A radar voxel can tell a robot a forklift is reversing at three meters per second. It cannot tell the robot that the carton it just picked up is starting to slip between two compliant pads, because the carton is inside the gripper, not out in front of the camera. Yesterday’s issue closed with a promise about an elastomer skin, a tiny camera, and three colored LEDs. Today walks the trick that turns a deforming piece of rubber into a sub-millimeter map of whatever the robot is touching, and the curious fact that the highest-resolution touch sensor in robotics today is not really a touch sensor at all. It is a camera looking sideways at a piece of rubber.
(just a reminder - A voxel -"volumetric pixel" is the 3D equivalent of a 2D pixel. While a pixel is a single point of color in a flat image, a voxel is a tiny 3D cube or block that holds information for a specific point in three-dimensional space.)
Friday gave the robot three optical depth modalities, and Monday added radar’s fourth dimension. All four measure the world from a distance. Today closes the distance. Vision-based tactile sensing replaces an array of pressure transducers with a high-resolution camera and a transparent skin, then uses the camera image to work out what the skin is touching. The technique sits inside more than a hundred research papers and a half-dozen commercial products as of mid-2026, and it is the modality every serious humanoid hand program now budgets for.
The bottom of a GelSight fingertip is a thin slab of clear silicone, a few millimeters thick, with a layer of reflective paint on the outer surface. The paint makes the gel look opaque when you look at it from inside the finger, even though the gel itself is transparent. When the finger presses into an object, the painted outer surface deforms to match the shape pressed against it. Inside the rigid housing of the finger, a small color camera looks up at the inside of the gel, and a ring of LEDs in at least three different colors lights the gel from three different positions around the camera.
