
Large Language Models (LLMs) are transforming the processing of unstructured text, offering vast potential for clinical applications and medical research. In healthcare, ambient scribes—automated systems combining speech recognition with documentation generation—are reducing provider burnout. Healthcare systems are also using LLMs for administrative tasks like managing insurance authorizations and drafting patient correspondence. As these models improve in capability and affordability, ensuring accuracy and reliability remains critical, especially in clinical settings.
In this blog, we explore the accuracy of leading LLMs in processing medical domain text. We selected the task of generating after-visit summaries (AVS) from brief hospital courses (BHC) using the MIMIC-IV dataset as an example, building on the work of Hegselmann et. al. (2024) to critically evaluate the capabilities and limitations of LLMs. Additionally, we examine the accuracy of these models as evaluators for medical domain tasks1.
Key Findings:
1. Cost-Effective Solutions Are Within Reach
While new generations of LLMs continue to offer improved accuracy at lower cost, human expert evaluations continue to uncover inaccuracies in clinical text generated by LLMs. However, fine-tuning smaller, open-source models offers a cost-effective alternative, delivering accuracy comparable to that of larger proprietary models.
2. LLM-as-Judge is Inadequate for Clinical Applications
While human evaluation remains the gold standard for accuracy, automated evaluation can be useful in augmenting clinician review, similar to LLMs augmenting other clinician workflows. Our findings reveal significant limitations in the medical domain, rendering this method inadequate for clinical use.
Factual inconsistencies in generated clinical text are particularly problematic due to their direct implications for patient well-being. Identifying and addressing these inaccuracies is a complex challenge that necessitates expert oversight and robust evaluation frameworks2 .
To assess the presence of inaccuracies in model generated text, we employ a systematic evaluation process to identify and categorize instances of fabricated or unsupported information. We studied popular general-purpose LLMs (GPT-4o, Claude-3.5-Sonnet) and fine-tuned, smaller models (specifically 8B parameter Llama models). For fine-tuned models, we look at fine-tuned medical models, and task specific fine-tuning. We also look at a zero-shot and 5-shot baselines for the 8B param model.
Our methodology follows the guidelines outlined by Hegselmann et. al. (2024) and the labeling protocols developed by Thomson et. al. (2021) for token-level error identification in medical documents. Our guidelines have been refined iteratively based on specific scenarios encountered during labeling.
Our annotators are expert physicians with MD degrees, working on the MedTator platform, where each BHC-AVS pair is reviewed by multiple experts who mark inaccuracies and categorize their types. To ensure accuracy and consistency, we employ a multi-labeling approach and prioritize inputs from annotators with a high degree of agreement.
The figure below shows a sample of our annotation workflow on the MedTator platform where the annotators are shown the BHC and corresponding AVS, and are tasked with marking spans containing inaccurate information along with the type of inaccuracy.

We distinguish between unsupported and contradicted facts. We also classify the inaccuracies into several categories such as unsupported condition, medication, procedure, location, name, time, number, word, other, incorrect fact, and contradicted fact following the categorization by Hegselmann et. al. (2024).
For each identified inaccuracy, we also gather remarks and rationales from the annotators explaining why the span was marked so.
Model accuracy has improved across generations, but even on this relatively straightforward task we observe several inaccuracies in the generated text.
Our evaluation results are presented in the following plot.

Model Evolution: The latest generation of models have achieved substantial improvements in accuracy, far surpassing their predecessors in processing and generating text specific to the medical domain.
Impact of Fine-Tuning: Fine-tuning on relevant data has a significant impact on model performance, aligning with results from Hegselmann et. al. (2024) on Llama-2-70B fine-tuned models. Our fine-tuned model, Log10-finetune-Llama-3.1-8B-Instruct, with ~8B parameters, demonstrates performance comparable to much larger models—such as GPT-4o and Claude-3.5-Sonnet—while operating at just a fraction of the cost (~50x lower inference cost). Notably, it achieves an accuracy rate of 0.5 inaccuracies per example, matching the results of these larger, more resource-intensive models.
Not all inaccuracies carry the same level of risk. By collecting fine-grained annotations, we can pinpoint specific areas of failure and evaluate the potential harm posed by different types of inaccuracies. This granular approach not only reveals the models’ tendencies to produce specific errors but also highlights the varying levels of risk associated with these inaccuracies in clinical contexts.
These annotations are organized into the eleven categories described earlier, each offering insights into the nature and severity of the errors. The figure below provides a detailed breakdown of the types of inaccuracies observed in our annotated summaries, helping to identify which categories pose the greatest risk to patient safety and clinical decision-making.
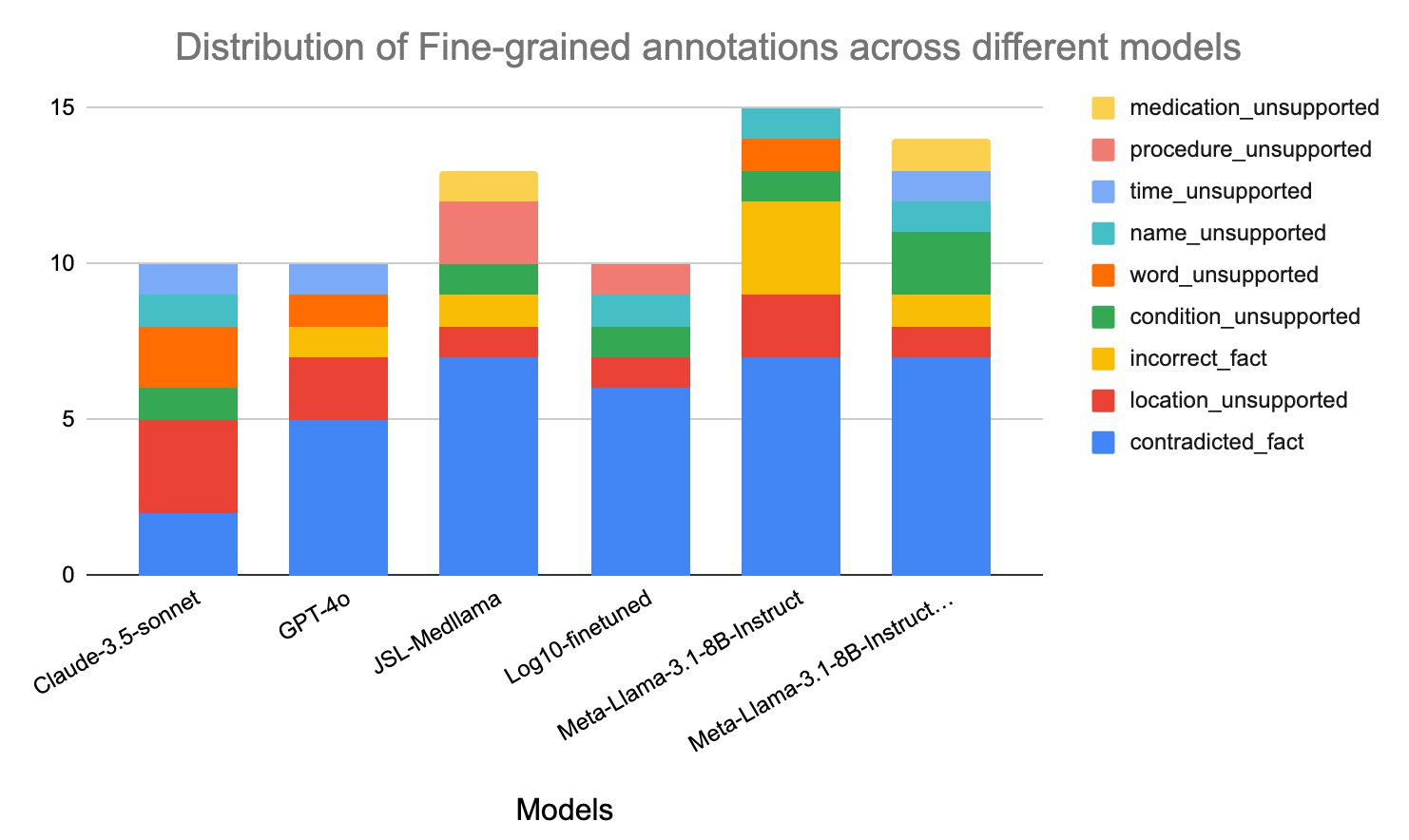
Examining the inaccuracies in the generated texts reveals some intriguing patterns across all models studied.
One recurring pattern was seen where the model has a tendency to infer or fill in information based on contextual cues. While this highlights the predictive capabilities of LLMs, it can lead to undesirable outcomes in a clinical setting where even the slightest inaccuracy can be catastrophic. For instance, in one case, a redacted reference to a patient's destination was filled in as “rehab,” likely inferred from the surrounding context. Such fabricated details not only risk misleading readers but also undermine trust in the generated text.
Another class of inaccuracies stems from the model's tendency to replace specific medical jargon with more general, commonly understood terms, often leading to inaccuracies.
For example, a patient’s MRI report indicating no “infarctions” was rephrased as showing no “damages.” Although "damage" might appear to be a simpler alternative, it is imprecise in this context. The term “damage” is broader in scope, and in this case, the MRI revealed other conditions that could also qualify as “damage,” leading to potential misinterpretation.
Similarly, the model substituted “metabolic acidosis” with “metabolic imbalance,” a generalization that diluted the specificity of the original term. These substitutions highlight the critical need for preserving medical accuracy, as even subtle changes in terminology can significantly impact clinical understanding and decision-making.
At a sample level, the results reflect the fine-grained inaccuracy annotations

Evaluating clinical text for clinical applications is time-intensive and difficult to scale, as it relies on expert review. Specialists often prioritize different details, leading to variability in assessments and making large-scale evaluation challenging. To address this, "LLM-as-judge" has been adopted, using language models as evaluators to provide scalable solutions for assessing accuracy across large datasets or repeated tasks.
While this approach significantly reduces the time and resources required for evaluation, it poses challenges in clinical workflows, where even small inaccuracies can have serious consequences.
To better understand how well LLMs perform in this role, we evaluated their ability to serve as accurate judges for clinical text. Using frontier models like GPT-4o, Claude-3.5-Sonnet, and Llama-3.1-405B, we assessed their generated summaries for factual accuracy, comparing their performance against the judgments of human experts.
Simply asking the LLM evaluator to assign a binary or pointwise score based on a given rubric for a BHC-AVS pair unsurprisingly yields unsatisfactory results. In nearly all of our evaluations using these scoring methods, we observe a tendency for evaluators to be excessively lenient, giving higher grades to the generated summaries than might be warranted. We also observe considerable variation in scores when using pointwise scoring, which can be partially mitigated by employing a carefully crafted rubric.
One hypothesis to explain this inconsistency is that a judge, operating within a continuous evaluation space, may lack a stable internal scoring mechanism.
This could lead to variability in judgments, as there are no clear, discrete thresholds for scoring, unlike more structured systems with well-defined criteria.
The approach that yields the best results is when we use a structured set of instructions that breaks the task into smaller, atomic sub-tasks. These sub-tasks involve separately extracting facts, assessing their significance, and performing compositional fact-checking along with asking the model to generate explanations or rationale (similar to CoT prompting) to identify any inaccuracies.
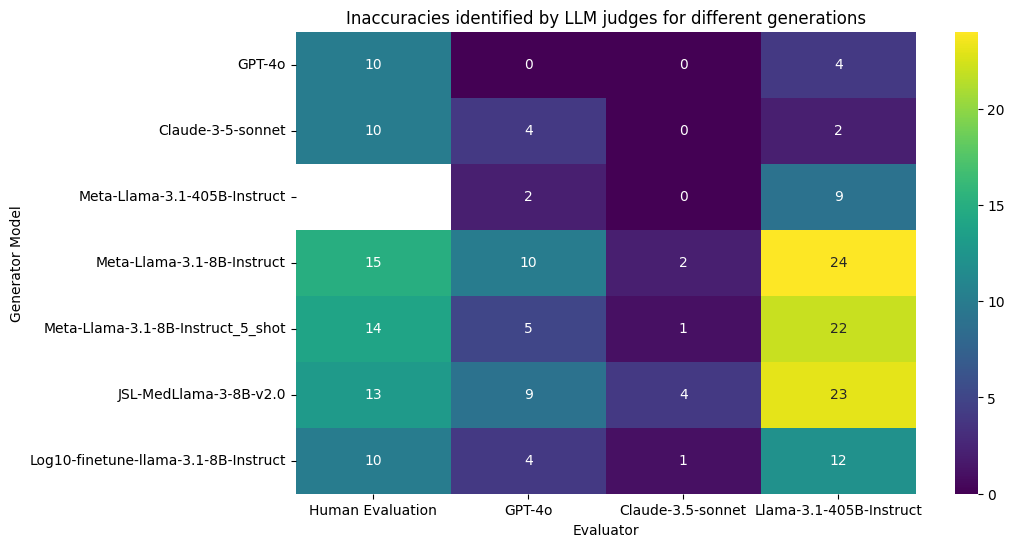
Self-preference bias - LLM models, when used as evaluators, often exhibit a bias towards preferring their own generated responses.
This self-preference bias has been observed in previous research, which highlights that LLMs tend to favor their own outputs when compared to human-generated content or other model outputs. We notice a strong self-preference bias for GPT-4o and Claude-3.5-Sonnet based evaluators as shown in figure above (i.e., 0 self-identified errors). In comparison, Llama-3.1-405B doesn’t show a strong self-preference bias. However, it seems to prefer the outputs of larger models over smaller models.Leniency - Some LLM evaluators are more lenient than others.
In our experiments, we observe that some evaluators show a natural tendency to be more lenient than others. For instance, Llama-3.1-405B-Instruct tends to be the most stringent, while Claude-3.5-Sonnet generally exhibits more leniency. While Claude-3.5-Sonnet's identification of facts and their importance often aligns with the strictest evaluator, it is more prone to overlooking minor inaccuracies. This leniency can be problematic in clinical contexts, where the threshold for accuracy is exceedingly high and even small discrepancies can have significant consequences.
In this blog, we explored the accuracy and efficiency of LLMs in healthcare, using an example task to highlight their potential and limitations. Even as models continue the trend of increasing capability, human expert evaluations still reveal errors in generated clinical text. Our study shows that fine-tuning smaller, open-source models can still deliver accuracy comparable to best-in-class proprietary models, all at a fraction of the cost.
Human oversight remains critical in clinical applications, yet automated approaches hold promise for augmenting review processes. We examined the "LLM-as-Judge" approach for evaluating clinical tasks and found significant limitations, including self-preference bias and varying levels of leniency, which make it unsuitable for high-stakes medical use. To address these shortcomings, innovative methods like Latent Space Readout, developed at Log10, offer a path forward. This advanced evaluation technique surpasses the accuracy of LLM-as-Judge by leveraging latent space analysis and insights from mechanistic interpretability.
Unlocking the full potential of LLMs in healthcare will require continued development of such innovative solutions. To further support research in this field, we plan to publish our annotated dataset on PhysioNet, enabling broader collaboration and innovation.
For deeper insights or questions about our research, reach out to us at ai@log10.io.
We’d love to hear from you!