A modern humanoid robot carries about as much battery as a high-end electric bicycle - roughly 2 to 2.5 kilowatt-hours, and has to spend that energy on 40 to 50 actuated joints, a head full of cameras, a tactile stack, radios, cooling fans, and a single piece of silicon that runs the entire brain.
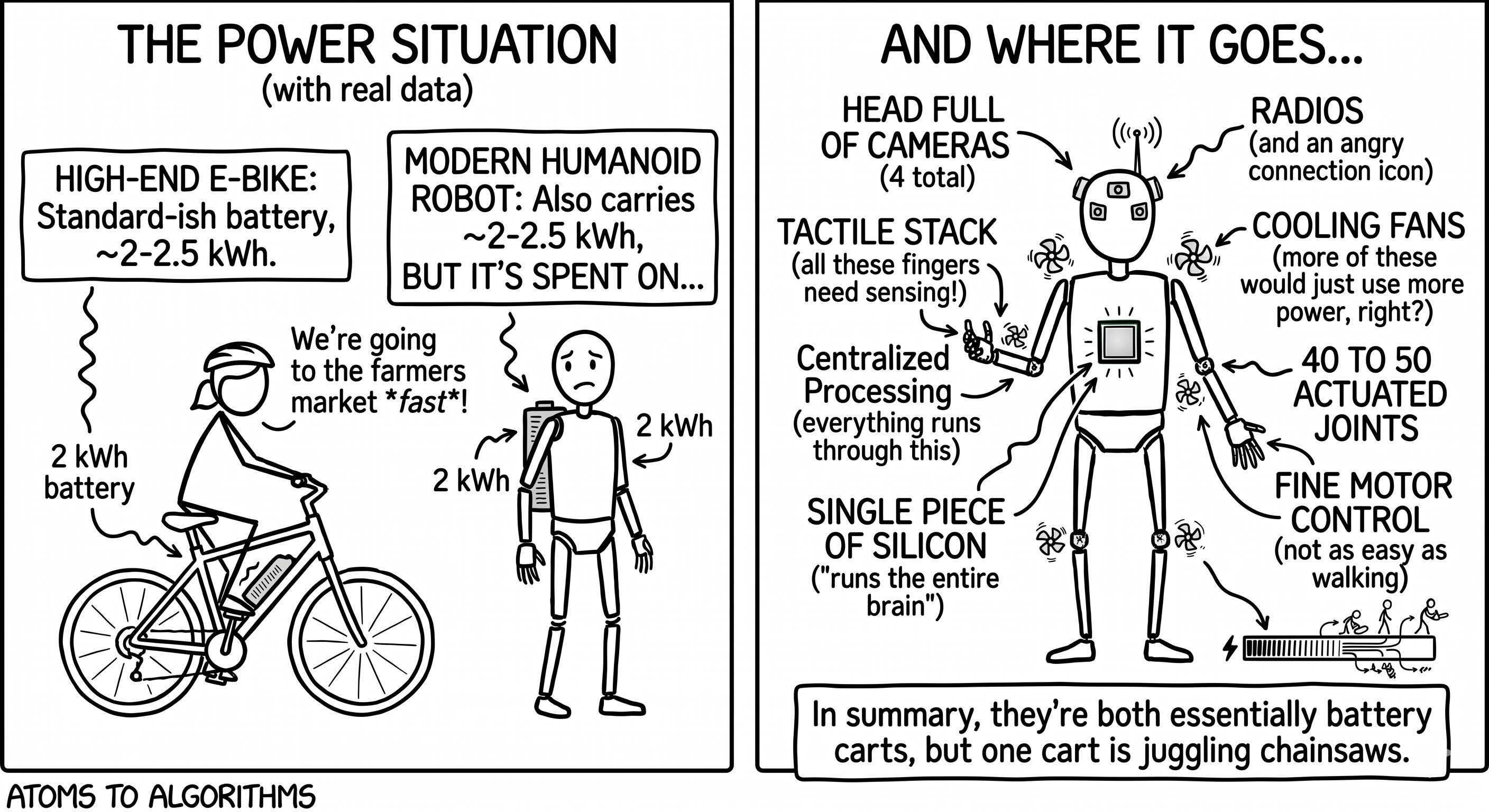
The new headliner for that silicon is NVIDIA’s Jetson Thor, a module that delivers up to 2,070 trillion AI operations per second inside a 40 to 130 watt envelope. Run a 7-billion-parameter “see, read, and act” foundation model on it thirty times a second and the model eats most of those watts. Everything else the brain has to do - turn raw pixels into clean images, fuse sensor streams, run the millisecond-by-millisecond joint control that stops the robot from falling over - has to fit inside what’s left. On the order of forty watts. The humanoid race in 2026 is, at the chip layer, a race to spend those forty watts wisely.
Yesterday we mapped the gap between robot vision (essentially solved) and robot touch (two orders of magnitude behind a human fingertip), and ended on a question: who actually thinks with all those sensor streams? Today is the silicon that does the thinking, and the watt budget that decides what’s realistic to think about. Tomorrow we close the week by stitching all four layers - magnets, gearboxes, sensors, compute into a single picks-and-shovels argument. Slowly we are connecting all the dots to make it full functioning machine.
Here is silly comparison for fun -

The human brain runs on roughly 20 watts continuously. About the same as a dim LED bulb. It’s only ~2% of body mass but burns ~20% of resting metabolism, and that 20W stays remarkably flat whether you’re solving differential equations or watching TV. For context, a whole resting human body burns about 100W, and a walking human totals 300 to 400W (mostly muscle).
A humanoid robot’s brain alone sits at 40 to 130W for NVIDIA’s Jetson Thor, and 15 to 70W for the smaller Qualcomm and Ambarella parts. So the silicon doing roughly analogous perception and policy work consumes about 6x more power than a biological brain, and that’s before you add the image-signal-processor, the real-time control MCU, and the sensor stack on top.
The whole robot is worse. A humanoid like Atlas or Optimus draws on the order of 1,000 to 2,000W while walking, dominated by servo motors holding the body up against gravity. So a human/humanoid comparison at the system level looks roughly like:
Walking human: ~350W, ~20W of that for the brain
Walking humanoid: ~1,500W, ~100W of that for the brain
The whole-body gap is ~4x; the brain-only gap is ~5 to 6x; and the per-operation gap is much wider than either, because biological neurons get an estimated 10^16 to 10^17 synaptic operations per second out of those 20W, which no current silicon comes close to. (Synaptic ops are not floating-point ops, so this is a loose comparison.)
The kicker is the energy budget per “shift.” A human eats ~2,000 kcal, which is ~2.3 kWh of chemical energy, and gets a full waking day out of it. A current humanoid carries about the same ~2.3 kWh in its battery and gets 3 to 5 hours. Same energy, very different mileage. Biology is winning on efficiency by roughly an order of magnitude, and that gap is where most of the engineering pressure on the next-gen humanoid SoCs comes from.
I am sure it is area of research on its own and at some point the gap will keep reducing or at least I am hoping for it that there is alpha there in long run.
The brain of a humanoid robot has three layers, and each one has a different physical constraint.
The bottom layer is the fast reflex loop what keeps the robot from face-planting. It runs about a thousand times a second, reads how each joint is currently moving, and tells the motors how hard to push. It is small, predictable, and lives on a real-time processor isolated from everything else. The power cost is single-digit watts. The cost of interrupting it is the robot falling over.
The middle layer is perception and reflexive action, what takes the raw camera and touch streams and decides “reach left and grasp.” In 2026 this is increasingly a learned neural network running 20 to 50 times a second. This is where the watts go. A 7-billion-parameter model is, at the silicon level, a tower of matrix multiplications; running it at robot speed is what motivates a chip like Jetson Thor in the first place.
The top layer is slow reasoning, what reads “go clean the kitchen counter” in plain language and breaks it into sub-tasks. It tolerates seconds of latency and usually lives off-robot, in the cloud. That gets you a much bigger model, but the cost is network round-trip time and a dependency on coverage. The newest research idea articulated in a March 2026 paper called ECHO is to split this layer: the cloud writes the script, the robot performs it, and the connection between them is just thin enough to survive a dropped signal. - I feel this is kind of biggest risk, as if the cloud connection drops, the only layer that goes dark is the slow reasoning layer. The bottom two layers, the 1 kHz reflex loop and the 20 to 50 Hz reactive policy, both live on the robot. So a humanoid mid-task doesn't fall over when Verizon hiccups, it finishes whatever motion reference the cloud already sent and then runs out of new instructions. That's the "thin enough to survive a dropped signal" property ECHO claims: the cloud sends a script, the edge executes it, and the edge can keep executing the current script for some bounded interval after the cloud goes silent.
Two numbers explain why this is hard. First, a humanoid’s battery has to last a working shift. At 130 watts of continuous chip draw, the silicon alone burns roughly 40% of a 2.3 kWh pack in eight hours. Compute is no longer a rounding error against the actuators. Second, the end-to-end latency budget for stable manipulation sensor in, action out - is about thirty to fifty milliseconds. Inside that window the robot has to read its cameras, denoise them, fuse them with depth and tactile data, push the result through the big neural network, decode an action, and send torque commands. If any single stage runs late, the whole loop becomes useless.
That combination - finite watts, hard latency is why there is now a three-way race to define the standard chip for this market. NVIDIA is coming from the data center: maximum AI horsepower and a foundation-model framework (Isaac GR00T) built for humanoids. Qualcomm, with its new Dragonwing IQ10 series at CES 2026, is coming from smartphones: less raw horsepower, a long pedigree of squeezing performance out of milliwatts. Ambarella is coming from automotive driver-assist: not the biggest chip, but exceptional at the image-processing pipeline upstream of any neural network. NVIDIA is closest to owning the market - Boston Dynamics, Figure, Amazon Robotics, Apptronik, and Caterpillar are all on Jetson Thor today. Once an OEM commits to a chip family, they implicitly commit to that vendor’s simulator, runtime, and update pipeline for years. The chip choice is becoming the stickiest engineering decision a humanoid program makes, after the actuator selection.
