We recently ran our first AI for Founders Workshop. We didn’t demo tools. We shared the mental models and real-world systems that have made our own team measurably faster over the past 18 months. Here’s what we covered.
Every founder we talk with has tried ChatGPT, Claude, Gemini, Copilot, Codex. The edge isn’t access to AI, it’s how deeply teams weave it into their daily workflows.
There are five layers of AI to unlock, and most people are stuck on layer one: type a prompt, get a response.
Layer one is basic text generation, where models predict the next token based on training data, is powerful for drafts, summaries, and translation. But the model doesn’t know your mission, your team, your customers, or what happened in last Tuesday’s standup. And it will confidently make things up when it doesn’t know.
Layer two is retrieval. With retrieval, the model pulls from your actual documents, databases, and knowledge bases before responding. This is how you get AI that knows your product and your processes. Most “AI for enterprise” tools today are retrieval under the hood.
Layer three: tool use. This is the jump from “AI that talks” to “AI that does.” Models can now search the web, run code, query databases, and call APIs. The infrastructure breakthrough here is MCP, the Model Context Protocol that Anthropic open-sourced in late 2024. Think of it as USB-C for AI: one standard that lets any model connect to any tool. OpenAI and Google have adopted it, too. There are hundreds of integrations now, from Slack and GitHub to Notion, calendars, and CRMs.
Layer four is reasoning, and this is where the frontier capabilities seemed to move fastest. Every major provider now ships dedicated reasoning modes. GPT-5.4 Thinking has deliberative reasoning as a structured process before generating a response. Gemini 3.1 launched a Deep Think tier that more than doubled its predecessor’s reasoning benchmarks. Claude’s latest models use Adaptive Thinking, which automatically calibrates reasoning depth to the complexity of the problem. This means AI can now handle problems that require genuine multi-step thinking, from financial modeling and architectural decisions to legal analysis and scientific research, not just generating a first draft for you to edit.
Layer five is the execution layer on top of all this, where everything compounds: agentic systems. Multi-step thinking to multi-step planning and execution. Give an agent a goal, and it figures out the steps. What data to retrieve, which tools to use, how to reason through decisions, when to loop back and try again. No human in the loop.
This isn’t theoretical. Every team we work with is now asking the same thing: which workflows do we hand off first?
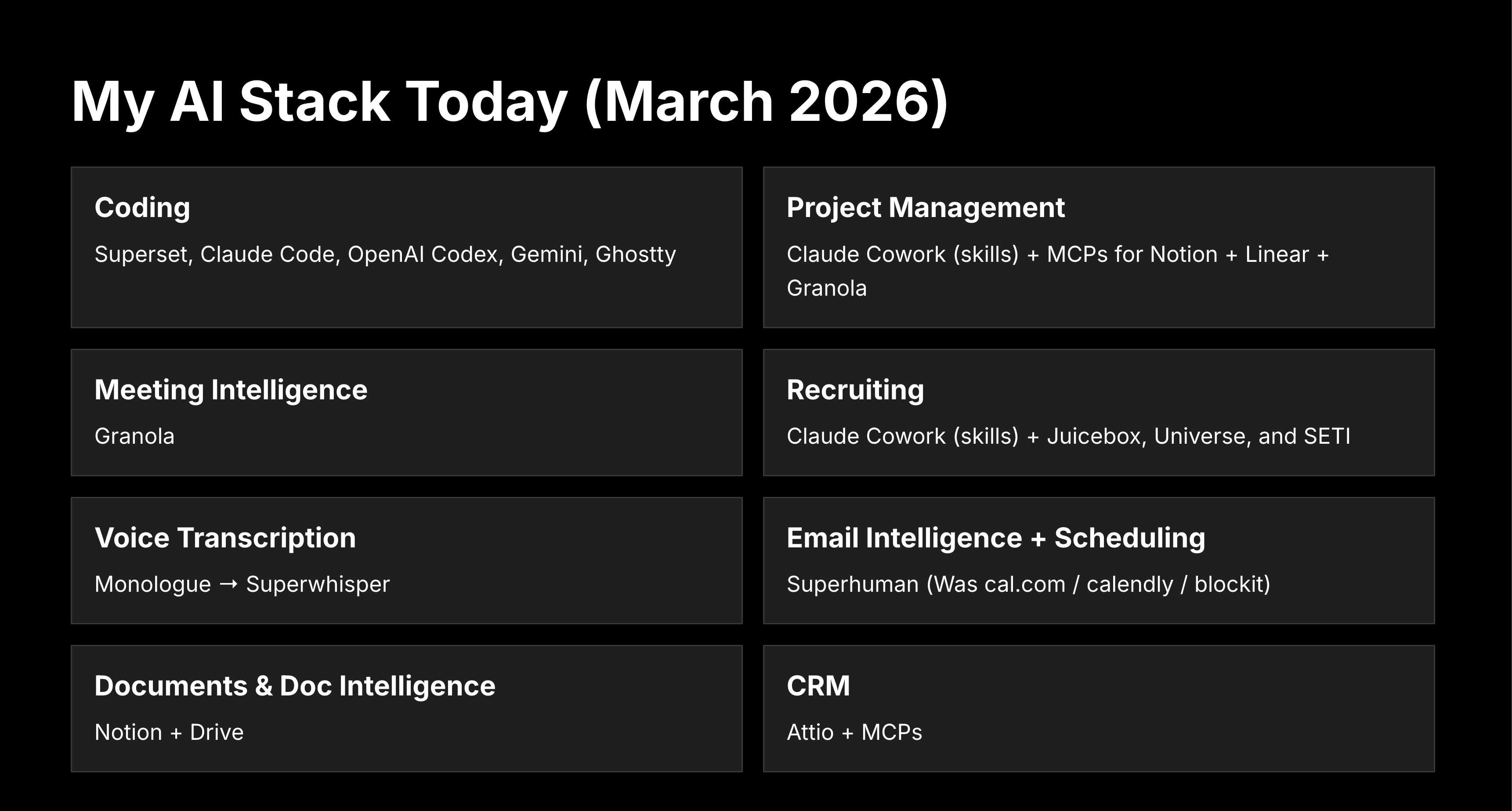
Here’s the shift that caught even experienced engineering teams off guard: software is disposable now.
You can build something useful in an afternoon and rebuild it from scratch tomorrow if the requirements change. The time horizon compressed from weeks and months to hours and days. Knowledge work is following the same curve, with entire business functions being shipped as prompts and plugins - from recruiting to operations to legal review.
We haven’t hand-written more than a few lines of code in months on our platform team. The bottleneck flipped. Most of the time now goes into reviewing what the AI produced, not producing it ourselves. That’s a weird adjustment, honestly, going from “I build things” to “I evaluate things that got built for me,” but the output difference is hard to argue with.
The cost of AI-generated software is less than $10/hr and dropping fast. Analysis, research, idea generation, knowledge work generally: all being driven toward zero at the same rate. Quality still matters enormously, but the scarce resource shifted from production to judgment.
What does this mean practically? CEOs should be building prototypes. Scientists should be building dashboards. Everyone on your team should be building with AI, regardless of their role.
If you invested time in prompt engineering over the past two years, the models caught up. The frontier models all interpret natural language well enough that elaborate templates and magic words are unnecessary. Even sloppy, terse prompts get great results now. The skill that matters is knowing what you want before you start typing.
If you can explain something to a smart coworker, you can explain it to AI. We stopped teaching prompt engineering on our team and started teaching people to think clearly about what they’re trying to accomplish. That turned out to be the harder skill, and the more valuable one.
Model selection is similar. Pick one, go deep, measure results. The founders who are 10x more effective didn’t find the “best” model. They went deep with one and built it into every workflow. The founders we’ve seen get the most out of AI all did the same thing: picked one tool and wove it into everything.
Frontier models are great at solving hard problems. But most of the work that bogs teams down isn’t hard. It’s repetitive. Filtering a long list, scoring candidates against a rubric, classifying support tickets, pulling structured fields from messy documents. That’s where small open-source models come in.
The pattern we use internally is what we call “one general, an army of troops.” You use a frontier model once to set the criteria and write the scoring rubric. Then you deploy a small model, something like Qwen 3.5 running locally on Ollama, thousands of times to do the actual sorting and filtering. The big model thinks. The small models execute.
One of our engineers demoed this at the workshop with a real problem: a 12-person battery startup needs grant funding, and there are 80,000+ grants on grants.gov. Claude filtered by category first, dropping obvious non-fits. Then a small model checked eligibility on each remaining grant individually, something a frontier model wouldn’t do because the cost would be absurd. Then another round of small-model calls ran an ELO tournament, 5,190 pairwise comparisons, to rank the survivors by fit. The result: a prioritized top 10, grounded in the actual grant text, for pennies. The same job on Opus would have cost roughly $2,500.
You can run these small models free on your laptop with Ollama or LM Studio. Data never leaves your machine, which solves the privacy and compliance questions (HIPAA, ITAR, SOC 2) that block a lot of teams from using AI on sensitive data in the first place. If you need scale, managed cloud APIs like AWS Bedrock or Google Model Garden charge per token with no servers to manage.
Once you see this, the question changes. Instead of “which AI model should I use?” you start asking “what kind of problem is this?” Hard reasoning, strategy, open-ended thinking? Use a frontier model. Repetitive classification, scoring, extraction at scale? Run a small one thousands of times for almost nothing.
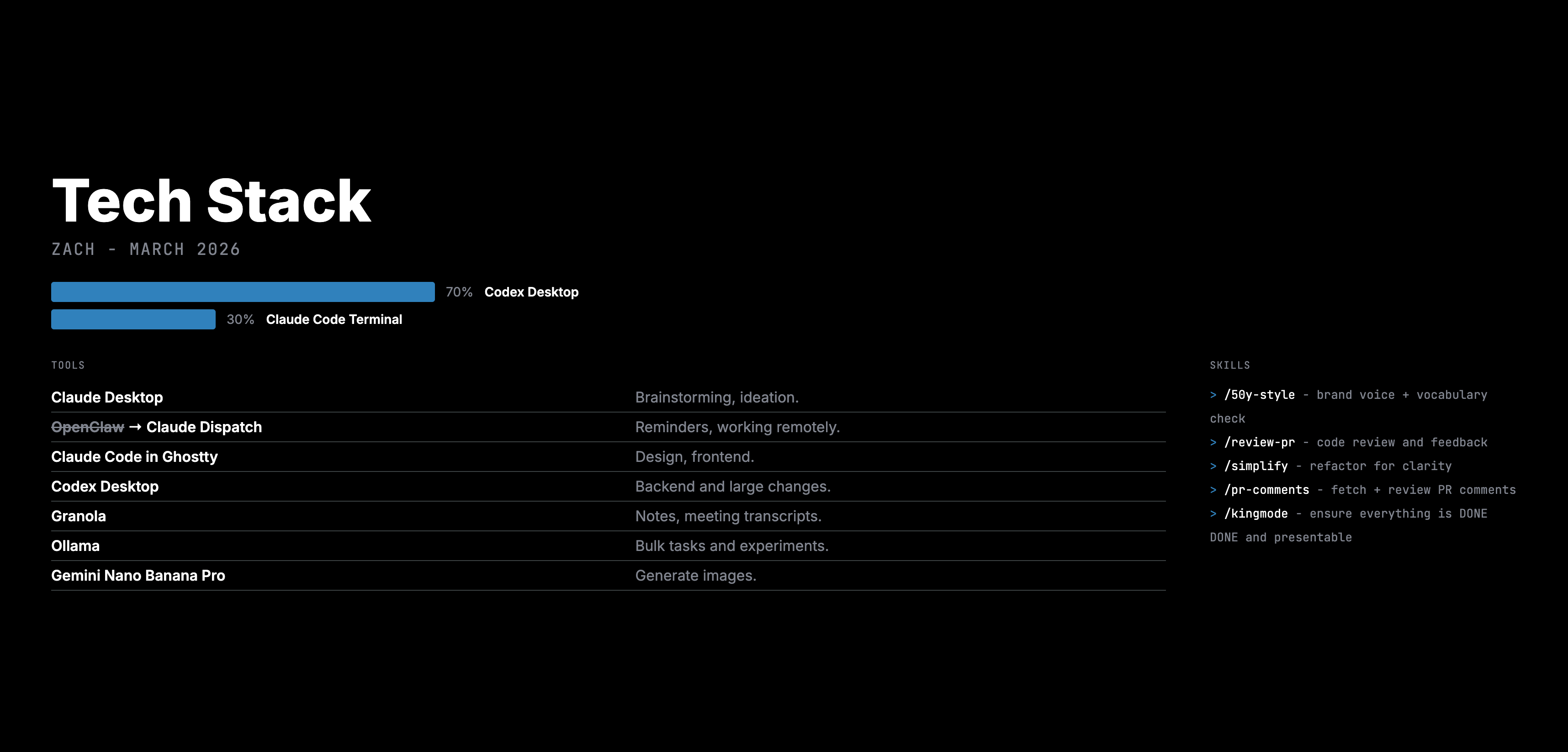
We don’t just talk theory. Here’s what AI-native work looks like on our team today.
Our code review process uses twelve parallel AI reviewers on a single pull request, each checking a different dimension: security, performance, style, correctness, DRY violations, data safety. The results get consolidated, validated, and posted as line comments. Three engineers on our platform team shipped 65+ issues in a single week. None of us could have done that two years ago.
We built a recruiting agent that automates candidate sourcing end-to-end: it searches, scores candidates with ELO rankings across multiple dimensions, and drafts personalized outreach. Days of manual work collapsed into minutes.
We have a daily commitment tracker that scans meeting notes, cross-references calendar, project management, and email, and surfaces what was promised versus what actually got done. Hours of admin, tasks that would otherwise fall through the cracks: handled.
The use cases will vary from team to team, but the question remains the same: are you enabling work at a speed that wasn’t physically possible 2 years ago?
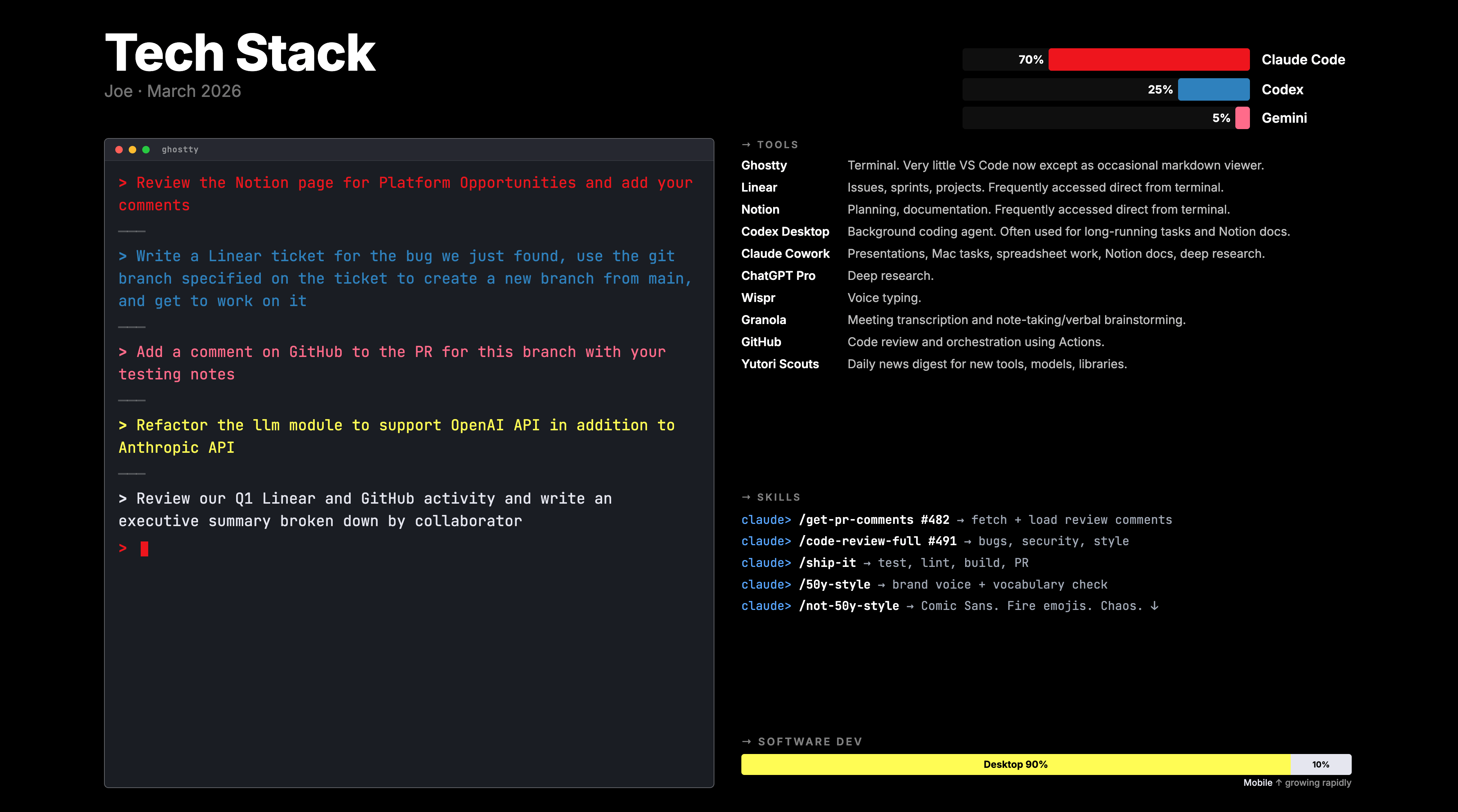
Getting the tools running is the easy part. Getting your team to actually change how they work is where most founders stall. Here’s what worked for us.
Rituals matter most. We run weekly “AI in Action” meetings where someone shows what they built or automated that week. One week it’s an automated commitment tracker, the next it’s a vibe-coded data explorer. It normalizes experimentation and creates a healthy pressure to ship. We also made AI-native a real hiring criterion. If candidates aren’t already using AI tools deeply, that tells us something.
Measurement is the other thing that keeps adoption from stalling. Track tokens used, hours saved, quality gains, and tasks automated, and talk about them internally. Quantify the before and after. Projects without structured measurement tend to quietly fade.
Privacy concerns are the number one reason teams stall. Give your team a simple framework: green (public info, anonymized data, internal drafts:any AI tool), yellow (internal strategies and financials: approved enterprise tools only), red (PII, customer data, proprietary IP: never). Once people know the boundaries, usage goes up. Print it, post it, put it in onboarding.
Finally, build a context system instead of a prompt library. The old approach was a collection of clever prompts. The new approach is reusable contexts, instructions, and workflows that prepare models before conversations start. Role contexts tell AI what it needs to know about each function. Workflow templates are step-by-step processes the AI can follow without you spelling it out each time. Output standards define what “good” looks like so the AI calibrates to your bar. When a new hire can plug into your team’s context system on day one, you’ve built something that compounds instead of living in one person’s head.
AI generates output far faster than humans can review, hence today's bottleneck. We can easily generate 100s of review tasks for every 10 we have time to look at manually. Over the next 6 months we expect that to change, as auto-reviewing capability matures. It's likely the bottleneck is shifting again, to 'which of the 1000s of feature ideas and prototypes should we discuss and proceed with?'. So the cost of ideation approaches zero, and prioritization becomes the bottleneck task.
Multi-agent teams, coordinated squads that plan, split, review, and merge, are moving from research to production. Background agents that monitor, process, and deliver while you sleep are already here in early form. And cost keeps collapsing: $10/hr today, likely $1/hr soon.
The specific tools will keep changing. The habits you build around clear thinking, structured delegation, and measuring results will outlast all of them. Guide well, review fast, and start designing the systems and feedback loops that let agents work autonomously.
The next thing to do after this is to pick one workflow. Measure the before and after. Talk about it internally. That’s the smallest version of the shift, and it’s enough to show your team what’s possible.