When people talk about “space-efficient hash tables”, they are usually talking about the following type of guarantee: If we are storing 



But, what if I told you we can do better? In fact, it’s possible to construct a hash table that uses fewer than 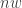
Techniques for building extremely tiny hash tables have been known to theoreticians for decades. But how hard is it to build one in the real world? Not that hard at all, it turns out.
In this post, I’ll show you how to build a very simple extremely tiny hash table for 32-bit keys.
The Construction. Since our keys are 32-bits, we can write each key 
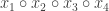


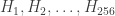
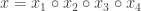
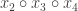
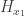
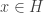
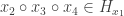
Finally, each 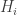
Analysis. The trick here is that, even though
How much space do the 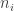
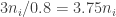
The different sub-hash-tables 

Finally, we need to account for the metadata of the 256 sub-hash-tables. All things considered, in my implementation, this uses less than 6000 bytes. So our total space is at most 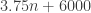
For any 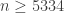
Real-World Performance. So is this data structure fast? Well, it’s not blazingly fast. But it’s not embarrassingly slow either.
On my laptop, the time to first insert ten million keys and then do twenty million queries (half positive, half negative) is 3.7 seconds. If we instead use the C++ std::unordered_set (configured to use the same hash function as our original hash table), the same sequence of operations takes 7.3 seconds.
So we’re faster than the C++ hash table, but at the same time, that’s not a Herculean feat. (And it’s also not a fair comparison since, of course, the C++ hash table supports much more functionality). But it is a proof of concept: you can build extremely tiny hash tables in the real world.
My code is available at https://github.com/williamkuszmaul/tinyhash.