Why current LLM costs are not sustainable
aditya.patadia.orgCosts will continue to come down. That's how technology works. They will continue to come down further and further until they cross the threshold and become negative, and when that happens, instead of it costing you money to use GPT 5.5, you'll actually receive money! LLMs will become magic money generating machines, and I personally can't wait.
The problem space has a few aspects:
1. We're still in the "$5 airport Uber" era of LLMs. They're heavily subsidized, and everyone still complains about costs.
2. There hasn't been a real incentive to work on cost optimization for data centers and the hardware they contain. When/if price hikes happen and send people scrambling to use other models or drastically reduce AI usage, this will suddenly need to happen.
3. We're massively overusing SOTA models. As long as you're on a subsidized subscription, you can use Claude Opus 4.8 high to write blog article meta descriptions. If you paid by token, you wouldn't do that.
4. Open models are a wildcard that could completely change the calculus.
>3. We're massively overusing SOTA models. As long as you're on a subsidized subscription, you can use Claude Opus 4.8 high to write blog article meta descriptions. If you paid by token, you wouldn't do that.
This idea that the subscriptions are subsidized is repeated over and over, but I've never seen any proof of this. It seems to be entirely based on the inferred API cost the subscription usage could give you, but there are a lot of assumptions needed for that to follow.
> This idea that the subscriptions are subsidized is repeated over and over, but I've never seen any proof of this. It seems to be entirely based on the inferred API cost the subscription usage could give you, but there are a lot of assumptions needed for that to follow.
My claude code environment shows me cost per token used in that session, according to API costs. It regularly exceeds $200. I pay $200 a month for my claude subscription. That's fairly obviously subsidised, unless you genuinely believe their unit costs are 100x less than what they're charging.
The API inference cost to customers is not the actual cost of providing inference, and the cost of providing API inference need not be the cost of providing subscriber inference.
But they also determine the token prices. What you describe could also be true if they take a 5x profit margin on api tokens and 2x margin on subscriptions.
That's what they want to charge you. Not the actual cost. The actual cost is a gpu that's probably already paid off and about $2 of electricity
Most prices, like GPUs, are amortized over several years, when doing the calculus. Maybe they're already paid off, maybe they aren't. I would lean toward "aren't".
They are subsidized by the huge losses incurred by the AI companies.
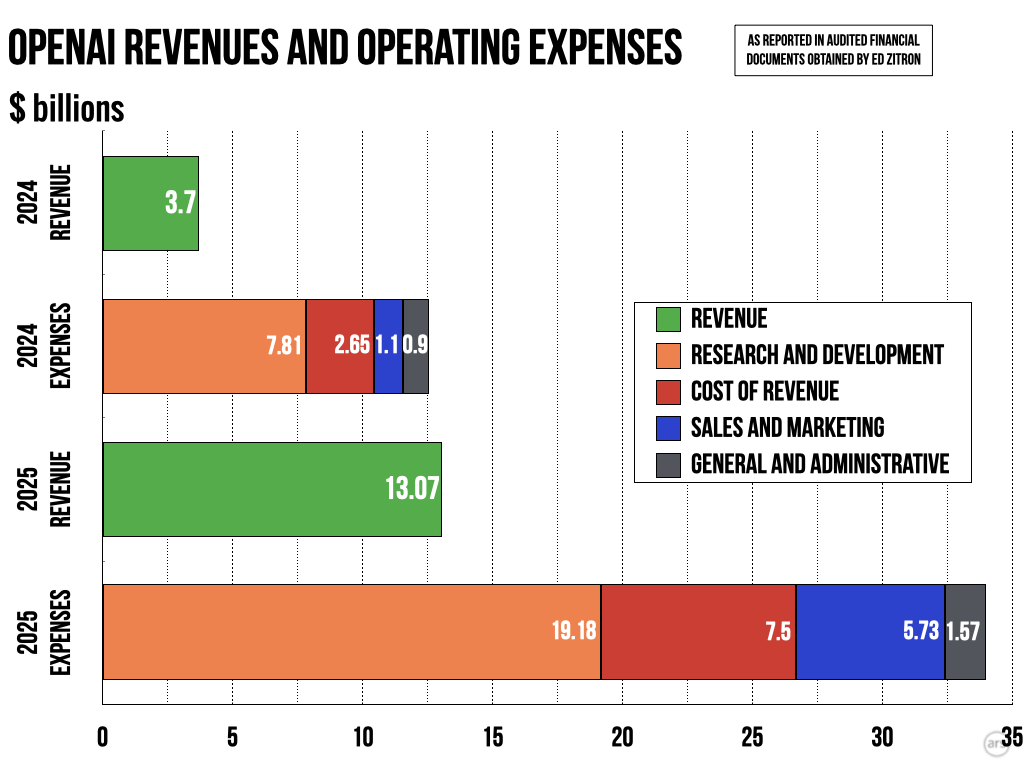
Data from OpenAI shows their 2025 inference revenue exceeded their cost of inference by a good margin (https://cdn.arstechnica.net/wp-content/uploads/2026/06/opena...). Saying this is being subsidized is like saying any investment in future productive assets is "subsidized".
Anthropic have claimed they expect their first profitable quarter this year. As far as we can infer their current API prices have decent margins.
Anyone can claim they are profitable, simply by reclassifying their expenses as some other thing or shuffling them to separate corporate structure. Until we will real financial audit, the CEOs claims are just a hot air.
OpenAI's leaked documents also said OpenAI was profitable on inference. The small resellers of open models have nowhere near the resources to optimise their models or inference and yet usually have a lower cost, why wouldn't the big labs?
Only if those losses are coming from subscriptions, instead of capex and training, which is not at all clear.
this argument assumes that capex and training costs will go down over time. but theyll have to keep up with one another and stay on top of latest knowledge so Im not sure if thats true
"Our 2015 car models are totally profitable if we will just stop making new cars and continue producing only 2015 models for the next decade."
I don't understand this argument. How does it make the subscription any less subsidised if the losses are only because developing the product is just so darn expensive?
Feels like arguing that it's not clear if Bugatti's losses came from selling the Veyron instead of designing and developing the Veyron.
