In December 2024, James Duncan agreed to join a D&D-style game with some friends. He was in his forties and
hadn’t joined a role-playing game for a long time. Given he grew up coding, he decided he wasn’t going to track his character on paper and instead would build a quick web app.
“How hard could it be?” he thought. Famous last words.
James had good reason to assume this would be straightforward. As an experienced engineer, he had started out by building for the web in 1995. In the late 2000s, he had a part to play in bringing Node.js to the world. He knew this terrain and although it had been a while since he tapped at a keyboard in anger, he expected to find it had improved since he last did.
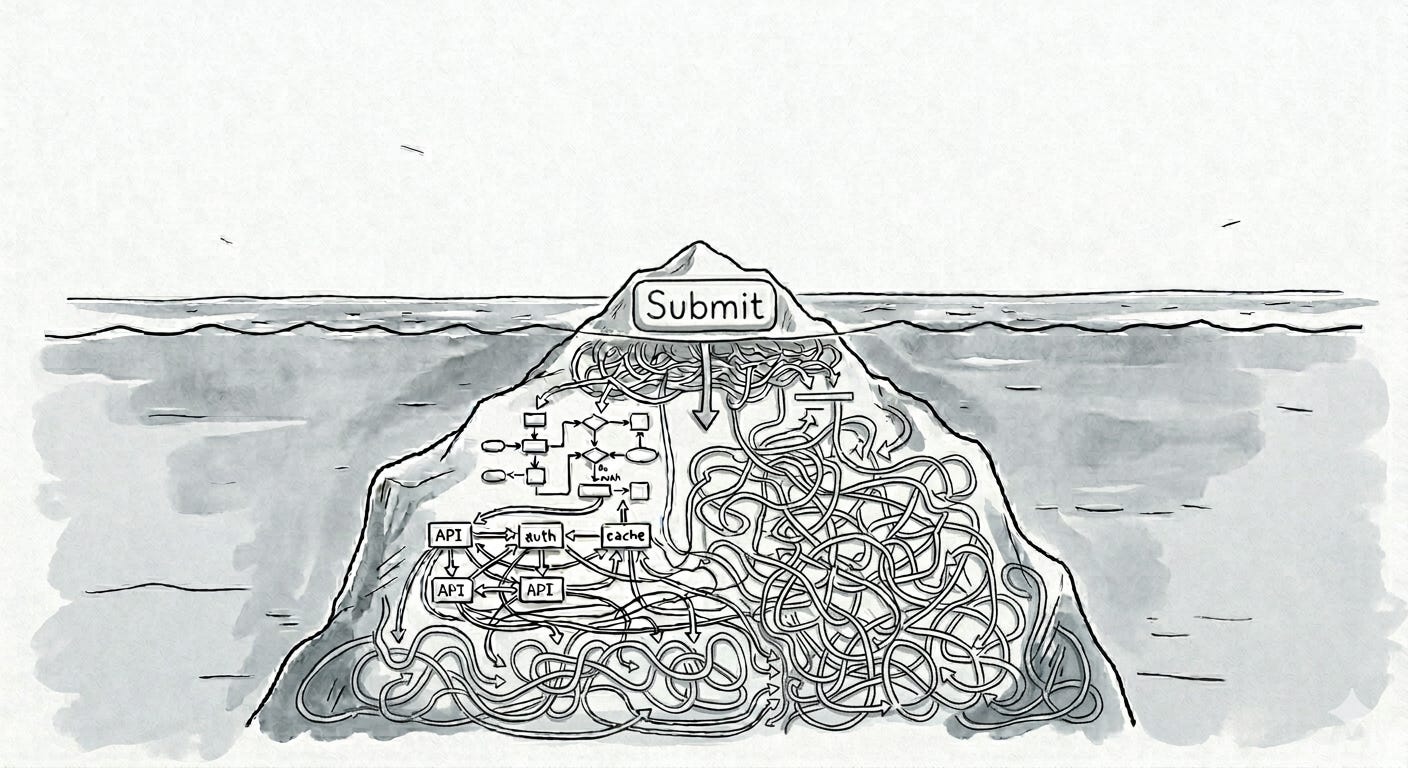
The opposite was true – building a quick web app was simply not possible without a serious time commitment. As he went down the rabbit hole, he found a web that had become, in his telling, impossible to reason about. You couldn’t open a page, read what it was doing, and understand it. What was once a self-describing document that laid out its structure, content, and behavior in a single readable artifact has been replaced by a hollow shell fed by APIs.
James spent nine months in what he describes as archaeology and, given his part in bringing Node.js to the world, no small amount of guilt. He read & re-read the documents that define how the web works and went back through the specifications that browsers and servers are built on. He was trying to understand not just why the web had ended up this way, but whether there was anything to be done about it.
There was a moment, not that long ago, when you could view the source code of a webpage and understand what it did. The document described itself. Interface and data were the same artifact. If you wanted to know what a page was doing, you read it.
As web apps became more sophisticated, developers needed to build something the protocol wasn’t designed to express: real-time updates, complex state, rich interactions. Rather than extending the protocol, they built abstractions on top of it: JSON APIs, client-side rendering, virtual DOMs, state management layers. Each solved a real problem. Each also moved further from anything HTTP could describe natively. The complexity accumulated in the gap between what the protocol could express and what the application needed to do.
The result: a modern webpage is typically a hollow display shell. It shows you things, but it doesn’t contain them. The actual data lives on a server somewhere, fetched and loaded into the page at runtime. What you see in your browser is a rendered output, not a document. You could look at the source of a 1999 webpage and understand what it was doing. You can look at the source of most pages today and find scaffolding that means nothing without the server behind it and the execution that fills it in.
The problem doesn’t stop at the browser. It runs through the whole stack. Change a rule about how user data gets validated, and another part of the system that uses that rule behaves differently without warning. Update the logic that calculates a price, and three other pieces of code will now produce different results in ways nobody has documented. A change stopped having a knowable blast radius. You push something and then wait to find out what else you’ve broken.
This is the environment that developers have learned to work in. It’s also the environment that AI agents inherited.
In 2022, researchers at Stanford and other institutions built SWE-bench: a benchmark designed to measure how well LLM agents could fix bugs from real GitHub repositories.
Models that successfully resolved issues rarely edited more than a single file. The actual human-written fixes for solving the bugs in the study averaged 1.7 files. Agents consistently produced shorter, more localized fixes than the real solution required. Multi-file coordination was where they broke down.
By 2025, frontier models score 77–81% on standard SWE-bench tasks - but those are largely single-file, well-specified problems. SWE-bench Pro, designed for enterprise-grade, multi-file fixes, sees even top models fall below 25%. On private codebases the models have never seen, scores drop further, to 15–18%.
A model that could hold an entire codebase in memory simultaneously would fare better. But the structure of the software makes the problem worse than it needs to be, regardless of how much context is available.
Daniel Jackson at MIT CSAIL has spent the better part of twenty years approaching this problem from the formal methods direction. His 2021 book, The Essence of Software, argues that software should be understood as collections of independent concepts: bounded units of behavior, each with a clear purpose, minimal dependencies, and a direct mapping to what the user actually experiences. The problem is that most software isn’t built that way.
Take a simple “like” feature in a blogging app. It involves a user and an article, so it doesn’t fit cleanly into either the user module or the article module. It gets split across files, each piece owned by a different part of the codebase, and the behavior that the user experiences as a single coherent action becomes invisible in the code. When concepts bleed into each other like this, the system becomes illegible. You can no longer tell, by reading it, what it does.
His November 2025 paper with Eagon Meng, “What You See Is What It Does,” names the property directly. A well-structured system should exhibit correspondence between its visible behavior and its code structure. A declarative synchronization layer makes that correspondence explicit, rather than burying it in event chains scattered across files and services.
The SWE-bench literature and Jackson’s work arrive at the same constraint from opposite ends. The benchmark researchers found empirically that agents fail when changes span multiple files. Jackson identified structurally why: most software violates correspondence and locality not as an exception, but as a matter of course. The properties that make code readable to humans are the same properties that make it legible to agents. The two problems were always the same problem.
The industry produced two responses to these agent struggles.
The first is MCP: build a parallel, machine-readable interface alongside the human one. Describe your API in a format agents can consume. Create a second surface for machines to navigate. This approach reminds James of the early 2000s, when web developers were always struggling with the fact that Internet Explorer had a completely different set of affordances from Mozilla. “It’s building an alternate user interface only for machines as well as humans.” MCP tells an agent what it can do, not what the software is trying to do.
The second response is headless browsers and computer vision: execute the page, observe it, and act. James described this as “the equivalent of a toddler with an iPad, jabbing its fingers on it and being happy when it makes flashing lights and nice sounds.” That was more true two years ago than it is today, as computer use agents have improved substantially. But the underlying problem hasn’t changed. The agent is still inferring structure from appearance, guessing at what elements mean from how they look. It doesn’t know whether the blue button submits a form or empties a cart. It finds out by clicking.
Both approaches assume the software stays as it is. They are navigation aids for an illegible system, not a solution to the illegibility itself.
What James eventually found, deep in the 1997 HTTP specification, was a footnote.
When your browser loads a webpage, it’s making an HTTP request, asking a server to send it something. The Range header, introduced in 1997, was designed to let you ask for only part of what a server had. Instead of downloading an entire file, you could ask for a chunk, such as bytes 2,786 to 11,492. Useful for things like resuming an interrupted download halfway through a large file.
The range header was sort of what he wanted: ask the server for the chunk of bytes containing his character’s health, update it, and write it back. But byte ranges for a dynamic webpage wouldn’t work. Web pages change, so byte 2,786 today might be in the middle of a username, and tomorrow in the middle of something else.
But rereading the spec, James noticed something that had apparently gone unnoticed for twenty-eight years: bytes are described as merely one unit that could be defined. Others could be. None had been.
If you go to the IANA range unit registry today, there is one entry. Bytes.
What if you could define a range unit that addressed elements on a page by what they are, rather than where they happen to sit in a file? An addressing scheme that holds regardless of what else on the page has changed. Not “bytes 2,786 to 11,492” but “the hit points for this character.”
He built a server that implemented exactly that, then a demo to show what it unlocked. A mock mail application and a simple to-do list. He gave Claude a draft technical specification of how the system worked. “Hey, Claude,” he told it, “read my mailbox and apply the techniques in the specification to update my to-do list with anything you find.” The agent did it without hand-holding. No special tool calls, no parallel interface, no headless browser clicking at things it couldn’t read. The document described its own structure, its capabilities, its authorization rules. The agent read the page. He is building this into a product called Pagelove, which is currently in early access.
“The capabilities reveal themselves to the AI agent,” James said, “in a way they don’t through a traditional UI shell.”
Adaptive software changes behavior in response to what users actually need by editing the code. To do that without breaking the codebase requires legibility.
On the web, and all the way down: a backend function with a knowable blast radius, an API contract that describes what touches it, a UI component that corresponds to a bounded piece of logic.
Legibility isn’t a new idea. Engineers have always known that systems with fewer dependencies are easier to reason about, but over the past twenty years, we’ve optimized for different goals. Microservices, APIs, and abstraction layers made systems easier to operate and divide between teams. A side effect is that understanding the system end-to-end became harder.
Agents depend on access, context, and visibility and optimizing for agents requires a different approach than optimizing for teams of human engineers.
Most of the industry is building agents that fit within the current software paradigm. A smaller group of researchers and a handful of newer startups are building software designed from the ground up to be understood by agents.
A system where what you see is what it does, and what you change is all that changes.
That might be exactly what adaptive software requires.
The blank space in the IANA registry has been there for twenty-eight years. It may not be blank much longer.