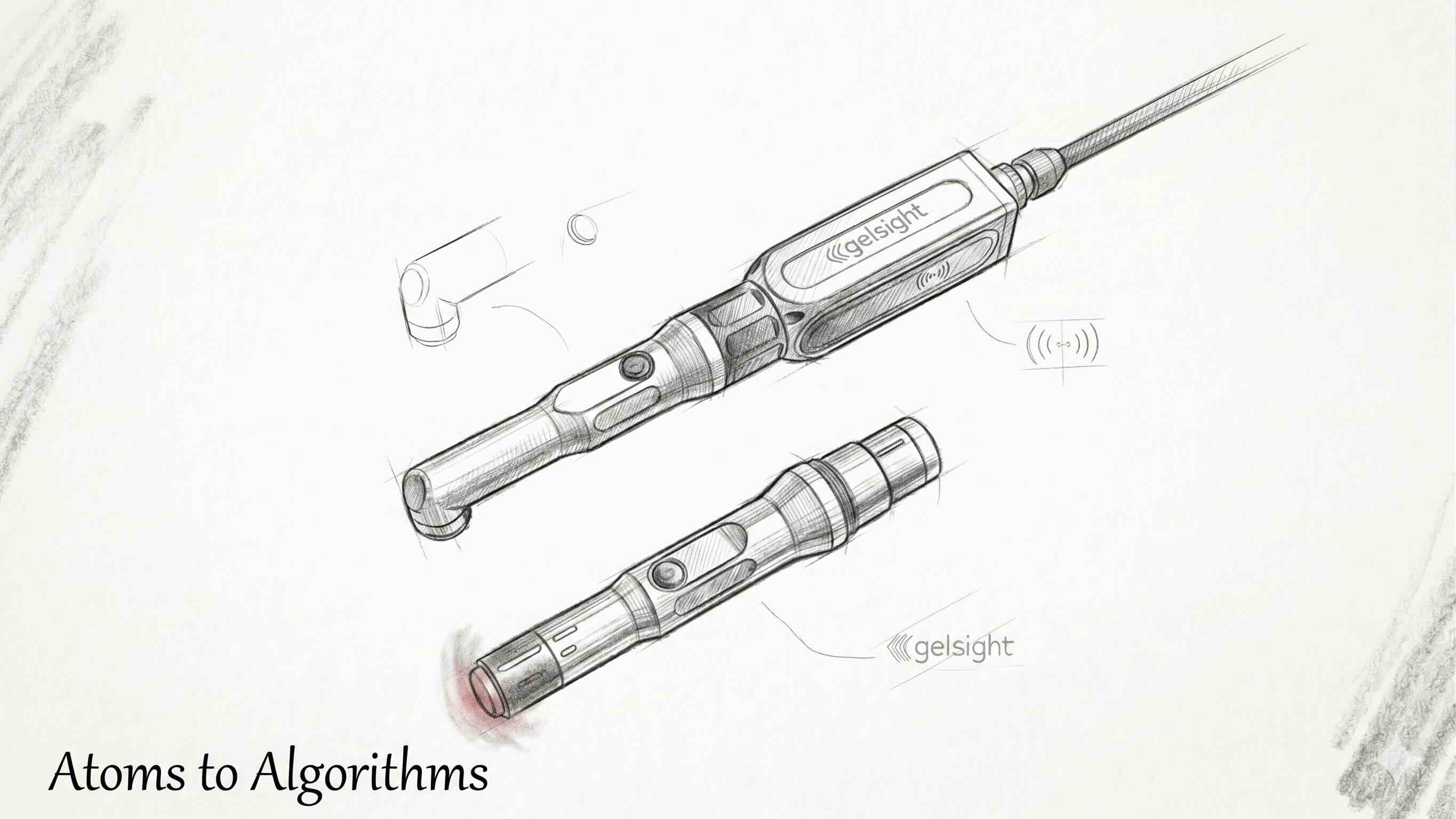
This is where a forty-five-year-old trick from computer vision called photometric stereo enters. The idea is that if you photograph a surface lit by three known lights from three different angles, the shading at each pixel tells you the orientation of the surface at that pixel. The classical version of the trick took three separate photos. The GelSight version takes one photo with three colored lights, because the camera’s red, green, and blue channels do the separation for you. Press a coin into the gel and the lookup tells the camera that the rim is steeper than the face, the date numerals dent the gel by tens of microns, and even the rotation of Lincoln’s head shows up as a tiny deflection. The earliest GelSight, out of Ted Adelson’s lab at MIT in 2009, resolved features about two microns wide. The commercial GelSight Mini, in production today, resolves features in the twenty-five to seventy-five micron range, which is more than an order of magnitude better than what the human fingertip can discriminate.
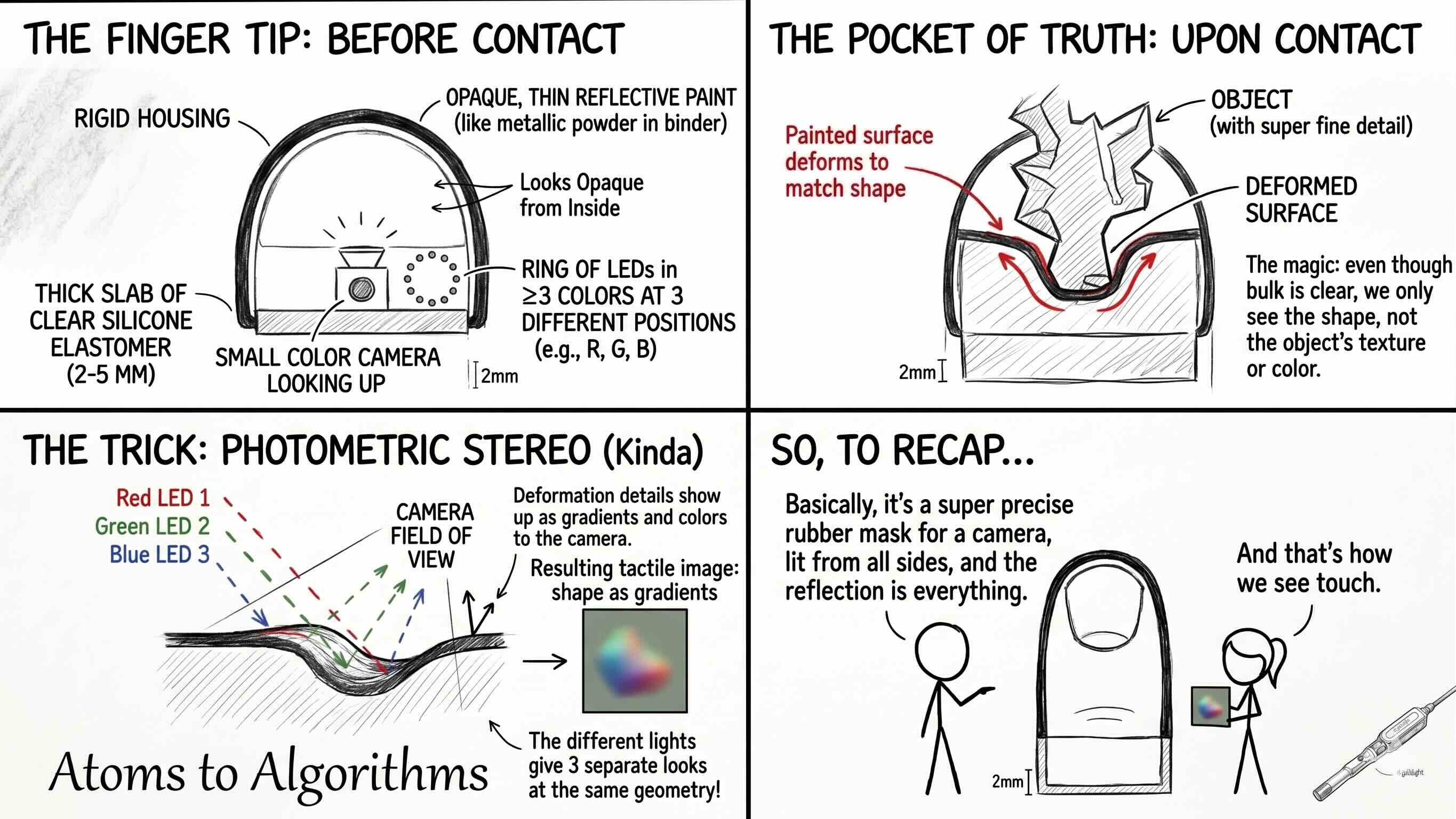
Three things follow from this design. First, the sensor is camera-priced, not transducer-priced. A 1080p camera and a 3D-printed plastic housing cost roughly fifteen dollars in parts. This is why Meta and GelSight together open-sourced DIGIT in 2020, and why the academic community now has more than thirty hardware variants in circulation. Second, the spatial resolution dominates everything else. A traditional capacitive or piezoresistive tactile array good enough for industrial gripper feedback runs at one taxel per several millimeters and tops out around a few hundred taxels per finger. A GelSight Mini produces roughly thirty thousand effective tactile pixels per fingertip at a similar cost. Third, the output is an image, which means everything the field has learned about training neural networks on images applies directly. The same foundation-model leverage that arrived in optical depth (Friday) and in 4D imaging radar (Monday) is now arriving in tactile.
What this buys for manipulation is the part that matters. Press a GelSight finger against a piece of cardboard and you can read the texture and the slight ridge where the box flap meets the body. Press it against an egg and you can watch the contact patch grow as the grip closes, then see the shear pattern shift the moment the egg starts to slip. The slip shows up in the gel image tens of milliseconds before the egg actually moves, which is enough time for a closed-loop controller to tighten the grip before the egg falls.
A team out of Beijing’s GeWu-Lab released AnyTouch 2 in February, a tactile representation-learning framework that works across multiple sensor types and explicitly models physical force dynamics over time. The argument is that tactile learning is now becoming sensor-agnostic, the way ImageNet pretraining is camera-agnostic.
In March, GelSight announced a Phase II Air Force SBIR contract to build a compact, ruggedized fingertip sensor with real-time three-dimensional touch and force data, aimed at defense robotics grippers. The interesting detail is not the headline. It is that government funding is now flowing directly into the form-factor problem, which has been the principal barrier to putting GelSight on a humanoid hand at production volume.
Also in March, a paper called MuxGel demonstrated a clever coating pattern that interleaves tactile-sensitive regions with transparent windows on the same gel, letting a single camera produce both external vision and tactile reconstruction. This is the first credible argument that vision-based tactile sensors do not have to be blind eyes trapped inside the finger; they can look out at the world at the same time.
