“Just use an LLM.”
That was my advice to a colleague recently when they asked about a classification problem. Who fine-tunes BERT anymore? Haven’t decoder models eaten the entire NLP landscape?
The look I got back was… skeptical. And it stuck with me.
I’ve been deep in LLM-land for a few years now. When your daily driver can architect systems, write production code, and reason through problems better than most junior devs, you start reaching for it reflexively. Maybe my traditional ML instincts had atrophied.
So I decided to actually test my assumptions instead of just vibing on them.
I ran 32 experiments pitting small instruction-tuned LLMs against good old BERT and DeBERTa. I figured I’d just be confirming what I already believed, that these new decoder models would obviously crush the ancient encoders.
I was wrong.
The results across Gemma 2B, Qwen 0.5B/1.5B, BERT-base, and DeBERTa-v3 were… not what I expected. If you’re trying to decide between these approaches for classification, you might want to actually measure things instead of assuming the newer model is better.

All the code is on GitHub if you want to run your own experiments.
Experiment Setup
What I Tested
BERT Family (Fine-tuned)
- BERT-base-uncased (110M parameters)
- DeBERTa-v3-base (184M parameters)
Small LLMs
- Qwen2-0.5B-Instruct
- Qwen2.5-1.5B-Instruct
- Gemma-2-2B-it
For the LLMs, I tried two approaches:
- Zero-shot - Just prompt engineering, no training
- Few-shot (k=5) - Include 5 examples in the prompt
Tasks
Four classification benchmarks ranging from easy sentiment to adversarial NLI:
| Task | Type | Labels | Difficulty |
|---|---|---|---|
| SST-2 | Sentiment | 2 | Easy |
| RTE | Textual Entailment | 2 | Medium |
| BoolQ | Yes/No QA | 2 | Medium |
| ANLI (R1) | Adversarial NLI | 3 | Hard |
Methodology
For anyone who wants to reproduce this or understand what “fine-tuned” and “zero-shot” actually mean here:
BERT/DeBERTa Fine-tuning:
- Standard HuggingFace Trainer with AdamW optimizer
- Learning rate: 2e-5, batch size: 32, epochs: 3
- Max sequence length: 128 tokens
- Evaluation on validation split (GLUE test sets don’t have public labels)
LLM Zero-shot:
- Greedy decoding (temperature=0.0) for deterministic outputs
- Task-specific prompts asking for single-word classification labels
- No examples in context—just instructions and the input text
LLM Few-shot (k=5):
- Same as zero-shot, but with 5 labeled examples prepended to each prompt
- Examples randomly sampled from training set (stratified by class)
All experiments used a fixed random seed (99) for reproducibility. Evaluation metrics are accuracy on the validation split. Hardware: RunPod instance with RTX A4500 (20GB VRAM), 20GB RAM, 5 vCPU.
 I’d forgotten how pretty text-only land can be. When you spend most of your time in IDEs and notebooks, SSH-ing into a headless GPU box and watching nvitop do its thing feels almost meditative.
I’d forgotten how pretty text-only land can be. When you spend most of your time in IDEs and notebooks, SSH-ing into a headless GPU box and watching nvitop do its thing feels almost meditative.
Results
Let’s dive into what actually happened:
| Model | Method | SST-2 | RTE | BoolQ | ANLI |
|---|---|---|---|---|---|
| DeBERTa-v3 | Fine-tuned | 94.8% | 80.9% | 82.6% | 47.4% |
| BERT-base | Fine-tuned | 91.5% | 61.0% | 71.5% | 35.3% |
| Qwen2.5-1.5B | Zero-shot | 93.8% | 78.7% | 74.6% | 40.8% |
| Qwen2.5-1.5B | Few-shot | 89.0% | 53.4% | 73.6% | 45.0% |
| Gemma-2-2B | Zero-shot | 90.0% | 61.4% | 80.9% | 36.1% |
| Gemma-2-2B | Few-shot | 86.5% | 73.6% | 81.5% | 47.8% |
| Qwen2-0.5B | Zero-shot | 87.6% | 53.1% | 61.8% | 33.2% |
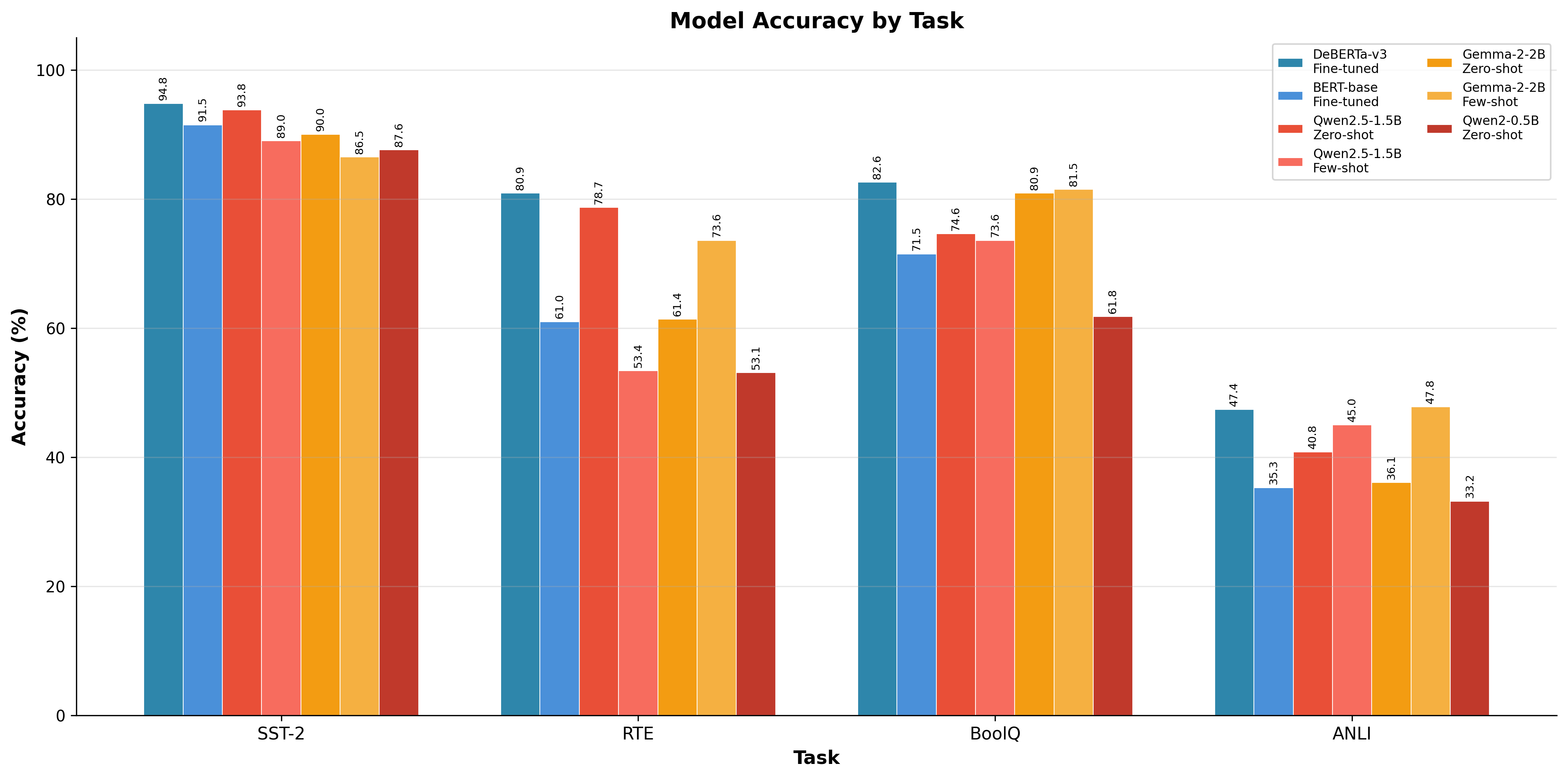
DeBERTa-v3 wins most tasks—but not all
DeBERTa hit 94.8% on SST-2, 80.9% on RTE, and 82.6% on BoolQ. For standard classification with decent training data, the fine-tuned encoders still dominate.
On ANLI—the hardest benchmark, specifically designed to fool models—Gemma few-shot actually beats DeBERTa (47.8% vs 47.4%). It’s a narrow win, but it’s a win on the task that matters most for robustness.
Zero-shot LLMs actually beat BERT-base
The LLMs aren’t losing to BERT—they’re losing to DeBERTa. Qwen2.5-1.5B zero-shot hit 93.8% on SST-2, beating BERT-base’s 91.5%. Same story on RTE (78.7% vs 61.0%) and BoolQ (Gemma’s 80.9% vs BERT’s 71.5%). For models running purely on prompts with zero training? I’m calling it a win.
Few-shot is a mixed bag
Adding examples to the prompt doesn’t always help.
On RTE, Qwen2.5-1.5B went from 78.7% zero-shot down to 53.4% with few-shot. On SST-2, it dropped from 93.8% to 89.0%. But on ANLI, few-shot helped significantly—Gemma jumped from 36.1% to 47.8%, enough to beat DeBERTa.
Few-shot helps on harder tasks where examples demonstrate the thought process, but can confuse models on simpler pattern matching tasks where they already “get it.” Sometimes examples add noise instead of signal.
BERT Goes Brrrr
Okay, so the accuracy gap isn’t huge. Maybe I could still justify using an LLM?
Then I looked at throughput:
| Model | Method | Throughput (samples/s) | Latency (ms/sample) |
|---|---|---|---|
| BERT-base | Fine-tuned | 277 | 3.6 |
| DeBERTa-v3 | Fine-tuned | 232 | 4.3 |
| Qwen2-0.5B | Zero-shot | 17.5 | 57 |
| Qwen2.5-1.5B | Zero-shot | 12.3 | 81 |
| Gemma-2-2B | Zero-shot | 11.6 | 86 |
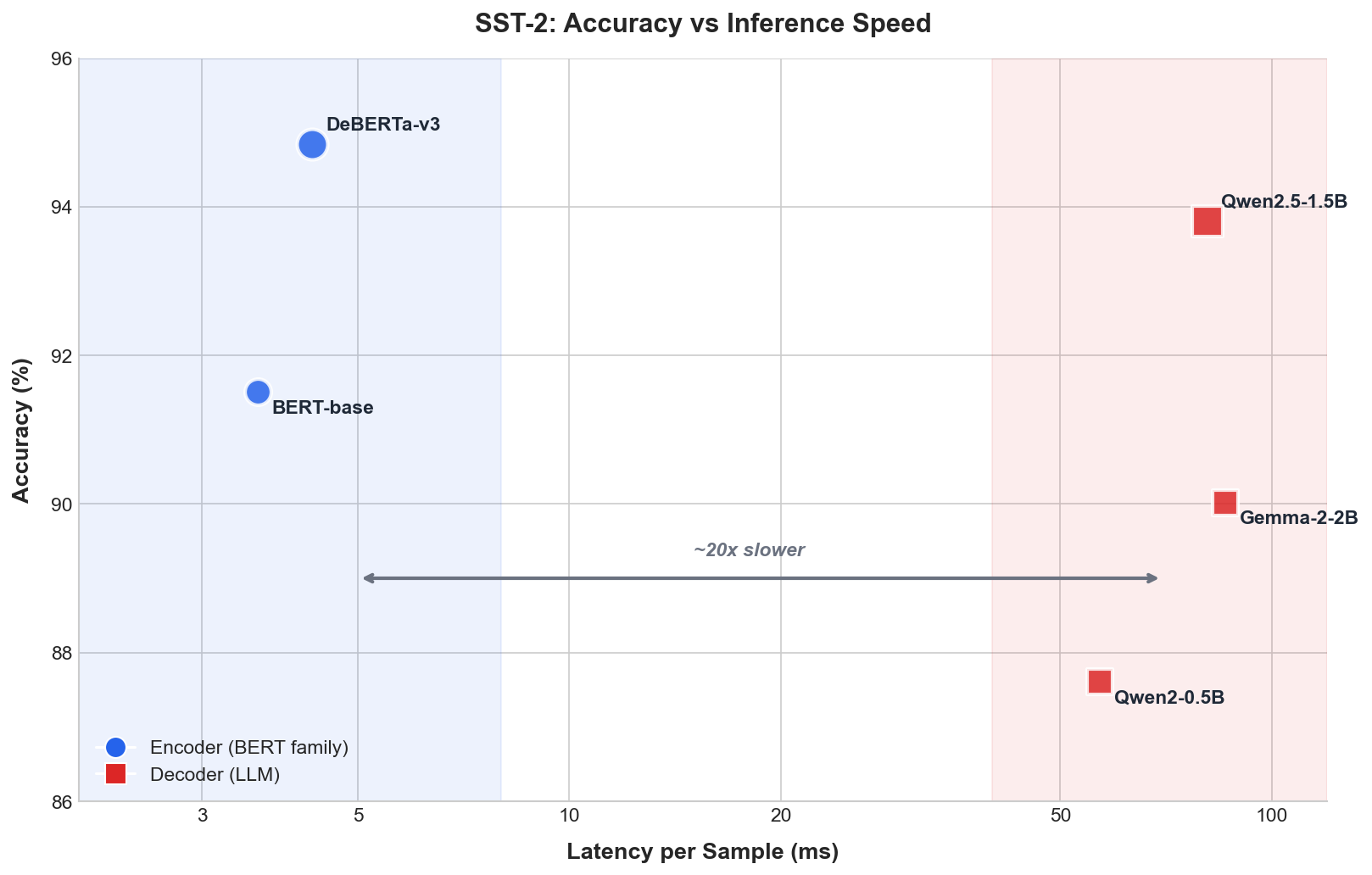
BERT is ~20x faster.
BERT processes 277 samples per second. Gemma-2-2B manages 12. If you’re classifying a million documents, that’s one hour vs a full day.
Encoders process the whole sequence in one forward pass. Decoders generate tokens autoregressively, even just to output “positive” or “negative”.
Note on LLM latency: These numbers use
max_length=256for tokenization. When I bumped it tomax_length=2048, latency jumped 8x—from 57ms to 445ms per sample for Qwen-0.5B. Context window scales roughly linearly with inference time. For short classification tasks, keep it short or make it dynamic.
Try It Yourself
These models struggled on nuanced reviews. Can you do better? Try classifying some of the trickiest examples from my experiments:
Challenge Complete!
You: | Models:
When LLMs Make Sense
Despite the efficiency gap, there are cases where small LLMs are the right choice:
Zero Training Data
If you have no labeled data, LLMs win by default. Zero-shot Qwen2.5-1.5B at 93.8% on SST-2 is production-ready without a single training example. You can’t fine-tune BERT with zero examples.
Rapidly Changing Categories
If your categories change frequently (new product types, emerging topics), re-prompting an LLM takes seconds. Re-training BERT requires new labeled data, training time, validation, deployment. The iteration cycle matters.
Explanations with Predictions
LLMs can provide reasoning: “This review is negative because the customer mentions ‘defective product’ and ‘waste of money.’” BERT gives you a probability. Sometimes you need the story, not just the number.
Low Volume
If you’re processing 100 support tickets a day, throughput doesn’t matter. The 20x speed difference is irrelevant when you’re not hitting any resource constraints.
When BERT Still Wins
High-Volume Production Systems
If you’re classifying millions of items daily, BERT’s 20x throughput advantage matters. That’s a job finishing in an hour vs. running all day.
Well-Defined, Stable Tasks
Sentiment analysis. Spam detection. Topic classification. If your task definition hasn’t changed since 2019, fine-tuned BERT is proven and stable. No need to fix what isn’t broken.
You Have Training Data
With a few thousand labeled examples, fine-tuned DeBERTa will beat small LLMs. It’s a dedicated specialist vs. a generalist. Specialization still works.
Latency Matters
Real-time classification in a user-facing app where every millisecond counts? BERT’s parallel processing wins. LLMs can’t compete on speed.
Limitations
Before you @ me on Twitter—yes, I know this isn’t the final word. Some caveats:
I only tested small LLMs. Kept everything under 2B parameters to fit comfortably on a 20GB GPU. Bigger models like Llama-3-8B or Qwen-7B would probably do better, but then the efficiency comparison becomes even more lopsided. You’re not beating BERT’s throughput with a 7B model.
Generic prompts. I used straightforward prompts without heavy optimization. Task-specific prompt engineering could boost LLM performance. DSPy-style optimization would probably help too—but that’s another blog post.
Four benchmarks isn’t everything. There are plenty of classification scenarios I didn’t test. Your domain might be different. Measure, don’t assume.
Conclusion
So, can small LLMs beat BERT at classification?
Sometimes, and on the hardest task, they actually do. Gemma few-shot edges out DeBERTa on adversarial NLI, the benchmark specifically designed to break models.
DeBERTa-v3 still wins 3 out of 4 tasks when you have training data. And BERT’s efficiency advantage is real—~20x faster throughput matters when you’re processing millions of documents and paying for compute.
Zero-shot LLMs aren’t just a parlor trick either. Qwen2.5-1.5B hits 93.8% on sentiment with zero training examples—that’s production-ready without a single label. For cold-start problems, rapidly changing domains, or when you need explanations alongside predictions, they genuinely work.
Hopefully this gives some actual data points for making that call instead of just following the hype cycle.
All the code is on GitHub. Go run your own experiments.
Surely I’ve made some embarrassing mistakes here. Don’t just tell me—tell everyone! Share this post on your favorite social media with your corrections :)