The equivalent is when Amazon was running a loss because they were spending all their money on building warehouses. It exactly make sense, but that's the argument.
From the article:
> What is happening here is that leading AI labs are charging not only for inference but also for research in model architecture, training data collection and curation, model training cost (which can be tens or even hundreds of millions of dollars), paying their employees and recovering the marketing costs.
That's what's being subsidized.
You are saying it as if those costs were not necessary to provide the service.
They are not. They are necessary for the development of future models, which does not influence the availability of the current ones. Plus you have chinese models distilling current SOTA for pennies on the dollar, so as a consumer I never will be worse off in the long (1-2 years) run.
OpenAI inference revenue exceeds its cost of inference by a good margin in 2025 (https://cdn.arstechnica.net/wp-content/uploads/2026/06/opena...)
Great, but that's only a part of operational costs. A craftsman's revenue may exceed the electricity bill for the power drill, doesn't mean the business is sustainable.
Day 2 the craftsman has not made up for the investment/loss of their equipment. Not a useful example.
Sorry, I don't understand what you are trying to say.
Is this supposed to be some sort of gotcha? Apart from research and marketing, that's operational costs. I mean, every product could be cheaper, if you didn't have to pay for employees and means of production.
What assumptions are needed for inferring cost based on api pricing?
The API inference cost to customers is not the actual cost of providing inference, and the cost of providing API inference need not be the cost of providing subscriber inference.
That API pricing isn't massively inflated.
> 1. We're still in the "$5 airport Uber" era of LLMs. They're heavily subsidized, and everyone still complains about costs.
How does that figure look if you count in the current unprecedented LLM/AI-driven price inflation on both hardware, services and software? I don't believe we're exactly in the "$5 airport uber" era if you count that into your total.
To draw a parallel - airport Ubers are still $5, but you can't buy a 2nd hand prius any more!
Following your parallel: Except the fact that you still need a car in your life, even if you take an uber to the airport when needed :)
And in this analogy you need to spend a lot more when buying a car, no matter if it's a new or 2nd hand one, following the price inflation caused by cheap Ubers. So in essence, my question is how much have those cheap Uber rides then cost you in reality, when factoring in the directly related price increases for the things you need and buy? Is it a net positive or negative at the end of the day for anyone other than the very few at the very top of the system?
It's just making a parallel. We may be at the 10cent Uber. But oil and labour costs tend to go up, tokens as used today will probably cost what they cost today or less. But we won't just go to the airport, if we can go to Mars we will ask for it.
It about what you pay, not about what it costs.
Mostly agreed, however I'm not sure about 3: I suspect it works like gym memberships, and the companies mostly make their money from people who don't use the subscriptions all that much.
I think the problem is that the companies mostly don't make money, period. They may have better unit economics on underused subscriptions, but I don't see a world in which OAI/Anthropic don't heavily tighten the screws in the future.
Right now it's silly to default to frontier models, but it won't bankrupt your company. I believe in the short-medium term future, we'll need to be more deliberate about model choices.
In the long-term, of course, tech costs tend to plummet. Is there a future where in 15 years, my Apple Watch locally runs an Opus 4.8-class model? Maybe. And that would obviate this whole discussion.
I'm just here so I can look at my post history and have a hearty laugh about in a few years.
I'd say that is/was their long game, but it's still very much in hype phase so there's a lot of people intensively using these models, and I don't think it's anywhere near cost efficient right now. Maybe in the long run when people get bored with it, but on the other hand people are becoming dependent on it for everyday things.
We've already seen price hikes / token limits earlier this year, with suddenly some people running out of budget on the first day of the month. This will likely keep going for a while.
On the other hand, costs will drop too - open models and specialized hardware, as the article notes. The long question will be whether the companies will get a return on their invested billions. I don't think they will, not with the amount of competition they're facing, and I don't think any one company or model (series) has a monopoly yet. Popularity sure, but I'm confident a competitor may appear tomorrow and people will switch.
I follow a guy called Daniel McCarthy on LinkedIn who writes a lot on CLV and that seems to be his take. Even if theoretically you get way more than you pay with subscriptions, the vast majority of people are not power users.
The vast majority of active users of ChatGPT could successfully use a model like Gemma 4 12B with agentic search if x86 hardware didn't make that so difficult.
Likely even the E4B, which is really both fun and impressive.
That is clearly a big component of Apple's bet, anyway.
I have experimented with it and E4b is perfectly capable of being useful if you provide it with ready–to–use skills.
It's still more like programming than telling a chatbot to go make you GTAVI in JavaScript and make sure the graphics are as good as the original.
Maybe a safer prediction would be that most people will be fine just using hybrid agentic programs that run the models locally(probably with extra spyware). I think this is Apple's bet.
> I suspect it works like gym memberships, and the companies mostly make their money from people who don't use the subscriptions all that much.
I think it's like that, but not quite. The people who have a subscription but barely use it were probably never doing any serious work with AI in the first place. I.e., why would they get a subscription when their one or two chat questions (or, "make a picture of me as a superhero" prompts) per day can be had for free?
Especially with Claude, I think people who subscribe skew very heavily towards people that can very easily make more than $20 worth of queries in a month. And then there's the not-insignificant number of people who are tokenmaxxing.
It's like the gym membership model except ten percent of members are able to spend 72 hours per day at the gym while the rest spend 8 IMO.
Based on the people I know, they're paying because when ask they want the smartest model to be the one answering. There's still quite a difference between models.
Technically yes but it's not hard to get to $20 plan caps. Till current hardware prices cool down I don't see it being easy to make money on frontier models.
> We're still in the "$5 airport Uber" era of LLMs. They're heavily subsidized, and everyone still complains about costs.
Inference is not exactly cheap. Based on what do you think this is "heavily subsidized" still? What would to token cost have to be, with current models, for it to not be that? What do you know that has you make such a claim?
> 1. We're still in the "$5 airport Uber" era of LLMs. They're heavily subsidized, and everyone still complains about costs.
Do they? It's free right now at chat.com. After that it's $20/month which isn't much in the US. Three Starbucks or two meals at McDonald's will run you more than that these days.
