A couple of weeks ago on Halloween night, I was out with some friends when my advisor sent me a message to check web.mit.edu, right now. It took me a few seconds of staring to realize that an article about my masters thesis work on a nonparametric approach to detecting trends on Twitter was on the homepage of MIT. Over the next few days, it was picked up by Forbes, Wired, Mashable, Engadget, The Boston Herald and others, and my inbox and Twitter Connect tab were abuzz like never before.
There was a lot of interest in how this thing works and in this post I want to give an informal overview of the method Prof. Shah and I developed. But first, let me start with a story…
A scandal
On June 27, 2012, Barclays Bank was fined $450 million for manipulating the Libor interest rate, in what was possibly the biggest banking fraud scandal in history. People were in uproar about this, and many took their outrage to Twitter. In retrospect, “#Barclays” was bound to become a popular, or “trending” topic. But how soon could one have known this with reasonable certainty? Twitter’s algorithm detected “#Barclays” as a trend at 12:49pm GMT following a big jump in activity around noon (Figure 1).

Figure 1
But is there something about the preceding activity that would have allowed us to detect it earlier? It turns out that there is. We detected it at 12:03, more than 45 minutes in advance. Overall, we were able to detect trends in advance of Twitter 79% of the time, with a mean early advantage of 1.43 hours and an accuracy of 95%.
In this post I’ll tell you how we did it. But before diving into our approach, I want to motivate the thinking behind it by going over another approach to detecting trends.
The problem with parametric models
A popular approach to trend detection is to have a model of the type of activity that comes before a topic is declared trending, and to try to detect that type of activity. One possible model is that activity is roughly constant most of the time but has occasional jumps. A big jump would indicate that something is becoming popular. One way to detect trends would be to estimate a “jumpiness” parameter, say p, from a window of activity and declare something trending or not based on whether p exceeds some threshold.

Figure 2
This kind of method is called parametric, because it estimates parameters from data. But such a “constant + jumps” model does not fully capture the types of patterns that can precede a topic becoming trending. There could be several small jumps leading up to a big jump. There could be a gradual rise and no clear jump. Or any number of other patterns (Figure 3).

Figure 3
Of course, we could build parametric models to detect each of these kinds of patterns. Or even one master parametric model that detects all of them. But pretty soon, we get into a mess. Out of all the possible parametric models one could use, which one should we pick? A priori, it is not clear.
We don’t need to do this — there’s another way.
A data-driven approach
Instead of deciding what the parametric model should be, we take a nonparametric approach. That is, we let the data itself define the model. If we gather enough data about patterns that precede trends and patterns that don’t we can sufficiently characterize all possible types of patterns that can happen. Then instead of building a model from the data, we can use the data directly to decide whether a new pattern is going to lead to a trend or not. You might ask: aren’t there an unlimited number of patterns that can happen? Don’t we need an unreasonable amount of data to characterize all these possibilities?
It turns out that we don’t, at least in this case. People acting in social networks are reasonably predictable. If many of your friends talk about something, it’s likely that you will as well. If many of your friends are friends with person X, it is likely that you are friends with them too. Because the underlying system has, in this sense, low complexity, we should expect that the measurements from that system are also of low complexity. As a result, there should only be a few types of patterns that precede a topic becoming trending. One type of pattern could be “gradual rise”; another could be “small jump, then a big jump”; yet another could be “a jump, then a gradual rise”, and so on. But you’ll never get a sawtooth pattern, a pattern with downward jumps, or any other crazy pattern. To see what I mean, take a look at this sample of patterns (Figure 4) and how it can be clustered into a few different “ways” that something can become trending.






Figure 4: The patterns of activity in black are a sample of patterns of activity leading up to a topic becoming trending. Each subsequent cluster of patterns represents a “way” that something can become trending.
Having outlined this data-driven approach, let’s dive into the actual algorithm.
Our algorithm
Suppose we are tracking the activity of a new topic. To decide whether a topic is trending at some time we take some recent activity, which we call the observation 

Each of these examples takes a vote 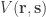



where 

Figure 5
Finally, we sum up all of the “trending” and “non-trending” votes, and see if the ratio of these sums is greater than or less than 1.

One could think of this as a kind of weighted majority vote k-nearest-neighbors classification. It also has a probabilistic interpretation that you can find in Chapter 2 of my thesis.
In general, the examples 

This approach has some nice properties. The core computations are pretty simple, as we only compute distances. It is scalable since computation of distances can be parallelized. Lastly, it is nonparametric, which means we don’t have to decide what model to use.
Results
To evaluate our approach, we collected 500 topics that trended in some time window (sampled from previous lists of trending topics) and 500 that did not (sampled from random phrases in tweets, with trending topics removed). We then tried to predict, on a holdout set of 50% of the topics, which one would trend and which one would not. For topics that both our algorithm and Twitter’s detected as trending, we measured how early or late our algorithm was relative to Twitter’s.
Our most striking result is that we were able to detect Twitter trends in advance of Twitter’s trend detection algorithm a good percent of the time, while maintaining a low rate of error. In 79% percent of cases, we detected trending topics earlier than Twitter (1.43 hours earlier), and we managed to keep an error rate of around 95% (4% false positive rate, 95% true positive rate).
Naturally, our algorithm has various parameters (most notably the scaling parameter


Figure 6
Conclusion
We’ve designed a new approach to detecting Twitter trends in a nonparametric fashion. But more than that, we’ve presented a general time series analysis method that can be used not only for classification (as in the case of trends), but also for prediction and anomaly detection (cartooned in Figure 7).

Figure 7
And it has the potential to work for a lot more than just predicting trends on Twitter. We can try this on traffic data to predict the duration of a bus ride, on movie ticket sales, on stock prices, or any other time-varying measurements.
We are excited by the early results, but there’s a lot more work ahead. We are continuing to investigate, both theoretically and experimentally, how well this does with different kinds and amounts of data, and on tasks other than classification. Stay tuned!
________________________________________________________
Notes:
Thanks to Ben Lerner, Caitlin Mehl, and Coleman Shelton for reading drafts of this.
I gave a talk about this at the Interdisciplinary Workshop on Information and Decision in Social Networks at MIT on November 9th, and I’ve included the slides below. A huge thank you to the many people who listened to dry runs of it and gave me wonderful feedback.
For a less technical look, Prof. Shah gave a great talk at the MIT Museum on Friday, November 9th: