![]()
AlphaOne
 University of Illinois Urbana-Champaign
University of Illinois Urbana-Champaign
![]() UC Berkeley
UC Berkeley
†Equal contribution
EMNLP 2025 Main
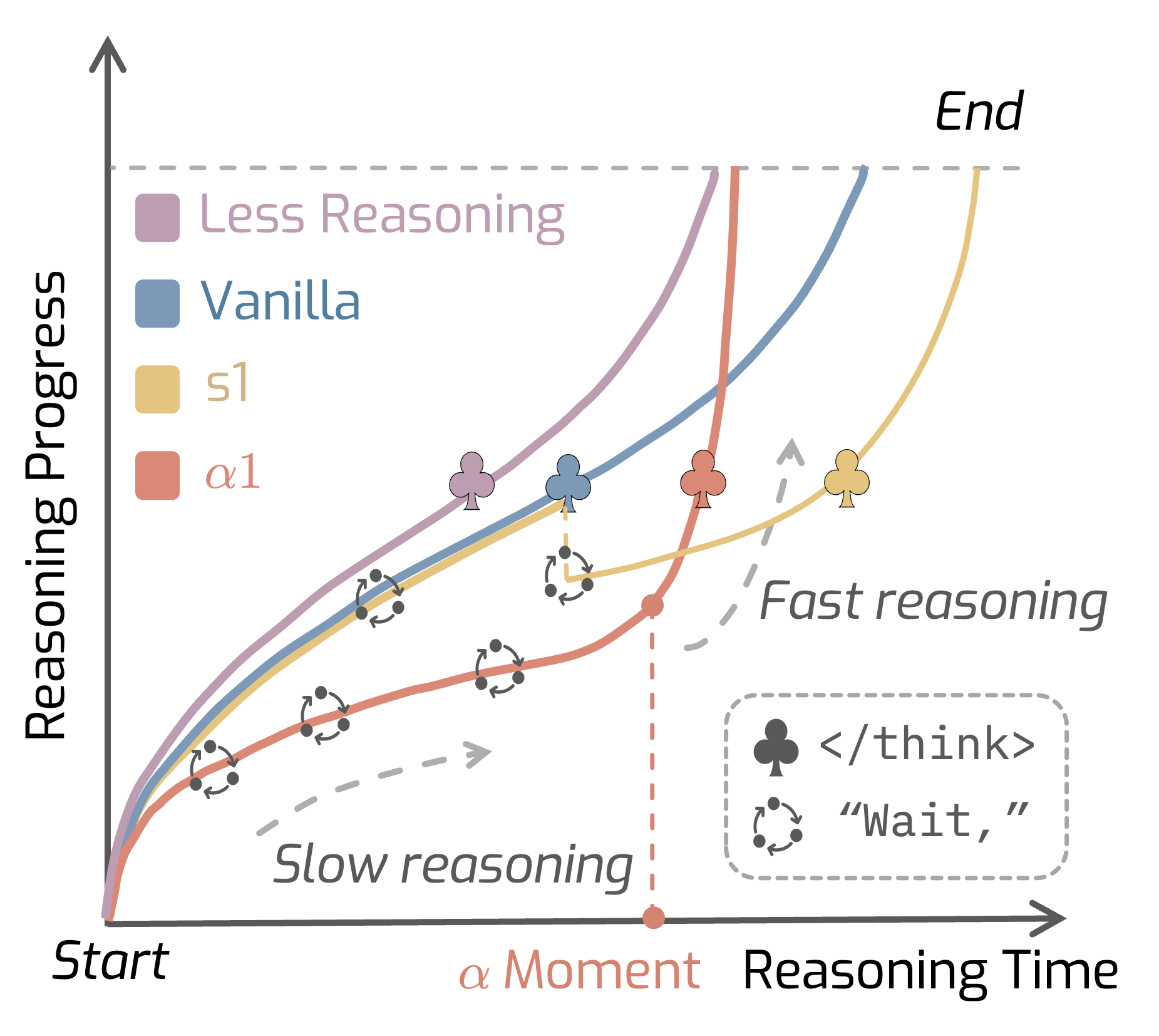

Overview
Key Takeaways
We present some insightful findings from evaluating three different ![]() LRMs, ranging from 1.5B to 32B across six reasoning benchmarks, including math, code generation, and scientific problem reasoning.
LRMs, ranging from 1.5B to 32B across six reasoning benchmarks, including math, code generation, and scientific problem reasoning.
💡 Slow thinking first, then fast thinking, leads to better LRM reasoning.
💡 Slow thinking can bring efficient test-time scaling.
💡 Slow thinking transitioning in high frequency is helpful.
Experiments
Case Study
Success Examples
Failure Examples
BibTeX
@article{AlphaOne25,
title={AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time},
author={Zhang, Junyu and Dong, Runpei and Wang, Han and Ning, Xuying and Geng, Haoran and Li, Peihao and He, Xialin and Bai, Yutong and Malik, Jitendra and Gupta, Saurabh and Zhang, Huan},
journal={arXiv preprint arXiv:2505.24863},
year={2025}
}