NVIDIA Jetson Thor is now generally available. The same chip is going into Atlas at Boston Dynamics, Amazon’s warehouse fleet, Figure’s commercial humanoid, Apptronik’s Apollo, and Caterpillar’s construction-site autonomy stack. That breadth makes it the closest thing to a humanoid industry standard that has ever existed. (NVIDIA Newsroom)
Qualcomm has entered the humanoid race. At CES 2026 in January, Qualcomm unveiled the Dragonwing IQ10 chip series - its first explicitly humanoid-class robotics processor. The pitch is performance per watt rather than raw performance, which matters more on a battery-powered platform than the marketing graphs suggest. (Qualcomm) This is the most legitimate competition to Jetson Thor as per the information available publicly.
Memory bandwidth is becoming the real ceiling. A March 2026 survey of foundation models on edge devices found that diffusion-policy workloads which benchmark at 30 frames per second in isolation drop to 6 to 12 frames per second under realistic sensor load - purely because the memory subsystem can’t keep up. That is why Jetson Thor’s top SKU ships with 128 gigabytes of unified memory: the bottleneck has migrated. (arXiv)
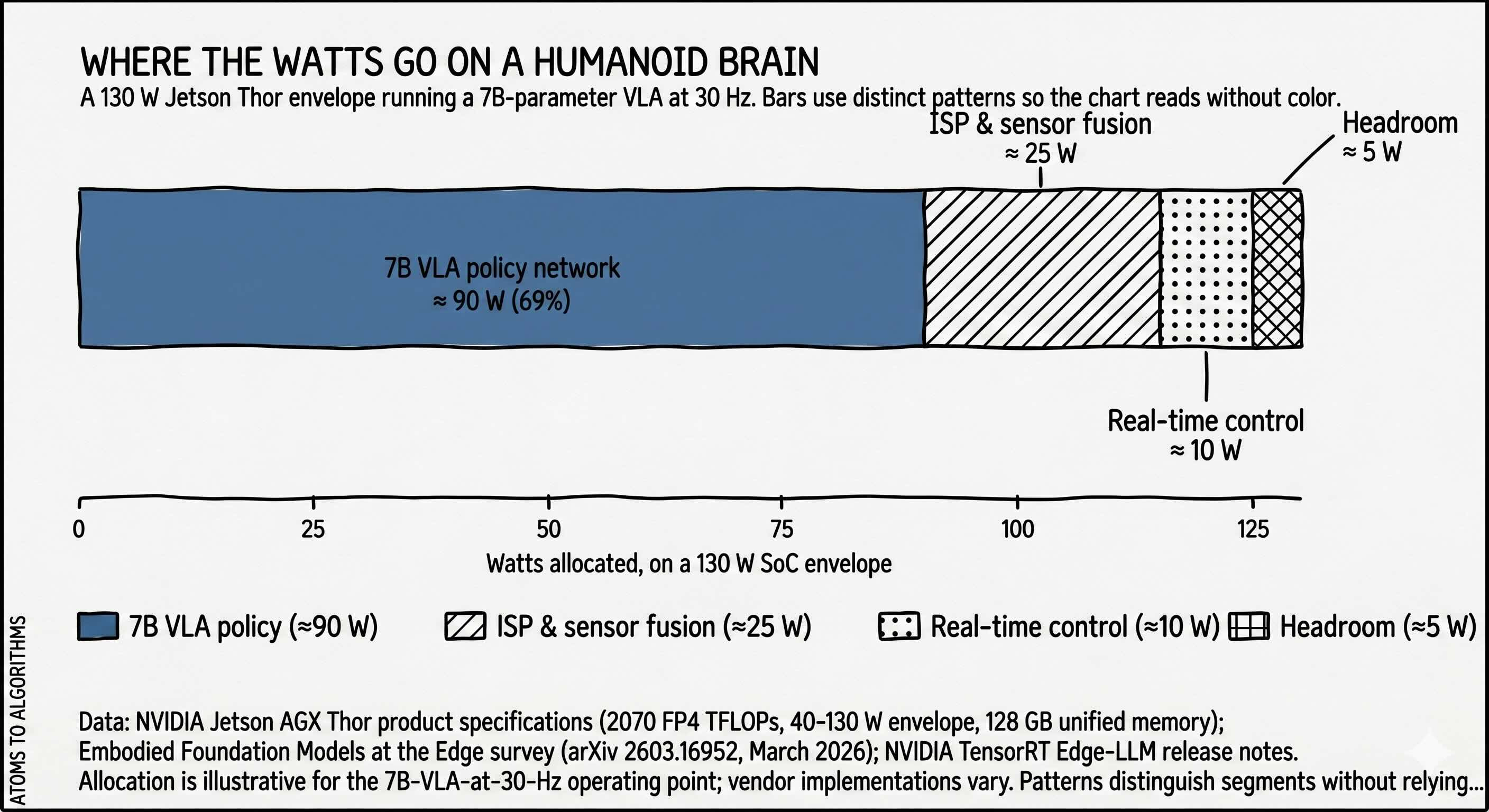
The visualization is a stacked watt budget showing how a 130-watt chip envelope gets carved up when you run a modern 7-billion-parameter robot policy at 30 Hz. The big block is the policy itself roughly two-thirds of the budget. The image-signal processing, sensor fusion, real-time joint control, and headroom together share the remaining third. The exact split varies vendor to vendor and tuning to tuning, but the shape is robust: the foundation model is now the dominant consumer of on-robot watts, and “everything else the brain does” lives in the residual.
The thing that should make you pause is not the math; it is the way the math compounds. If on-robot models keep growing and they will - then the residual either shrinks until the rest of the stack starves, the chip envelope has to grow, or the rest of the stack has to be re-architected to take less. Each path has a different winner in chip and battery markets, and that is the question Week 1 has been quietly setting up. Tomorrow we close the week with the synthesis: across rare-earth magnets, strain-wave gearboxes, the tactile-vision asymmetry, and now the watt budget, who actually gets paid regardless of which humanoid OEM wins and which of those beneficiaries compounds, versus which just collects the same dollar of components from every robot maker.
Subscribe for tomorrow’s read - we’re walking the robotics supply chain from atoms to algorithms, one weekday at a time.
Sources: