A single photograph cannot tell you how far away anything is. Hold a photo at arm’s length and your eyes can guess depth from familiar cues (this mug looks the right size, that wall has texture I recognize), but the raw image has no distance information. A robot looking at a single camera frame has the same problem, only without the lifetime of familiarity. Today we start with walk through robotics, the part where the robot stops contemplating its own joints and starts looking at the world. Three honest answers exist for “how far is that thing.” Each pays a different price. By 2026, a fourth answer (foundation models running on cheap stereo pairs) is quietly eating the other three. I wonder if its going to be same debate eventually as LiDAR vs Camera + AI, we often see people fight on X on Tesla and Waymo approach.
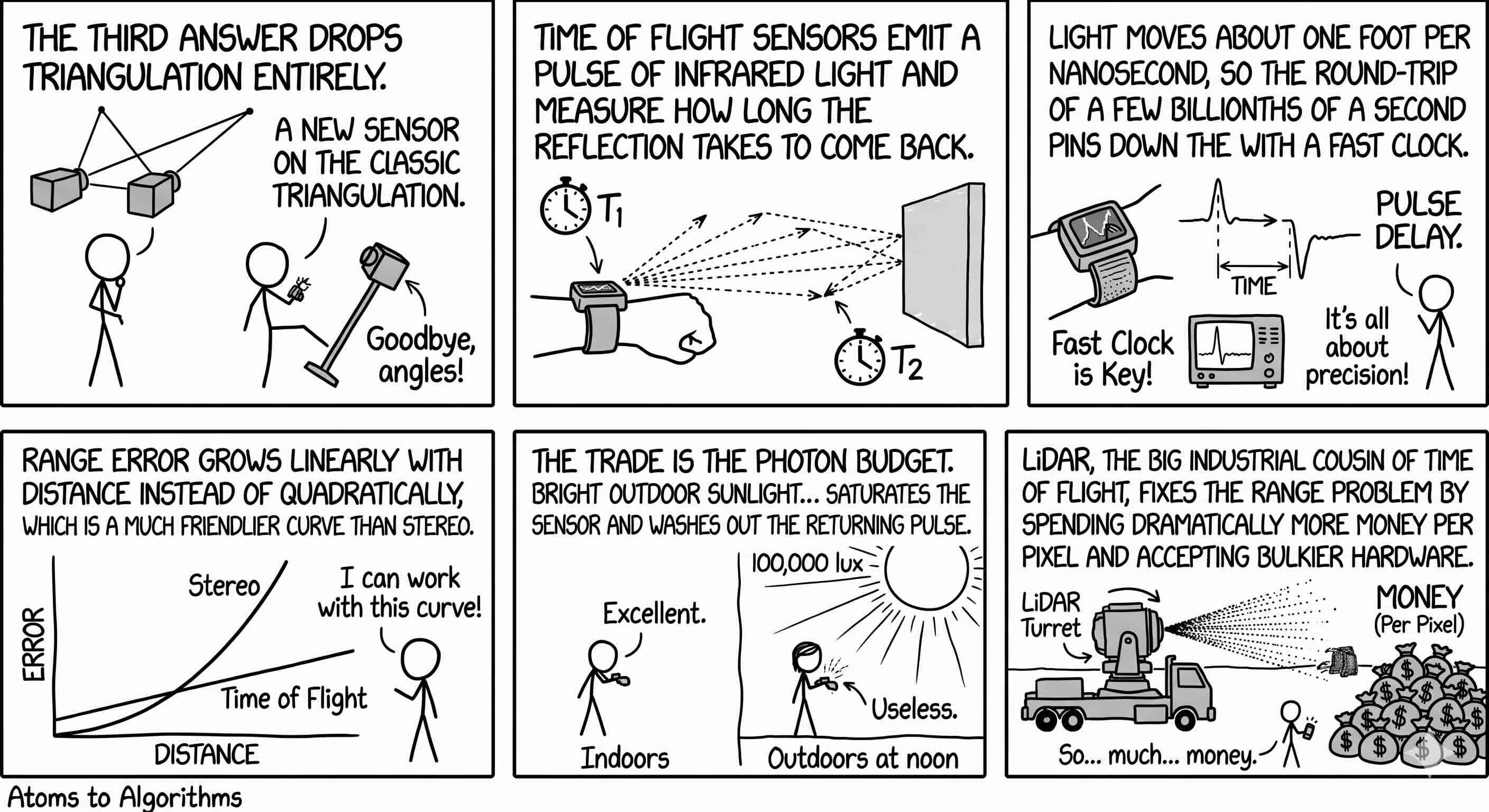
The first answer is the one your eyes already use. Two cameras, a small distance apart, see the same object from two slightly different angles. Closer objects shift more between the two views than far objects do, and the size of that shift, called disparity, is enough to compute distance with one division. This is passive stereo. The math is older than most robotics labs; the price is that depth gets noisier with distance. An object one meter away can be located to within a centimeter or two with a typical sensor. The same sensor at five meters is good to roughly ten centimeters at best. The error grows with the square of distance, which is the binding ceiling on every two-camera depth system in the field today.

The second answer cheats. If the world does not have enough texture to find matching points between two cameras (think of a robot looking at a blank white wall), you can throw your own texture onto the scene. Structured light does exactly that. A projector emits a known pattern of dots or stripes, a camera watches how that pattern deforms across the scene, and the deformation gives away the geometry. The original Microsoft Kinect, the iPhone’s TrueDepth front camera that powers Face ID, and the depth sensor on the gripper of Amazon’s new Vulcan warehouse robot all use this trick. The catch: structured light is an indoor technology. Direct sunlight contains so much infrared light that it drowns the projected pattern, and the pattern itself gets dimmer with distance, so the useful range is short.
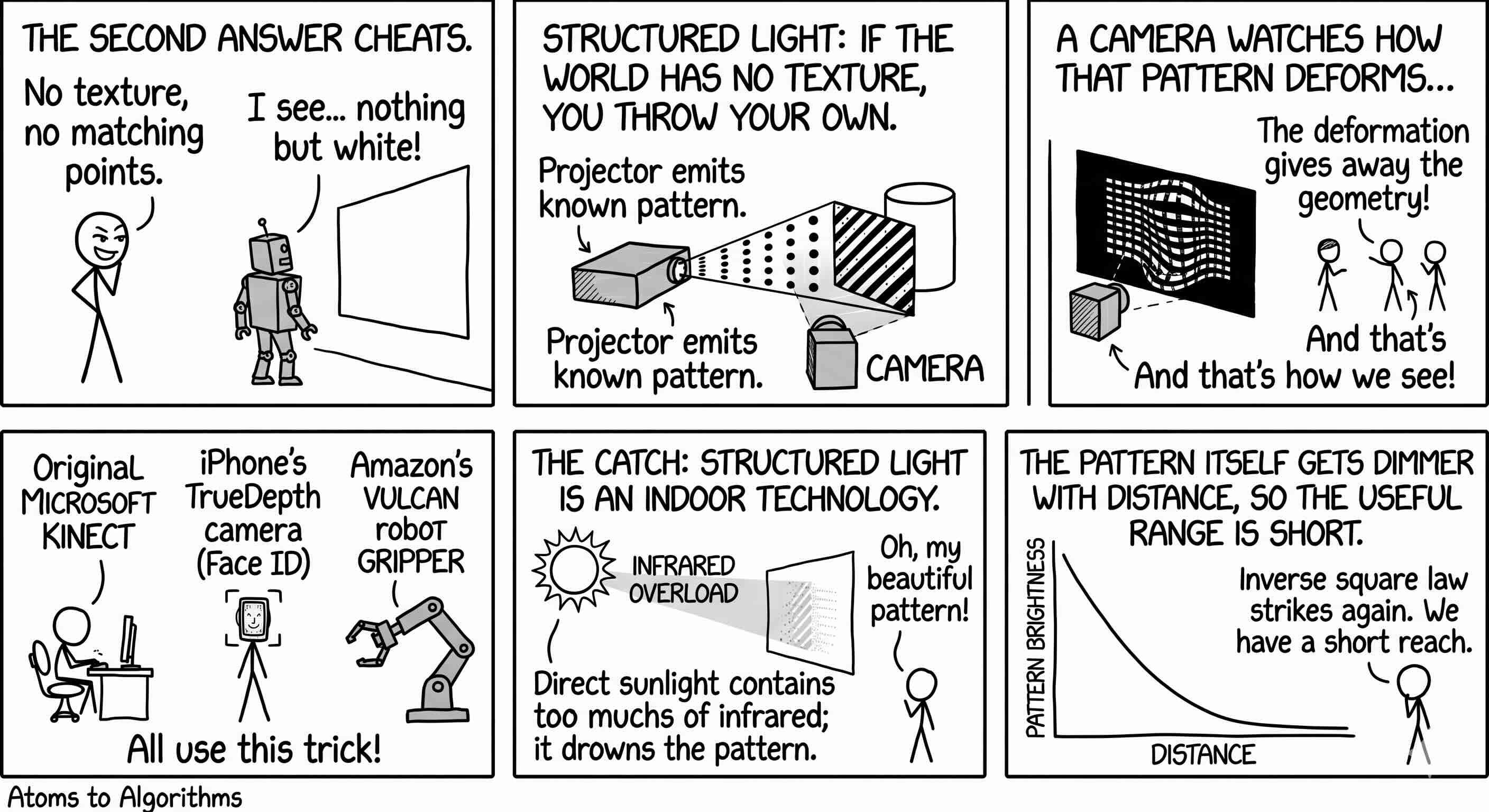
The third answer drops triangulation entirely. Time of flight sensors emit a pulse of infrared light and measure how long the reflection takes to come back. Light moves about one foot per nanosecond, so the round-trip time of a few billionths of a second pins down the distance with a fast clock. Range error grows linearly with distance instead of quadratically, which is a much friendlier curve than stereo. The trade is the photon budget. Bright outdoor sunlight (anything above roughly 20,000 lux) saturates the sensor and washes out the returning pulse. Indoors and at industrial scale, time of flight is excellent. Outdoors at noon, it is almost useless. LiDAR, the big industrial cousin of time of flight, fixes the range problem by spending dramatically more money per pixel and accepting bulkier hardware.
So far the choice has been a trilemma. Stereo is cheap but blurry at distance. Structured light is sharp but indoor-only. Time of flight is range-friendly but daylight-shy. Until last year, robot designers picked one and lived with it. Then something changed.