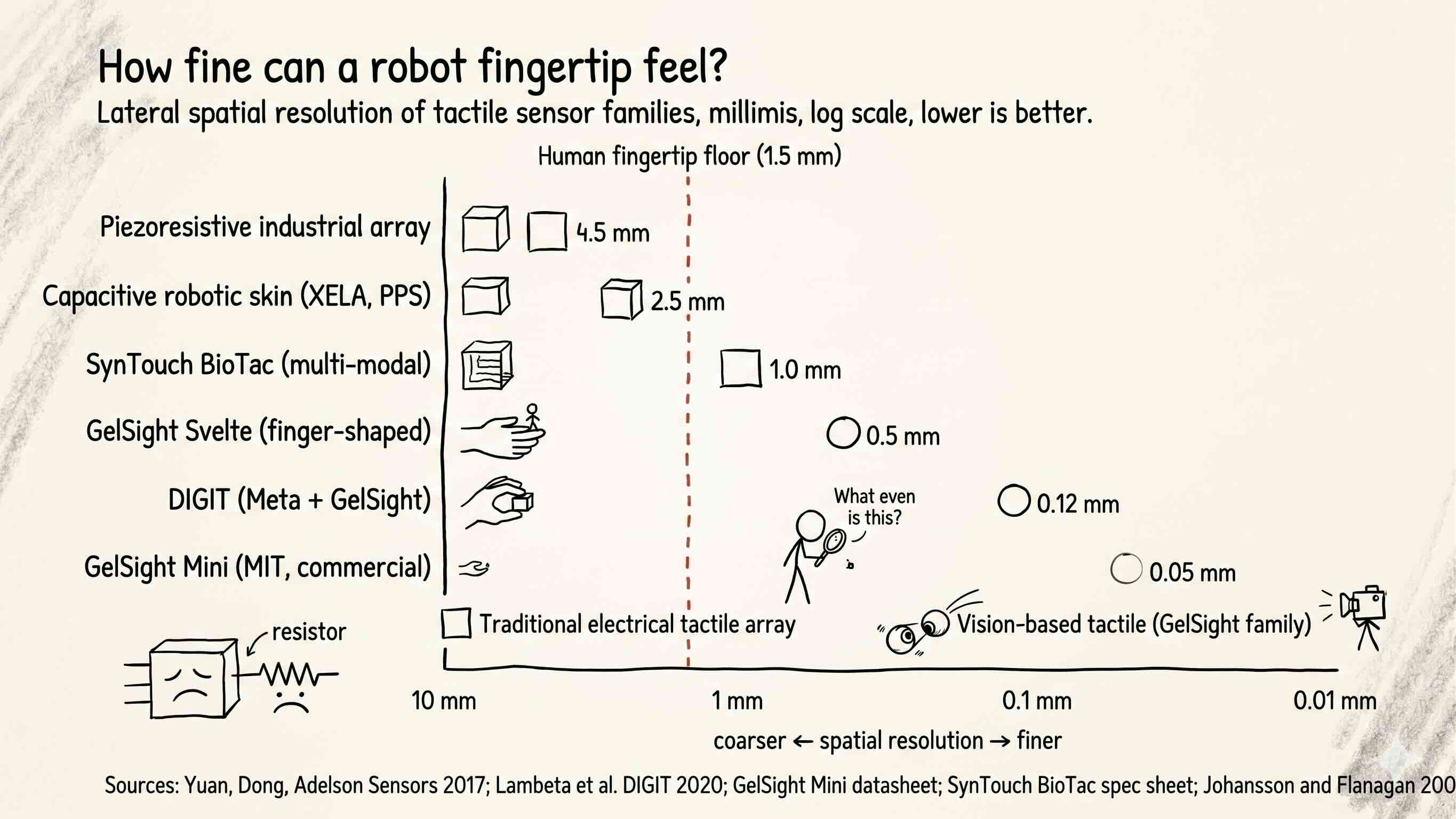
Above visualization plots the lateral spatial resolution of the main tactile sensor families on a log scale, from coarse on the left to fine on the right. Industrial piezoresistive arrays sit near five millimeters. Capacitive grids on robotic skins sit near two to three millimeters. The human fingertip’s two-point discrimination threshold, the biology floor, sits at roughly 1.5 millimeters. The DIGIT sensor sits near 120 microns. The GelSight Mini sits near twenty-five to seventy-five microns. The takeaway is that vision-based tactile sensors cross the human fingertip floor by more than an order of magnitude, on hardware that costs roughly the same as a smartphone camera module. The graph also marks a vertical “biology floor” reference line so the reader can see at a glance which modalities have crossed it.
The story to hold for next one is this. Vision-based tactile sensing solves the close-range, contact-rich half of perception that no camera, no LiDAR, no radar can touch. But it solves it one fingertip at a time. A humanoid robot stitching together stereo depth in front of it, radar velocity around it, and tactile maps inside its grippers ends up with a dozen different sensors producing different kinds of data at different rates, all of which have to be folded into a single estimate of “where am I, what is around me, and what am I touching right now.” That folding problem is SLAM, simultaneous localization and mapping, and it is where the next issue lives.
Subscribe for tomorrow’s read, we’re walking the robotics supply chain from atoms to algorithms, one weekday at a time.
Sources: