RISC-V Instructions
robalni.orgWhat seems to be missing are the hardware optimized and accelerated short and big memcpy/memset.
On x86_64, on modern micro-archs, "rep stos[bwdq]" and "rep movs[bwdq]". I bet that, in modern binaries, memcpy/memset call sites are actually place holders for such instructions (before the memory segment goes back to Read/Executable), registers are rdi,rsi,rdx (rcx would be pushed on the stack or the code generated to account for just rcx availability on the call site).
Also, expect x86_64 -> risc-v port bugs because to: byte->byte word->halfword doubleword->word quadword->doubleword
> On x86_64, on modern micro-archs, "rep stos[bwdq]" and "rep movs[bwdq]". I bet that, in modern binaries, memcpy/memset call sites are actually place holders for such instructions
You'd lose that bet.
An optimised memcpy/memset using normal instructions is typically much faster than "rep movsb" (etc).
It is however a lot of code, so "rep movsb" has its place in low-memory low-performance settings.
> hardware optimized and accelerated short and big memcpy/memset
Classic CISC fallacy: if they made an instruction to do it then it must be the fastest way to do it.
Nope. That wasn't even the intention of the designers of things such as the VAX and 8086. Those complex instructions were provided to let assembly language programmers write code a little more quickly, even if it ran a little more slowly, because according to the 1970's "Software crisis" theory computers were rapidly getting cheaper, but programmers were scarce and expensive, and vast amounts of software needed to be written.
The whole key was to make (assembly language) programmers more productive, and if that made the code slightly inefficient that didn't matter because you could easily buy an extra computer or two, and anyway next year's model will be faster.
"rep stosb" has been optimized since Ivy Bridge CPUs.
> Beginning with processors based on Ivy Bridge microarchitecture, REP string operation using MOVSB and STOSB can provide both flexible and high-performance REP string operations for software in common situations like memory copy and set operations.
> Beginning with processors based on Ice Lake Client microarchitecture, REP MOVSB performance of short operations is enhanced. The enhancement applies to string lengths between 1 and 128 bytes long.
* https://www-ssl.intel.com/content/www/us/en/architecture-and...
See my other reply for more details.
An optimized memcpy/memset using normal instructions is much faster than "rep movsb"/"rep stosb" only in certain ranges of the copy/fill size (on all modern Intel/AMD CPUs).
Using normal instructions for memcpy can have around a double speed for copy sizes under 1 kB, but it is always slower for very big copies.
For an optimized memcpy/memset, one must choose between normal instructions and "rep movsb"/"rep stosb" for each copy/fill, depending on the CPU model and on the copy/fill size.
Gosh that's complex.
On all RISC-V CPUs I have currently access to with the pre-ratification RVV 0.7.1, the simple 9 instruction memcpy function shown by camel-cdr is faster than any other kind of memcpy (simple byte-by-byte loop with no decision overhead, or complex glibc function) at EVERY sensible size.
These range from the C906 core found in Linux-capable boards costing $6 or $10 (Pine64 Ox64, Sipeed M1s, Milk-V Duo), the the C920 OoO cores in the 64 core SOPHON SG2042.
Here are some numbers I ran on a 1 GHz C906 over two years ago:
https://hoult.org/d1_memcpy.txt
The short RVV function has absolutely constant execution time out to n=64 AND this time is 40% less than standard memcpy even at size 0 or 1 byte, and from 8 to 128 bytes it is at least 3x faster.
A 1.8x advantage is maintained for any size that fits in L1 cache, then after that both are able to saturate the memory bus.
Remember, this is a low-end in-order core (similar to Cortex-A35) designed in 2019, with only 128 bit vector registers and ALU. But the same thing applies on newer, higher-performance cores.
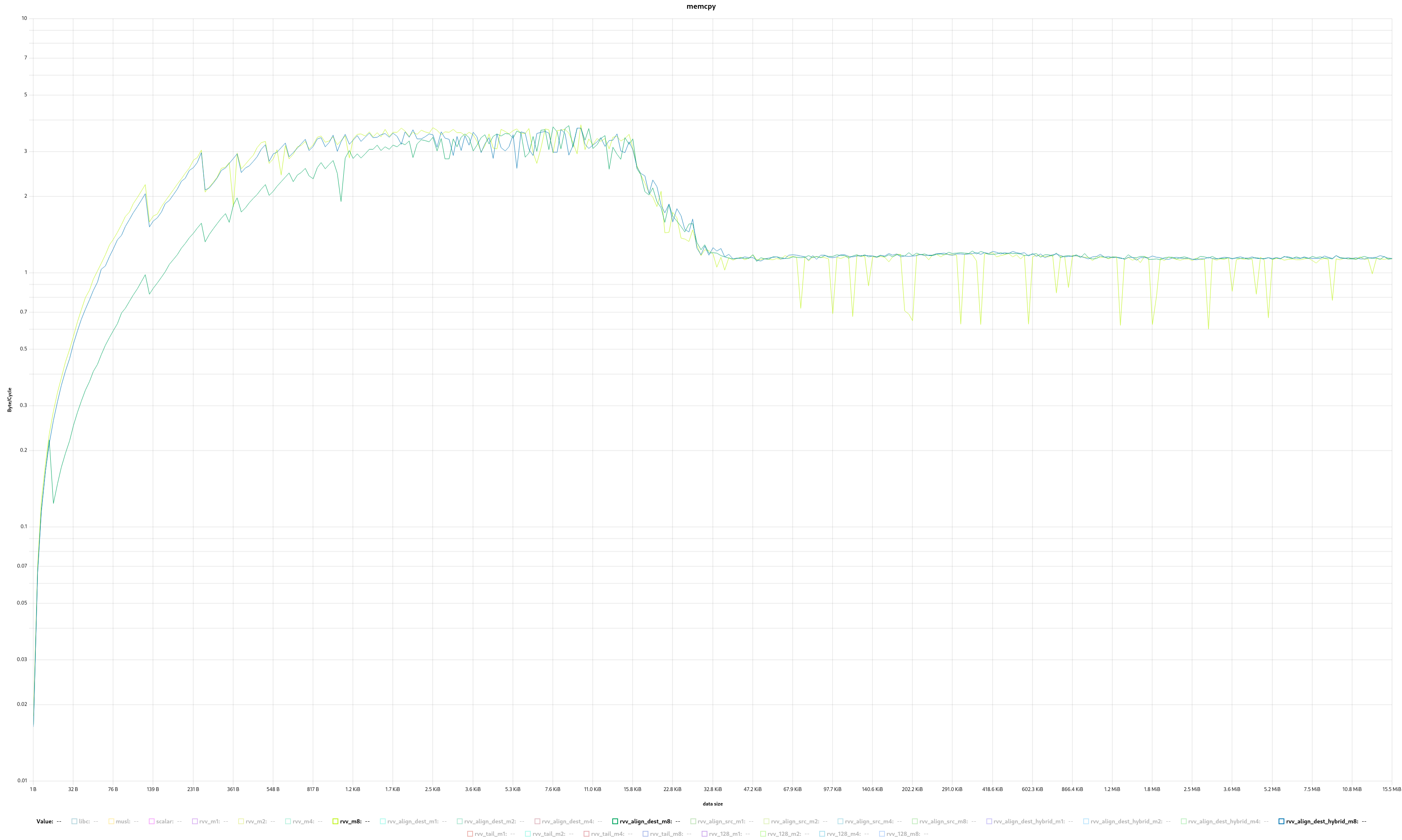
I found that for randomly aligned data, memcpy that aligns the destination pointer to vlenb is more stable when copying more data, on my MangoPi MQ Pro. (https://i.postimg.cc/Z4r29hnM/1.png)
I've got the best results from this code:
memcpy_rvv_align_dest_hybrid: mv a3, a0 csrr t0, vlenb slli t1, t0, 8 # skip costly division for more values bltu a2, t1, 2f # len < vlen sub t1, zero, a0 remu t1, t1, t0 # align = (-dest) % vlen vsetvli t0, t1, e8, m8, ta, ma # align dest to vlen 1: vle8.v v0, (a1) add a1, a1, t0 sub a2, a2, t0 vse8.v v0, (a3) add a3, a3, t0 2: vsetvli t0, a2, e8, m8, ta, ma bnez a2, 1b retOMG you've bloated a 9 instruction function to 15 instructions!!!!
Well, ok, scalar optimised memcpy() gets into hundreds of instructions.
Your result may well be hardware dependent. That's the kind of thing that you kind of have to wait for hardware to appear to actually know (or be in the team designing the hardware).
Just how much faster is it on C906? And does the same happen on C910?
I'd actually expect the final version to also incorporate the Zihintntl extension, which would allow the load/stores to bypass the cache, since the equivalent non temporal instruction on x86 are also the fastest.
Those might be "cheap" to tack onto an x86 core where there already is a ton of microcoding infrastructure, but on RISC-V that just won't the the case often. It could make sense to have an extension for it, but not really any reason to have it in base RISC-V.
> Also, expect x86_64 -> risc-v port bugs because to: byte->byte word->halfword doubleword->word quadword->doubleword
Yeah, I don't know why everyone doesn't just call it int8, int16 and so on. That would be much better. This "word" naming is just confusing.
I would be using SSE or AVX instructions for memcpy.
On recent Intel and AMD CPUs, SSE or AVX instructions can beat "rep movsb" only in certain ranges of copy sizes.
On all CPUs, "rep movsb" is slower for very short copies. The threshold under which "rep movsb" becomes slower depends on the CPU model. For example, on a Zen 3 the threshold is slightly above 2 kilobytes, so for copies up to 2 kB one should use SSE/AVX and above 2 kB one should use "rep movsb".
On Zen 3 there is a second range where "rep movsb" is slower, approximately between 1 MB and 20 MB (i.e. when the operands are in the L3 cache memory).
For any larger copies "rep movsb" is again faster.
So depending on the size of the copy and on the CPU model, an optimized memcpy should choose either "rep movsb" or SSE/AVX for each copy.
A simplified criterion that should be acceptable on most recent CPUs would be to always use "rep movsb" for sizes of one memory page (4 kB) or more and to use SSE/AVX for the shorter copies.
There's no such thing, as RISC-V memory operations are very consciously explicit load/store instructions.
RISC-V does not have memory to memory ops.
Classic RISC "load/store" architectures don't even have register-memory ops either besides load and store.
x86, as wonderfully CISC-y as it is, has register-memory and memory-memory ops with various fun addressing modes.
While most of the time load and store instructions are enough, all RISC ISAs were forced to add eventually a few atomic read-modify-write instructions, otherwise the programs for systems with a large number of cores become too inefficient.
The most important atomic read-modify-write instruction is fetch-and-add, the next in importance are fetch-and-or, fetch-and-and and fetch-and-xor, and then the next in importance are fetch-and-max and fetch-and-min (signed and unsigned).
Aarch64 has all of them since Armv8.1-A (since Cortex-A55 and Cortex-A75), while RISC-V also has all of them in one of the extensions (AMO).
That is solving a completely different problem.
The RISC-V AMO instructions are designed and intended to be implemented such that the arithmetic part is NOT executed in the CPU in a read-modify-write sequence -- only very low end CPUs (microcontrollers, that don't have a real memory hierarchy or multiple processors anyway) do it that way.
What actually happens is this:
All of rs1 (the memory address), rs2 (the amount to be added), and a field indicating this is an AMOADD, not AMOMIN, AMOXOR etc or even a plain store are send out on in parallel fields on the peripheral bus (e.g. TileLink-C or TileLink-UH) until it gets to either the actual endpoint containing the target address (perhaps an I/O device and register), or the point where the target address is found to be accessed by a simple read/write (TileLink-UL) bus -- this is often the last-level cache controller. But it could also be an L1 or L2 cache for another CPU core, or in another CPU cluster, or even in a completely different computer with the addr/data/op triple passing over 400G ethernet or NVMe or something on the way.amoadd.w rd,rs2,(rs1)In either case, this point is much closer to the data than the originating CPU is. The TileLink device at that point atomically reads the memory contents, performs the arithmetic, stores the new value, and then sends the old value back to the CPU just the same as for a memory read.
From the CPU's point of view, the AMO is just like a memory read, except extra data (the value to be swapped, aded, xored etc) is sent with the address ... so that's like a write.
AMO instructions do not add any new complexity or state sequencing to the CPU core, compared to simple load/store.
I use TileLink as the example bus, as it was co-developed with RISC-V at Berkeley, but may RISC-V CPU cores can use AXI (or both), and Arm has recently added similar capability to AXI.
This kind of implementation (with the computations done locally in the memory or memory controller or cache controller) has already been proposed and implemented in 1981, in the NYU Ultracomputer project, i.e. the first time when such fetch-and-operation instructions have been proposed as a superior alternative to the swap or test-and-set instructions that had been previously used to ensure mutual exclusion in multiprocessor systems.
So this RISC-V extension, while very useful and actually mandatory for any CPU with a high core count, has nothing original or new, but it just follows a 40-years old established practice.
From the point of view of the memory, these atomic operations are always read-modify-write cycles. Whether the data travels up to a CPU core or only on a shorter path, depends on the implementation, but this does not change the meaning of the operation.
> [...] RISC-V [...] has nothing original or new, but it just follows a 40-years old established practice.
That is a very precise description of RISC-V as a whole.
RISC-V very deliberately does not try to break new ground technically, but consolidates the best of not only the 40 years of RISC history (and avoiding the things that turned out to be outright mistakes, or just not necessary), but even you could say the last 60 years with ideas taken from enduring designs such as IBM System/360 and Cray-1.
Being able to prove that every feature in RISC-V is either so old and so common as to be unpatentable, or else that it was patented and the patent has expired, is an essential part of RISC-V's protection against the Intel/AMD and Arm duopoly (and others). As is every company that joins RISC-V International certifying as part of joining that they do not have any IP claims against the ISA.
> while very useful and actually mandatory for any CPU with a high core count
And yet somehow A53 and A57 didn't have it!!!
The very first RISC-V chips for public sale -- the FE310 in December 2016, and the FU540 in early 2018 -- both have the AMO instructions. The former despite being a single core microcontroller with only SRAM and no external memory bus, where CLI/SEI will do the job.
For instance, I heard hhe ISA does avoid the mistake of the FLAGS everywhere which is supposed to be a nightmare for out-of-order processors.
Right. The only high performance clean sheet ISA designed since 1990 with FLAGS/condition codes is Aarch64. Alpha: no. Itanium: no. RISC-V: no.
You could perhaps argue that Aarch64 was not quite entirely clean-sheet, as for the first decade or so virtually all Aarch64 implementations had to share registers and pipelines with ARMv7.
The "since 1990" limit is the RS/6000 (aka POWER aka PowerPC), which understood that FLAGS are a bottleneck in superscalar designs, and tried to solve this by having 8 complete sets of flags instead of the usual 1. So in a way it's a step on the path from FLAGS to no FLAGS too.
By far the most common case in code is to do some kind of comparison and then immediately branch on the result of that comparison. RISC-V integrates this into a single "compare and branch" instruction. The surviving ISAs that use FLAGS now fuse the conditional branch instruction with the preceding instruction that sets the FLAGS.
In the much rarer case where you want to do a comparison and branch based on it only some time later, modern ISAs allow you to save the result of the comparison into any of the general-purpose integer registers, using either `slt`, `sltu` or simply `sub`.
You'll likely see memcpy implemented using the vector extension, e.g.:
Are you sure `rep stos/movs` are actually optimal on x86_64 systems?memcpy: mv a3, a0 # Copy destination loop: vsetvli t0, a2, e8, m8, ta, ma # Vectors of 8b vle8.v v0, (a1) # Load bytes add a1, a1, t0 # Bump pointer sub a2, a2, t0 # Decrement count vse8.v v0, (a3) # Store bytes add a3, a3, t0 # Bump pointer bnez a2, loop # Any more? ret # ReturnEdit: I just ran tinymembench on my CPU (Ryzen 5 1600X)
C copy backwards : 7300.7 MB/s (1.2%) C copy backwards (32 byte blocks) : 7330.5 MB/s (1.5%) C copy backwards (64 byte blocks) : 7313.6 MB/s (0.7%) C copy : 7385.3 MB/s (1.0%) C copy prefetched (32 bytes step) : 7737.9 MB/s (1.0%) C copy prefetched (64 bytes step) : 7701.1 MB/s (1.6%) C 2-pass copy : 6414.2 MB/s (2.1%) C 2-pass copy prefetched (32 bytes step) : 6947.9 MB/s (1.4%) C 2-pass copy prefetched (64 bytes step) : 6985.8 MB/s (1.5%) C fill : 9197.2 MB/s (1.2%) C fill (shuffle within 16 byte blocks) : 9193.0 MB/s (1.4%) C fill (shuffle within 32 byte blocks) : 9175.0 MB/s (2.2%) C fill (shuffle within 64 byte blocks) : 9229.0 MB/s (1.1%) --- standard memcpy : 11302.6 MB/s (1.2%) standard memset : 11046.1 MB/s (1.4%) --- MOVSB copy : 7668.6 MB/s (1.5%) MOVSD copy : 7607.0 MB/s (0.8%) SSE2 copy : 7987.0 MB/s (5.0%) SSE2 nontemporal copy : 11989.2 MB/s (2.7%) SSE2 copy prefetched (32 bytes step) : 7739.9 MB/s (1.3%) SSE2 copy prefetched (64 bytes step) : 7807.6 MB/s (2.9%) SSE2 nontemporal copy prefetched (32 bytes step) : 12503.7 MB/s (1.5%) SSE2 nontemporal copy prefetched (64 bytes step) : 12605.2 MB/s (2.5%) SSE2 2-pass copy : 6977.1 MB/s (1.7%) SSE2 2-pass copy prefetched (32 bytes step) : 7311.1 MB/s (1.8%) SSE2 2-pass copy prefetched (64 bytes step) : 7334.7 MB/s (1.5%) SSE2 2-pass nontemporal copy : 3223.3 MB/s SSE2 fill : 10919.1 MB/s (1.8%) SSE2 nontemporal fill : 30713.9 MB/s (1.8%)short and big "rep [sto|mov]s[bwdq]" hardware accelerated are very recent on AMD, I think you need at least a zen3.
The instructions have been there since 1978.
Nice if they're finally making them fast after 45 years, but most people's software has to run on older CPUs (and Intel CPUs) too.
This is exactly that, those were "accelerated" VERY recently. And 2 different versions: short and big memcpy/memset.
{kind=link}
Does anyone have something like this for amd64 or aarch64?
Might be useful when I'm tinkering with my toy compiler.
You could look at the architecture manuals, such as:
https://www.amd.com/en/support/tech-docs/amd64-architecture-...
https://developer.arm.com/documentation/ddi0602/2023-06/
There seem to be some instruction set summaries on the web too like:
https://developer.arm.com/documentation/qrc0001/m
https://www.cs.swarthmore.edu/~kwebb/cs31/resources/ARM64_Ch...
https://courses.cs.washington.edu/courses/cse469/18wi/Materi...
https://www.felixcloutier.com/x86/
That last one seems like a real gem for intel/x86.
These architectures might have a few more instructions than RISC-V though, and the encoding (especially amd64) may be more complicated.