NVIDIA Research released a depth-estimation neural network called FoundationStereo in early 2025, then talked about it openly at the 2026 robotics blog cycle. The model was trained on more than one million synthetic pairs of stereo images, learned what depth looks like in indoor rooms and outdoor parks and industrial floors and warehouse aisles, and ships with no scene-specific tuning required. Point a pair of cheap cameras at the world, run the model, and the depth you get back is competitive with what you used to pay $350 for in a specialty depth camera. Boston Dynamics is running NVIDIA’s vision pipeline on its production robots through the same software stack, with the newest Jetson Thor compute board processing eight stereo camera streams at once in real time, ten times faster than the previous Jetson generation. The two-camera answer, plus a foundation model, is starting to beat the other two on cost and accuracy at the same time.
NVIDIA’s FoundationStereo took a Best Paper nomination at the CVPR vision conference in 2025 and the commercial version is openly described as “coming soon.” A November 2025 NVIDIA developer post laid out how the Jetson Thor chip can offload stereo depth onto dedicated hardware engines, leaving the GPU free for the neural-network policy that decides what the robot should do next. A new paper called StereoVLA, posted on arXiv in December 2025, shows for the first time that stereo cues materially help vision-language-action models on contact-rich manipulation tasks, and observes that stereo is currently “rarely exploited” in foundation-model policies. Another paper, D3RoMa, tackles the hardest case for any depth sensor: transparent and shiny objects, where laser pulses pass through glass and structured-light patterns reflect off chrome. The diffusion-based stereo approach in D3RoMa works where the older sensors flat-out fail.
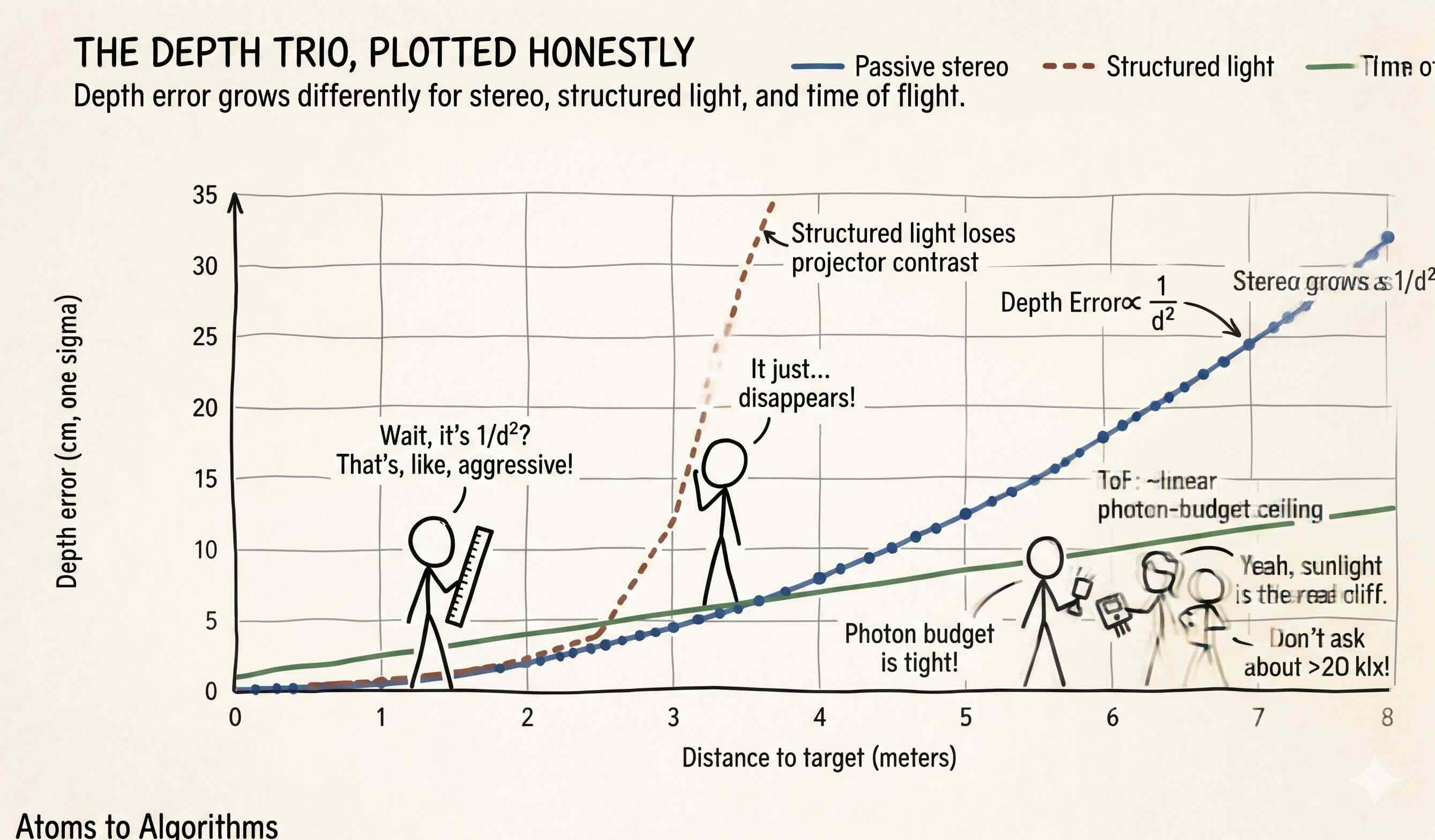
Above visualization plots the three modalities on a shared distance axis with their typical depth error. Stereo’s curve sweeps upward as a quadratic. Structured light tracks stereo at close range and then drops off a cliff once ambient light or distance overwhelm the projector. Time of flight runs as a straight line up to its photon-budget ceiling and stops. Three different curves, three different working ranges, no single winner across the full envelope. The right answer for a humanoid is rarely a single sensor. It is two or three modalities fused, with a learned model picking which one to trust where.
A closing thought worth holding. For most of robotics history, the depth sensor was an item on the bill of materials, a separate purchase with its own catalog page. That era is ending. The depth pipeline is becoming a feature of the compute platform, not a discrete device. Tomorrow we look at the radar lane, where 4D imaging radar arrays (Arbe’s product is the cleanest case) measure not just position but velocity, in every voxel, in a single shot. Stereo can tell you the mug is there; radar can tell you the mug is sliding toward the edge of the table at five centimeters a second. The two are complementary, and the industry is just starting to learn how to fuse them.
Subscribe for tomorrow’s read, we’re walking the robotics supply chain from atoms to algorithms, one weekday at a time.
Sources: