Japanese typography: Kilograms of sinograms
aisforfonts.comWhat's amazing about hentai-kana (hentai as "alternative form", not pervert) is that governments and town registrars still allow using them as an official name in their electronic registry. I recently got a copy of my family register, and found out that my grandma's name was officially in hentai kana. Apparently they made special fonts for each unique character, but I don't know how they're encoded on their database. It was kinda awe-inspiring how much they care the details like that. They could replace it with a regular kana but they didn't. Names are serious business!
住民基本台帳収録変体仮名 (jūmin kihon daichō shūroku hentaigana, or Jūki-gana for short) is the character set specifically made for the administrative purposes of those local government registrars. I don't know what the actual computer system used there is based on, but it looks like Tron Code and Super Kanji support the character set. https://commons.wikimedia.org/wiki/Juki-Gana
The thing about hentaigana is that it's more or less an open set. I don't think there is the standard set of hentaigana that scholars agree upon. At a quick glance, juki-gana does not seem to be identical to Unicode's hentaigana set (https://www.unicode.org/charts/PDF/U1B000.pdf), although I'm sure the intersection is non-empty.
Hentaigana have unicode codes as you can see in this table: https://en.wikipedia.org/wiki/Hentaigana#In_Unicode
So all they need to do is use a font that implements it.
According to that page, they were only implemented in 2017. So any systems before that wouldn’t’ve been using Unicode.
> I don't know how they're encoded on their database.
All hentaigana are available in Unicode 10. They can be found in the Unicode block 1B000–1B12F (Kana Supplement + Kana Extended-A).
For example, U+1B004 𛀄 HENTAIGANA LETTER A-3
They're not in JIS X 0213, so don't expect them to be widely available any time soon...
I practice rote memorization of some 340+ hentaigana with Anki.
It is completely brutal.
I reviewed this one 384 times already: https://www.benricho.org/kana/kana-img/f4f6.gif
The lapses are just crazy.
My second most reviewed, at 374 times, is https://www.benricho.org/kana/kana-img/f465.gif
Third, at 306 times, https://www.benricho.org/kana/kana-img/f4b7.gif
Dare I ask why? They're thoroughly useless unless you regularly read pre-1900 literature in the original.
> Names are serious business!
It's also serious because names are accepted as signature using hanko (official stamps) for official business and procedures.
I used ヲ instead of ウォ in my name in my hanko. It’s katakana, not hentaigana but you don’t see it except in old documents when they used to use katakana for particles (it’s equivalent to を). Saving the extra character meant I could get it made in ten minutes instead of one day. It sometimes gets comments when I use it.
By the way, there’s no requirement that your hanko matches your name and they only need to be registered for large purchases, like a house or for business use. They are however kept on record by your bank and sometimes compared digitally. By law foreigners can always use a signature instead of hanko but it’s not recommended as the comparison will often fail. On the other hand, online banking ans ATMs are good enough now that it’s been a good five years since I set foot in a bank.
> By the way, there’s no requirement that your hanko matches your name and they only need to be registered for large purchases, like a house or for business use.
There is a requirement for it to match your name (or registered alias) if you want to register it as a 実印, no?
GP seems to be talking about 銀行印
When they say "only need to be registered for large purchases, like a house", they're talking about a 実印 - a 銀行印 is not "registered" in that sense (it will be on file at the bank, of course).
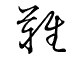{kind=link}
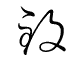{kind=link}
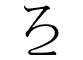{kind=link}
> some words that are common and were originally written in kanji are now written with hiragana (such as the word "here", ここ instead of 此処).
Not really. Japanese as a spoken language predates writing systems, and words like "koko" are yamatokotoba (original Japanese), not loans from other languages. It was first written in kanji (Chinese characters) because that was the only script they had initially, hiragana and katakana came later.
To confuse things even more, 此処 is valid Chinese as well, but the pronunciation is unrelated, they just mapped the meaning on top. This is also fairly common, to the point that there's a technical term for it (jukujikun).
You add in some interesting, additional facts, but you do not in anyway refute what the author wrote.
I think your comment would make more sense if you removed the “not really“ in the beginning. You come off as saying “No, it was not written in kanji at first. It was initially written in kanji!” Which casts a weird, negative shadow on the otherwise interesting facts you add.
It's a pretty subtle point, but the author is saying that "some words were originally written in kanji", while I'm noting that for a word like ここ, that's only true if you include the time when everything was originally written kanji. So the statement is technically correct, but IMHO rather misleading, since (the man'yogana pre-kana period aside) it's generally quite rare for word to make the leap from kanji to kana.
An even more subtle point is that kanji usage is fluid, so it's perfectly correct to write many words as kanji or kana, but with subtle shifts in meaning. For example, いい and 良い are both "good", but the latter is more formal and may even be read differently (yoi vs ii).
My experience lies on the artice author's side of this discussion.
Read some original Mishima or Dazai and they use kanji for words that modern novelists generally don't. Pick up some late Edo texts and the kaji-to-kana ratio is even greater still.
More mundanely though, if you consider typical text messages or random notes in a notebook, it's really common for words to "make the leap from kanji to kana" simply due to laziness/convenience/whatever.
> An even more subtle point is that kanji usage is fluid, so it's perfectly correct to write many words as kanji or kana, but with subtle shifts in meaning. For example, いい and 良い are both "good", but the latter is more formal and may even be read differently (yoi vs ii).
Correct, and sometimes words who are otherwise written in Kanji can be written in Kana in order to put emphasis on them, similar to how we use italics in Western languages.
> To confuse things even more, 此処 is valid Chinese as well
There's a lot more in common between the writing in Taiwan and Japan since Taiwan kept the "older" kanji while the CCP went thru the cultural revolution and the simplification of the number of strokes in each sign.
Still, there's a bunch of stuff that kind of looks like it would make sense when reading a Chinese word in Japanese, but turns out there's a lot of meanings are very different, either because the meaning evolved over time, or the Japanese simply imported kanji using their original sounds and not caring about their actual meaning.
>there's a bunch of stuff that kind of looks like it would make sense when reading a Chinese word in Japanese, but turns out there's a lot of meanings are very different
As someone who knows nothing of the Japanese language beyond the very basics, I found these videos quite entertaining:
https://www.youtube.com/watch?v=-E6vHCT0wpw
https://www.youtube.com/watch?v=rzJqXd-1dEU
It looks like many characters are familiar to his respondents, but their combinations make absolutely no sense.
Hmm many respondents made fairly good guess to the actual meaning though
Super interesting topic. Sometimes Japan uses the simplified version, or somewhat in between. Off the top of my head I only can think of 学/學.
There’s a handful of kanji created in Japan (called) kokuji, mostly food related. Some of these made it back to China. And there are a few differences based on simple mistakes, for example a Chinese character mistakenly applied to the wrong species of fish.
Just to add to this, simplified forms are mostly confined to Joyo kanji. The old forms do, however, exert their existence even in modern kanji as sub-pieces of (mostly rarer) other kanji---e.g. 専 used to be written 專, which still exists as the right half of 慱.
Also, there are lots of cases where the "simple" modern form doesn't really seem all that much simpler when viewing it in a typeface. My ad-hoc hypothesis is that these simplifications were considered with handrwiting in mind, e.g. 戻 (modern) vs. 戾 (original).
See https://en.m.wikipedia.org/wiki/Shinjitai#Inconsistencies My own goto example of these inconsistencies is 臭 vs. 嗅, aggravated by the fact that Chinese fonts will have the extra stroke in 臭.
This kind of thing happens with lots of language combinations as well, when loan words or Ana logical words embed themselves locally with different semantics.
You can even see this within a language e.g. UK/USA/Australia or Portugal/Brazil.
> 此処 is valid Chinese as well
No. In Chinese it's 此处 (simplified Chinese) or 此處 (traditional Chinese).
AFAIK, 処 is simplified Japanese. The original kanji is 處, which is the same as traditional Chinese.
Interesting; that shares structure with 虚. That also has some nuances of place reference.
Answer of the author of the article : I will double check about 此処 now, although I am pretty sure I ran into it when I read some books from the beginning of 20th century for my research. But I definitely still see 何処 written a lot, standing for どこ. I even saw it again today in a musical show of the 1990s!
The word 'sinogram' sounds a bit contrived, and is not something I see a lot of scholars on this topic use. I personally would recommend against using it. They are mostly just called 'Chinese characters' in English when referring to these logograms, or simply 'kanji' if specifically talking about the Chinese characters in use in Japanese writing. Kanji (and in Korean 'hanja') literally means Han characters after all.
I'm glad the Japanese writing system survived the first waves of digitization (at which point a vocal group of people worldwide was willing to sacrifice cultural artefacts and linguistic finesse for the sake of modernization) and in time put its own mark on things like character encoding and the technical capabilities of fonts on computers.
The author seems to be French-speaking, and "sinogramme" seems to be an accepted term in French:
> Les caractères chinois, ou sinogrammes, sont les unités logographiques qui composent l'écriture des langues chinoises.
Some additional information: France is actually a leading country when it comes to Japanese Studies, to the point where high-level knowledge of French is a relevant skill in pursuing Japanese studies elsewhere, as many papers were historically only available in French.
I studies Japanese a bit in France a long time ago and was told that spoken French includes all the sounds of spoken Japanese so that a French speaker should have no problem pronouncing Japanese, apart from the accent.
This is in contrast to the endless trouble French speakers have with the English 'th'...
The stereotypical French speaker who has trouble with English [h] would definitely have the same problem with the Japanese [h], [ç] and [ɸ]. If they can't manage the tongue placement for English [θ], how are they supposed to handle Japanese [ɕ] and [ʑ]? And that's just the consonants.
Usually when someone thinks that language X has all the sounds of language Y, it's a speaker of language X who hasn't yet realized that their ears are too attuned to language X to recognize the sounds of language Y as something different. Don't trust your ears!
It's only the letter H and R (as transcribed in romaji) that are not immediate for a French speaker but they are not difficult. Certainly much simpler than 'th' in English. (Source: not my ears but Japanese textbooks)
How would a French speaker pronounce し [ɕi] and じ [ʑi]? My guess would be « chi » [ʃi] and « ji » [ʒi]. Close enough to be understood, but different enough to be noticeable.
Japanese prononciation is not difficult for native French speakers. Off the top of my head, the main “difficulties” are the /r/ and the /h/ (which is always silent in French). That said, I am not sure it is much more difficult for native English speakers.
>This is in contrast to the endless trouble French speakers have with the English 'th'...
They have a whole country in the South to practice that sound...
Ah, that would explain it.
I did a MA of East Asian Studies at Helsinki University, and our professor ( https://en.wikipedia.org/wiki/Juha_Janhunen ) used the word sinogram as the standard terminology for the characters. I think this served two functions: 1) to disentangle the concept from a "character used in Chinese language", as sinograms are used at least in Chinese, Japanese, Korean and Vietnamese. 2) to create a parallel with words like "logograms" and "phonograms", as sinograms are not purely either, but contain features from both.
> as sinograms are used at least in Chinese, Japanese, Korean and Vietnam
While technically a true statement, the usage of kanji in Korea and Vietnam is now fairly limited - Korea uses typically a system based on combining sounds together nowadays (while you still see them use Kanji for names or titles here and there) and Vietnam has moved to (an accent-rich) alphabet during the French colonization .
Korean doesn't use kanji. It uses hanja.
While Korean uses a syllabary just like English, the sino-Korean words still have the underlying hanja. If you look up those words in the dictionary, it will show the hanja. [0]
From my understanding there are several usages of hanja to this day:
- Korean names. For the most part, given names will have hanja chosen by the parents/grandparents/family. However recently it's becoming more common to have pure hangeul names, or english/foreign names, with no associated hanja.
- To disambiguate homographs/homonyms. This is common on Korean tv shows.
- To represent countries, politicians, and surnames on news articles. For example, 朴 (surname Pak/Park) and 美 (USA). Here is a random article example. [1] and a list of common hanja that pops up. [2] Side note, it's humorous to me that the hanja used for USA is also the hanja for 'beauty' (미).
- For days of the week and months, I saw hanja being used somewhat commonly.
- To guess the meaning of unknown words. If you know a certain hanja reading like 비 or 경 then it makes figuring out words a bit easier.
[0]: https://en.dict.naver.com/#/entry/koen/27ed7d6b4161442885572...
[1]: https://www.chosun.com/politics/politics_general/2021/03/25/...
[2]: https://old.reddit.com/r/Korean/comments/km01fv/short_list_o...
edit: clarified about modern Korean naming practices.
> - Korean names. Unless they're into trendy foreign names, both the given name and surname will have hanja chosen.
Not necessarily true anymore. My wife has a completely made up given name that has nothing foreign: just two plain hangul characters without meaning on their own.
Ah right, I blanked on that.
Some of the most memorable people I ran into in Korea were named 하늘 and 보라. I also met someone with a single character name, but I can't remember which character... I think 강?
English doesn't use a syllabary.
You're right, I misunderstood that term.
I'd say good riddance. Why saddle yourself with this abomination?
Honestly, because it is crazy easy to read sinograms. I only lived in Japan for a few months and casually studied the language, but I wasn't with any other foreigners so I was 100% immersed in the language. At the end of the few months I reached the point where I could read Japanese faster than I can read English. It's as if reading a phonetic language still has to go through a process of symbol -> sound -> picture -> meaning in our brains, where a more ideographic language goes symbol -> meaning directly thus cutting out a lot of the processing time. Given that any given text is going to be read thousands of times more than it is written, the extra complexity in writing seems well worth the trade-off.
What resources did you use to get so good at reading kanji so fast? A few months to be able to read all but the simplest japanese is really incredible for someone that doesn't already know kanji.
I don't see the book on Amazon, but it was a pretty basic Kanji book that made a point of sorting them out by radicals so you could see how things were built, nothing too special.
I think the key was I bought tons of manga for children, the ones where all the kanji have the hiragana above them so you can get lots of vocabulary and kanji reenforcement from those.
I'm not the parent comment but I used an Anki deck from Nihongo Shark. It sorted the kanji by radicals. I did this for 2-3 months before burning out, but it made learning kanji much easier since I could see the radicals that they were composed of.
I did that as well. That deck is basically (with a few differences) an Anki version of Helsig's "Remembering the Kanji". I started with the book, and continued with the Nihongo Shark Anki deck later. The system works incredibly well for the first few hundred Kanji at least, after that it gets harder and harder to come up with the mnemonic devices the method is based on. But by that time it also starts to get easier to remember new kanji by traditional methods (in my experience at least). Even with my still incomplete number of kanji it does help tremendously with reading. It's faster and takes much less effort than trying to read just Hiragana (which I learned to read many years ago - it's still hard to read text written only in Hiragana). And with just kana you'll run into the homonym problem all the time too, unlike with kanji, and that doesn't make it easier either. Oh, and knowing the kanji can also sort out the (probable) meaning of a sentence even if I have not learned the actual word yet..
Sinograph is the term I’ve seen used in many introductory texts on Japanese. Apparently it was added just this month to the Oxford English Dictionary. https://public.oed.com/updates/new-words-list-march-2021/
"Kanji (and in Korean 'hanja') literally means Han characters after all."
They mean that in the specific context of those languages. The set of hanzi is different than the set of kanji, which is different than the set of hanja, which is different than characters that Taiwan uses. They are -not- the same characters.
I see no real issue with using sinogram/sinograph over Chinese character since it refers to a Chinese character being used in another language. And it obviates the whole hanzi, kanji, hanja thing when not necessary.
Yes indeed, I am French-speaking and "sinogrammes" is the most appropriate word in the academic world to talk about kanji. I am not sure if it is the same in the English academic world, some of the comments suggested that it is. I am going to check further about this point. (But writing my PhD in French so I will be safe anyway ^^)
The essay feels like something written in the 1970s.
One can refer to Chinese characters as hanzi.
Only when referring to the Chinese characters as used in Chinese.
A bit off topic: I happened to talk with an editor at a large Japanese publishing company a few hours ago and the marketability of audiobooks came up. While audio versions of Japanese fiction and nonfiction books are produced and sold, he said the business has never really taken off and his own company isn’t interested in it anymore. This contrasts with what seems to be a healthy and growing audiobook market in English-speaking countries.
I speculated that the nature of Japanese writing might be one reason. Written Japanese can sometimes be hard to understand when read aloud, as a lot of meaning is conveyed by the written characters themselves—most often by the kanji used, which frequently distinguish between different words with the same pronunciation, but also by the stylistic choice of whether to write a word in hiragana, katakana, or kanji.
I'd speculate differently. Americans commute by car, audiobooks are convenient to read while driving. Japanese commute by train, which is much more suitable to looking at a book (paper or electronic).
Also, Manga is massively popular, and that form doesn't covert well (or at all) to audiobook.
> I'd speculate differently. Americans commute by car...
Actually, I mentioned that possibility to the editor, too, as I have often read about Americans listening to audiobooks in the car. His response was that where he is from, in Saitama Prefecture, most people commute by car, too, but while they listen to the radio they don’t listen to audiobooks. That was his impression, anyhow.
You’re right about manga, of course.
I live in Saitama, I used to live in Canada. Thus I think the editor is blind to the differences.
In Canada you commute by driving fast along large roads, what would be highways in Japan. While in Saitama, and most of Japan car commutes, you drive on much smaller roads. You often need to stop for lights. At any time a moped might drive next to you in your own lane. Over all the experience leaves little attention to spare and the drive is never monotonous.
Meanwhile in Canada the driving was longer overall, and always with large stretchs at high speeds with no stopping once on the highway. Mopeds and motorbikes are not allowed to sneak by you. When the highway backs up you've find yourself driving for 30+ minutes without turning.
Saitama backs up too, but more because many intersections have no dedicated turning lanes. Thus a driving turning left will block everyone behind. When traffic is bad a couple intersections near my house often let no more than 3 cars per cycle through.
Personally I expect the audiobook market to be about the differences in commuting. On trains it is easier to read a book than to wear headphones. In cars your attention is constantly demanded.
In exchange commuting by car implies a shorter commute. I can commute into the core of Tokyo from Saitama in only 30 minutes. Parking costs 30 dollars for the day, and highway tolls cost 14 dollars in total, but it saves me otherwise unbillable time and thus makes sense for my situation.
Japanese-speaking people have trouble understanding each other?
> Japanese-speaking people have trouble understanding each other?
Probably no more so than speakers of other languages.
What I meant is that written Japanese often conveys information that will be lost if the text is read aloud as it is written, as words written differently are often pronounced the same.
English has similar cases, such as “right,” “write,” and “rite.” But Japanese has many, many more. For example, the words 壮観, 送還, 相姦, 相関, 相観, 挿管, 創刊, and 総監 are all pronounced sōkan, but they mean, respectively, a grand sight, repatriation, incest, correlation, physiognomy, intubation, start of publication, and inspector general. When the words are seen, their meaning is immediately clear. When they are heard, the listener must infer which meaning is intended from the context, and often the context is insufficient.
Radio announcers, when reading aloud a text, will sometimes explain the kanji with which a word was written. Audiobook narrators probably don’t feel they have the authority to do so.
> 壮観, 送還, 相姦, 相関, 相観, 挿管, 創刊, and 総監
It's not a fair comparison (because these are chosen to be homonyms in Japanese), but interestingly, all but one of them are also regular Korean words and they all sound different:
> janggwan, songhwan, sanggan, sanggwan, (unused), sapgwan, changgan, chonggam
I think he is saying that in writing, Japanese allows you to be expressive in ways that take advantage of the written medium, and a spoken version of the same text loses those text-only expressive features.
Yes, they absolutely do. You have to see it to believe it.
The language is full of homonyms, for instance.
Misunderstandings occur and then there is a back and forth along the pattern of "No, I don't mean the GENSHI (原子, atom) of GENBAKU (原爆, atom bomb). I mean GENSHI (原資, capital) as in SHIKIN (資金, funds). Okane no koto (having to do with money)." "Aaa... naruhodo".
They also often cannot read the names of people and places. It is simply not possible. If you don't know, the best you can do is form several plausible hypotheses, all of which could be incorrect due to some semi-arbitrary assignment.
What other sibling comments is true, but it's worth noting that there are cases where spoken Japanese can be ambiguous, and people disambiguate by... mimick-writing in their palm with their finger.
Sounds more like a divergence between written and spoken Japanese.
Audiobooks were a fairly niche market in the US until extremely recently, which is why Audible was able to come in and take over a huge percentage of the market share.
Audible also seems to be doing ok in Japan now so it's probably way to early to attribute the relative popularity of audiobooks to any property of the language.
Reading this reminding me of Modern Digital Publishing and Layout still largely ignores vertical text. [1], and that is especially true on the Web.
[1] https://atadistance.net/2019/10/20/japanese-text-layout-for-...
Katakana, to me, is such a trouble. I really wonder whether I'm the only one who believes that Katakana is a big part of the reason, why it's very hard for native Japanese speakers to learn English.
In a Japan of today, you grow up with a plentitude of words taken from English and written + pronounced in Katakana. So you learn to pronounce "san-do-i-chi" for sandwich, "de-za-i-na" for "designer", "su-ma-ho" for smartphone, "ca-re-n-da" for calendar. And since you use and pronounce them wrongly on a daily basis you reinforce the Japanesified pronunciations. Then, actually pronouncing "calendar" in an English way becomes tricky.
So to me, the alphabets are a great example of a "historically grown" system, that's ripe for a "refactoring".
I think this is kind of backwards. Japanese just has a restrictive phonetic system that makes it awkward to borrow English words. It’s unlikely that if it were written differently they’d pronounce the words more like English.
English has an alphabet, but we still slaughter the pronunciation of harakiri, karaoke, and kamikaze because our phonology demands it. The one Japanese word we pronounce okay is "tsunami" which has a sound we don't have, lol!
Yeah, good point. Some more: anime, manga, samurai.
Unlikely. English and Japanese have different phonetics. The writing system just reflects the spoken language.
Korean has this same problem. Ice cream becomes ah-ee-suh kr-ee-muh, etc. I don't know very much Japanese but I believe it's even worse for Korean in this regard.
interesting perspective, but more important reason in my opinion is that Japanese has so simple pronunciation (many vowels and fewer sounds all together), so Japanese people are not accustomed to making those difficult sounds that are in English.
> It is hard for me to read a text that is set only in hiragana (as in the Japanese version of Animal crossing on Switch for example, the characters only speaks in kana, with no spacing separating words...
I'm very curious as to why Nintendo made this choice!
Is it because the game is designed to be welcoming to children? In which case, why not use furigana and use it as an opportunity to learn Kanji though repetition?
Is it supposed to reflect the simplicity of a back-to-nature lifestyle and the characters therein?
I'm inclined to suspect is the latter of the two; especially if kana is only employed in character speech while other parts of the game use Kanji.
Has anybody played the Japanese version? Can you speak to the use of Kanji in the game?
> Is it supposed to reflect the simplicity of a back-to-nature lifestyle and the characters therein?
I'm inclined to suspect is the latter of the two; especially if kana is only employed in character speech while other parts of the game use Kanji.
This, but it’s the other way around. When characters speak to the player, who exists outside of the game world, it is in a mix of kanji and kana. When they write within the game world, it is in kana only.
'Cutscene'y type talks like Tom Nook or Isabelle introducing are in kanji but irc pretty much everything else like items and villager chat is hiragana.
It's a genre staple. Up until recently screens were typically too low-res to properly display frequently-used kanji. If they included furigana the furigana might be still too small as well to display them in an aesthetically coherent manner.
OMG, I read 藩, cold: "han" feudal domain. I did stare at it for a second or three, but got it. I added it to my vocabulary maybe a year-and-a-half ago?
It, and words that include it, are not such common words. How/why did he choose that for the example, I wonder.
For that matter, how did I add it? It was due to some recursive chasing of words in a dictionary, where some word's older meaning was being explained as relating to some feudal situations in the Edo period, and that explanation used 藩 in it. Evidently, I have reviewed it 24 times. The fact that it contains 番 ("ban", number in a series, turn, ...) helps a lot.
I'm glad to see I'm not the only one that does this.
I write down Korean word definitions in Korean, and this usually leads me to a whole bunch of niche words.
Commonness depends on your reading material, of course -- if you read Japanese novels set in the feudal era you'll trip over 藩 all the time :-)
I suspect the author meant to use 漢 (as in hanzi/kanji), and keyed in the wrong one instead.
Answer from the author of the article herself : No no, I put the kanji 藩 on purpose, because I love this kanji! It is a beautiful one I think :)
I am currently memorizing Hiragana (~100% done) and Katagana (~10% done), before venturing into learning some basic Japanese. It's incredibly and unnecessarily complicated, from the perspective of a "westerner" (Italian roots, fluent in English, some Spanish, bits of French). I'm still fascinated by it, and still want to learn some, primarily because I like visiting Japan and I plan to spend several weeks per year there. Kyoto is my favorite city. Last year I was fortunate enough to spend 3 months there, at the beginning of the pandemic (March to June 2020).
It would be great if languages could be "upgraded" to remove the hardest parts, both for native speakers and for foreigners willing to learn.
I remember reading that a famous poet/literate (can't remember who) tried to propose that for the Spanish language, decades ago.
Otherwise, it would be nice to have a universal language that everyone can learn and speak. Obviously, English is now occupying that spot, but I'd bet that English is certainly not the easiest, nor the most complete, language we could use.
Attempts such as Esperanto and others were never carried out with enough skills or resources. I'm wondering if it could be possible to do so today.
Coincidentally, I wrote a novel ~20 years ago, in which the protagonist is a language professor that invents a new universal language, called Galatico, and "open sources" it for the benefit of humanity. I even ventured as far as designing the basic concepts of this artificial language. It was really fun. Without knowing it, I used an alphabet system (base 64, in my case) similar to the one used in the Cistercian numerals [0]. I discovered this just two months ago, when visiting a Cistercian monastery in Italy, and then reading more about these monks.
Truly fascinating, for me.
> Attempts such as Esperanto and others were never carried out with enough skills or resources.
That is a dubious claim. The truth of the matter is that there is no economic benefit in learning Esperanto over learning English as a second language, and (comparatively) very little cultural benefit. Learning English unlocks a vast world of literature, media, and communication in addition to the basic marketable skill its proficiency entails. Esperanto? Not so much.
The only way to force the use of Esperanto or any artificial language is to force children to learn it worldwide. That's something you might expect in North Korea (if they were so inclined), but most people would rightly dismiss it as a mostly pointless exercise.
It’s worth noting that esperanto predates the era of English as an international language. Back when Zamenhof designed esperanto, French was the closest thing to an international language that unlocked the vast world of literature, media, culture, etc.
It's even harder to learn a universal language if you can always turn to Google Translate.
You can't. Gtranslate is absolute rubbish for Japanese and Korean, in my experience. It only really works on simple sentences, converted to English.
It does not generate formality levels correctly or consistently at all, so if you translate multiple sentences it can go from non-formal and non-polite to very formal and polite.
English is more or less a universal language, and esperanto will never achieve anything other than being a toy language for nerds. It's neat, but that's all it is. You would be better served learning Mandarin, English, Spanish, or German.
Just because a language more complicated to someone with a different culture doesn't mean that it's unnecessarily complicated.
It's a very westerner thing to say "your language is too complicated, you should simplify it for me"
Well, you can actually make a pretty good objective case for Japanese writing being the most complicated writing system on the planet, since no other language that I'm aware of regularly mixes 4 scripts, where basically entirety of Chinese forms just one of those scripts. Except that whereas in Chinese it's rare for a character to have more than one or two readings, in Japanese there are characters with over 70:
https://en.wiktionary.org/wiki/%E7%94%9F#Japanese
It's telling that there is what's effectively a reading test for Japanese people, where it requires 12 years of schooling to take a stab at Level 2 (covering only the "daily use" kanji!), and Level 1 requires years of additional study on top of that:
You're presenting this very misleadingly. Kanken 2 is basically comparable to something like an SAT; it covers what people are expected to have mastered by the end of high school (reading and writing, incidentally). As such it's odd to say it "requires 12 years of schooling" as if that proved something about the language.
Kanken levels beyond 2 are a different matter; they cover words that aren't in common use, and are more akin to learning trivia for the sake of learning trivia.
Most kids learn to read & write the alphabet in grade 1, although mastering the idiosyncrasies of English spelling takes a bit longer. By comparison, Japanese kids are still grinding their way through the jōyō kanji all the way to grade 12. So, yes, I think this tells you a lot about the complexity of the writing system.
Japanese kids learn to write hiragana and katakana at similar age which is comparable to the Latin Alphabet. By comparison, most English speakers still participate in stuff like spelling bees and have to actively learn to spell individual words (remember, English is not a regular phonetic language) well into adulthood.
Again: kanji tests are vocabulary tests, not just orthography tests, so Kanken is not comparable to first-graders learning the alphabet. If you're familiar with Japanese you must already know this, so I'm not sure what you're trying to argue.
It could be argued that Chinese has a lot more characters to learn if you're including the Nanori (Readings used in Names) for 生.
If you take a language like English, it's still arguable that you'd need 12 years worth of schooling to do an advanced test.
Kanji Kentei seems to ask esoteric things at level 2. So it's a test of fluency of not only the Kanji but the language.
How would an English learner fare with Shakespeare or reading a book like Finnegans Wake?
I don't know if there's any data about this. But I think what would be a good study is the level of native proficiency in languages around the world.
Does languages considered simpler result in a greater mastery by the general population?
The Kanji Kentei is not a language test, but specifically a test about kanji, and the fact that you need to be familiar with Chinese poetry etc to ace it showcases how complex the writing system is. About the closest English gets is asking obscure loanwords in spelling bees.
So like reading the original unadapted Don Quixote in Spanish. Not bad as Shakespeare, but some words had a different meaning back in the day, with inusual metaphors impossible to know unless you were an expert on Middle Ages.
For example, "La negra" would mean "the sword", and "duelos y quebrantos" wouldn't mean "mournings and breakdowns", but some kind of dish made by mixing scrambled eggs, chorizo and bacon.
Japan definitely has one of the most complicated writing systems in the world, but you can get pretty complicated with alphabets if you just go too long without spelling reform. Look at the split between Tibetan as written and Tibetan as pronounced, or basically anything to do with English and our complete lack of spelling integrity.
As someone who has studied Korean and some Japanese, Japanese is definitely much more complex. If someone saw English had two syllabaries for the same exact sounds (like katakana and hiragana) they would probably also say it's unnecessarily complex. From a foreign perspective, lowercase and uppercase could be seen as arbitrarily complex.
I would guess they're talking about kanji though, which really isn't very complex. It's moreso just annoying to have glyphs that you can't pronounce if you don't already know an onyomi/kunyomi reading...
That's a very simplistic view of the criticism, and I completely disagree with it. Just because I think Japanese is complicated (not "unnecessarily", that of course doesn't make sense when talking about a natural language) doesn't mean I think it should be simplified, nor that I can't back my claims.
Take hiragana for instance, it consists of 46 characters (versus 26 for the latin alphabet). The latin alphabet is way more efficient than hiragana because we compose sounds instead of syllables: ta is t+a, whereas in hiragana あ doesn't appear in た. Then you add katakana and kanji, and it just becomes impossible to think of Japanese writing as not complicated.
That does not mean it's not complicated either.
When learning a bit of Japanese to me it was quite obvious that the script was most likely intentionally left (or made) complicated. By using a normal alphabet that actually fits to the structure of Japanese language it would be just another ordinary language to learn.
Using a syllables-script for an ending grammar just doesn't make sense. Using 2 syllable scripts is just strange.
It most likely helped the leaders there to stay in control. Without native Japanese translators foreigners are unable to get very far.
WE USE THREE SYLLABLE SCRIPTS ALL THE TIME IN ENGLISH. lowercase and uppercase are two divergent evolutions of the roman alphabet that got shoved together for no particular reason. 𝘢𝘯𝘥 𝘪𝘵𝘢𝘭𝘪𝘤𝘴 𝘪𝘴 𝘢 𝘵𝘩𝘪𝘳𝘥 𝘥𝘦𝘴𝘤𝘦𝘯𝘥𝘢𝘯𝘵 𝘰𝘧 𝘵𝘩𝘦 𝘢𝘭𝘱𝘩𝘢𝘣𝘦𝘵 𝘵𝘩𝘢𝘵 𝘸𝘦 𝘮𝘦𝘳𝘨𝘦𝘥 𝘪𝘯 𝘵𝘰𝘰. 𝕬𝖙 𝖑𝖊𝖆𝖘𝖙 𝖜𝖊 𝖉𝖔𝖓'𝖙 𝖚𝖘𝖊 𝕭𝖑𝖆𝖈𝖐𝖑𝖊𝖙𝖙𝖊𝖗 𝖆𝖓𝖞𝖒𝖔𝖗𝖊.
>SYLLABE
Ahem. Not even syllabes.
Also, Gothic letters are just a representation, such as cursive, which in the end are the same letter.
You have the Sans/Serif versions of the CJK characters, too.
Are you an Engul user? Syllabic scripts for English are rare. Usually people use letters.
False. Uppercase and lowercase are spelt identically, so do the italics.
LOL. You've been reading Roman letters for so long you've forgotten that A and a don't look even remotely alike.
Uppercase and lowercase are not spelt identically any more than katakana and hiragana are. q-Q, e-E, r-R, a-A, b-B and most of the rest are all completely different characters. Even m and M are not as straightforwardly connected as someone who learned a latin-character based language as their first language would think.
q-Q, e-E, a-A and b-B don't diverge a lot.
Now, put Kanjis in the list and we could guess the closes to that in Spanish would be & (et) and nothing more.
Thinking that e or a look anything like E or A is entirely down to your first language using the Latin alphabet (I'm making an assumption but I can't think of any other way they would look similar).
I've done language conversation exchanges with Japanese English learners and the characters really are completely different to someone learning them for the first time.
へ is virtually identical to ヘ visually. Most of the katakana and hiragana pairs derive from the same kanji and share visual similarities, especially if you’re familiar with Chinese calligraphy. So what?
What you've said is nonsensical.
A good example of the phrase "a little bit of knowledge is a dangerous thing"
The language is structured around those two syllable letters.
Well, I haven't made that up myself - I got the idea from linguistics books - and from people that lived there for a long time. And those linguists were very clear that the language came first and then syllable script was bolted on.
What you already knows determines what you consider "easy".
When you learn English, Italian, Spanish and French you are not learning really 4 different languages as those languages overlap each other, they are from the same family(English is part of the germanic[anglo-saxon] but also the Latin family[normand]).
If you are native English speaker, you will learn French easily as most of english vocabulary(more than 60% of adjectives, and adverbs for example) comes from French.
As a native Spanish speaker, I understand most Italian and Portuguese with little effort, and French only problem is pronunciation, reading it is very easy.
For a Chinese native(Mandarin or Cantonese), learning written Japanese is easy, almost trivial.
I find Hiragana and Katakana easy to learn, not different from a vocabulary. It is kanji what is harder.
You may see the merit of it in a year or so. Spelling and pronunciation is unambiguous (at least for kana where there’s no chance to misread). It’s really hard to read pure kana because you have to process a lot of homophones although I guess that’s surmountable because it mostly works for spoken language. You do however see even native speakers explain which word they mean by signing the kanji, from time to time. And it’s a nice feature to see a new word for the first time and know how to read it (you can guess based on the radicals pretty accurately) and an approximation of its meaning.
Absolute peak language for puns and dad jokes, too.
> Spelling and pronunciation is unambiguous (at least for kana where there’s no chance to misread).
Even kana have exceptions where spelling and pronunciation are ambiguous. E.g. は/へ, which canonically represent [ha̠]/[he̞] but are also used for particles pronounced [ɰᵝa̠]/[e̞], which would usually be written わ/え. And こうし pronounced either [ko̞ːɕi] when it means 格子 (grid) or [ko̞ɯ̟ᵝɕi] when it means 子牛 (calf). Then there are aspects of the pronunciation like pitch accent and devoiced vowels that can't be expressed using kana at all...
Émilie Rigaud's work is amazing.
I read parts of the article, and skimmed the rest, and almost spat water at my screen when I read the last section:
> Hentaigana : beauties
>
> The word hentaigana is made of kana, — syllabic elements —, and hentai [...]
Here she (?) is referring to 変体 and not 変態. Earlier in the article she said "[j]apanese language is a very playful language" but I don't think she's thinking of homonyms. :-)
Sorry if I made you spat water on your screen haha! You are right, I should correct in my article "differs from the norm" by "different in shape". Thanks!