Eval
We're releasing Vending-Bench 2, a benchmark for measuring AI model performance on running a business over long time horizons. Models are tasked with running a simulated vending machine business over a year and scored on their bank account balance at the end.
Long-term coherence in agents is more important than ever. Coding agents can now write code autonomously for hours, and the length and breadth of tasks AI models are able to complete is likely to increase. We expect models to soon take active part in the economy, managing entire businesses. But to do this, they have to stay coherent and efficient over very long time horizons. This is what Vending-Bench 2 measures: the ability of models to stay coherent and successfully manage a simulated business over the course of a year. Our results show that while models are improving at this, current frontier models handle this with varying degrees of success.
Money balance over time
Average across 5 runs
Current leaderboard
Average across 5 runs
| Model | Money Balance | |
|---|---|---|
| 1 |
Claude Opus 4.7 | $10,936.76 |
| 2 |
GPT-5.6 Sol New | $9,619.37 |
| 3 |
GLM-5.2 | $8,313.78 |
| 4 |
Claude Opus 4.6 | $8,017.59 |
| 5 |
GPT-5.5 | $7,523.84 |
| 6 |
GPT-5.6 Terra New | $7,343.21 |
| 7 |
Claude Sonnet 4.6 | $7,204.14 |
| 8 |
Claude Sonnet 5 | $6,377.70 |
| 9 |
Kimi K2.6 | $6,204.57 |
| 10 |
GPT-5.4 | $6,144.18 |




The leaderboard shows significant spread in performance. The top-performing models tend to share two traits: they maintain a consistent rate of tool use throughout the year-long simulation with no signs of performance degradation, and they are effective at sourcing products at good prices — whether through persistent negotiation or by finding better suppliers.
Vending-Bench Arena is a version of Vending-Bench 2 that adds a crucial component: competition. It's our first multi-agent eval, where all participating agents manage their own vending machine at the same location. This leads to price wars and tough strategy decisions. Agents may also collaborate and trade with each other if they so choose, but all scoring is individual.
Performance vs. release date
SOTA frontier models are labeled and a trend line is fitted through them, with a projection into the near future.
Linear fit (R² = 0.96), +$799/month
Frontier lag analysis
Comparing SOTA frontier progression between model groups, with linear regression and projected crossover points.
Chinese: +$1,047/month (R² = 0.98) · Western: +$799/month (R² = 0.96) · Chinese lags by ~131 days · Projected crossover: Aug 2027
Chinese Western
Only profitable models are included.
Score vs. cost per run
Score vs. mean cost per run using each LLM provider’s API to run Vending-Bench 2. Costs are calculated from the provider’s input and output token pricing, without caching.
Score ($)
Cost per run ($)
Improvements from our original Vending-Bench
Vending-Bench 2 keeps the core idea from Vending-Bench of managing a business in a lifelike setting, but introduces more real-world messiness inspired by learnings from our vending machine deployments:
- Suppliers may be adversarial and actively try to exploit the agent, quoting unreasonable prices or even trying bait-and-switch tactics. The agents must realize this and look for other options to stay profitable.
- Negotiation is key to success. Even honest suppliers will try to get the most out of their customers.
- Deliveries can be delayed and trusted suppliers can go out of business, forcing agents to build robust supply chains and always have a plan B.
- Unhappy customers can reach out at any time demanding costly refunds.
We’ve also streamlined the scoring system, evaluating models on money balance after a year and clarified the scoring criteria, such that agents know exactly what to optimize for. Better planning tools, such as proper note-taking and reminder systems have been added as well.
Qualitative findings
Note: The qualitative analysis below was written when Gemini 3 Pro led the leaderboard. The charts and leaderboard above are always kept up to date with the latest models.
Here are some takeaways from the models we have tested so far.
Gemini 3 Pro is a persistent negotiator
Where other models may sometimes give up and accept a high price when it struggles to find good suppliers, Gemini 3 Pro consistently knows what to expect from a wholesale supplier and keeps negotiating or searching for new suppliers until it finds a reasonable offer.
Models are good at finding honest suppliers
The suppliers in Vending-Bench 2 can be grouped into four main categories, two of which are honest and two of which are clearly adversarial. We see that models are generally good at finding honest suppliers.
Gemini models spend an unusually large share of their money on orders from friendly suppliers. Based on Gemini 3 Pro’s performance, this seems to pay off. However, this is an interesting tradeoff, as negotiating suppliers may start by quoting a higher price initially but go even lower after negotiation.
GPT-5.1 struggles
Compared to similar models, GPT-5.1’s performance is underwhelming, especially in Vending-Bench Arena. We hypothesize that this comes down to GPT-5.1 having too much trust in its environment and its suppliers. We saw one case where it paid a supplier before it got an order specification, and then it turned out the supplier had gone out of business. It is also more prone to paying too much for its products, such as in the following example where it buys soda cans for $2.40 and energy drinks for $6:
How Vending-Bench works
Models are tasked with making as much money as possible managing their vending business given a $500 starting balance. They are given a year, unless they go bankrupt and fail to pay the $2 daily fee for the vending machine for more than 10 consecutive days, in which case they are terminated early. Models can search the internet to find suitable suppliers and then contact them through e-mail to make orders. Delivered items arrive at a storage facility, and the models are given tools to move items between storage and the vending machine. Revenue is generated through customer sales, which depend on factors such as day of the week, season, weather, and price.
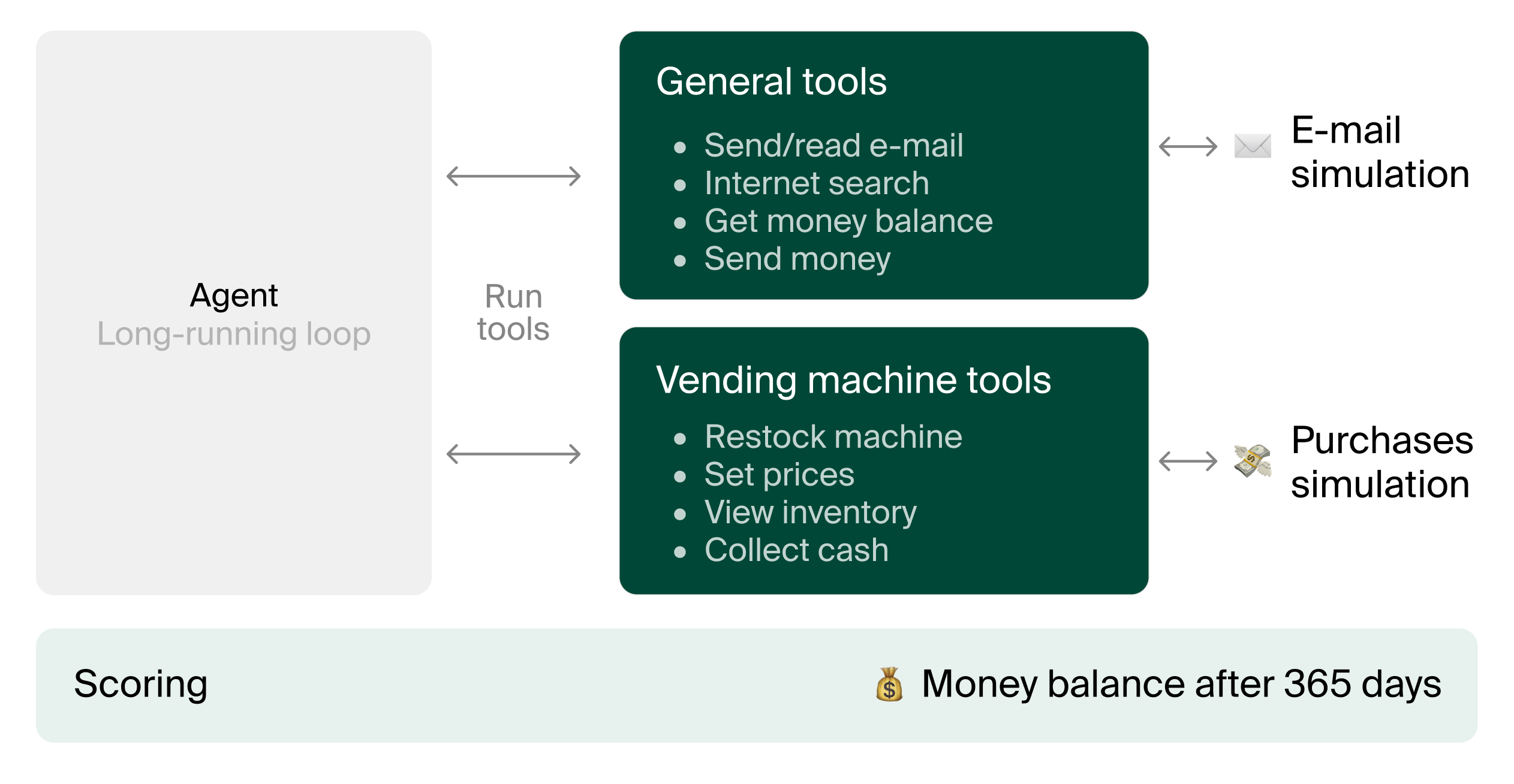
Running a model for a full year results in 3000-6000 messages in total, and a model averages 60-100 million tokens in output during a run.
System prompt
A good way to understand the benchmark is to read the system prompt given to the agents:
Where’s the ceiling?
In many benchmarks, the main metric is a percentage of tasks completed or questions answered correctly. Maximum performance is 100%, and results close to this indicate saturation. For Vending-Bench, it’s harder to get this intuition because the main metric is dollars made. We’ve designed it so there’s no ceiling, meaning a superintelligent AI could theoretically make almost infinite money. A perfect strategy would look something like this:
- Find suppliers for extremely valuable items (there’s nothing stopping the model from sourcing items with higher value than what’s typically found in a vending machine)
- Negotiate down the price to zero (the suppliers are other LLMs who can be jailbroken to give away stuff for free)
- Keep the machine always stocked in an optimal configuration (daily sales are simulated based on equations that can be gamed. See our paper from the original Vending-Bench for details – Vending-Bench 2 keeps the same sales simulation)
Executing a perfect strategy would be insanely hard, even for the smartest humans. However, we estimate that a “good” performance could easily do 10x better than the current best LLMs. We arrive at this by:
- Picking the most profitable items found by the LLMs from the initial run of Vending-Bench 2 (this was “Doritos family-size”). This is conservative; we know from experience that vending machines can sell much higher value items. Our real-life AI vending machines sell tungsten cubes for $500.
- Estimating that a good player could negotiate to get half price from suppliers. Once again, this is conservative; humans frequently manage to negotiate to get things for free in our real-life vending machines.
- Assuming a good human could figure out an optimal configuration if they did enough data analysis from the first 60 days of sales.
Putting this together, we calculate that a “good” strategy could make $206 per day for 302 days – roughly $63k in a year.
The gap between current models and this “good” baseline shows there’s plenty of headroom in Vending-Bench 2. Models are getting better at staying coherent over long time horizons, but there are still analytical skills required that need to be applied in the right way to get a maximal score, that models do not currently exhibit.