overage fees
And also not in the main page but some (very minors) extra fees exists :
- Each Segment stored on the network is charged a nominal Per Segment fee. The Per Segment Fee is (currently in 2025-04) $0.0000088 Per Segment Per Month.
In short it seems very competitives prices. Of courses prices will change depending on the offer/demand balance.
What are segments ? #
Well to explain this we have to deep dive a bit on “how your data is protected”
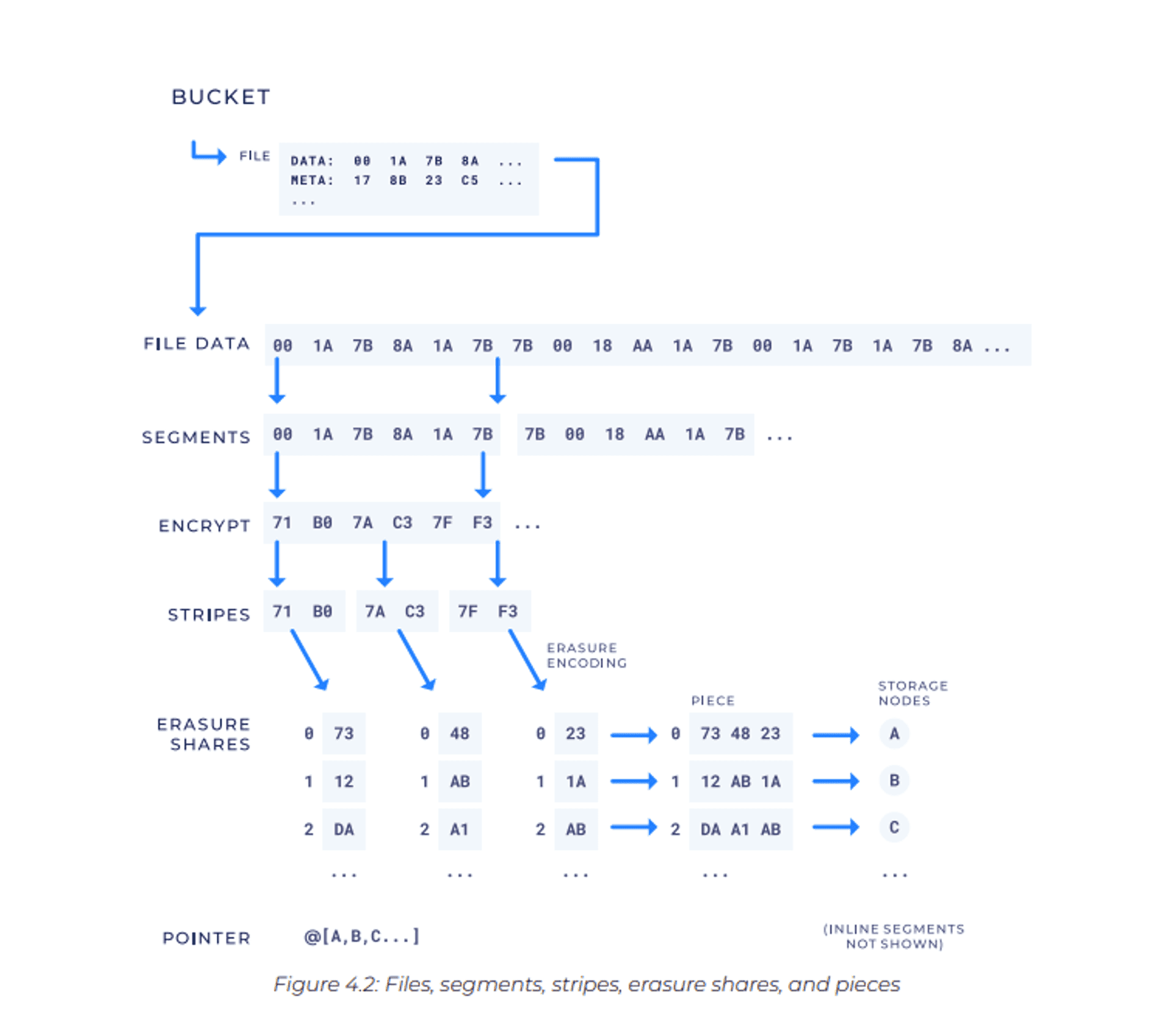
Screenshot from the StorJ Whitepaper 🤕
• A file is first divided into one or more segments : The default Segment size on Storj Satellites is 64MB
• Each segment is further subdivided into smaller units called stripes.
• Erasure encoding happens on individual stripes ... In a (k, n) erasure code scheme, n erasure shares are generated for every stripe.
• These erasure shares with the same index, across all stripes of a segment, are then concatenated to form a piece, which is what is stored on a storage node.
- Metadata of the bucket/objects are stored on the Sattelites.
Using kind of sharding and chunking is common in the storage Industry for somes reasons. This way you can grab only some parts (Like the S3 MPU) of a big file (for instance for Streaming Video).
Also distributed object storage is currently optimized for large files (several MB or larger - the larger the better).
warning For Small Files no erasure Coding !
The process below is only applied to “big” files, whitepaper is not very clear on what they consider to be “big”. It seems the limit is “4MB”
So small file (< 4MB ?) and files where data size is less than the metadata required to track its storage on remote nodes : won’t be really protected at ALL. If they do not exceed this threshold, they will be stored directly in the metadata on ... Satelites. I mean Satelites are machine with RAID Disk, but the chuncks won’t be secures/replicated by the network.
This is what they call an “Inline Segments”.
Disk on the metadata is smaller than on the Storage node (and more expensive: SSD), so you'll have to pay a surcharge (more Segments $$)
warning
And there is no native replication / protection for Metadata in the whitepaper at least.
StorJ advices the Satellite owner to do regular backup of the Metadata DATABASE into the Nodes, but no protection “by designed” 🤯
If I resume :
- If you file is > 4MB and < 64MB it creates 1 segment of 64MB
- Small files (=< 4MB ?) are less protected (no erasure coding), no replication. Backup are depending on the conscientious work of the platform administrator (?!)
- The more you store files the more you have to pay segment, because you consume more metadata and more segments and more data on store nodes.
- Storing 1 file of 1G is less expensive than storing 10 files of 100MB.
- You're better off storing tar.gz archives than unstructured files.
But does storing “archives” make any sense with S3 object ?
It seems not very convenant if I have to DL (and pay more) all my archives just to extract 1 files.
I prefer to do a list on my bucket and fetch only the file that I need.
Also the more I download the more I have to pay.
note
But the price is still very attractive we are talking about $0.0000088 / segments.
Encrypting : #
During the account creation Storj let you choose :
- The automatic mode : (basically Storj will use his own private key) your don’t have to type your master password each time you want to put/get/delete. The easiest way
- Manual mode : you ou need to enter your passphrase each time you access your data -> More privacy but you lost the passphrase = Datalost.
DATA is encrypted on the client side 👌 before it is sent to the Storj network with the uplink client.
The UX/UI : #
How this is easy to put/get my data.
Spoiler : This is really not to bad !
The UI is easy even for beginner. You will be well driven to create your first bucket.
They are also a lot of “wizard” to help you to generate you configuration to plug in your application (rclone/restic/nextcloud/Veeam/Comvault/TrueNas ...)
After creating a bucket, the wizard asks me if I want to activate object lock and versioning. For testing purposes, I create a standard bucket.
- S3 Object / Lock and versionning are available 😀
Once our bucket created let do some tests with rclone.
They are 2 way to use storJ with rclone :
- the Storj native way (with the uplink protocole) (You have to select storj backend during the rclone wizard)
- The S3 mode (through the Gateway) (You have to select S3 compatible backend during the rclone wizard)
Explanation of all the differences in the rclone documentation
Some tests with rclone : #
Bandwith during a PUT of a 7Gig file ~ 65Mi/s with s3 mode =~ 500MB/s : Really a decent througput for a distributed storage solution over Internet.

GET are even faster, I saturate the network of my test machine 🩹 ⏩

For small files, on the other hand, upload speed drops significantly but I was expecting this.
It could be more related to rclone behavior (computing the checksum before upload) than really a bottleneck on the network.

From my point of view performances are decent
During my test performances was pretty good ! But keep in mind that the network was probably not to busy at the moment.
note
Overall performance are also depending of the Storj network congestion : https://storjnet.info/
Finally : #
Globally I’m really impressed by the user experience and how easy it is to put your first bit into StorJ
The Pro : #
- Client super easy to deploy 💘
- Erasure Read Solomon is a solid tech that provides a great resiliency for you data 👌
- Real multi site distributed solution ☁️
- Data is encrypted on client side 🔐
- Documentation is totally decent (especially compared to the competitors)
- A great progress have be done on the UI / Portal and the user experience. 👊
- They try to follow the AWS S3 protocol which is a good thing for common adoption and data migration.
- Thus you can use / plug standard tools like rclone of even aws s3.
- But I guess they do not implement all the AWS S3 features (like versionning / lifecycle policy), this is very probably an standard S3.
- Thus you can use / plug standard tools like rclone of even aws s3.
The Con : #
- Metadata protection betweens nodes is not very clear I don’t know what is the protection for the
[KEY META -> Value DATA]owned by a Node or how this is replicated or not between Satellites. 🚩- This is the biggest RED flag for me, this point needs more clarification. Probably the response is somewhere in the community forum or something but it should be explained in the whitepaper.
- Small files (size ?!) are not replicated or erasure coded 🚩
- Mostly for cold storage / archive purpose.
- Overall architecture is complicated but ..
- Complicated problem (Data resiliency) can’t be solved by simple solutions, this is the counter-part to any distributed and scalable storage solution.
- From a user point of view this is not a problem.
- I didn’t understood what is the purpose on the blockchain ... Probably easier to get some cash to help the project and an easier way to retribute member of the network (that won’t be retribute with dollar but StorJ coin) But It lifts the romance of the blockchain out of the project.
- Cost estimation can be complicated (Segment pricing + Data Stored ...)
- Hosting a node or satelite is not for “hacker entusiasts” that want to support and secure the project with an old computer. 💸
Last words #
Will I use StorJ to backed up my data ?
- I don't know ... Solution looks mostly mature and, I love the initiative, but I have a Pcloud space with a lot of space available at the moment (yes, it's extremely centralized 🦡), but Pcloud is without subscription, and I'm not a fan of subscription services ...
- I liked the User experience and the documentation.
Well that was a long and difficult post. I hope I didn’t forget something important.
Next time I will try to review another "Web3" ... Storage tech.
If someone with a better experience than me, or from the StorJ community/team read this page and found a mistake, feel free to contact me.