> 2. There hasn't been a real incentive to work on cost optimization for data centers and the hardware they contain. When/if price hikes happen and send people scrambling to use other models or drastically reduce AI usage, this will suddenly need to happen.
It's actually worse, the AI explosion just hikes hardware prices faster than capacity can catch up - and it will likely not catch up in a while because investments are both expensive, long, and might not seem all that good idea while bubble is still bubbling.
The massive push frankly also made it unsustainable. If RAM didn't cost 3x and compute manufacturers would have to compete instead of selling every unit instantly at whatever price they want the frontier model tokens might've costed closer to sustainable amount
{kind=link}
> To give an example, just doing Typescript type fixes with this model across 50 files cost me $54 this afternoon.
If you can use a subscription with any of the SOTA models, do that.
Instead of around 4k EUR in token costs, my Opus usage costs me 108 EUR (with taxes) per month with their Max 5x plan. It's the same with OpenAI, those are heavily subsidized.
It doesn't make sense to pay per-token, unless you must.
> What is happening here is that leading AI labs are charging not only for inference but also for research in model architecture, training data collection and curation, model training cost (which can be tens or even hundreds of millions of dollars), paying their employees and recovering the marketing costs.
Chances are, they're never getting that money back. Best case scenario, the hype around AI slowly declines, worst case - it crashes and takes a part of the economy with it.
Also anyone doing distillation with hundreds or thousands of those subsidized attacks is probably winning big. Especially as the model architectures (e.g. DeepSeek V4) are more oriented towards efficiency.
> Last but not least and in fact the most important factor, is the ability of users to run local models. So far, almost everyone is using cloud-hosted models and local models are either too big to deploy or too slow to work with. With advancements in chips, this will change in 4-5 years’ time.
Currently beefy hardware to run them fast enough to be competitive with the cloud (at least 60 tps) is expensive and even then the small local models quite suck compared to SOTA or even DeepSeek V4 Pro and GLM 5.2, though they're way better than they used to be (compare Qwen 3.6 with 2.5 for example).
> If you can use a subscription with any of the SOTA models, do that.
Those subscriptions plans are for private use only! If you are running a business you are not allowed to use them actually. Anyway..
Opus 4.8 High effort seems adequate for me currently, at API pricing, with a $200/month budget.
This is at work where I don't work on greenfield or parallelize feature development.
I cannot see the agent burning through $50 for one moderately sized TypeScript cleanup in my setup. This sounds like something that can be improved on OP's side.
There have been rumors about a potential Sonnet 5 model release in the near future, which hopefully tilts the cost/benefit ratio further in our favor.
> I cannot see the agent burning through $50 for one moderately sized TypeScript cleanup in my setup.
Here's my usage, from the ccusage tool (slightly shortened for readability):
Now obviously that is all with the Max 5x subscription, other agents and models excluded.┌──────────┬───────────────┬────────────┬─────────────┬─────────────┬───────────────┬────────────────┬────────────────┬─────────────┐ │ Month │ Agent │ Models │ Input │ Output │ Cache Create │ Cache Read │ Total Tokens │ Cost (USD) │ ├──────────┼───────────────┼────────────┼─────────────┼─────────────┼───────────────┼────────────────┼────────────────┼─────────────┤ │ 2026-06 │ - Claude │ - opus-4-8 │ 13,635,792 │ 32,562,574 │ 177,985,265 │ 5,265,814,971 │ 5,489,998,602 │ $4665.09 │ └──────────┴───────────────┴────────────┴─────────────┴─────────────┴───────────────┴────────────────┴────────────────┴─────────────┘So per day that'd be around 155 USD (including weekends), which doesn't seem that far off, as long as the example cleanup takes up around 1/3 of one's daily work (or needs a lot of review/test iterations, or needs to review a lot of the existing code etc.).
Interestingly it seems 80% of the cost is in the cached tokens.
I do not know whether that is typical, or indicative of conversations with too many turns.
Not that I would worry about this on a subscription plan, but at work where we are billed at API rates, I try to move to new conversations as often as possible.
For agentic development upwards of 90% is pretty normal!
For example, if you make Claude Code explore a codebase, write a plan based on it and your requirements, do a few iterations of further specifying and altering it, and afterwards let it work for let's say 2-4 hours.
Sub-agents and dynamic workflows do alter the numbers a bit, but not to a crazy degree in the long run.
> I cannot see the agent burning through $50 for one moderately sized TypeScript cleanup in my setup.
I have absolutely seen stuff like this happen. Think about it, when you point Claude at a bunch of files, it has to suck them all up (tens of thousands of tokens), spend some proportional number of tokens doing stuff, and spit them back out (tens of thousands of tokens) for each pass in the "cleanup" loop. I had a similar situation occur a few months ago. Very small "add Javadoc to these dozens of classes" scenario. Sonnet rapidly rate limited my $20 plan so I switched to extra usage. A very small (IMO) number of changes later I had spent like $7 in tokens.
The main problem is you really have no idea ahead of time just how many tokens a given task is going to take. I suggest you try spending a day running your Opus 4.8 High effort on API pricing to see just how much your $200 subscription is being subsidized before you confidently state that $50 for some TS cleanup task isn't possible.
I've spend a week doing just that - I said at API pricing, $200/month currently seems adequate for 2-4 weeks of usage for me at work.
$50 would be 10M input tokens, not tens of thousands.
> I said at API pricing, $200/month
Well I saw $200/month and thought you were talking about a max plan, sorry. But I will say unless you're using that top end model extremely judiciously $200 for 2-4 weeks of work is similarly hard to believe (see the other poster breaking down their usage). What are you typically doing? Must be pretty hardcore stuff if you need to use the baddest available model. How many interactions per day? Care to share your token usage stats?
> $50 would be 10M input tokens, not tens of thousands.
Two things. One, input tokens are but one component, and the cheapest. Output tokens include the tens of thousands being spit out for file changes AND the thinking/crunching that you don't see. And that's the most expensive part. And remember, that's per iteration, not everything is one-shot (especially with tasks like "fix this large part of my codebase).
I don't have stats for what I use at work. This week I have been working on React frontend, also with TypeScript.
It is not my experience that you need to do 'hardcore stuff' to require the use of a large model. The difference in productivity between babysitting Sonnet and trying to get the result into a good shape compared to using Opus 4.8 seems large to me.
At home, unfortunately I only have the stats from the official apps rather than granular ones, and it looks like the Claude Desktop app is buggy: it was showing 17M tokens total in the last 30 days, but even just clicking on a conversation in my side bar increased the counter to 19M. It's clearly not working.
Codex shows up to 900M tokens total/week.
I think it will end up a game of haves and have nots - governments and companies with spare cash will go large and capitalise on the benefits of ai, everyone else will be left behind
The subscriptions will probably disappear or end up only allowed to use gimped versions of the models long term.
Why do you think that subscriptions are subsidized and not that enterprise tokens are sold at 3000% margin? There are few enough frontier labs that cartel is possible.
The value of tokens isn't necessarily objective and there's a bunch of factors that go into it: infrastructure costs and deprecation, the operational expenses for that and personnel, as well as a bunch of R&D for training new SOTA models that others can just distill at least partially.
The fact that they'll milk corpos that actually have money is obvious, compared to me because I'm broke, as are many other subscription users. The large AI labs don't seem to be profitable so I bet for the regular users there's plenty of subsidizing going on to at least get people to use the tech (and maybe that'd lead to some conversions at work or API usage eventually):
> OpenAI's net loss ballooned from $5 billion in 2024 to a staggering $39 billion last year, as it continued to spend heavily on AI model development and securing compute capacity, the Financial Times reported on Tuesday, citing audited financial figures confirmed by its sources.
https://finance.yahoo.com/markets/stocks/articles/openai-fin...
Inference itself might be profitable, but is just funding the training and other stuff.
I think this comes from the idea that serving these tokens without paying for training is already expensive, e.g. https://news.ycombinator.com/item?id=46613887 self-hosted solution might give you only 10-100x more affordable solution at cost.
So, given the SOTA providers with even larger models also need to continously be using considerable resources for training their next models, to fund future data centers, and make profit, the token costs are more likely reflecting the real costs, rather than the subscription costs.
Except there are plenty of inference providers worldwide (including the US) that serve open-weight models that are not subsidized, and are reasonable in cost. Or is your claim that those are all running at a loss?
So they do not train models, and in addition their models are expected to be smaller than SOTA models, although we cannot know for sure by how much.
So what's the price difference, 3000x?
My comment is about your statement "serving these tokens without paying for training is already expensive"...
One thing we do know from OpenAI's leaked financial document is that they are already profitable on inference, though that data is not broken down by cost and revenue of API vs. subscription. One important factor is that subscription inference can be optimized in ways to reduce cost (e.g., usage limits, batch optimization around API-prioritized inference, etc...). I think simply we do not know the actual cost of subscription interference for SOTA models.
I am using perhaps 15% of usage count on Claude with just the normal subscription. And I do full time software engineering and would say I use quite a lot of AI input on thoughts, designs and code drafts.
So how these companies and people manage to use these absurd amount of tokens is a mystery to me. It feels like this are just running huge amount of non-vetted data to the LLM's and or running loops against the LLM's which only produce fractional results if not wasted results for insane cost.
So really it is the equivalent of just burning money, or heating your house in the winter while having all your windows open.
Same for me, comfortable with a single Max sub, launching "claude --effort max" with Opus 4.8 (alas poor Fable, please come back!).
But try running Claude Opus at API prices through a 'clever' RAG based intermediate system 'managing' a 2024-era context size window completely unaligned with 2026 frontier model tool use expectations, that results in 100% cache miss and content coherency destruction on every single interaction. There's your typical 'Enterprise Agreement' GenAI setup.
I only really discovered this when trying to find out how my Enterprise friends' AI experiences were so completely opposite from my own successes as I could not believe how poor their results were even though on the surface it looked like we were using the same model, and I know they aren't 'bad' software engineers and developers.
> So how these companies and people manage to use these absurd amount of tokens is a mystery to me.
Fire and forget. They run multiple agents in parallel 24/7. AI isn't just a rubber ducky for them, its their main (only) tool at that point.
If you don't reset sessions eagerly or compact regularly it is easy to consume billions in input tokens while Claude churns away.
What is a "normal" subscription? Are you using Claude Code, or just Claude??
>>So how these companies and people manage to use these absurd amount of tokens is a mystery to me.
Absolutely!
I know some colleagues who are routinely spending thousands of dollars worth of tokens, I can't see to even max out the subscription limits even if Im working all the time. Curiously enough their output is lower too.
I mean have you tried to tokenmax?
It is not that hard. Just launch 10 different windows and make sure to loop back in after every turn and you will be burning billions of tokens per month in no time.
The question is what work do you do, that burns so many tokens.
Are in you sending it to work in nested for loops? If yes, what sort of work would that be?
I have already seen a number of people doing the math on what it would take for hardware to self host a Q8XL quantization of GLM5.2 shared between N numbers of people.
There's additional advantages that everything you query, all of your context cache and everything it outputs stays private and can't be arbitrarily turned off by external interference.
Personally I think it would be a fairly good bet that something with the 1TB of RAM needed to properly self-host GLM5.2 will still be a very usable piece of hardware in 4 to 5 years from now. There will be even larger, newer models available, sure. But there will also be better models that continue to fit in the same size.
Back in the earlier days of the internet, when "dedicated servers" were a competitive advantage, hobbyists and small dev shops definitely shared dedicated hardware.
So you could see small LLM co-operatives working out, yeah.
But my thinking is that this four-to-five-year scenario just won't come to fruition, because the whole concept of needing to run these massive, massive models will slightly more likely be rendered moot by smaller models with better reasoning capacity, and possibly even in that timescale by hardware innovations.
One of the biggest problems I have with the whole "we won't be profitable until 2030" model is that 2030 is almost exactly as far into the future as the launch of ChatGPT is in the past, and in that time, models far more capable than that first ChatGPT have been made available to freely download and run on desktop hardware that existed before it launched, and the entire non-model surrounding functionality of that original ChatGPT plus many more functions is now not much more than a routine weekend coding project.
I don't know why the market would entertain the idea that no upset like that is possible in the same period of time again.
the biggest problem is most ai will be local by 2030. Every future device you buy will have AI compute on it somewhere, built in, like it has on-device floating point.
On top of this, people are constantly coming up with better ways of running models on less special hardware and "good enough" models are now existing for most tasks.
So where does that leave the frontier labs? Drug discovery? Maybe some hard math problems? I mean it's not that big actually...
We're in a brief window where this is profitable, like batch computing was in the 70s. However, once your own device can do it, you're going to start migrating.
> So you could see small LLM co-operatives working out, yeah.
Only on a pay-per-token basis, I think. Unless it's a very tight-knit circle of folks. Fixed monthly subscription costs I doubt would work in that model. Because you'll get the inevitable: someone pegging the service 24/7 because it's "unlimited" while everyone else suffers.
Well, many of us who shared hardware also ran monitoring to make sure the share was fair; there used to be a whole industry for that sort of quota stuff.
You can presumably hard-limit LLMs the same way — total, burst quotas etc.
(Suddenly getting a very fun flashback to the environment in which someone first explained Markov chains to me — MediaMOO. A text-based chat environment with configurable limits on the number of CPU "ticks" you were allowed in order to do things)
the same argument was made 2 years ago: "in 2 years we'll be able to run GPT-4 level models on an expensive laptop, most people will be using this instead of the fancy cloud models".
we are there, Gemma4/Qwen3.6 are GPT-4 level models runnable on a fancy laptop.
but expectations shifted, nobody wants a GPT-4 level model anymore
Well, then you also have to assume higher expectations put on commercial offers raising operational costs. So, your objection really is a moot point.
Regarding the 'no more training data' point.
I agree that text capabilities are maybe hitting the limit of available training data.
But, the big AI platforms are now being used by so many people for so many things that this becomes the new data source for new and different types of abilities.
Theres also the fact that the AI story means they've been able to fund huge data center builds and hardware innovation. This will lift the existing AI/ML applications (e.g. robotics, sensing) in themselves, as well as the fact that they can be integrated with the text models in probably really useful ways.
So I think, maybe text abilities are nearing the end, but intelligence and other interfaces with the real world still have a lot of space to grow.
There is a wave of users switching over to DeepSeek Flash. There are Reddit threads of users sharing billion token spend for $20.
If all of global spend on Anthropic/OpenAI/Gemini APIs just switches over to DeepSeek then easily we can decrease total AI spend by 10x
v4 flash was really, really good in practice for me. While on openrouter it's around 1/100th of what the "SOTA" models cost.
But billions? A bit exaggerated.
DS is restricting the "expert" model usage already, because they do not have enough compute.
Probably won't be too long before the government decides to block deepseek's website based on "security" concerns.
It’s in the doing with the DAAMT Act and soon foreign AI companies will be on the entity list. Circumvent this sanctions and count with assets forfeiture, civil penalty and criminal prosecution. This will eliminate access to Deepseek and so on overnight. Cherry on top most westerners will face similar problems due to secondary sanctions.
Deepseek's models are open-weight and hosted all over the world, how would blocking deepseek's web sight do anything to stop its model's use?
Deepseek will be sanctioned and therefore no provider will offer it anymore. Only way to use it then will be private but even that will be forbidden if it gets classified as threat to national security.
>>Deepseek will be sanctioned and therefore no provider will offer it anymore.
That is possible inside the US. How do you do it all over the world? You have to convince every country in the world not use frontier models? Even worse how do you convince all the countries to not build their own models?
And then USA will have a disadvantage compared to rest of the world with cheaper LLMs and american AI companies will have tougher time surviving on domestic spend alone.
Who is "The government"?
China or your local one?
American
I am not sure if that is wise. It’s a hostile superpower after all
DeepSeek first and foremost is a business. Yes, being a business in China means risk of being ordered tomorrow to do something that is not in your best interests. But now we know the US is not immune to that level of government oversight either.
The difference is DeepSeek and other Chinese models are open weights.
By "hostile superpower" you mean USA?
As an European, today I certainly classify USA as a "hostile superpower" because the actions from the last few years of both the US government and of certain big US companies have stolen a lot of money directly from my own pocket, by artificially limiting competition in several important markets, like smartphones, SSDs and memory modules, thus greatly raising the prices in comparison with what they would have been in normal market conditions (i.e. if the US government had behaved after the same rules that they had forced upon the other countries for decades, by various methods of propaganda, bribing and blackmailing).
I'm in Europe. The only superpower that's been hostile to me, very directly - was US, when they asked a company I was relying on to limit model access based on nationality.
China has (so far), never done that to me.
Hostile? Us or them? I beg to differ who the hostile ones might be.
We are hostile to each other. It's ignorant or propagandistic to pretend it is only one sided. The concern is valid, if vague and unproven
USA is hostile to the entire world, because the US actions already for several years, but especially during the last year, have caused global price rises in more and more product categories, starting with smartphones, then with SSDs, then with DRAM and HDDs, and eventually with almost everything that is affected by energy costs.
This is not some hypothetical hostility, but billions of humans from all over the world have been losing more and more money in recent years and in recent months, from their own pockets, much of which eventually reaches US companies, like Qualcomm and Micron (or South-Korean companies, who have also benefited from the US policies).
Of course, China is not trustworthy, but until now, unless you are a neighbor like Taiwan, their hostility is only hypothetical and in the future, not real and in the present, like for USA.
Which one? China or the US?
All AI is a hostile superpower. Might as well use the cheap one.
Well... Open weights on premise is politically neutral.
The training might be political. Search for "deepseek tibet backdoor"
Try doing it at scale for a whole office. Not trivial.
There are plenty of US based hosters racing to optimize and drive efficiencies
Literal race on twitter posting to increase token throughput and drive down costs on these Chinese open source models
You could probably do with couple of instances. People rarely use ai 24/7, so right now you can oversubscribe and still have acceptable latency and high utilization rate.
Would prefer not to offend the author, but I do believe this article has very little for the HN audience. No new insight, and no numbers or new information.
Is there any place with better curation? I notice quite a few articles summarizing the state of AI that feel redundant with one another
It's weird to see people claiming that model capabilities are plateauing. It wasn't until late last year that we even had strong coding models. Imagine if, less than a year after the first iPhone launched, people claimed that smartphone capabilities were "plateauing" because Apple hadn't yet launched a new phone. And it seems the issue is less than "models aren't getting better" than, "models are good enough to handle 99% of the coding tasks people give to them".
I wonder how's model improvement/dollar invested ratio going. If gains are made by simply spending increasingly vast amounts of cash that's not going to last.
People claim what they see. I see no improvement since opus 4.6, quite the opossite.
That's only a few months old. Just because there's time between big releases doesn't mean progress stopped.
Fable seemed very clearly a step up in my one afternoon of usage. I gave it several bugs that other models had failed at repeatedly (in a mess of a vibe coded side project) and it fixed them each in one prompt.
> Just because there's time between big releases doesn't mean progress stopped.
No, but progress not stopping doesn't mean it's not plateauing. I believe 'plateauing' is understood as the process of approaching a plateau, not being stuck on a plateau already. So, the question is about the rate of progress, not its existence.
Which is not even 5 months old.
Prices will go down one way or another. That is of course unless the market gets cornered by restricting model use, restricting supply of essential hardware components or raw materials to make this hardware, etc.
In terms of running the model locally vs a service provider, that will be down to convenience more than anything else for the same reason why not everyone is hosting their own website at home on their own box.
Token prices will go down for sure, but i watched a video interview on yt from cloudflare ceo and apparently the internet traffic of agentics increased and took over human.
If we continue this year with a2a, agentic layer and co, there is probably a huge bulk coming up with a lot more agents running a lot longer and talking to each other to solve issues which will increase token usage significanlty.
My thinking is the same. I believe that AI will be the predominant forms of "intelligence" online probably taking as much as 90-99% of all traffic. It is not hard to see where this is going.
The price for tokens will become a proxy of consumed energy in my mind, i.e. tps will be something like kWh almost directly correlated in terms of cost.
> We are seeing improvements with each model release these days but it’s clear that the improvements are getting smaller and smaller.
This is obviously untrue, both with GPT-5.4, and Claude Fable as examples in the last 6 months.
I would struggle to ascertain the day-to-day difference between GPT-5.4 and GPT-5.5 tbh. Also, imho, Fable is highly hyped, I don't think it is dramatically better than Opus 4.8. Maybe my tasks and interaction with AI is relatively simple (i.e., lots of Rust programming, Linux system engineering stuff).
I haven't had enough time with fable, but I had to look back on how i worked with claude just 6 month ago to remind myself that it got a lot better.
Like i still used plan mode 6 month ago now I don't.
I would argue that with every model release we have a new learning phase.
> the improvements are getting smaller and smaller
The AI haters have been saying this for 2 years now.
gpt 5.5 regularly wastes tokens on wrong commands, requires lots of handholding. I highly doubt there's substantial improvement
This entire discussion is on the supply side chips, available weight, and switching cost. What is missing is the demand aspect. The firms that will be the most impacted when there is a drop in price are not Uber or Microsoft; it is that small privately-held firm using spreadsheets and hunches to make business decisions and cannot afford to invest in AI due to the high costs involved currently. The minute inference becomes affordable, an entirely new set of users joins the scene. The real issue is not what will happen to the laboratories it's what gets built for that next wave and whether it's actually useful or just cheaper versions of what already exists.
I am convinced that the combination of capable open weight models and specialized hardware will mean that Apple (and other hardware providers) will start shipping computers with built-in, hardwired, "LLM-on-a-chip" cards that are capable enough to meet 90% of your AI needs.
I really believe that in the near-term future we will run our LLMs in hardware, not in software. Hardwire a capable model into a device the size of a graphics card, embed it into a laptop, and you have something that uses less power, does faster inference, doesn't require additional CPU or memory, doesn't cost a monthly fee, and will probably eventually be available for under a (few) hundred bucks.
A 200 USD Clause 20x subscription gives you 13,000 USD equivalent in API credits. And those are believed to profitable for Anthropic while the 200 USD are properly not, if used to a large extend.
If the subscription is gutted by factor 2/5/10/20/65 to make it more profitable for Anthropic it will be harder for users to justify the subscription.
On the other hand 13,000 USD in API credits can go a very long way if used ergonomically. For instance using a max context length of 200k is multiplying your reach in comparison to 1m context.
These ridiculous market caps can only be justified if LLMs can ultimately produce outputs that are above human capabilities OR reduce costs and perform human tasks for cheaper than the human rate. Neither of these things have happened thus far and the incremental gains are decreasing more and more.
The OpenAIs and Anthropics are going to get eaten by open source, I don't see prices going up, prices are going to crater. The models are going to be more and more commoditized.
A few thoughts:
1. Chat, being 3 yr old, is a fairly mature and solved problem today. Top companies aren't even talking about it anymore! Gemma 31B does it amazingly well (for $0.4/1M token output). Practically every near-SoTA and SoTA model does simple "chat-like" QA amazingly well -- summarization, basic question answering, single- or few-step search.
2. Tasks -- or knowledge work on a computer -- are the new frontier. Computers have become competent only recently, and only for some of the tasks so far. I'd guess another 2-3 yr development cycle, after which "el cheapo" models will be virtually indistinguishable from SoTA.
As tasks are the new game in town, AI labs can still charge a premium for it. That premium has disappeared already for chat; most users cannot tell 99% correct answer from 95% correct answer; nor do they always wish for maximum accuracy.
3. What comes after Tasks? I think today's AI startups should figure that one out and solve it before everyone else.
Jobs come next after Tasks
> What is happening here is that leading AI labs are charging not only for inference but also for research in model architecture, training data collection and curation, model training cost (which can be tens or even hundreds of millions of dollars), paying their employees and recovering the marketing costs.
Of course they do. How else do you expect them to pay for that? If you buy a Foo from Acme, Inc, you aren’t only paying construction costs, either.
> On the other hand, once an open weight model is released, any inference provider can easily host it and just do some markup on inference cost. This proves way cheaper than running a frontier AI lab.
The only logical conclusion for commercial AI labs is to never release their models as open data, and try to stay ahead of open models. One way to do that is by having better models, another by having more users (because that decreases the per-user costs of creating the models, decreasing the price difference with companies running open models). The frontier labs are aiming for a combination of both.
As information flows abundantly, and as information processing flows more abundantly, where will the bottlenecks in the system emerge? It surely won't be in design and production. It probably won't be in chips, infrastructure, and energy (already commodities, increasingly competitive). So... what's the bottleneck? Political will? Human discernment/taste? Raw materials?
> doing Typescript type fixes with this model across 50 files cost me $54 this afternoon.
Not trying to be harsh, but that sounds like a skill issue. You have the language server to lean on; easy feedback loop; sub agent per type.
> To give an example, just doing Typescript type fixes with this model across 50 files cost me $54 this afternoon.
1. How much it costs in terms of programmers' salaries?
2. Can DeepSeek do this (I bet it can) and how much it costs?
The fact the author ever had the idea of using a SOTA to solve do this means LLMs are actually quite cheap.
> To give an example, just doing Typescript type fixes with this model across 50 files cost me $54 this afternoon.
Who in hell would actually do this? That's a level of problem that any of the flash-class models can solve.
Hand that sort of thing to GPT-mini, Haiku, or DeepSeek Flash, and save the big guns for big architectural problems.
One thing missing here is the maturity of agent harnesses. I’m finding the free deepseek flash model in opencode can handle all of my simple tasks, because the harness is so good. Soon that will be a local model.
And the reality is that other industries aren’t finding the use for LLMs as much as programmers are. Sure there are some benefits but you can’t fire your marketing department and replace it with AI
AI is google-in-a-box, and there will be dedicated hardware to run it locally like there was with the crypto ASICs.
I feel the only ones losing are the AI startups and Google. This is why they're trying to morph into a social-media like experience of simulated human interaction that can monetize a certain demographic of vulnerable people.
I don't agree with Uber & MS buring their AI consumer budget, it is hard to believe they miscalculate something this significant and not realize it within the first month itself.
Curren prices will come down. There is a lot of potential for optimization. Energy efficiency, energy generation, self hosting, model size and specialization. Etc. Rught now the state of the art is powering data centers with gas powered turbine generators. That's not very efficient.
Of course, but will the AI startups with their SaaS business model survive?
The current costs do not have to be sustainable for the SOTA model providers as they grow their user base. But I really wonder about the future as the costs have to increase at some point (to be sustainable) but at the same time the competition and local models get better and better.
The more I think on the problem, the more I believe this will be solved with US interventions. And the interventions will increase inflation by a lot, so prices will not go down.
The other alternatives with LLMs becoming more expensive in an Uber-like move may not work due to a lot of competition. I also don't think usage will increase 10x. I don't always have coding tasks for an LLM despite it being good.
My reasons to believe so are outside of what interests HN community and I am neither endorsing this behavior, nor I think it is that simple. But US also has a huge debt that it must service. Wouldn't it be convenient if it was suddenly halved in actual value?
unlikely scenario as the main mandate of the federal reserve is to keep inflation in check. inflation reaching such levels would also cause interest rates to rise astronomically, and this would make the debt harder to service
There is a good and cheap alternative: R9700 32GB + Qwen 3.5 27B Won't give you SOTA performance, but will be as good as Sonnet a few months back.
> and Microsoft, Salesforce and Github are taking steps to reduce AI spend by employees.
anyone got a source? sounds juicy
Alright, instead of all this yapping here's the real numbers you can use as a guide:
8xB200[1] costs around 250k DIY and 450k from an enterprise builder so that will be our cost factor, these consume around 7.8kw at 100% load with median load of around 7kw (optimistic) which means that a 240kwh solar installation would be enough to supply it (72kwh buffer for bad weeks / winter) and that will set you back around $240k: this includes battery storage, installation and inverters, diy cost would be lower at around $160k.
This puts the cost of the entire system anywhere from $410k to $690k. This does not take in any property tax or land ownership into account since honestly it varies too much. The solar is simply used to provide a fixed cost basis for powering hardware instead of monthly recurring payments. Financing a 5 year loan would cost anywhere from $8,313 to $15,700.
Now let's do the math for glm-5.2[3], a fully optimized theoretical build can do around 1200tok/s which means that's around 13-14 streams of ~90tok/s on average, pushing batching further and limiting context size to around ~300k with ~150k median) you can achieve up to 37 streams at around ~40tok/s pushing performance envelope to 1400tok/s. This means you are able to generate 2.5B to 2.9B tokens in 4 weeks.
Which means putting the numbers together you can serve 1m tokens at $2.86 to $3.32 per million output tokens all else being equal. Considering that glm-5.2 is approaching opus level intelligence it's pretty safe to say that same applies for frontier labs. Input/cache write/cache reads are very difficult to price, so this assumes you're providing input / cache for free[4]. As a very heavy user I generate around 2M to 5M output tokens a day which would put me at $5.72 to $6.6 of cost per day totalling $200 a month[2].
What I also don't mention is that frontier labs have BY FAR the lowest cost per token out of any provider out there due to the amount of money they also invest into efficiency gains. This was proven by the fact that anthropic saw a huge exodus of openai users put strain on their systems and with efficiency optimizations alone they managed to mitigate a bulk of capacity issues, altho they did run into limits and had to begin spreading out the duck curve, but I have zero doubts they're getting percentage points of improvements month to month.
[1]: H300's are unobtanium unless you're building rack-rooms, H200's are not that cost effective and saturate too fast while having poorer efficiency, only capable of running flash tier models.
[2]: Okay, I didn't expect to arrive at the $200, this is kind of entertaining.
[3]: fp8, z.ai serves fp8 according to openrouter.
[4]: Assuming you want to charge for input / cache, cache reads make up roughly 30% of the cost, output 20% 50% input so to price it out it would be roughly $.3 for 1m input, $.015 for cache reads and $1.5 for output. Judging by https://openrouter.ai/z-ai/glm-5.2#pricing, appears that my math checks out.
I think companies will fire 5-10% of people and convert them to token budget.
I also believe that before any real companies are running these models locally, they will already have some kind of agentic layer.
With the current frontier model lab progress, i do not see any real company which makes real money, running local models.
Running local models is easy for me, for sure not that easy for any company. Your DC needs to be able to host GPUs, it needs the cooling power, you need to have a DC. Without a DC, you need to have someone maintaining critical infrastrucutre, taking care of model evaluation etc.
For external parties, there might become a new business model: You might not hire an external anymore, but a token budget and the 'operator of the token budget'.
The current chip fabs are full, developing a high end / cheapisch local LLM Chip will still take a few years as long as the DC GPU demand is still as high as it is.
I work with large enterprises that _only_ run critical workloads on locally hosted models. Think banks, insurance, etc--businesses that absolutely cannot leak any data. They also have CC and Codex, but their use is extremely restricted; anything of consequence runs on models running on GPU clusters in their own datacenter.
I work at large enterprise and they are happy paying Microsoft and AWS for model hosting.
But for sure there will be use cases of very critical data, but at the end the question will still be how big they are in comparision to the rest of the market.
These cricial workloads also have the cost issue, right? so will they reduce workforce to compensate for the budget?
I am calling it now. LLM hosting is the new web hosting. You will have a market of hosting providers offering you access to LLM compatible hardware (the Hetzners of the LLM world) as well as virtualised LLM access (the Heroku of the LLM world). These will compete along pricing, ownership axes while frontier labs will compete mostly on performance, integration and ease of use (think Wordpress).
That's the only way I can see frontier labs charging high enough to sustain the cash flow needed to operate as racing to the bottom is not possible for them.
It is interesting to think whether this is another "Cambrian" era like the smartphone OSes when you had Symbian, Android, iOs, Windows Mobile and so many others competing.
I work at a very big company and they just pay azure and aws to host claude and co for them.
So the hyperscalers already won for now probably.
At the end of the day, you send a lot of personal data to these endpoints. If you already host everything through microsoft already, LLM hosting is then a no brainer.
i see all these claims its too expensive but why arent we comparing it to wage costs, is $10-20 an hour actually expensive?
The author understands well that Opensource is catching up but I think that the gap will remain constant - SOTA models will still be more performant.
The author mentions $54 in costs but the reality is that developers are paid around this much per hour.
What is likely to happen: LLM performance goes even higher and can do tasks that take humans days to accomplish. You then have to compare LLM cost with human cost - something the Author has forgotten in their analsys.
> The author mentions $54 in costs but the reality is that developers are paid around this much per hour.
Sure, but imagine a situation where you've spent an hour going back and forth with the LLM trying to fix a problem and at the end of it you've only made minimal progress. Now you've spent an hour of your time AND $54 with little to show for it. It's a metric I don't think many people track: the cost of going in circles with an LLM for an extended period of time while burning tokens and still not resolving the problem.
That happens with humans too and for sure LLMs make it better not worse.
I know the number of times I tried to do something where the answer was simple but I took a few days to get there.
I've posted this anecdote before, but i feel its worth posting again because I've seen this spread further.
>amusing side note: >Was in a meeting reviewing a potential new product, it was going well until they showed us that they had added AI to it (of course they have). It was pretty obviously just shoehorned in, and one part of that obviousness was that they had a column that showed how many tokens it took to make each query.
>I asked who is paying for the tokens, they said its included in the license. I said, so is there a budget or is it all you can eat. they said good question they didnt know and would get back to me. I said the reason i asked was just one query there had a 250k token burn on it. and it was a fairly simple query about one device.
>then, one of the execs on their side was heard saying out loud "Why are we even showing this to the customers?"
>it have us quite a chuckle. But lesson learned... the cost of adding AI to anything isnt really being accounted for let alone the true cost of actually running the AI.
>all things AI are going to get more expensive. even if you dont want the AI aspect.
> GPT 5.5, for example, costs $5 per million input tokens and $30 per million output tokens. This is currently the costliest model available as per OpenRouter.
claude 5 mythos and fabled are 50$/MOutTok. Previous models were priced at 75$, so presumably they found the "too expensive" price point.
>Most AI labs have likely ingested everything available in digital and print media for the model training.
This isn't how coding models get better though. Why would this have anything to do with plateauing?
This is no surprise at all and was very predictable.
The Chinese open weight models were always winning the AI race to zero where as the likes of Anthropic and OpenAI have no choice but to increase token costs.
Even Microsoft wants to use some of the Chinese models only realizing how expensive both the frontier models are. It turns out that Jevon's paradox does not exist in the US (it exists in China).
This "Tokenmaxxing" marketing stunt was a scam for the frontier models to raise even more money at unsustainable valuations.
Not the end of the world!
OpenAI and Anthropic will just go back to entirely healthy valuations of ~$5-10B each and the industry carries on.
Spot on. From an US outsider's perspective there's so much ridiculous stuff going on that you feel like you're watching an episode of "bum fights". I don't think US knowledge workers alone can carry this bubble.
i think we have the causation backwards here. llms aren't expensive because they have to be — they're expensive because we keep reaching for the expensive model instead of putting any effort into making the cheap one good enough.
a surprisingly large fraction of production workloads can be handled by smaller models with the right scaffolding. it's often easier to switch to a larger model than to engineer those pieces, so many teams never bother.
my intuition is that a lot of the current "ai cost crisis" is really an orchestration problem rather than a model pricing problem. before asking whether frontier pricing is sustainable, i'd first ask how much of that spend is simple tasks being sent to the smartest available model by default.
my bet for the next few years is that the model itself stops being where the value is. frontier models will become more like commodities, and the real difference will be the layer around them as routing each task to the cheapest model that can do it well, verifying the output, and only escalating when needed.
eventually, asking "which model do you use?" will sound a bit like asking "which cpu do you use?" the engine still matters, but the system built around it matters a lot more.
Unfortunately, the economics of what you suggest do not justify the trillion dollar valuations of OpenAI and Anthropic.