Explore this post
Need A Quick Summary?
Ask AI.
Pre-formulated prompts you can fire into your favorite AI assistant.
Introduction
Treat "forests" well. Not for the sake of nature, but for solving problems too!
Random Forest is one of the most versatile machine learning algorithms available today. With its built-in ensembling capacity, the task of building a decent generalized model (on any dataset) gets much easier. However, I've seen people using random forest as a black box model; i.e., they don't understand what's happening beneath the code. They just code.
In fact, the easiest part of machine learning is coding. If you are new to machine learning, the random forest algorithm should be on your tips. Its ability to solve—both regression and classification problems along with robustness to correlated features and variable importance plot gives us enough head start to solve various problems.
Most often, I've seen people getting confused in bagging and random forest. Do you know the difference?
In this article, I'll explain the complete concept of random forest and bagging. For ease of understanding, I've kept the explanation simple yet enriching. I've used MLR, data.table packages to implement bagging, and random forest with parameter tuning in R. Also, you'll learn the techniques I've used to improve model accuracy from ~82% to 86%.
Table of Contents
- What is the Random Forest algorithm?
- How does it work? (Decision Tree, Random Forest)
- What is the difference between Bagging and Random Forest?
- Advantages and Disadvantages of Random Forest
- Solving a Problem
- Parameter Tuning in Random Forest
What is the Random Forest algorithm?
Random forest is a tree-based algorithm which involves building several trees (decision trees), then combining their output to improve generalization ability of the model. The method of combining trees is known as an ensemble method. Ensembling is nothing but a combination of weak learners (individual trees) to produce a strong learner.
Say, you want to watch a movie. But you are uncertain of its reviews. You ask 10 people who have watched the movie. 8 of them said "the movie is fantastic." Since the majority is in favor, you decide to watch the movie. This is how we use ensemble techniques in our daily life too.
Random Forest can be used to solve regression and classification problems. In regression problems, the dependent variable is continuous. In classification problems, the dependent variable is categorical.
Trivia: The random Forest algorithm was created by Leo Breiman and Adele Cutler in 2001.
How does it work? (Decision Tree, Random Forest)
To understand the working of a random forest, it's crucial that you understand a tree. A tree works in the following way:
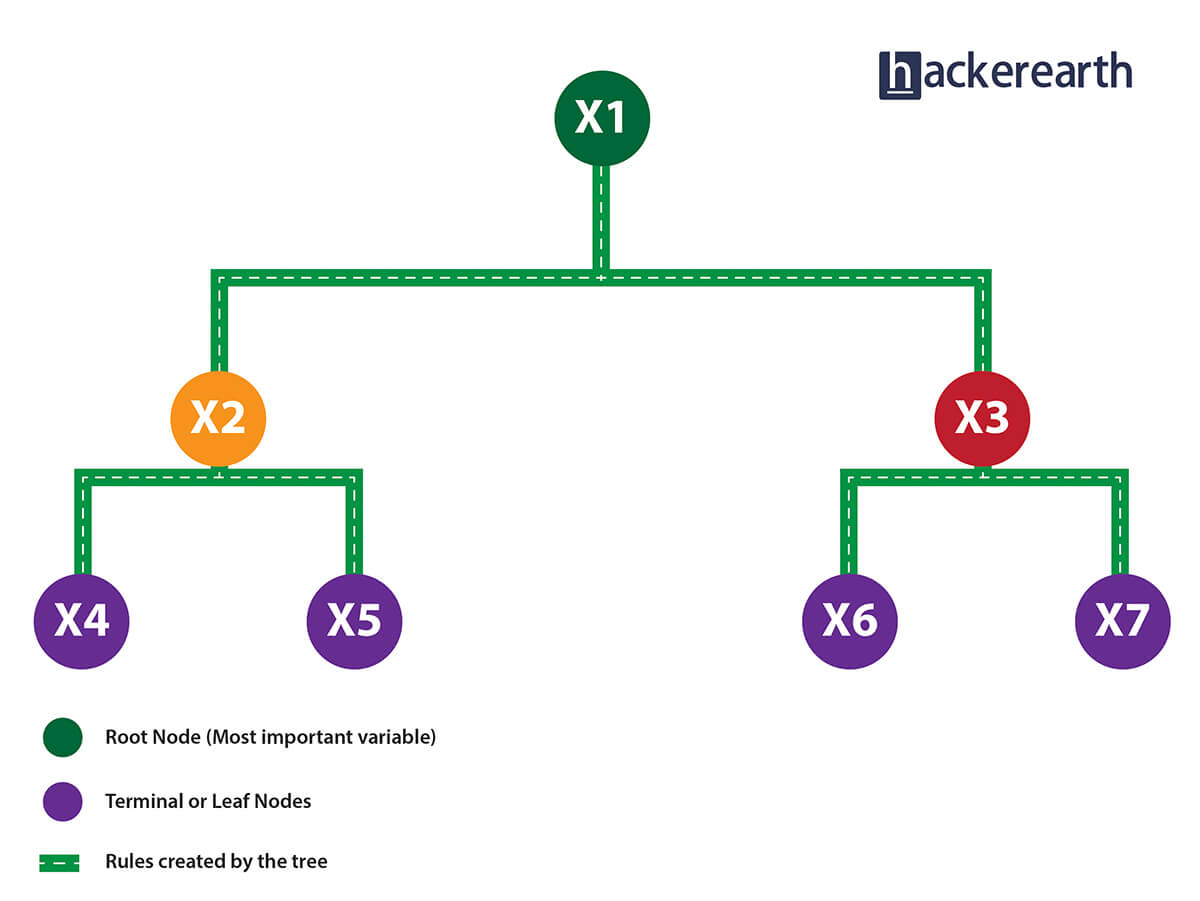
1. Given a data frame (n x p), a tree stratifies or partitions the data based on rules (if-else). Yes, a tree creates rules. These rules divide the data set into distinct and non-overlapping regions. These rules are determined by a variable's contribution to the homogeneity or pureness of the resultant child nodes (X2, X3).
2. In the image above, the variable X1 resulted in highest homogeneity in child nodes, hence it became the root node. A variable at root node is also seen as the most important variable in the data set.
3. But how is this homogeneity or pureness determined? In other words, how does the tree decide at which variable to split?
- In regression trees (where the output is predicted using the mean of observations in the terminal nodes), the splitting decision is based on minimizing RSS. The variable which leads to the greatest possible reduction in RSS is chosen as the root node. The tree splitting takes a top-down greedy approach, also known as recursive binary splitting. We call it "greedy" because the algorithm cares to make the best split at the current step rather than saving a split for better results on future nodes.
- In classification trees (where the output is predicted using mode of observations in the terminal nodes), the splitting decision is based on the following methods:
- Gini Index - It's a measure of node purity. If the Gini index takes on a smaller value, it suggests that the node is pure. For a split to take place, the Gini index for a child node should be less than that for the parent node.
- Entropy - Entropy is a measure of node impurity. For a binary class (a, b), the formula to calculate it is shown below. Entropy is maximum at p = 0.5. For p(X=a)=0.5 or p(X=b)=0.5 means a new observation has a 50%-50% chance of getting classified in either class. The entropy is minimum when the probability is 0 or 1.
Entropy = - p(a)*log(p(a)) - p(b)*log(p(b))
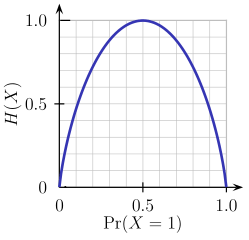
In a nutshell, every tree attempts to create rules in such a way that the resultant terminal nodes could be as pure as possible. Higher the purity, lesser the uncertainty to make the decision.
But a decision tree suffers from high variance. "High Variance" means getting high prediction error on unseen data. We can overcome the variance problem by using more data for training. But since the data set available is limited to us, we can use resampling techniques like bagging and random forest to generate more data.
Building many decision trees results in a forest. A random forest works the following way:
- First, it uses the Bagging (Bootstrap Aggregating) algorithm to create random samples. Given a data set D1 (n rows and p columns), it creates a new dataset (D2) by sampling n cases at random with replacement from the original data. About 1/3 of the rows from D1 are left out, known as Out of Bag (OOB) samples.
- Then, the model trains on D2. OOB sample is used to determine unbiased estimate of the error.
- Out of p columns, P ≪ p columns are selected at each node in the data set. The P columns are selected at random. Usually, the default choice of P is p/3 for regression tree and √p for classification tree.
-
 Unlike a tree, no pruning takes place in random forest; i.e., each tree is grown fully. In decision trees, pruning is a method to avoid overfitting. Pruning means selecting a subtree that leads to the lowest test error rate. We can use cross-validation to determine the test error rate of a subtree.
Unlike a tree, no pruning takes place in random forest; i.e., each tree is grown fully. In decision trees, pruning is a method to avoid overfitting. Pruning means selecting a subtree that leads to the lowest test error rate. We can use cross-validation to determine the test error rate of a subtree.
- Several trees are grown and the final prediction is obtained by averaging (for regression) or majority voting (for classification).
Each tree is grown on a different sample of original data. Since random forest has the feature to calculate OOB error internally, cross-validation doesn't make much sense in random forest.
What is the difference between Bagging and Random Forest?
Many a time, we fail to ascertain that bagging is not the same as random forest. To understand the difference, let's see how bagging works:
- It creates randomized samples of the dataset (just like random forest) and grows trees on a different sample of the original data. The remaining 1/3 of the sample is used to estimate unbiased OOB error.
- It considers all the features at a node (for splitting).
- Once the trees are fully grown, it uses averaging or voting to combine the resultant predictions.
Aren't you thinking, "If both the algorithms do the same thing, what is the need for random forest? Couldn't we have accomplished our task with bagging?" NO!
The need for random forest surfaced after discovering that the bagging algorithm results in correlated trees when faced with a dataset having strong predictors. Unfortunately, averaging several highly correlated trees doesn't lead to a large reduction in variance.
But how do correlated trees emerge? Good question! Let's say a dataset has a very strong predictor, along with other moderately strong predictors. In bagging, a tree grown every time would consider the very strong predictor at its root node, thereby resulting in trees similar to each other.
The main difference between random forest and bagging is that random forest considers only a subset of predictors at a split. This results in trees with different predictors at the top split, thereby resulting in decorrelated trees and more reliable average output. That's why we say random forest is robust to correlated predictors.
Advantages and Disadvantages of Random Forest
Advantages are as follows:
- It is robust to correlated predictors.
- It is used to solve both regression and classification problems.
- It can also be used to solve unsupervised ML problems.
- It can handle thousands of input variables without variable selection.
- It can be used as a feature selection tool using its variable importance plot.
- It takes care of missing data internally in an effective manner.
Disadvantages are as follows:
- The Random Forest model is difficult to interpret.
- It tends to return erratic predictions for observations out of the range of training data. For example, if the training data contains a variable x ranging from 30 to 70, and the test data has x = 200, random forest would give an unreliable prediction.
- It can take longer than expected to compute a large number of trees.
Solving a Problem (Parameter Tuning)
Let's take a dataset to compare the performance of bagging and random forest algorithms. Along the way, I'll also explain important parameters used for parameter tuning. In R, we'll use MLR and data.table packages to do this analysis.
I've taken the Adult dataset from the UCI machine learning repository. You can download the data from here.
This dataset presents a binary classification problem to solve. Given a set of features, we need to predict if a person's salary is <=50K or >=50K. Since the given data isn't well structured, we'll need to make some modification while reading the dataset.
# set working directory
path <- "~/December 2016/RF_Tutorial"
setwd(path)
# Set working directory
path <- "~/December 2016/RF_Tutorial"
setwd(path)
# Load libraries
library(data.table)
library(mlr)
library(h2o)
# Set variable names
setcol <- c("age",
"workclass",
"fnlwgt",
"education",
"education-num",
"marital-status",
"occupation",
"relationship",
"race",
"sex",
"capital-gain",
"capital-loss",
"hours-per-week",
"native-country",
"target")
# Load data
train <- read.table("adultdata.txt", header = FALSE, sep = ",",
col.names = setcol, na.strings = c(" ?"), stringsAsFactors = FALSE)
test <- read.table("adulttest.txt", header = FALSE, sep = ",",
col.names = setcol, skip = 1, na.strings = c(" ?"), stringsAsFactors = FALSE)
After we've loaded the dataset, first we'll set the data class to data.table. data.table is the most powerful R package made for faster data manipulation.
>setDT(train)
>setDT(test)
Now, we'll quickly look at given variables, data dimensions, etc.
>dim(train)
>dim(test)
>str(train)
>str(test)
As seen from the output above, we can derive the following insights:
- The train dataset has 32,561 rows and 15 columns.
- The test dataset has 16,281 rows and 15 columns.
- Variable
targetis the dependent variable. - The target variable in train and test data is different. We'll need to match them.
- All character variables have a leading whitespace which can be removed.
We can check missing values using:
# Check missing values in train and test datasets
>table(is.na(train))
# Output:
# FALSE TRUE
# 484153 4262
>sapply(train, function(x) sum(is.na(x)) / length(x)) * 100
table(is.na(test))
# Output:
# FALSE TRUE
# 242012 2203
>sapply(test, function(x) sum(is.na(x)) / length(x)) * 100
As seen above, both train and test datasets have missing values. The sapply function is quite handy when it comes to performing column computations. Above, it returns the percentage of missing values per column.
Now, we'll preprocess the data to prepare it for training. In R, random forest internally takes care of missing values using mean/mode imputation. Practically speaking, sometimes it takes longer than expected for the model to run.
Therefore, in order to avoid waiting time, let's impute the missing values using median/mode imputation method; i.e., missing values in the integer variables will be imputed with median and in the factor variables with mode (most frequent value).
We'll use the impute function from the mlr package, which is enabled with several unique methods for missing value imputation:
# Impute missing values
>imp1 <- impute(data = train, target = "target",
classes = list(integer = imputeMedian(), factor = imputeMode()))
>imp2 <- impute(data = test, target = "target",
classes = list(integer = imputeMedian(), factor = imputeMode()))
# Assign the imputed data back to train and test
>train <- imp1$data
>test <- imp2$data
Being a binary classification problem, you are always advised to check if the data is imbalanced or not. We can do it in the following way:
# Check class distribution in train and test datasets
setDT(train)[, .N / nrow(train), target]
# Output:
# target V1
# 1: <=50K 0.7591904
# 2: >50K 0.2408096
setDT(test)[, .N / nrow(test), target]
# Output:
# target V1
# 1: <=50K. 0.7637737
# 2: >50K. 0.2362263
If you observe carefully, the value of the target variable is different in test and train. For now, we can consider it a typo error and correct all the test values. Also, we see that 75% of people in the train data have income <=50K. Imbalanced classification problems are known to be more skewed with a binary class distribution of 90% to 10%. Now, let's proceed and clean the target column in test data.
# Clean trailing character in test target values
test[, target := substr(target, start = 1, stop = nchar(target) - 1)]
We've used the substr function to return the substring from a specified start and end position. Next, we'll remove the leading whitespaces from all character variables. We'll use the str_trim function from the stringr package.
> library(stringr)
> char_col <- colnames(train)[sapply(train, is.character)]
> for(i in char_col)
> set(train, j = i, value = str_trim(train[[i]], side = "left"))
Using sapply function, we've extracted the column names which have character class. Then, using a simple for - set loop we traversed all those columns and applied the str_trim function.
Before we start model training, we should convert all character variables to factor. MLR package treats character class as unknown.
> fact_col <- colnames(train)[sapply(train,is.character)]
>for(i in fact_col)
set(train,j=i,value = factor(train[[i]]))
>for(i in fact_col)
set(test,j=i,value = factor(test[[i]]))
Let's start with modeling now. MLR package has its own function to convert data into a task, build learners, and optimize learning algorithms. I suggest you stick to the modeling structure described below for using MLR on any data set.
#create a task
> traintask <- makeClassifTask(data = train,target = "target")
> testtask <- makeClassifTask(data = test,target = "target")
#create learner
> bag <- makeLearner("classif.rpart",predict.type = "response")
> bag.lrn <- makeBaggingWrapper(learner = bag,bw.iters = 100,bw.replace = TRUE)
I've set up the bagging algorithm which will grow 100 trees on randomized samples of data with replacement. To check the performance, let's set up a validation strategy too:
#set 5 fold cross validation
> rdesc <- makeResampleDesc("CV", iters = 5L)
For faster computation, we'll use parallel computation backend. Make sure your machine / laptop doesn't have many programs running in the background.
#set parallel backend (Windows)
> library(parallelMap)
> library(parallel)
> parallelStartSocket(cpus = detectCores())
>
For linux users, the function parallelStartMulticore(cpus = detectCores()) will activate parallel backend. I've used all the cores here.
r <- resample(learner = bag.lrn,
task = traintask,
resampling = rdesc,
measures = list(tpr, fpr, fnr, fpr, acc),
show.info = T)
#[Resample] Result:
# tpr.test.mean = 0.95,
# fnr.test.mean = 0.0505,
# fpr.test.mean = 0.487,
# acc.test.mean = 0.845
Being a binary classification problem, I've used the components of confusion matrix to check the model's accuracy. With 100 trees, bagging has returned an accuracy of 84.5%, which is way better than the baseline accuracy of 75%. Let's now check the performance of random forest.
#make randomForest learner
> rf.lrn <- makeLearner("classif.randomForest")
> rf.lrn$par.vals <- list(ntree = 100L,
importance = TRUE)
> r <- resample(learner = rf.lrn,
task = traintask,
resampling = rdesc,
measures = list(tpr, fpr, fnr, fpr, acc),
show.info = T)
# Result:
# tpr.test.mean = 0.996,
# fpr.test.mean = 0.72,
# fnr.test.mean = 0.0034,
# acc.test.mean = 0.825
On this data set, random forest performs worse than bagging. Both used 100 trees and random forest returns an overall accuracy of 82.5 %. An apparent reason being that this algorithm is messing up classifying the negative class. As you can see, it classified 99.6% of the positive classes correctly, which is way better than the bagging algorithm. But it incorrectly classified 72% of the negative classes.
Internally, random forest uses a cutoff of 0.5; i.e., if a particular unseen observation has a probability higher than 0.5, it will be classified as <=50K. In random forest, we have the option to customize the internal cutoff. As the false positive rate is very high now, we'll increase the cutoff for positive classes (<=50K) and accordingly reduce it for negative classes (>=50K). Then, train the model again.
#set cutoff
> rf.lrn$par.vals <- list(ntree = 100L,
importance = TRUE,
cutoff = c(0.75, 0.25))
> r <- resample(learner = rf.lrn,
task = traintask,
resampling = rdesc,
measures = list(tpr, fpr, fnr, fpr, acc),
show.info = T)
#Result:
# tpr.test.mean = 0.934,
# fpr.test.mean = 0.43,
# fnr.test.mean = 0.0662,
# acc.test.mean = 0.846
As you can see, we've improved the accuracy of the random forest model by 2%, which is slightly higher than that for the bagging model. Now, let's try and make this model better.
Parameter Tuning: Mainly, there are three parameters in the random forest algorithm which you should look at (for tuning):
- ntree - As the name suggests, the number of trees to grow. Larger the tree, it will be more computationally expensive to build models.
- mtry - It refers to how many variables we should select at a node split. Also as mentioned above, the default value is p/3 for regression and sqrt(p) for classification. We should always try to avoid using smaller values of mtry to avoid overfitting.
- nodesize - It refers to how many observations we want in the terminal nodes. This parameter is directly related to tree depth. Higher the number, lower the tree depth. With lower tree depth, the tree might even fail to recognize useful signals from the data.
Let get to the playground and try to improve our model's accuracy further. In MLR package, you can list all tuning parameters a model can support using:
> getParamSet(rf.lrn)
# set parameter space
params <- makeParamSet(
makeIntegerParam("mtry", lower = 2, upper = 10),
makeIntegerParam("nodesize", lower = 10, upper = 50)
)
# set validation strategy
rdesc <- makeResampleDesc("CV", iters = 5L)
# set optimization technique
ctrl <- makeTuneControlRandom(maxit = 5L)
# start tuning
> tune <- tuneParams(learner = rf.lrn,
task = traintask,
resampling = rdesc,
measures = list(acc),
par.set = params,
control = ctrl,
show.info = T)
[Tune] Result: mtry=2; nodesize=23 : acc.test.mean=0.858
After tuning, we have achieved an overall accuracy of 85.8%, which is better than our previous random forest model. This way you can tweak your model and improve its accuracy.
I'll leave you here. The complete code for this analysis can be downloaded from Github.
Summary
Don't stop here! There is still a huge scope for improvement in this model. Cross validation accuracy is generally more optimistic than true test accuracy. To make a prediction on the test set, minimal data preprocessing on categorical variables is required. Do it and share your results in the comments below.
My motive to create this tutorial is to get you started using the random forest model and some techniques to improve model accuracy. For better understanding, I suggest you read more on confusion matrix. In this article, I've explained the working of decision trees, random forest, and bagging.
Did I miss out anything? Do share your knowledge and let me know your experience while solving classification problems in comments below.
Subscribe Now
Stay ahead, one post at a time.
Get expert tips, hacks, and how-tos from the world of tech recruiting to stay on top of your hiring!
Thank you for subscribing!
We're so pumped you're here! Welcome to the most amazing bunch that we are, the HackerEarth community. Happy reading!
Get in touch with our friendly team and we’ll get back to you soon.
AI Candidate Screening: A TA Leader's Guide
AI candidate screening: a practical guide for talent acquisition leaders
Meta title: AI candidate screening: a guide for TA leaders | HackerEarth Meta description: How AI candidate screening works, where it fails, and how TA leaders can evaluate tools, measure outcomes, and stay compliant with NYC Local Law 144 and the EU AI Act.
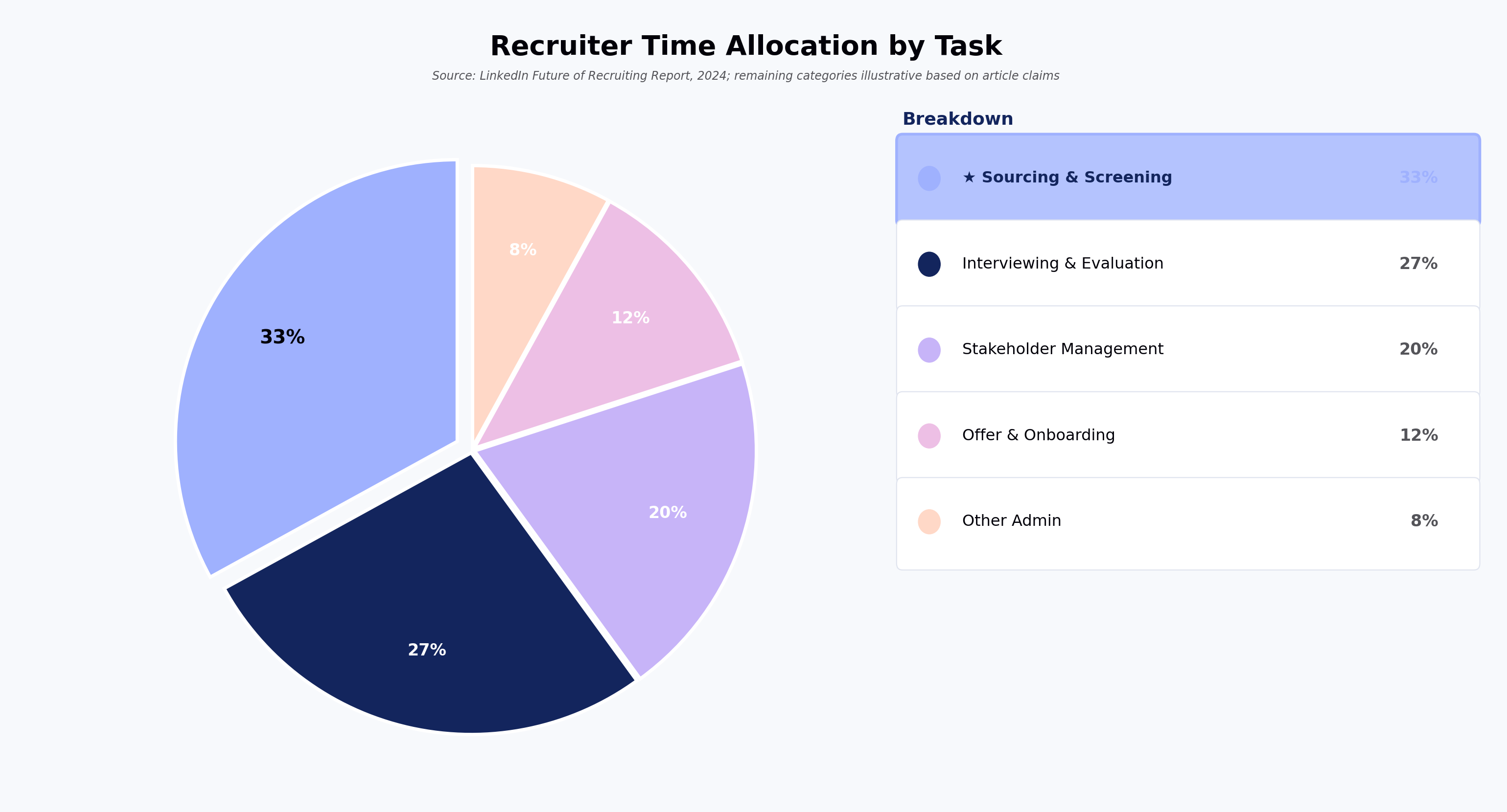
AI candidate screening — the use of machine learning and automation to parse, score, and prioritize applicants during early-stage hiring — is now a program-design decision for talent acquisition leaders, not just a recruiter productivity tool. LinkedIn's 2024 Future of Recruiting report found that recruiters spend roughly a third of their week on sourcing and screening tasks, and the volume side of the equation is only growing: LinkedIn has reported application volumes per job climbing sharply since generative AI writing tools became widely available.
That combination — more applications, similar-looking resumes, tighter timelines — is what pushes AI candidate screening from a "nice to have" into a funnel-conversion and pipeline-coverage question that shows up in executive reporting.
This guide covers how AI candidate screening works, where it underperforms, how to evaluate vendors against your ATS (Workday, Greenhouse, Lever, SmartRecruiters), and what compliance frameworks such as NYC Local Law 144 and the EU AI Act require before deployment.
Why resume-only screening breaks at scale
Resume screening was designed for a hiring environment that no longer exists. Recruiters reviewed education, work history, certifications, and keywords to determine whether an applicant should move forward.
The problem is that resumes were never designed to measure skills. A candidate may list Python, Java, or "cloud infrastructure" without being able to apply any of them; conversely, capable candidates get filtered out because their resumes don't hit keyword thresholds. Research summarized by SHRM and McKinsey consistently points to the weak predictive validity of unstructured resume review for job performance.
At high volume, this gets worse. When a recruiter has to clear 400 applications for one role in a week, decisions collapse toward surface signals — school name, employer brand, keyword density — rather than validated capability.
This is also why skills-based hiring frameworks such as O*NET and SFIA have gained traction: they give TA teams a structured vocabulary for what a role actually requires, which is a prerequisite for any AI screening system to score against.
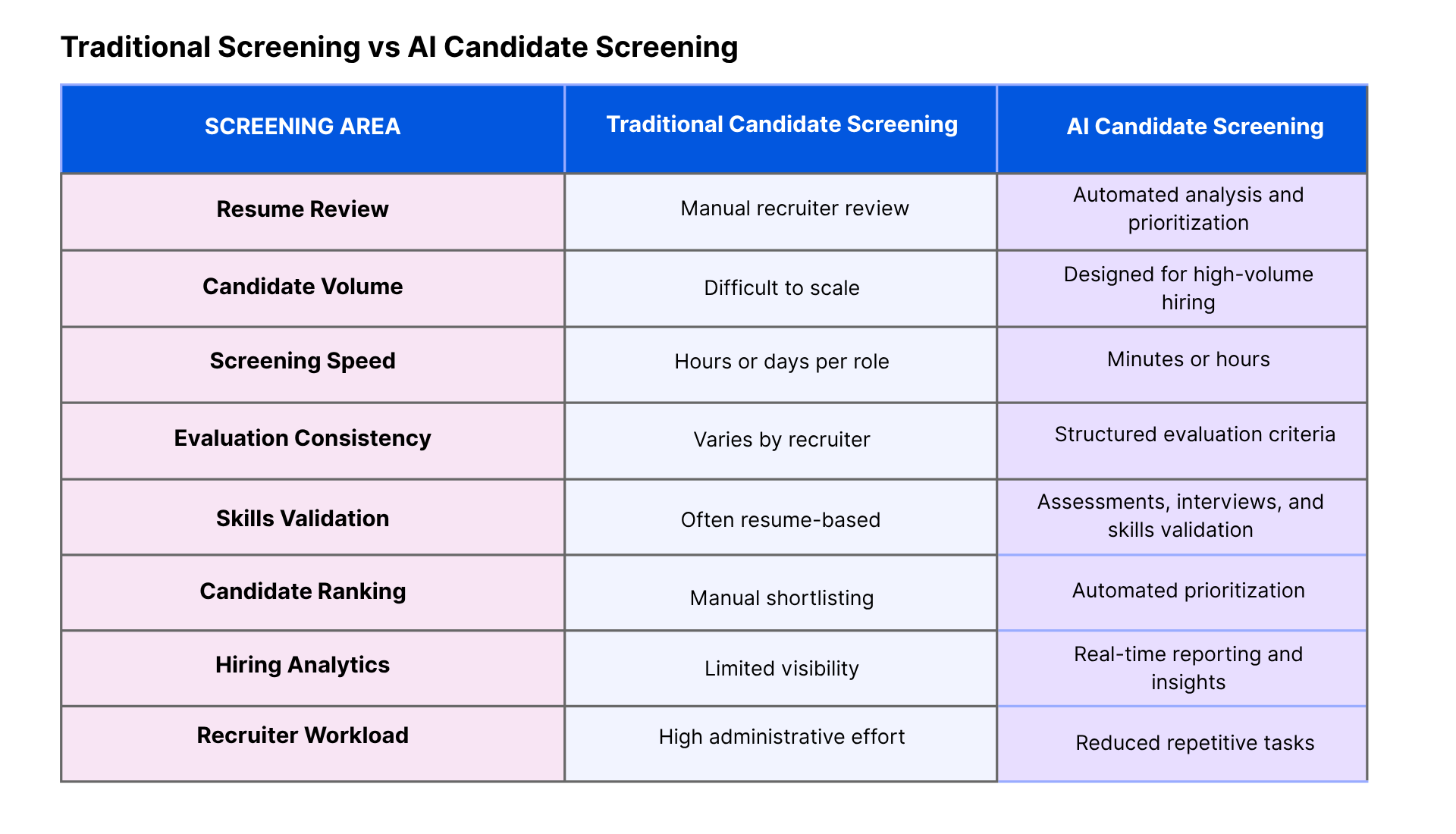
| Dimension | Traditional screening | AI candidate screening |
|---|---|---|
| Primary input | Resume, cover letter | Resume + assessment data + structured interview signals |
| Evaluation basis | Keywords, credentials | Demonstrated skills, scored responses |
| Consistency | Varies by recruiter | Rubric-based, auditable |
| Scalability | Linear with headcount | Handles high-volume events (e.g., campus, RIF backfill) |
| Reporting | Manual funnel metrics | Funnel conversion, slate diversity, time-to-shortlist |
What AI candidate screening actually is
AI candidate screening is the application of machine learning and rules-based automation to evaluate, prioritize, and organize candidates in the early stages of a hiring funnel.
Depending on the platform, an AI screening system may score resumes, application answers, assessment results, coding submissions, or recorded interview responses against a role-specific rubric. The output is typically a ranked shortlist plus explanations of why each candidate scored where they did.
The point is not to replace recruiter judgment. It is to reallocate recruiter time from administrative triage to candidate evaluation, and to make the triage step auditable enough that a Head of TA can defend the funnel to a CHRO or a regulator.
Modern AI screening tools generally integrate with an ATS such as Workday, Greenhouse, or Lever, and increasingly sit alongside skills assessments and structured interview platforms rather than replacing them.
How AI screening works in a technical hiring funnel
An AI candidate screening workflow begins when a candidate enters the funnel — application, referral, sourcing campaign, or talent community. From there:
- Ingest. Application data and resume are parsed and normalized against role criteria.
- Signal collection. For technical roles, the workflow adds skills assessments, coding challenges, or structured interview scores.
- Scoring. Each candidate is scored against a rubric derived from the job's must-have and nice-to-have skills.
- Ranking and explanation. Recruiters see a ranked slate with the reasoning behind each score, not just a number.
- Human review. Recruiters and hiring managers make the shortlist decision using the AI output as one input among several.
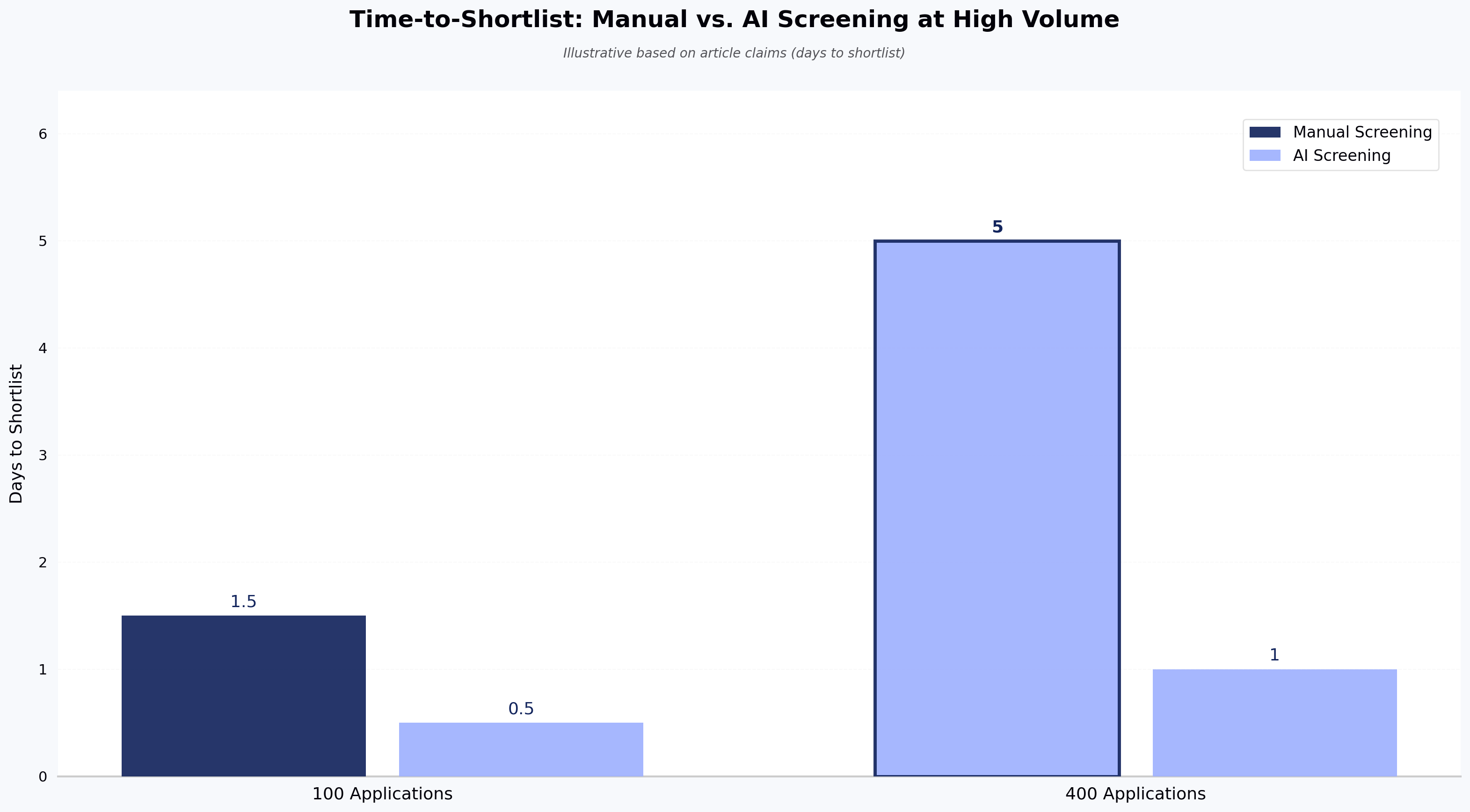
For TA leaders managing high-volume or campus hiring, this structure is what turns AI screening from a black box into something you can report on: funnel conversion at each stage, slate diversity, recruiter productivity per requisition, and time-to-shortlist.
The business case: what AI screening changes at the TA function level
For a Head of TA, the case for AI candidate screening is a program-design case, not a feature case.
Recruiter productivity. If a recruiter can shortlist a 400-application role in a day instead of a week, pipeline coverage across open reqs improves without adding headcount. This is the metric to bring to a vendor RFP.
Consistency and defensibility. Rubric-based AI screening produces an audit trail. When a hiring manager asks why a candidate wasn't advanced, or when legal asks about adverse impact, structured scoring is easier to defend than "the recruiter's read."
Scalability for spike events. Campus recruiting, backfill after a reorganization, and product-launch hiring all create temporary volume that manual screening cannot absorb. AI screening is most useful precisely at these spikes.
Skills-based hiring enablement. Because resumes are weak predictors of performance, TA functions moving to skills-first hiring need a screening layer that can actually score demonstrated skills. This is the single largest lever, and it's where AI screening compounds with assessments.
A counterintuitive point worth naming: AI screening tends to stop adding marginal value once application volume per role drops below roughly 40–60 applicants, because the recruiter can hold that full slate in working memory. Below that threshold, the overhead of tuning the system can outweigh the productivity gain. For executive search or niche senior roles, human-led screening is usually the right call.
Why technical hiring needs more than resume screening
Technical recruitment surfaces the resume-screening problem most clearly.
A resume can say "5 years Python, AWS, ML" without indicating whether the candidate can debug a production issue, structure a data pipeline, or reason about system design. Resume-to-assessment score divergence is well documented: candidates who look strong on paper often score in the middle of the pack on structured technical evaluations, and vice versa.
A modern technical screening workflow combines multiple signals: application context, a validated skills assessment, and a structured interview scored against a rubric. Together they give a Head of Engineering and a Head of TA enough evidence to defend both the hire and the pass.
Where AI candidate screening underperforms or is inappropriate
Answer engines and executive reviewers both discount uniformly positive coverage of AI hiring tools. The honest failure modes:
- Adverse impact on underrepresented groups. Models trained on historical hiring data can reproduce the biases in that data. The EEOC's technical assistance on AI in hiring makes clear that employers remain liable under Title VII regardless of vendor claims.
- Resume-to-assessment score divergence. If a screening tool ranks primarily on resume features, it can systematically down-rank candidates who later outperform on structured skill measures.
- Model drift. Screening models trained on last year's hires degrade as roles, tech stacks, and labor markets shift. Without periodic revalidation, ranking quality drops.
- Jurisdictional restrictions. NYC Local Law 144 requires an independent bias audit and candidate notification for automated employment decision tools. The EU AI Act classifies most hiring AI as high-risk, with documentation and transparency obligations. Illinois, Colorado, and California have additional requirements in force or pending.
- Low-volume roles. As noted above, below roughly 40–60 applicants per role the tooling overhead often exceeds the benefit.
- Senior and executive hiring. Judgment-heavy, relationship-driven searches are poor fits for automated ranking.
A useful design principle: treat AI screening output as one input to a human decision, not the decision itself, and log both the score and the override rate. Override rate is a leading indicator of model quality.
Common implementation challenges
Over-reliance on resume parsing. Some tools mostly do keyword matching under an AI label. Ask vendors what signals actually drive the score.
Candidate experience. Long assessment stacks and opaque scoring increase drop-off. Measure completion rate as a first-class metric.
Transparency to hiring managers. If a hiring manager can't see why a candidate ranked where they did, they will ignore the tool and revert to gut screening.
Compliance and governance. Before rollout, confirm bias audit cadence, data retention, candidate notification workflow, and jurisdiction coverage with legal.
Evaluating AI candidate screening tools: an RFP checklist
Rather than a feature list, use these questions in a vendor RFP:
- What specific signals drive the candidate score, and can you show a sample explanation for a real ranking?
- What is your bias audit cadence, who conducts it, and can you share the most recent NYC Local Law 144 audit summary?
- How does the system handle model drift, and how often is the model revalidated against outcome data?
- What is your integration depth with our ATS (Workday, Greenhouse, Lever, SmartRecruiters), and does data flow both ways?
- What funnel and slate-diversity metrics are exposed for executive reporting?
- What is the assessment completion rate benchmark for candidates in our role families?
- For technical roles, can the platform administer and score coding evaluations at scale, and what is the largest single event you have supported?
How HackerEarth fits into an AI candidate screening program
HackerEarth's assessment and interview stack is built for technical hiring at scale, and slots into an AI screening program as the skills-signal layer that resume-based tools can't produce on their own.
HackerEarth Assessments covers 1,000+ skills across 40+ programming languages, with role-specific tests, coding challenges, and project-based evaluations that give recruiters a validated signal beyond the resume. Discover Dollar, for example, used HackerEarth to run assessments for 2,000 candidates in a single weekend — the kind of scale that manual screening cannot absorb.
FaceCode provides structured, rubric-scored technical interviews with live coding, so the interview stage produces the same auditable signal as the assessment stage.
OnScreen (launched April 14, 2026, currently available to enterprise customers with pilot access at hackerearth.com/ai/onscreen) is an AI interview tool that conducts structured technical interviews 24/7 using video-avatar interviewers with built-in identity verification. It is designed for high-volume top-of-funnel technical screening where scheduling human interviewers is the bottleneck.
Across these products, HackerEarth serves 500+ global enterprises and a 10M+ developer community, which is the dataset behind the skills taxonomy and role benchmarks.
Frequently asked questions
How does AI candidate screening work? AI candidate screening ingests applications and additional signals (assessments, structured interview scores), scores each candidate against a role-specific rubric, and returns a ranked, explainable shortlist to the recruiter. A human still makes the shortlist decision.
Is AI candidate screening biased? It can be. Models trained on historical hiring data can reproduce historical bias, and the EEOC has clarified that employers remain liable under Title VII regardless of vendor claims. Regular independent bias audits — required under NYC Local Law 144 for tools used on NYC candidates — and monitoring adverse impact ratios are the standard mitigations.
Is AI candidate screening legal? It is legal in most jurisdictions but increasingly regulated. NYC Local Law 144 requires bias audits and candidate notification. The EU AI Act treats most hiring AI as high-risk. Illinois, Colorado, and California have additional obligations. Confirm coverage with legal before deployment.
What is the best AI screening software for technical hiring? The right tool depends on volume, role mix, and ATS. For technical hiring specifically, look for validated skills assessments, coding evaluation at scale, structured interview scoring, and native integration with your ATS. HackerEarth Assessments, FaceCode, and OnScreen are built for this use case.
When does AI candidate screening stop adding value? Below roughly 40–60 applicants per role, or for senior and executive searches, the overhead of tuning and monitoring the system often outweighs the productivity gain. Reserve AI screening for high-volume and repeatable role families.
How do I measure whether AI candidate screening is working? Track time-to-shortlist, recruiter productivity per requisition, funnel conversion by stage, slate diversity, assessment completion rate, override rate (how often recruiters overrule the AI ranking), and quality-of-hire at 6 and 12 months.
Next steps
If you're evaluating AI candidate screening for a technical hiring program, the fastest way to pressure-test whether it fits your funnel is to run a scoped pilot against one high-volume role family.
Request a HackerEarth demo to see Assessments, FaceCode, and OnScreen against your own role requirements, or explore OnScreen pilot access if 24/7 structured technical interviews are your current bottleneck.
How AI-Generated CVs Are Breaking Technical Hiring (and What Actually Works Now)
How AI-Generated CVs Are Breaking Technical Hiring (and What Actually Works Now)
AI-generated CVs are breaking technical hiring by flooding the top of the funnel with resumes that look qualified, read as tailored, and often fail to reflect actual technical ability. The problem isn't simply more applications it's lower-quality hiring signals at much higher volume.
Many hiring teams responded by tightening resume filters. Unfortunately, that only delays the problem. If resumes are already an unreliable signal, adding more resume-based screening simply pushes poor matches further into recruiter screens, technical interviews, and engineering calendars.
What "AI-Generated CVs" Means in 2026
Not every AI-assisted resume represents the same challenge.
Tailored writing refers to candidates using AI tools to rewrite an accurate resume for a specific job description. The experience is genuine; AI simply improves presentation.
Inflated writing is more problematic. Candidates exaggerate projects, technical depth, or ownership using AI, creating resumes that appear impressive but don't hold up during interviews.
Fully synthetic applications involve fake identities, automated submissions, or proxy candidates attempting to move through the hiring process. While less common, they create significant hiring risk.
According to LinkedIn's Future of Recruiting report, AI is rapidly changing how candidates apply for jobs. As application volumes rise, many organizations are seeing resume quality decline rather than improve.
Why Resume Screening Isn't Working Anymore
Resume screening has always been an imperfect predictor of technical ability. What has changed is how easy it has become to create an optimized resume.
Today, candidates can generate resumes that closely match job descriptions within minutes. Keyword-based ATS filters often rank these resumes highly, even when the underlying skills don't match the role. As a result, recruiters spend more time reviewing candidates who appear qualified on paper but struggle during technical evaluations.
What Actually Works
Organizations seeing the best hiring outcomes are shifting their focus from resumes to stronger evaluation signals.
Start with Skills
Instead of reviewing resumes first, many teams now begin with a role-specific technical assessment. The assessment becomes the primary hiring signal, while the resume provides supporting context rather than acting as the initial filter.
Design AI-Friendly Take-Home Assignments
Rather than trying to prevent AI use, successful teams design assignments that assume candidates will use AI. Evaluation focuses on decision-making, technical reasoning, and the candidate's ability to explain trade-offs instead of whether AI helped write the code.
Standardize Technical Interviews
Structured interviews improve consistency by ensuring every candidate is evaluated using the same questions, scoring criteria, and rubrics. For remote hiring, identity verification also helps reduce proxy interview risks.
Review Every Signal Together
Strong hiring decisions rarely come from a single assessment. Teams that review technical assessments, interviews, take-home assignments, and recruiter feedback together are better able to distinguish genuine talent from polished resumes.
Where the Impact Is Greatest
The effects of AI-generated resumes vary across hiring scenarios. High-volume campus hiring often struggles with resume inflation, making skills assessments especially valuable. Remote senior engineering hiring faces greater risks from proxy candidates, while regulated industries require structured, well-documented hiring processes that can withstand audits.
What to Avoid
Adding more resume filters rarely improves hiring quality. AI detection tools continue to produce unreliable results, and requiring cover letters simply encourages candidates to generate more AI-written content. Likewise, "AI-proof" assessment questions often frustrate genuine candidates without preventing misuse.
Key Takeaways
AI-generated resumes have fundamentally changed technical hiring by reducing the reliability of resume-based screening. Organizations that shift toward skills-first assessments, structured interviews, and evidence-based hiring decisions are better equipped to identify genuine technical talent while delivering a fairer candidate experience.
Vibecoding Assessment: 2026 Guide for Engineering Teams
What Is Vibecoding? A 2026 Guide to Vibecoding Assessment for Engineering Teams
A vibecoding assessment — an evaluation of how candidates collaborate with AI coding assistants to build software — has emerged as a distinct hiring signal in 2026, separate from traditional algorithmic screens. Vibecoding itself is the practice of building software by directing an AI model in natural language: describing intent, reviewing generated code, refining prompts, and shipping working software instead of manually writing most of the code. As of 2026, a growing number of engineering teams are treating vibecoding assessment as a core part of technical hiring.
The term originated with Andrej Karpathy's February 2025 post on X describing the experience of "giving in to the vibes," where AI handles most of the typing while the developer focuses on direction, review, and decision-making.
Engineering teams are incorporating vibecoding into hiring because software development itself has changed. GitHub's 2024 Octoverse Developer Survey found that a large majority of surveyed developers (reported as more than 97%) had used AI coding tools at work, and Stack Overflow's 2024 Developer Survey reported that 76% of developers are using or planning to use AI tools in their development process (figures should be re-verified against the primary source before publication). Some practitioners report that senior engineers who cannot effectively use AI coding assistants are becoming less productive than peers who can, though this observation is largely anecdotal at this stage. At the same time, candidates who rely entirely on AI without understanding the generated code create risks that traditional coding interviews do not measure well.
This guide explains what vibecoding is, what companies should evaluate, where a vibecoding assessment fits into the hiring funnel, and the trade-offs teams should consider. It's written primarily for engineering managers and technical hiring leads designing AI coding assessment and AI coding interview workflows for AI-native development.
Defining vibecoding
Vibecoding is a workflow, not a tool.
Developers work inside AI-powered coding environments — the current market includes tools like Cursor, Windsurf, Claude Code, and GitHub Copilot Workspace, among others (listed as factual acknowledgment of the tooling landscape, not as endorsed alternatives). Instead of writing every line manually, they describe the problem, review AI-generated code, refine prompts, debug mistakes, and ship working code.
The AI generates much of the code, but the developer remains responsible for intent, architecture, validation, debugging, and overall code quality.
Core skills behind vibecoding
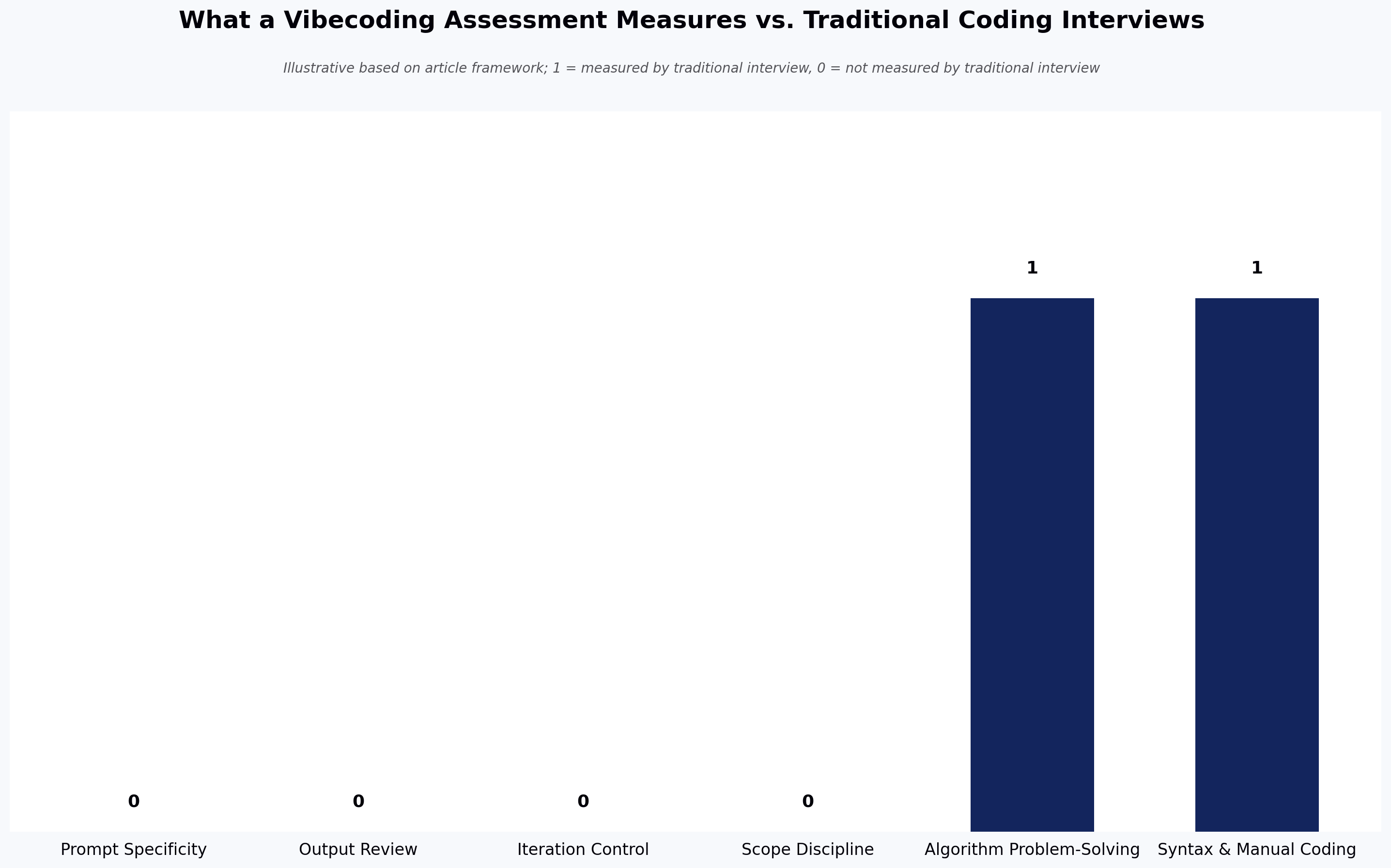
Effective AI-assisted developers consistently demonstrate four measurable skills.
Prompt specificity
They know how much context and which constraints to provide so the AI produces useful output.
Output review
Strong developers quickly identify hallucinated APIs, logic errors, security concerns, poor abstractions, and missing edge cases instead of trusting AI blindly.
Iteration control
They understand when to refine a prompt, edit code manually, or discard the AI's output and start over.
Scope discipline
They keep the AI focused on the current task instead of allowing it to rewrite unrelated parts of the codebase. In practice, scope discipline may be a stronger hiring signal than prompt quality — strong prompts are easy to imitate, but consistent scope control under time pressure reveals engineering judgment.
Why traditional technical assessments miss these skills
Most technical interviews were designed for a world where candidates manually wrote every line of code. Today's workflow looks different.
Take-home assignments no longer measure the right thing because AI assistance has become commonplace. The real question is no longer whether candidates use AI, but how effectively they use it.
Similarly, anti-AI proctoring methods like browser lockdowns or disabled copy-paste simulate outdated workflows rather than real engineering environments.
Algorithm-based interviews also measure less than they once did. AI models can often solve many standard algorithm challenges from memory, so memorizing textbook solutions has become a weaker predictor of on-the-job performance. In our experience, HackerEarth's technical assessment library has been moving toward more scenario-based problems for this reason.
What a vibecoding assessment should measure
A well-designed vibecoding assessment gives candidates access to an AI coding assistant, a realistic engineering task, a fixed time limit, and visibility into their workflow.
Rather than evaluating only the final submission, interviewers should assess how candidates approach the problem.
They should observe whether candidates break complex problems into manageable steps, write clear and context-rich prompts, carefully review AI-generated code, iterate intelligently when things go wrong, and ultimately deliver code that is reliable and maintainable.
Some practitioners report that output review and iteration strategy often provide stronger hiring signals than the final implementation itself — a contestable claim, but one that anecdotally holds up when interviewers review recorded sessions.
Where a vibecoding assessment fits in the hiring funnel
Organizations are adopting vibecoding assessment workflows in several ways.
Some companies are replacing lengthy take-home assignments with 60–90 minute AI-assisted coding sessions where interviewers observe both the candidate's workflow and final solution. As an illustrative example, one mid-sized fintech engineering team described (in an interview with our team) replacing an eight-hour take-home with a 75-minute AI-assisted screen and reported meaningfully reduced top-of-funnel drop-off, along with faster time-to-hire, because candidates preferred the shorter format. This is presented as directional feedback, not a benchmark.
Others keep a traditional coding screen to evaluate core problem-solving skills before introducing a dedicated AI coding interview round.
For senior engineering roles, companies increasingly conduct collaborative pair-programming sessions where the hiring manager, candidate, and AI assistant solve realistic engineering problems together. Many teams find this approach produces stronger hiring signals because it closely mirrors day-to-day work.
Challenges of vibecoding assessments
Like any interview method, a vibecoding assessment comes with trade-offs.
Evaluating AI-assisted workflows is inherently more subjective than grading algorithm questions, making clear rubrics and reviewer calibration essential. This is one reason rubric-based leaderboards — which turn subjective review into structured, comparable scoring — have become a common approach for teams building out AI coding assessment programs.
AI coding assistants also evolve rapidly, so assessments should be reviewed and updated regularly to stay relevant.
Another consideration is candidate familiarity with AI tools. Whenever possible, organizations should provide a standardized environment and clearly explain which tools are available during the interview.
Finally, AI cannot replace engineering fundamentals. Candidates still need strong knowledge of data structures, databases, system design, debugging, and software architecture. A vibecoding assessment should strengthen technical assessments — not replace them. It's worth noting a contestable prediction here: some argue vibe coding interviews will replace whiteboard interviews within two years. That view understates how much system design and architectural reasoning still matter for senior roles, and we expect whiteboard-style interviews to persist for design rounds well beyond 2028.
How HackerEarth supports AI-assisted hiring
Two HackerEarth products map most directly to the workflow described above. VibeCode Arena is a hands-on practice environment where developers can work across multiple LLMs, with rubric-based leaderboards that generate data usable for AI literacy programs, LLM selection, and L&D calibration — directly addressing the subjectivity problem raised in the Challenges section by turning reviewer judgment into structured, comparable scoring. For live whiteboarding or extended pair-programming with the hiring team — the senior-role scenario described above — FaceCode is the collaborative interviewing product, and it pairs naturally with Skill Assessments that measure the foundational engineering knowledge which remains essential regardless of AI adoption.
Frequently asked questions
Is vibecoding just prompt engineering?
No. Prompt engineering is only one part of the workflow. A vibecoding assessment also evaluates reviewing AI-generated code, debugging, managing iterations, and maintaining scope throughout development.
How long should a vibe coding interview be?
Many teams find 60–90 minutes works well for mid-funnel screens, where the goal is to observe the full loop of prompt, review, and iteration. Senior pair-programming interviews are often structured tighter — around 45–60 minutes — not because seniors need less time, but because the interviewer is present to steer the session, so less unstructured exploration is required. Both durations are practitioner conventions rather than fixed rules; calibrate to your role and rubric.
Can candidates game an AI coding assessment?
It is harder than gaming take-home assignments, primarily because prompt history and iteration steps are captured in real time. That makes post-hoc rationalization visible: a candidate who cannot explain why they refined a prompt a certain way, or who accepts obviously flawed AI output without comment, is easy to spot in the recording. Rotating assessment tasks regularly further reduces the risk.
Should junior candidates also use AI?
Yes, but fundamentals should carry greater weight. Junior engineers are more likely to accept incorrect AI output without sufficient verification, making foundational knowledge especially important.
What changes for senior engineers?
Senior interviews become less about scoring isolated coding tasks and more about collaborative engineering. Interviewers focus on technical judgment, AI collaboration, code review skills, and communication.
Key takeaways
Vibecoding reflects how software is increasingly built in 2026. The strongest AI-assisted developers know how to guide AI effectively, critically review its output, iterate intelligently, and maintain code quality. Traditional coding interviews miss many of these capabilities, making a vibecoding assessment a useful addition to hiring. When combined with strong evaluations of engineering fundamentals, vibe coding interviews provide a more complete picture of candidate ability.
Try VibeCode Arena for AI literacy and LLM calibration
CTA: If you're building AI literacy programs or calibrating LLM choice for your engineering org, request a VibeCode Arena walkthrough to see how rubric-based leaderboards can support your team's AI adoption.
Discover powerful tools designed to streamline hiring, assess talent efficiently, and run seamless hackathons. Explore HackerEarth’s top products that help businesses innovate and grow.
Assessments
AI-driven advanced coding assessments
Learn More
OnScreen
Interview every candidate. Defend every decision.
Learn More
Hackathons
Engage global developers through innovation
Learn More
L & D
Tailored learning paths for continuous assessments
Learn More